
- Giới thiệu
Trong các cụm Mô hình Ngôn ngữ Lớn (LLM), đặc biệt là các mô hình lớn hơn, hiệu quả của khối lượng công việc đào tạo AI phân tán là rất quan trọng. Hiệu quả của mô hình phụ thuộc rất nhiều vào khả năng truyền tải khối lượng dữ liệu lớn giữa các GPU và nút của mạng. Đào tạo AI đòi hỏi phải trao đổi gradient và trọng số thông qua các kết nối mạng băng thông cao, độ trễ thấp.
Khi khối lượng công việc đào tạo được phân bổ trên nhiều GPU hoặc nút (miền), cần phải giao tiếp thường xuyên để đồng bộ hóa các tham số và chia sẻ dữ liệu. Nếu băng thông mạng hoặc độ trễ không tối ưu, GPU có thể ở trạng thái chờ, chờ các giao tiếp này thay vì thực hiện tính toán.
Khi các LLM ngày càng phát triển, bao gồm hàng tỷ tham số, nhu cầu về một nền tảng mạng mạnh mẽ trở nên thiết yếu. Các mạng bị mất dữ liệu, tắc nghẽn hoặc không tối ưu có thể trở thành những điểm nghẽn đáng kể. “Thời gian dành cho mạng” có khả năng chiếm tới 50% thời gian xử lý công việc, như được thể hiện trong sơ đồ Meta bên dưới.
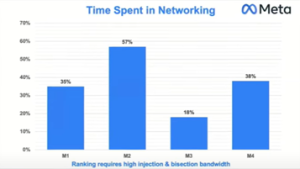
Hiệu quả “khối lượng công việc” đào tạo đề cập đến mức độ sử dụng tài nguyên tính toán để đạt được hiệu suất cao. Một trong những yếu tố chính ảnh hưởng đến “Hiệu quả khối lượng công việc” là thời gian chờ đợi trên mạng trong quá trình đào tạo phân tán. “Thời gian dành cho mạng” này trực tiếp làm giảm mức sử dụng phần cứng, tăng tổng thời gian đào tạo và tăng chi phí vận hành.
Giảm thiểu “Thời gian dành cho Mạng” — thông qua các kết nối tốc độ cao và giao thức truyền thông được cải tiến cho phép tính toán song song hiệu quả hơn, tối đa hóa việc sử dụng tài nguyên, từ đó cải thiện đáng kể hiệu quả đào tạo. Do đó, hiệu suất của mạng ảnh hưởng trực tiếp đến thông lượng tính toán tổng thể. Điều này thực sự biến mạng thành một phần không thể thiếu của khả năng tính toán trong các tình huống đào tạo phân tán.
Ai cũng hiểu rằng giao tiếp GPU-to-GPU hiệu quả đòi hỏi băng thông cao và độ trễ thấp — thường đạt được nhờ các công nghệ như RoCEv2. Tuy nhiên, các kiến trúc sư mạng cũng cần cân nhắc các tính năng mới bổ sung như cân bằng tải động và kiểm soát tắc nghẽn được cải thiện khi thiết kế các giải pháp cho mạng GPU. Việc so sánh các giải pháp khác nhau đòi hỏi sự hiểu biết rõ ràng về các tính năng này và cách chúng giải quyết những thách thức cụ thể trong các trường hợp sử dụng đào tạo phân tán.
Khi chúng tôi bắt đầu soạn thảo blog, rõ ràng là việc hiểu biết cơ bản về giao tiếp GPU và các mô hình lưu lượng điển hình của chúng là vô cùng quan trọng. Bối cảnh này sẽ cho phép độc giả đánh giá những thách thức mà các giải pháp mạng truyền thống phải đối mặt với những yêu cầu này. Nó cũng sẽ làm nổi bật nhu cầu về các tính năng nâng cao.
Bài đăng đầu tiên của chúng tôi sẽ tập trung vào việc cung cấp một cái nhìn tổng quan ngắn gọn về các cụm đào tạo GPU, bài đăng thứ hai sẽ giải thích các mô hình lưu lượng GPU-to-GPU và các công nghệ/kỹ thuật liên quan, cũng như các đặc điểm lưu lượng mạng độc đáo được thúc đẩy bởi các mô hình lưu lượng này. Bối cảnh này sẽ mở đường cho các cuộc thảo luận chuyên sâu hơn về băng thông cần thiết, độ trễ và các tính năng mạng mới nổi. Chúng tôi dự định sẽ đề cập đến các chủ đề này trong một hoặc nhiều bài đăng trong tương lai.
