

Trong bài viết trước, chúng tôi đã giới thiệu cách chạy Llama 2 trên XE9680 bằng LLM Playground của NVIDIA (một phần của nền tảng NeMo). Đây là một nền tảng tiên tiến để thử nghiệm và triển khai các mô hình ngôn ngữ lớn (LLM) cho nhiều ứng dụng doanh nghiệp khác nhau.
Thực tế là việc chạy suy luận trực tiếp với các mô hình nền tảng trong bối cảnh doanh nghiệp đơn giản là không thể và đặt ra một số thách thức, chẳng hạn như thiếu kiến thức chuyên ngành, khả năng thông tin lỗi thời hoặc không đầy đủ và nguy cơ tạo ra phản hồi không chính xác hoặc gây hiểu lầm.
Công nghệ tăng cường truy xuất (RAG) đại diện cho một cải tiến quan trọng trong không gian AI tạo sinh.
RAG kết hợp các mô hình nền tảng AI tạo sinh với các kỹ thuật truy xuất thông tin tiên tiến để tạo ra các hệ thống tương tác vừa có khả năng phản hồi nhanh vừa cung cấp thông tin sâu sắc. Nhờ tính linh hoạt, RAG có thể được thiết kế theo nhiều cách khác nhau. Trong một bài blog gần đây, David O’Dell đã trình bày cách xây dựng RAG từ đầu.
Blog này cũng đóng vai trò là tài liệu bổ sung cho Sách Trắng Kỹ thuật NVIDIA RAG On Dell có sẵn tại đây , trong đó nêu bật giải pháp được xây dựng trên Phần cứng Trung tâm Dữ liệu Dell, K8s, Dell CSI PowerScale cho Kubernetes và bộ NVIDIA AI Enterprise. Xem Sách Trắng Kỹ thuật để tìm hiểu thêm về kiến trúc giải pháp và phương pháp tiếp cận logic được sử dụng.
Trong blog này, chúng tôi sẽ trình bày cách tiếp cận mới của NVIDIA cung cấp cách triển khai RAG tự động hơn, có thể được khách hàng tận dụng khi tìm kiếm cách tiếp cận chuẩn hóa hơn.
Chúng tôi sẽ hướng dẫn bạn từng bước để bắt đầu và vận hành phần mềm LLM Playground của NVIDIA , giúp bạn có thể thử nghiệm các pipeline RAG của riêng mình. Trong các bài đăng trên blog tiếp theo (khi chúng ta đã quen thuộc với những kiến thức cơ bản về LLM Playground), chúng tôi sẽ bắt đầu đào sâu hơn một chút về pipeline RAG để bạn có thể tùy chỉnh sâu hơn và triển khai các pipeline RAG tiềm năng bằng cách sử dụng các thành phần phần mềm của NVIDIA.
Nhưng trước tiên, chúng ta hãy cùng tìm hiểu những điều cơ bản.
Xây dựng đường ống RAG của riêng bạn (Bắt đầu)
Một quy trình RAG điển hình bao gồm nhiều giai đoạn. Quá trình tiếp nhận tài liệu diễn ra ngoại tuyến, và khi có truy vấn trực tuyến, việc truy xuất các tài liệu liên quan và tạo phản hồi sẽ diễn ra.
Ở cấp độ cao, kiến trúc của hệ thống RAG có thể được rút gọn thành hai đường ống:
- Một quy trình lặp lại của quá trình tiền xử lý, thu thập và tạo nhúng tài liệu
- Một đường ống suy luận với truy vấn của người dùng và tạo phản hồi
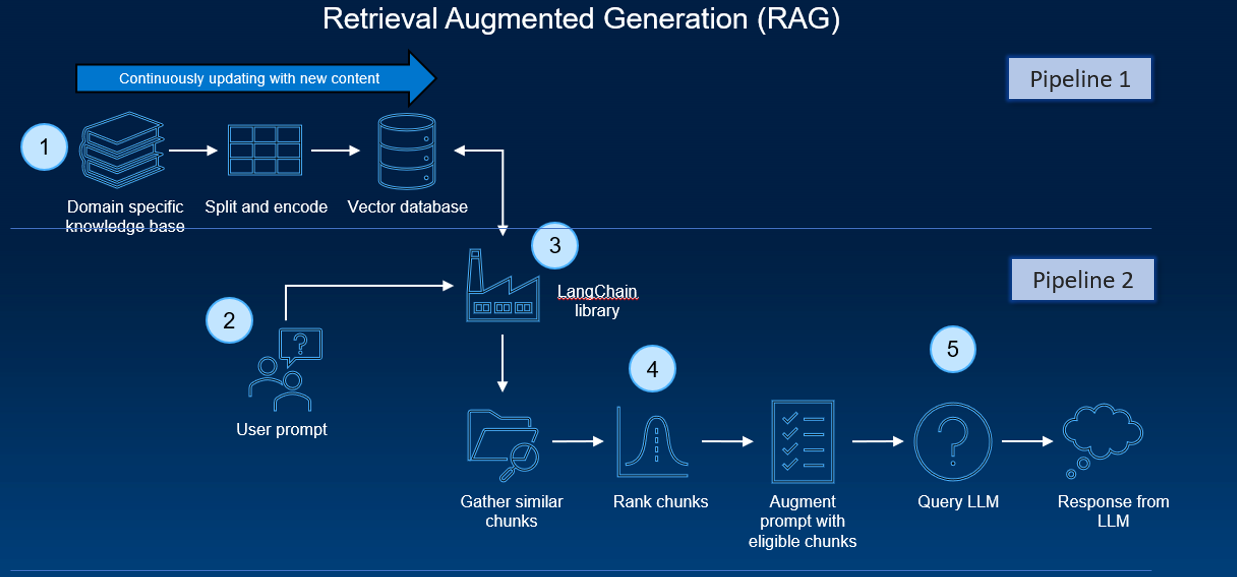
Một số thành phần và công cụ phần mềm thường được sử dụng. Các thành phần này hoạt động cùng nhau để cho phép xử lý và xử lý dữ liệu hiệu quả, cũng như thực hiện các tác vụ suy luận.
Các thành phần phần mềm này, kết hợp với thiết lập phần cứng (như GPU và máy ảo/bộ chứa), tạo ra một cơ sở hạ tầng để chạy các tác vụ suy luận AI trong một quy trình RAG điển hình. Việc tích hợp các công cụ này cho phép xử lý các tập dữ liệu tùy chỉnh (như PDF) và tạo ra các phản hồi tinh vi, giống con người bởi một mô hình AI.
Như đã đề cập trước đó, David O’Dell đã cung cấp một hướng dẫn cực kỳ hữu ích để thiết lập và vận hành đường ống RAG. Một trong những thành phần quan trọng là chức năng đường ống .
Hàm pipeline trong thư viện Transformers của Hugging Face là một API cấp cao được thiết kế để đơn giản hóa quy trình sử dụng các mô hình được đào tạo trước cho nhiều tác vụ NLP khác nhau, đồng thời trừu tượng hóa sự phức tạp của việc tải mô hình, tiền xử lý dữ liệu (như mã hóa), suy luận và hậu xử lý. Pipeline giao tiếp trực tiếp với mô hình để thực hiện suy luận nhưng tập trung nhiều hơn vào tính dễ sử dụng và khả năng truy cập hơn là mở rộng quy mô và tối ưu hóa việc sử dụng tài nguyên. Là một API cấp cao, nó trừu tượng hóa phần lớn sự phức tạp liên quan đến việc thiết lập và sử dụng các mô hình dựa trên transformer khác nhau.
Nó lý tưởng để triển khai nhanh chóng các tác vụ NLP, tạo mẫu và các ứng dụng đòi hỏi tính dễ sử dụng và đơn giản.
Nhưng liệu có dễ thực hiện không?
Việc thiết lập và duy trì các đường ống RAG đòi hỏi chuyên môn kỹ thuật đáng kể về AI, học máy và quản trị hệ thống. Mặc dù một số thành phần (chẳng hạn như ‘chức năng đường ống’) được thiết kế để dễ sử dụng, nhưng thông thường, chúng không được thiết kế để mở rộng quy mô.
Vì vậy, chúng ta cần phần mềm mạnh mẽ, có khả năng mở rộng và dễ sử dụng hơn.
Các giải pháp của NVIDIA được thiết kế để có hiệu suất cao và khả năng mở rộng, điều cần thiết để xử lý khối lượng công việc AI quy mô lớn và tương tác thời gian thực.
NVIDIA cung cấp tài liệu mở rộng, các mẫu sổ ghi chép Jupyter và một ứng dụng web chatbot mẫu, vô cùng hữu ích cho việc hiểu và triển khai quy trình RAG.
Hệ thống được tối ưu hóa cho GPU NVIDIA, đảm bảo sử dụng hiệu quả một số phần cứng mạnh mẽ nhất hiện có.
Phương pháp đơn giản hóa của NVIDA — Xây dựng hệ thống RAG bằng các công cụ của NVIDIA:
Phương pháp của NVIDIA là hợp lý hóa quy trình RAG và giúp việc khởi động và chạy trở nên dễ dàng hơn nhiều.
Bằng cách cung cấp một bộ công cụ được tối ưu hóa và các thành phần được xây dựng sẵn, NVIDIA đã phát triển một quy trình làm việc AI cho việc tạo ra dữ liệu tăng cường truy xuất, bao gồm một chatbot mẫu và các yếu tố người dùng cần để tạo ứng dụng riêng bằng phương pháp mới này. Nó giúp đơn giản hóa nhiệm vụ khó khăn trước đây là tạo ra các chatbot AI phức tạp, đảm bảo khả năng mở rộng và hiệu suất cao.
Bắt đầu với sân chơi LLM của NVIDIA
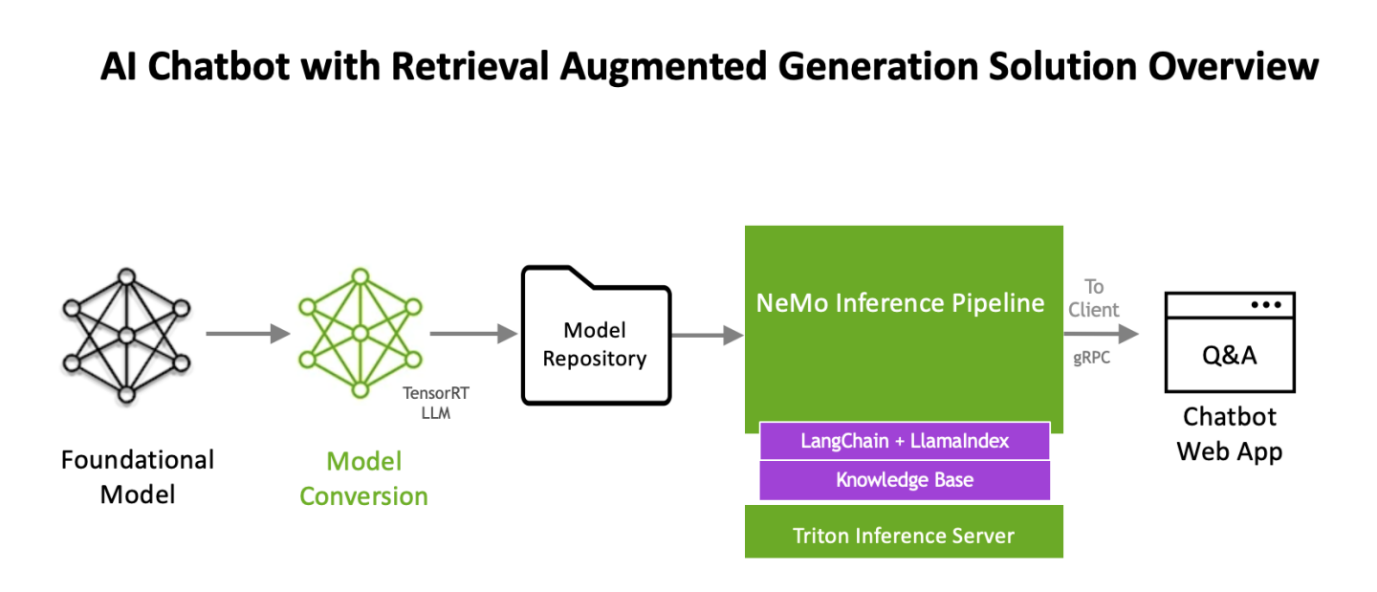
Quy trình làm việc sử dụng NVIDIA NeMo, một khuôn khổ để phát triển và tùy chỉnh các mô hình AI tạo sinh, cũng như phần mềm như NVIDIA Triton Inference Server và NVIDIA TensorRT-LLM để chạy các mô hình AI tạo sinh trong quá trình sản xuất.