1.1. Các kỹ thuật song song khác nhau: Song song là một kỹ thuật quan trọng trong việc huấn luyện các Mô hình Ngôn ngữ Lớn (LLM) do yêu cầu tính toán và hạn chế bộ nhớ rất lớn của chúng. Các mô hình này không thể được huấn luyện hiệu quả trên một GPU duy nhất khi chúng có hàng tỷ tham số. Song song phân bổ khối lượng công việc tính toán và bộ nhớ trên nhiều thiết bị, giúp tăng tốc đáng kể thời gian huấn luyện và nâng cao khả năng mở rộng. Các loại song song chính bao gồm:
1.1.1. Song song dữ liệu (DP) : Nhiều GPU, mỗi GPU lưu trữ một bản sao hoàn chỉnh của mô hình và xử lý các lô dữ liệu khác nhau. Độ dốc được đồng bộ hóa trong quá trình lan truyền ngược.
1.1.2. Song song Tensor (TP) : Các lớp hoặc tenxơ của mô hình được phân vùng trên các GPU. Điều này liên quan đến việc chia các lớp mô hình lớn ở cấp độ chiều tenxơ.
1.1.3. Song song đường ống (PP) : Các lớp mô hình được chia thành các giai đoạn tuần tự phân bổ trên các GPU hoặc nút khác nhau, tạo thành một đường ống mà dữ liệu chạy qua.
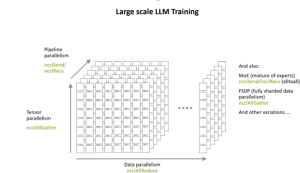
do Sreeram Potluri thực hiện – Khóa đào tạo NVIS tháng 5 năm 2024
Việc kết hợp các kỹ thuật song song này có thể cải thiện việc đào tạo và triển khai LLM. Điều này đảm bảo sử dụng hiệu quả tài nguyên bộ nhớ và tính toán. Ví dụ, việc kết hợp song song dữ liệu, tenxơ và đường ống có thể xử lý hiệu quả số lượng tham số khổng lồ và kiến trúc sâu.
Các kỹ thuật song song khác nhau dựa trên các phép toán tập thể để phối hợp tính toán trên nhiều đơn vị tính toán như GPU hoặc nút (như sơ đồ trên). Ví dụ, trong song song dữ liệu, mỗi thiết bị xử lý các lô dữ liệu khác nhau. Tuy nhiên, sau đó, chúng phải đồng bộ hóa gradient thông qua giao tiếp tập thể (như all-reduce) trước khi cập nhật trọng số mô hình để đảm bảo tính nhất quán.
Trong cơ chế song song tenxơ, tenxơ được phân chia trên các thiết bị, yêu cầu đồng bộ hóa ở mọi lớp để trao đổi kết quả từng phần, một lần nữa sử dụng các phép toán tập thể để duy trì tính chính xác và hiệu suất. Cơ chế song song đường ống phân đoạn mô hình trên các thiết bị và đòi hỏi các phép toán tập thể để chuyển các phép kích hoạt và gradient giữa các giai đoạn đường ống. Do đó, các phép toán tập thể tốc độ cao là rất cần thiết để giảm thiểu chi phí truyền thông và mở rộng quy mô đào tạo LLM thành công trên cơ sở hạ tầng phân tán.
2. Các thao tác tập thể và một-một trong Học sâu: Nhìn chung, các thao tác tập thể và p2p đề cập đến một tập hợp các nguyên hàm giao tiếp — chẳng hạn như all-reduce, all-gather, all-to-all và broadcast. Các tập hợp này được yêu cầu để phối hợp và đồng bộ hóa dữ liệu (như gradient hoặc tham số) trên nhiều GPU hoặc nút trong quá trình huấn luyện phân tán.
2.1. Ví dụ về các hoạt động này:
Tất cả tập hợp
Thao tác Allgather là một nguyên hàm giao tiếp tập thể quan trọng trong huấn luyện mô hình ngôn ngữ lớn phân tán (LLM). Nó cho phép mỗi GPU tham gia chia sẻ dữ liệu riêng của mình với mọi GPU khác trong nhóm.