Các thành phần phần mềm đều là một phần của NVIDIA AI Enterprise, một nền tảng phần mềm giúp đẩy nhanh quá trình phát triển và triển khai AI sẵn sàng đưa vào sản xuất với tính bảo mật, hỗ trợ và ổn định mà doanh nghiệp cần.
Nvidia đã công bố một quy trình làm việc tăng cường thu hồi dữ liệu như một ví dụ ứng dụng tại
https://resources.nvidia.com/en-us-generative-ai-chatbot-workflow/knowledge-base-chatbot-technical-brief
Ngoài ra, nó còn duy trì một trang git với thông tin cập nhật về cách triển khai nó trong Linux Docker, Kubernetes và Windows tại
https://github.com/NVIDIA/GenerativeAIExamples
Tiếp theo, chúng tôi sẽ hướng dẫn (ở cấp độ cao) quy trình sử dụng triển khai đường ống NVIDIA AI Enterprise Suite RAG bên dưới.
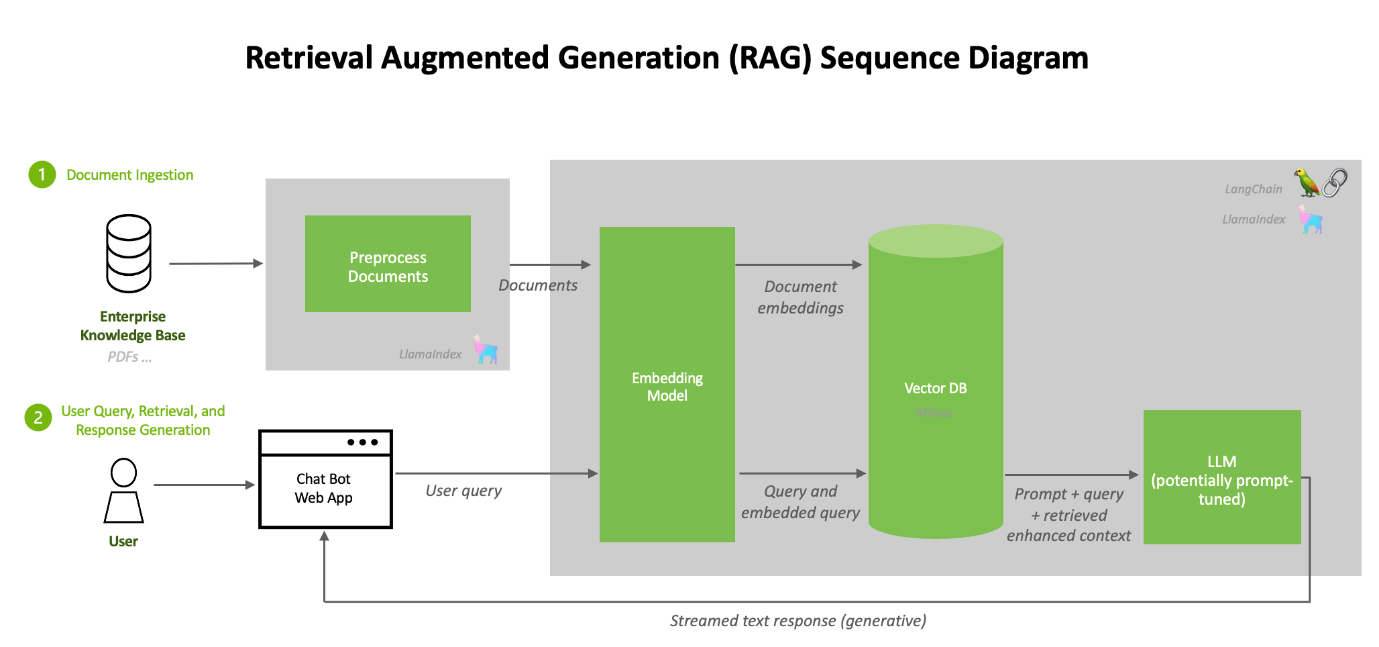
Quy trình này dựa trên tài liệu tại liên kết https://github.com/NVIDIA/GenerativeAIExamples/tree/v0.2.0/RetrievalAugmentedGeneration
Triển khai
Hướng dẫn dành cho nhà phát triển NVIDIA cung cấp hướng dẫn chi tiết để xây dựng chatbot Retrieval Augmented Generation (RAG) sử dụng mô hình Llama2 trên TRT-LLM. Hướng dẫn bao gồm các điều kiện tiên quyết như GPU NVIDIA, Docker, NVIDIA Container Toolkit, Tài khoản NGC và trọng số mô hình Llama2. Hướng dẫn cũng bao gồm các thành phần như Triton Model Server, Vector DB, API Server và Jupyter notebook để phát triển.
Các bước chính bao gồm thiết lập các thành phần này, tải lên tài liệu và tạo câu trả lời. Quy trình này được thiết kế cho chatbot doanh nghiệp, nhấn mạnh vào khả năng tùy chỉnh và tận dụng công nghệ AI của NVIDIA. Để biết chi tiết và hướng dẫn đầy đủ, vui lòng tham khảo hướng dẫn chính thức .
Các thành phần phần mềm chính và quy trình kiến trúc (để bắt đầu và chạy với sân chơi LLM)
1. Llama2 : Llama2 cung cấp khả năng xử lý ngôn ngữ tiên tiến, thiết yếu cho các tương tác chatbot AI phức tạp. Nó sẽ được chuyển đổi sang định dạng TensorRT-LLM.
Hãy nhớ rằng, chúng ta không thể lấy một mô hình từ HuggingFace và chạy trực tiếp trên TensorRT-LLM. Một mô hình như vậy sẽ cần trải qua giai đoạn chuyển đổi trước khi có thể tận dụng hết những ưu điểm của TensorRT-LLM. Chúng tôi vừa đăng một bài viết hướng dẫn chi tiết về cách thực hiện việc này thủ công tại đây . Tuy nhiên, (đừng lo lắng) như một phần của quy trình Docker Compose của LLM, tất cả những gì chúng ta cần làm là trỏ một trong các biến môi trường của mình đến mô hình llama. Nó sẽ tự động thực hiện quy trình chuyển đổi cho chúng ta! (Các bước được nêu trong phần triển khai của bài viết)
2. NVIDIA TensorRT-LLM : Khi nói đến việc tối ưu hóa các mô hình ngôn ngữ lớn, TensorRT-LLM là chìa khóa. Nó đảm bảo các mô hình mang lại hiệu suất cao và duy trì hiệu quả trong nhiều ứng dụng khác nhau.
- Thư viện bao gồm các kernel được tối ưu hóa, các bước tiền xử lý và hậu xử lý, cùng các nguyên hàm giao tiếp đa GPU/đa node. Các tính năng này được thiết kế đặc biệt để nâng cao hiệu suất trên GPU NVIDIA.
 Nó sử dụng tính song song tenxơ để suy luận hiệu quả trên nhiều GPU và máy chủ mà không cần sự can thiệp của nhà phát triển hoặc thay đổi mô hình.
Nó sử dụng tính song song tenxơ để suy luận hiệu quả trên nhiều GPU và máy chủ mà không cần sự can thiệp của nhà phát triển hoặc thay đổi mô hình.
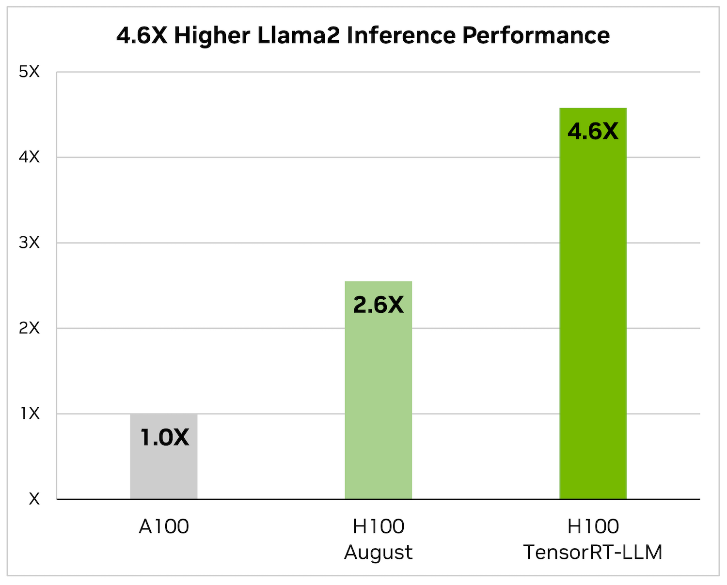
Chúng tôi sẽ cập nhật Hướng dẫn thiết kế AI tạo sinh trong doanh nghiệp – Suy luận – để phản ánh các yêu cầu về kích thước mới dựa trên TensorRT-LLM
3. LLM-inference-server: NVIDIA Triton Inference Server (container) : Việc triển khai các mô hình AI được đơn giản hóa với Triton Inference Server. Nó hỗ trợ khả năng mở rộng và phục vụ mô hình linh hoạt, điều này rất cần thiết để xử lý các khối lượng công việc AI phức tạp. Triton Inference Server chịu trách nhiệm lưu trữ mô hình Llama2 TensorRT-LLM.
Bây giờ chúng ta đã có mô hình nền tảng được tối ưu hóa, chúng ta cần xây dựng phần còn lại của quy trình làm việc RAG.
- Chain-server: langChain và LlamaIndex (container) : Cần thiết cho hoạt động của đường ống RAG. Một công cụ để kết nối các thành phần LLM với nhau. LangChain được sử dụng để kết nối các thành phần khác nhau như trình tải PDF và cơ sở dữ liệu vector, tạo điều kiện thuận lợi cho việc nhúng, vốn rất quan trọng đối với quy trình RAG.
4. Milvus (container) : Là một cơ sở dữ liệu vector tập trung vào AI, Milvus nổi bật nhờ khả năng quản lý lượng dữ liệu khổng lồ cần thiết trong các ứng dụng AI. Milvus là một cơ sở dữ liệu vector nguồn mở có khả năng tìm kiếm vector được tăng tốc bởi GPU NVIDIA.
5. e5-large-v2 (container) : Mô hình nhúng được thiết kế cho nhúng văn bản. Khi nội dung từ cơ sở tri thức được truyền đến mô hình nhúng (e5-large-v2), nó sẽ chuyển đổi nội dung thành các vectơ (được gọi là “nhúng”). Các nhúng này được lưu trữ trong cơ sở dữ liệu vectơ Milvus.