Trong quá trình huấn luyện song song mô hình, mỗi công nhân tính toán một phần của mô hình hoặc tập dữ liệu. Sau khi phần hoặc tập dữ liệu đó hoàn tất, tính toán cục bộ (chẳng hạn như tính toán gradient hoặc kích hoạt chuyển tiếp), công nhân sẽ sử dụng Allgather để trao đổi kết quả. Giờ đây, tất cả công nhân đều sở hữu bộ dữ liệu đầy đủ cần thiết cho các bước tiếp theo. Việc trao đổi dữ liệu đồng bộ này đảm bảo tính nhất quán của mô hình và cho phép tính toán thêm (ví dụ: cập nhật tham số) trên các thiết bị phân tán.
Việc triển khai Allgather hiệu quả là điều cần thiết để tối đa hóa thông lượng và giảm thiểu chi phí truyền thông trong đào tạo LLM quy mô lớn.

Tất cả giảm
AllReduce là một hoạt động giao tiếp tập thể thiết yếu cho việc huấn luyện phân tán các Mô hình Ngôn ngữ Lớn (LLM). Trong mỗi bước huấn luyện, các gradient hoặc tham số được tính toán trên nhiều GPU sẽ được cộng lại trên tất cả các nút. Kết quả sau đó được truyền trở lại mỗi nút, do đó tất cả chúng đều giữ nguyên các giá trị đồng bộ, trung bình (hoặc giảm thiểu) giống nhau.
Quy trình này đảm bảo tính nhất quán của mô hình trên các quy trình phân tán và rất quan trọng để mở rộng hiệu quả việc đào tạo LLM trên các cụm máy tính hiệu năng cao. AllReduce giảm thiểu chi phí giao tiếp so với các phương pháp đơn giản và thường được triển khai bằng các thư viện cải tiến như NCCL hoặc MPI.

Tất cả cho tất cả
Hoạt động All-to-All đề cập đến một mô hình giao tiếp trong điện toán phân tán, trong đó dữ liệu hoặc gradient phải được trao đổi giữa tất cả các GPU tham gia trong quá trình huấn luyện. Hoạt động này rất quan trọng trong các tình huống như song song mô hình phân tán (song song chuyên gia) và tinh chỉnh.
Mỗi thiết bị chỉ nắm giữ một phần của mô hình hoặc tập dữ liệu. Trong quá trình đồng bộ hóa trọng số mô hình, tổng hợp gradient hoặc chia sẻ kích hoạt — mỗi nút cần gửi và nhận dữ liệu từ mọi nút khác trong cụm, đảm bảo tính nhất quán và cho phép tính toán cộng tác. Các kết nối tốc độ cao, chẳng hạn như InfiniBand hoặc Ethernet hiệu suất cao, rất quan trọng cho các hoạt động này, vì mạng kém hiệu quả hoặc chậm có thể tạo ra tình trạng tắc nghẽn đáng kể.

Các thao tác all-to-all hiệu quả giúp tối đa hóa việc sử dụng tài nguyên và giảm thiểu thời gian đào tạo. Việc triển khai chúng đòi hỏi sự phối hợp chặt chẽ để cân bằng giữa chi phí truyền thông và hiệu quả tính toán, đặc biệt là khi quy mô mô hình tăng lên. Có một số thao tác tập hợp thường được sử dụng hơn (ví dụ: ReduceScatter, Scatter, Reduce, Gather, v.v.).
2.2 Thư viện truyền thông tập thể trong học sâu
Thư viện tập thể là các thành phần phần mềm chuyên biệt, triển khai hiệu quả các hoạt động tập thể và ngang hàng (p2p) này bằng cách tận dụng các công nghệ mạng và cấu trúc phần cứng tiên tiến. Ví dụ, Thư viện Giao tiếp Tập thể NVIDIA (NCC – nickl) được sử dụng rộng rãi trong đào tạo LLM để tăng tốc và cải thiện các hoạt động này, đảm bảo luồng dữ liệu giữa GPU và các nút có băng thông cao và độ trễ thấp.
Một số thư viện truyền thông cạnh tranh khác là RCCL (Thư viện truyền thông tập thể ROCm) của AMD và cuối cùng là Thư viện truyền thông tập thể MS-CCL không đồng nhất của Microsoft dành cho GPU của nhiều nhà cung cấp.