Mô hình nhúng như “e5-large-v2” được sử dụng hai lần trong quy trình làm việc RAG (Retrieval-Augmented Generation – Tạo dữ liệu tăng cường truy xuất) thông thường, nhưng cho các mục đích hơi khác nhau ở mỗi bước. Cách thức hoạt động như sau:
Việc sử dụng cùng một mô hình nhúng cho cả tài liệu và truy vấn của người dùng đảm bảo rằng các phép so sánh và tính toán độ tương đồng là nhất quán và có ý nghĩa, dẫn đến kết quả truy xuất có liên quan hơn.
Chúng ta sẽ nói về cách tạo “cung cấp ngữ cảnh cho mô hình ngôn ngữ để tạo phản hồi” trong phần quy trình làm việc nhắc nhở, nhưng trước tiên, hãy xem cách thức hoạt động của hai quy trình nhúng.
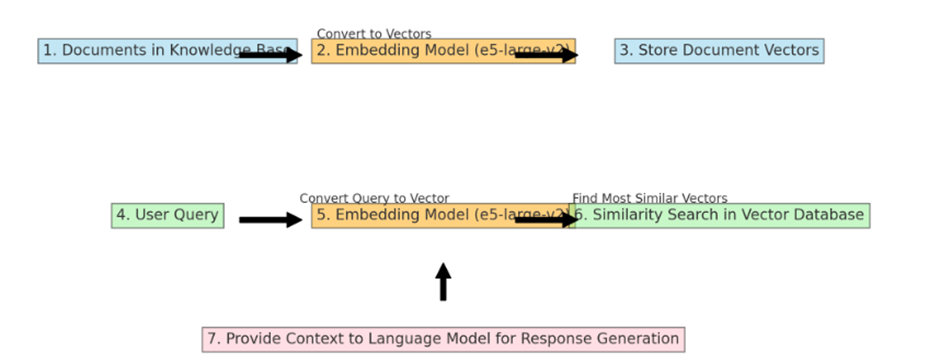
Chuyển đổi và Lưu trữ Vector Tài liệu: Đầu tiên, một mô hình nhúng xử lý toàn bộ tập hợp tài liệu trong cơ sở tri thức. Mỗi tài liệu được chuyển đổi thành một vector. Các vector này về cơ bản là các biểu diễn số của tài liệu, ghi lại nội dung ngữ nghĩa của chúng ở định dạng mà máy tính có thể xử lý hiệu quả. Sau khi được tạo, các vector này được lưu trữ trong cơ sở dữ liệu vector Milvus. Đây là một quy trình một lần, thường được thực hiện khi cơ sở tri thức được thiết lập ban đầu hoặc khi nó được cập nhật thông tin mới.
Xử lý Truy vấn Người dùng: Mô hình nhúng tương tự cũng được sử dụng để xử lý truy vấn người dùng. Khi người dùng gửi truy vấn, mô hình nhúng sẽ chuyển đổi truy vấn này thành một vectơ, tương tự như cách nó đã làm với các tài liệu. Điều quan trọng là truy vấn và tài liệu được chuyển đổi thành các vectơ trong cùng một không gian vectơ, cho phép so sánh có ý nghĩa.
Thực hiện Tìm kiếm Tương đồng: Sau khi truy vấn của người dùng được chuyển đổi thành một vectơ, vectơ truy vấn này được sử dụng để thực hiện tìm kiếm tương đồng trong cơ sở dữ liệu vectơ (chứa các vectơ của tài liệu). Hệ thống sẽ tìm kiếm các vectơ tài liệu tương đồng nhất với vectơ truy vấn. Trong ngữ cảnh này, tính tương đồng thường có nghĩa là các vectơ gần nhau trong không gian vectơ, ngụ ý rằng nội dung của tài liệu có liên quan về mặt ngữ nghĩa với truy vấn của người dùng.
Cung cấp ngữ cảnh nâng cao cho việc tạo phản hồi: Các tài liệu (hoặc một phần của chúng) tương ứng với các vectơ tương tự nhất sẽ được truy xuất và cung cấp cho mô hình ngôn ngữ dưới dạng ngữ cảnh. Ngữ cảnh này, cùng với truy vấn gốc của người dùng, giúp mô hình ngôn ngữ tạo ra phản hồi chính xác và có thông tin hơn.
6. Mạng container nvidia-LLM : Cho phép giao tiếp giữa các container.
7. Web Front End (LLM-playground container) Web Frontend cung cấp giao diện người dùng (UI) trên các API. LLM-playground container cung cấp một ứng dụng web chatbot mẫu. Các yêu cầu đến hệ thống trò chuyện được gói gọn trong các lệnh gọi FastAPI đến Triton Inference Server.
Quy trình làm việc nhanh chóng
Xây dựng một lời nhắc tăng cường : Bước tiếp theo là xây dựng một lời nhắc cho Mô hình Ngôn ngữ Lớn (LLM) cơ bản. Lời nhắc này thường bao gồm:
- Câu hỏi ban đầu của người dùng : Nêu rõ câu hỏi hoặc vấn đề.
- Ngữ cảnh được truy xuất : Thông tin liên quan được truy xuất từ cơ sở kiến thức. Ngữ cảnh này rất quan trọng vì nó cung cấp cho LLM những thông tin cụ thể mà có thể chưa được đào tạo hoặc có thể quá mới hoặc quá chi tiết so với dữ liệu đào tạo.
- Định dạng và Cấu trúc : Lời nhắc phải được định dạng và cấu trúc sao cho LLM có thể hiểu rõ thông tin nào đến từ truy vấn và thông tin nào là ngữ cảnh từ kết quả truy xuất. Điều này có thể bao gồm các mã thông báo hoặc dấu phân cách đặc biệt.
Cân nhắc về độ dài và độ phức tạp: Lời nhắc mở rộng có thể trở nên rất lớn, đặc biệt nếu ngữ cảnh được truy xuất quá rộng. Có một sự đánh đổi cần được cân nhắc ở đây:
Quá ít ngữ cảnh : Có thể không cung cấp đủ thông tin để LLM đưa ra phản hồi có căn cứ.
Quá nhiều ngữ cảnh : Điều này có thể làm cho LLM quá tải hoặc vượt quá giới hạn mã thông báo của nó, dẫn đến thông tin đầu vào bị cắt ngắn hoặc sự chú ý bị loãng trên lời nhắc.
Đưa lời nhắc đến LLM : Sau khi lời nhắc được xây dựng, nó sẽ được đưa đến LLM nền tảng. LLM sau đó xử lý lời nhắc này, xem xét cả truy vấn ban đầu của người dùng và ngữ cảnh được cung cấp.
Tạo phản hồi : LLM tạo ra phản hồi dựa trên lời nhắc tăng cường. Phản hồi này được kỳ vọng sẽ chính xác hơn, giàu thông tin hơn và phù hợp với ngữ cảnh hơn so với những gì LLM có thể tạo ra chỉ dựa trên truy vấn ban đầu, nhờ vào ngữ cảnh bổ sung do quy trình truy xuất cung cấp.
Hậu xử lý : Trong một số hệ thống, có thể có thêm một bước hậu xử lý phản hồi, chẳng hạn như tinh chỉnh, rút ngắn hoặc định dạng để phù hợp hơn với nhu cầu của người dùng.
Ví dụ về lời nhắc tăng cường: Định dạng này giúp mô hình ngôn ngữ hiểu câu hỏi cụ thể được hỏi và bối cảnh để trả lời câu hỏi đó, dẫn đến phản hồi chính xác và phù hợp hơn.
[Hỏi]: “Những tiến triển mới nhất trong việc điều trị bệnh Alzheimer tính đến năm 2024 là gì?”
[Bối cảnh – Nghiên cứu Memoriax]: “Một nghiên cứu đột phá được công bố vào năm 2023 đã chứng minh hiệu quả của một loại thuốc mới, Memoriax, trong việc làm chậm sự tiến triển của bệnh Alzheimer. Loại thuốc này nhắm vào các mảng bám amyloid trong não.”
[Bối cảnh – Sự chấp thuận của FDA]: “FDA đã chấp thuận một phương pháp điều trị bệnh Alzheimer mới vào cuối năm 2023, bao gồm thuốc và liệu pháp kích thích não có mục tiêu.”
[Bối cảnh – Nghiên cứu lối sống]: “Một nghiên cứu năm 2024 nhấn mạnh vai trò của chế độ ăn uống, tập thể dục và rèn luyện nhận thức trong việc làm chậm các triệu chứng của bệnh Alzheimer.”
Vui lòng cung cấp tổng quan về những diễn biến này và ý nghĩa của chúng đối với việc điều trị bệnh Alzheimer.
Triển khai XE9680
Các thành phần sau đây sẽ cần phải được cài đặt.
- Ít nhất một GPU NVIDIA A100 với Llama 2 7B vì nó yêu cầu khoảng 38GB bộ nhớ GPU, nên việc triển khai của chúng tôi được phát triển bằng cách sử dụng 8x H100 cho Llama2 70B trên XE9680
- Máy chủ XE9680 của chúng tôi đang chạy Ubuntu 22.04
- Trình điều khiển NVIDIA phiên bản 535 hoặc mới hơn.
- Docker, Docker-Compose và Docker-Buildx
Bước 1 – Đăng nhập vào NVIDIA GPU Cloud
Để ghi nhật ký docker trên NGC, bạn cần tạo người dùng và khóa truy cập. Vui lòng tham khảo hướng dẫn và chạy lệnh sau:
Đăng nhập Docker nvcr.io
Bước 2 – Tải xuống Trọng lượng Mô hình Trò chuyện Llama2
Trọng số Mô hình Trò chuyện Llama 2 cần được tải xuống từ Meta hoặc HuggingFace . Chúng tôi đã tải xuống các tệp trong quá trình triển khai và lưu trữ chúng trên Dell PowerScale F600. Máy chủ của chúng tôi có thể truy cập vào chia sẻ này với kết nối Eth 100Gb, cho phép chúng tôi thực hiện nhiều thí nghiệm đồng thời trên các máy chủ khác nhau. Sau đây là giao diện của thư mục chứa trọng số mô hình Llama 70b sau khi tải xuống:
fbronzati@node003:~$ ll /aipsf600/project-helix/models/Llama-2-70b-chat-hf/ -h
tổng cộng 295G
drwxrwxrwx 3 fbronzati ais 2.0K Jan 23 07:20 ./
drwxrwxrwx 9 nobody nogroup 221 23 tháng 1 07:20 ../
-rw-r—r—1 fbronzati ais 614 Dec 4 12:25 config.json
-rw-r—r—1 fbronzati ais 188 Dec 4 12:25 generation_config.json
drwxr-xr-x 9 fbronzati ais 288 Dec 4 14:04 .git/
-rw-r—r—1 fbronzati ais 1.6K Dec 4 12:25 .gitattributes
-rw-r—r—1 fbronzati ais 6.9K 4 tháng 12 12:25 LICENSE.txt
-rw-r—r—1 fbronzati ais 9.2G Dec 4 12:40 model-00001-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:09 model-00002-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.3G Dec 4 12:30 model-00003-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:21 model-00004-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:14 model-00005-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:12 model-00006-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.3G Dec 4 12:55 model-00007-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:24 model-00008-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:00 model-00009-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:11 model-00010-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.3G Dec 4 12:22 model-00011-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:17 model-00012-of-00015.safetensors
-rw-r—r—1 fbronzati ais 9.2G Dec 4 13:02 model-00013-of-00015.safetensors