Sự lựa chọn và hiệu quả của thư viện tập thể tác động trực tiếp đến khả năng mở rộng và tốc độ đào tạo mô hình phân tán: các hoạt động tập thể hiệu quả được triển khai thông qua các thư viện tiên tiến như NCCL là rất quan trọng để duy trì sự đồng bộ hóa và thông lượng trong các cụm đào tạo LLM đa nút lớn.
Sau đây là tổng quan về các khả năng khác do NCCL cung cấp ( Phần này được lấy từ hướng dẫn dành cho nhà phát triển NCCL 2.6.4 của Nvidia – phần tổng quan ).
NCCL tích hợp với các nền tảng học sâu phổ biến như PyTorch, TensorFlow và MXNet, cung cấp các quy trình giao tiếp được cải thiện. Điều này giúp tăng tốc quá trình đào tạo học sâu trên các hệ thống đa GPU.
2.2.1. Tự động phát hiện cấu trúc mạng : NCCL sở hữu tính năng phát hiện cấu trúc mạng tiên tiến và các mô hình điều chỉnh nội bộ, tự động lựa chọn các thông số tối ưu dựa trên nhiều yếu tố. Một số yếu tố đó bao gồm số lượng GPU, kích thước miền NVLink, tốc độ NVLink và cấu trúc mạng PCIe. Tính năng tự động phát hiện này đảm bảo hiệu suất truyền thông tối ưu.
Các Thư viện Truyền thông Tập thể như NCCL tự động phát hiện cấu trúc liên kết của GPU, bao gồm việc hiểu cách sắp xếp vật lý của GPU. Chúng cũng phát hiện các kết nối mạng như PCIe, NVLink, NVSwitch và Mellanox InfiniBand.
Quá trình phát hiện này bao gồm việc truy vấn hệ thống về vị trí GPU và bộ điều hợp mạng để xây dựng bản đồ nội bộ về cấu trúc mạng. Việc lập bản đồ này rất cần thiết để cải thiện các tuyến giao tiếp—chọn đường dẫn có băng thông cao nhất và độ trễ thấp nhất để đảm bảo đồng bộ hóa dữ liệu hiệu quả và giảm thời gian đào tạo.
-
- Thư viện truyền thông tập thể phát hiện sự sắp xếp của GPU và các kết nối khả dụng (như PCIe, NVLink, NVSwitch và InfiniBand) trong và giữa các nút.
- Bằng cách thẩm vấn hệ thống về vị trí GPU, bộ điều hợp mạng và các đường dẫn truyền thông có thể có, các thư viện này sẽ xây dựng một bản đồ nội bộ về cấu trúc mạng.
- Nhận thức về cấu trúc này cho phép thư viện cải thiện việc di chuyển dữ liệu bằng cách lựa chọn các tuyến truyền thông hiệu quả nhất, giảm thiểu độ trễ và tối đa hóa băng thông.
- Thư viện cũng có thể sử dụng các tính năng nâng cao như GPUDirect RDMA, cho phép truy cập bộ nhớ trực tiếp từ GPU này sang GPU khác trên các nút, bỏ qua CPU để giảm độ trễ.
- Công nghệ truyền thông nhận biết cấu trúc mạng của NCCL có thể điều chỉnh các thuật toán dựa trên các đường dẫn mạng được phát hiện, ưu tiên NVLink cho truyền thông nội nút và InfiniBand cho truyền thông liên nút.
2.2.2. Khả năng chịu lỗi NCCL cung cấp một bộ tính năng cho phép ứng dụng phục hồi sau các lỗi nghiêm trọng như lỗi mạng, lỗi nút hoặc lỗi quy trình. Khi xảy ra lỗi như vậy, ứng dụng sẽ có thể gọi ncclCommAbort trên bộ giao tiếp để giải phóng tất cả tài nguyên. Sau đó, nó sẽ tạo một bộ giao tiếp mới để tiếp tục.
2.2.3. Chất lượng Dịch vụ : Các ứng dụng chồng chéo giao tiếp có thể được hưởng lợi từ các tính năng Chất lượng Dịch vụ (QoS) mạng. NCCL cho phép ứng dụng gán một lớp lưu lượng (TC) cho mỗi thiết bị giao tiếp để xác định các yêu cầu giao tiếp của thiết bị. Tất cả các hoạt động mạng trên một thiết bị giao tiếp sẽ sử dụng TC đã được gán.