-rw-r—r—1 fbronzati ais 8.9G Dec 4 13:22 model-00014-of-00015.safetensors
-rw-r—r—1 fbronzati ais 501M Dec 4 13:17 model-00015-of-00015.safetensors
-rw-r—r—1 fbronzati ais 7.1K 4 tháng 12 12:25 MODEL_CARD.md
-rw-r—r—1 fbronzati ais 66K 4 tháng 12 12:25 model.safetensors.index.json
-rw-r—r—1 fbronzati ais 9.2G 4 tháng 12 12:52 pytorch_model-00001-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G 4 tháng 12 12:25 pytorch_model-00002-of-00015.bin
-rw-r—r—1 fbronzati ais 9.3G 4 tháng 12 12:46 pytorch_model-00003-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G 4 tháng 12 13:07 pytorch_model-00004-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G 4 tháng 12 12:49 pytorch_model-00005-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G 4 tháng 12 12:58 pytorch_model-00006-of-00015.bin
-rw-r—r—1 fbronzati ais 9.3G 4 tháng 12 12:34 pytorch_model-00007-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G 4 tháng 12 13:15 pytorch_model-00008-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G 4 tháng 12 13:05 pytorch_model-00009-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G 4 tháng 12 13:08 pytorch_model-00010-of-00015.bin
-rw-r—r—1 fbronzati ais 9.3G 4 tháng 12 12:28 pytorch_model-00011-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G 4 tháng 12 13:18 pytorch_model-00012-of-00015.bin
-rw-r—r—1 fbronzati ais 9.2G 4 tháng 12 13:04 pytorch_model-00013-of-00015.bin
-rw-r—r—1 fbronzati ais 8.9G 4 tháng 12 13:20 pytorch_model-00014-of-00015.bin
-rw-r—r—1 fbronzati ais 501M 4 tháng 12 13:20 pytorch_model-00015-of-00015.bin
-rw-r—r—1 fbronzati ais 66K 4 tháng 12 12:25 pytorch_model.bin.index.json
-rw-r—r—1 fbronzati ais 9.8K Dec 4 12:25 README.md
-rw-r—r—1 fbronzati ais 1.2M Dec 4 13:20 Responsible-Use-Guide.pdf
-rw-r—r—1 fbronzati ais 414 Dec 4 12:25 special_tokens_map.json
-rw-r—r—1 fbronzati ais 1.6K 4 tháng 12 12:25 tokenizer_config.json
-rw-r—r—1 fbronzati ais 1.8M 4 tháng 12 12:25 tokenizer.json
-rw-r—r—1 fbronzati ais 489K 4 tháng 12 13:20 tokenizer.model
-rw-r–r– 1 fbronzati ais 4.7K 4 tháng 12 12:25 USE_POLICY.md
Bước 3 – Sao chép nội dung GitHub
Chúng ta cần tạo một thư mục làm việc mới và sao chép kho lưu trữ git bằng lệnh sau:
fbronzati@node003:/aipsf600/project-helix/rag$ git clone https://github.com/NVIDIA/GenerativeAIExamples.git
fbronzati@node003:/aipsf600/project-helix/rag$ cd GenerativeAIExamples
fbronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ git checkout tags/v0.2.0
Bước 4 – Thiết lập Biến Môi trường
Để triển khai quy trình làm việc, chúng tôi sử dụng Docker Compose , cho phép bạn định nghĩa và quản lý các ứng dụng đa container trong một tệp YAML duy nhất. Điều này giúp đơn giản hóa nhiệm vụ phức tạp là sắp xếp và điều phối các dịch vụ khác nhau, giúp việc quản lý và sao chép môi trường ứng dụng của bạn dễ dàng hơn.
Để điều chỉnh việc triển khai, bạn cần chỉnh sửa tệp compose.env bằng thông tin về môi trường của bạn, thông tin như thư mục bạn đã tải xuống mô hình, tên mô hình, GPU nào sẽ sử dụng, v.v., tất cả đều có trong tệp, bạn sẽ cần sử dụng trình soạn thảo văn bản ưa thích của mình, sau đó chúng tôi sử dụng vi với lệnh:
fbronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ vi triển khai/compose/compose.env
Biến Dell XE9680
Dưới đây, chúng tôi cung cấp biến được sử dụng để triển khai quy trình làm việc trên Dell PowerEdge XE9680.
” export MODEL_DIRECTORY=”/aipsf600/project-helix/models/Llama-2-70b-chat-hf/ ” Đây là nơi chúng ta trỏ đến mô hình đã tải xuống từ hugging face – mô hình sẽ tự động được chuyển đổi sang định dạng tensorR-TLLM khi các container được triển khai bằng các tập lệnh trợ giúp
fbronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ triển khai cat/compose/compose.env
# đường dẫn đầy đủ đến bản sao cục bộ của trọng số mô hình
# LƯU Ý: Đây phải là đường dẫn tuyệt đối chứ không phải đường dẫn tương đối
xuất MODEL_DIRECTORY=”/aipsf600/project-helix/models/Llama-2-70b-chat-hf/”
# Điền vào đây nếu bạn không có GPU. Để trống nếu bạn có GPU cục bộ
#export AI_PLAYGROUND_API_KEY=””
# cờ để kích hoạt lượng tử hóa nhận biết kích hoạt cho LLM
# xuất QUANTIZATION=”int4_awq”
# kiến trúc của mô hình. ví dụ: lạc đà không bướu
xuất MODEL_ARCHITECTURE=”llama”
# tên của mô hình đang được sử dụng – chỉ để hiển thị trên giao diện
xuất MODEL_NAME=”Llama-2-70b-chat-hf”
# [TÙY CHỌN] số lượng mã thông báo đầu vào tối đa
xuất MODEL_MAX_INPUT_LENGTH=3000
# [TÙY CHỌN] số lượng mã thông báo đầu ra tối đa
xuất MODEL_MAX_OUTPUT_LENGTH=512
# [TÙY CHỌN] số lượng GPU có sẵn cho máy chủ suy luận
xuất khẩu INFERENCE_GPU_COUNT=”tất cả”
# [TÙY CHỌN] thư mục cơ sở bên trong đó tất cả các ổ đĩa liên tục sẽ được tạo
# xuất DOCKER_VOLUME_DIRECTORY=”.”
# [TÙY CHỌN] tệp cấu hình cho máy chủ chuỗi wrt pwd
xuất APP_CONFIG_FILE=/dev/null
Bước 5 – Xây dựng và khởi động các thùng chứa
Vì kho lưu trữ git có các tệp lớn nên chúng tôi sử dụng lệnh git lfs pull để tải xuống các tệp từ kho lưu trữ:
fbronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ nguồn triển khai/compose/compose.env; docker-compose -f triển khai/compose/docker-compose.yaml xây dựng
Sau đó, chúng ta chạy lệnh sau để xây dựng hình ảnh container docker:
fbronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ nguồn triển khai/compose/compose.env; docker-compose -f triển khai/compose/docker-compose.yaml xây dựng
Và cuối cùng, bằng lệnh tương tự, chúng ta triển khai các container:
fbronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ nguồn triển khai/compose/compose.env; docker-compose -f triển khai/compose/docker-compose.yaml up -d
CẢNH BÁO: Biến AI_PLAYGROUND_API_KEY chưa được đặt. Mặc định là một chuỗi trống. Đang tạo mạng “nvidia-LLM” với trình điều khiển mặc định Đang tạo milvus-etcd … xong Đang tạo milvus-minio … xong Đang tạo LLM-inference-server … xong Đang tạo milvus-standalone … xong Đang tạo evaluation … xong Đang tạo notebook-server … xong Đang tạo chain-server … xong Đang tạo LLM-playground … xong
Việc triển khai sẽ mất vài phút để hoàn tất, tùy thuộc vào kích thước của LLM bạn đang sử dụng. Trong trường hợp của chúng tôi, mất khoảng 9 phút để khởi chạy vì chúng tôi sử dụng mô hình 70B:
f bronzati@node003:/aipsf600/project-helix/rag/GenerativeAIExamples$ docker ps -a ID CONTAINER IMAGE COMMAND CREATED STATUS PORTS NAMES ae34eac40476 LLM-playground:latest “python3 -m frontend…” 9 phút trước Đã hoạt động 9 phút 0.0.0.0:8090->8090/tcp, :::8090->8090/tcp LLM-playground a9b4996e0113 chain-server:latest “uvicorn RetrievalAu…” 9 phút trước Đã hoạt động 9 phút 6006/tcp, 8888/tcp, 0.0.0.0:8082->8082/tcp, :::8082->8082/tcp chain-server 7b617f11d122 đánh giá: phiên bản mới nhất “jupyter lab –allow…” 9 phút trước Đã hoạt động 9 phút 0.0.0.0:8889->8889/tcp, :::8889->8889/tcp đánh giá 8f0e434b6193 máy chủ sổ tay: phiên bản mới nhất “jupyter lab –allow…” 9 phút trước Đã hoạt động 9 phút 0.0.0.0:8888->8888/tcp, :::8888->8888/tcp máy chủ sổ tay 23bddea51c61 milvusdb/milvus:v2.3.1-gpu “/tini — milvus run…” 9 phút trước Đã hoạt động 9 phút (ổn định) 0.0.0.0:9091->9091/tcp, :::9091->9091/tcp, 0.0.0.0:19530->19530/tcp, :::19530->19530/tcp milvus-standalone f1b244f93246 LLM-inference-server:latest “/usr/bin/python3 -m…” 9 phút trước Đã hoạt động 9 phút (ổn định) 0.0.0.0:8000-8002->8000-8002/tcp, :::8000-8002->8000-8002/tcp LLM-inference-server 89aaa3381cf8 minio/minio:RELEASE.2023-03-20T20-16-18Z “/usr/bin/docker-ent…” 9 phút trước Đã hoạt động 9 phút (ổn định) 0.0.0.0:9000-9001->9000-9001/tcp, :::9000-9001->9000-9001/tcp milvus-minio ecec9d808fdc quay.io/coreos/etcd:v3.5.5 “etcd -advertise-cli…” 9 phút trước Đã hoạt động 9 phút (ổn định) 2379-2380/tcp
Truy cập sân chơi LLM
Container LLM-playground cung cấp một ứng dụng web chatbot mẫu trong quy trình làm việc. Các yêu cầu gửi đến hệ thống trò chuyện được gói gọn trong các lệnh gọi FastAPI đến container LLM-inference-server đang chạy máy chủ suy luận Triton với Llama 70B đã được tải.
Mở ứng dụng web tại http://host-ip:8090.
Chúng ta hãy thử xem nhé!
Một lần nữa, chúng tôi đã dành thời gian để trình diễn Llama2 chạy trên NVIDIA LLM playground trên XE9680 với 8 GPU H100. LLM playground được hỗ trợ bởi máy chủ Triton Inference của NVIDIA (nơi lưu trữ mô hình llama).
Chúng tôi hy vọng đã cho bạn thấy rằng LLM Playground của NVIDIA, một phần của khuôn khổ NeMo, là một nền tảng sáng tạo để thử nghiệm và triển khai các mô hình ngôn ngữ lớn (LLM) cho nhiều ứng dụng doanh nghiệp khác nhau. Đồng thời, chúng tôi cung cấp:
- Tùy chỉnh LLM được đào tạo trước : Cho phép tùy chỉnh các mô hình ngôn ngữ lớn được đào tạo trước bằng cách sử dụng các kỹ thuật điều chỉnh p cho các trường hợp sử dụng hoặc nhiệm vụ cụ thể theo miền.
- Thí nghiệm với đường ống RAG
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...