Ý nghĩa của TC phụ thuộc vào plugin mạng được thiết bị giao tiếp sử dụng (chẳng hạn như mạng IB sử dụng mức dịch vụ, mạng RoCE sử dụng loại dịch vụ). TC được định nghĩa bởi cấu hình hệ thống. Các ứng dụng phải hiểu các TC khả dụng trên hệ thống và hành vi tương đối của chúng để sử dụng chúng hiệu quả.
2.3. NCCL hoạt động ở đâu
2.3.1. Trong mỗi nút tính toán
NCCL hoạt động trên tất cả các GPU được cài đặt trong một nút duy nhất. Nó sử dụng các kết nối tốc độ cao như NVLink, PCIe hoặc bộ nhớ chia sẻ để xử lý giao tiếp giữa các GPU của nút đó.
2.3.2. Trên nhiều nút tính toán
Đối với các cụm phân tán, NCCL cho phép giao tiếp giữa các GPU nằm trên các máy chủ vật lý (node) khác nhau. Để đạt được điều này, NCCL tận dụng các công nghệ mạng như InfiniBand, RoCE hoặc Ethernet. Giao tiếp nội bộ giữa các node này rất quan trọng để mở rộng quy mô các cụm lớn.
2.3.3. Tích hợp với các khuôn khổ học sâu
Các thư viện học sâu (như DistributedDataParallel của PyTorch hoặc MultiWorkerMirroredStrategy của TensorFlow) gọi các hàm NCCL một cách minh bạch. NCCL chạy như một phần của quy trình huấn luyện được khởi chạy trên mỗi GPU — không có dịch vụ NCCL riêng biệt. Thay vào đó, các chương trình con của nó được gọi từ cùng một quy trình Python (hoặc C++) chạy mã huấn luyện.
2.3.4. Bối cảnh quy trình
NCCL chạy trong bối cảnh tập lệnh đào tạo hoặc quy trình khung của người dùng trên mỗi GPU. Do đó, mỗi quy trình công nhân chịu trách nhiệm cho một phân đoạn mô hình hoặc phân đoạn dữ liệu đều bao gồm các lệnh gọi NCCL cho giao tiếp tập thể cần thiết.
Những điểm chính
- Hiệu quả mạng rất quan trọng đối với việc đào tạo phân tán các mô hình ngôn ngữ lớn, vì nó quyết định tốc độ chia sẻ dữ liệu giữa các GPU và nút. Băng thông mạng kém hoặc độ trễ cao gây ra tình trạng GPU nhàn rỗi, làm tăng đáng kể thời gian đào tạo và chi phí vận hành. Việc sử dụng các kết nối tốc độ cao, độ trễ thấp và các tính năng mạng tiên tiến sẽ tối đa hóa việc sử dụng tài nguyên và hiệu suất đào tạo tổng thể.
- Quá trình đào tạo LLM phân tán hiệu quả phụ thuộc vào một số loại song song—bao gồm song song dữ liệu, tenxơ và đường ống—cho phép các mô hình lớn mở rộng trên nhiều GPU bằng cách phân bổ đều tải tính toán và bộ nhớ.
- Các hoạt động giao tiếp tập thể quan trọng như allreduce, allgather và all-to-all đồng bộ hóa các gradient, kích hoạt và trọng số mô hình giữa các GPU; hiệu quả của chúng rất cần thiết để duy trì tính nhất quán và hiệu suất trong quá trình đào tạo LLM.
- Cần có các kết nối tốc độ cao (như InfiniBand, RoCEv2, NVLink và NVSwitch) và công nghệ mạng mạnh mẽ; băng thông kém hoặc độ trễ cao có thể dẫn đến tình trạng tắc nghẽn đáng kể, với khả năng mất tới 50% thời gian xử lý công việc do phải chờ lưu lượng mạng.
- Các thư viện truyền thông tập thể chuyên biệt—như NCCL của NVIDIA, RCCL của AMD và MS-CCL của Microsoft—tự động phát hiện các sắp xếp GPU/cấu trúc mạng và tối ưu hóa việc di chuyển dữ liệu trên các cụm bằng các tính năng như nhận biết cấu trúc mạng, GPUDirect RDMA, khả năng chịu lỗi và QoS mạng.
- Hiệu quả của các thư viện và cơ sở hạ tầng mạng này tác động trực tiếp đến thông lượng đào tạo, khả năng mở rộng và hiệu quả về chi phí; luồng lưu lượng cụm GPU tối ưu là nền tảng cho việc triển khai LLM quy mô lớn thành công.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...