
Những điểm chính cần ghi nhớ :
- Giải pháp chuyển tải bộ nhớ đệm KV có khả năng mở rộng của Dell, được hỗ trợ bởi PowerScale và ObjectScale, mang lại Thời gian đến mã thông báo đầu tiên (TTFT) nhanh hơn tới 19 lần so với vLLM tiêu chuẩn, cho phép hiệu suất suy luận cao hơn và thời gian phản hồi truy vấn thấp hơn .
- Giải pháp của Dell giúp giải phóng tài nguyên GPU, chuyển bộ nhớ đệm KV sang bộ nhớ hiệu năng cao, khắc phục tình trạng tắc nghẽn bộ nhớ và cải thiện hiệu suất. Các bài kiểm tra điểm chuẩn cho thấy bộ nhớ của Dell vượt trội hơn các đối thủ cạnh tranh như VAST, mang lại khả năng tăng tốc nhanh hơn và hiệu suất tốt hơn .
- Ngoài khả năng suy luận, Nền tảng dữ liệu AI (AIDP) của Dell còn đơn giản hóa toàn bộ vòng đời dữ liệu AI—từ dữ liệu thô đến việc tạo ra kiến thức—giúp các tổ chức vận hành AI ở quy mô lớn.
Các Mô hình Ngôn ngữ Lớn (LLM) đang chuyển đổi hoạt động kinh doanh, từ việc nâng cao tương tác với khách hàng đến đẩy nhanh quá trình tạo nội dung. Khi các mô hình AI này trở nên mạnh mẽ hơn, nhu cầu tính toán của chúng cũng tăng lên, tạo ra một thách thức đáng kể: các điểm nghẽn hiệu suất có thể làm chậm tiến độ và làm tăng chi phí. Nhiều tổ chức tin rằng giải pháp duy nhất là bổ sung các GPU đắt tiền và ngốn điện hơn.
Có một hướng đi thông minh hơn, tiết kiệm chi phí hơn. Chìa khóa nằm ở việc tối ưu hóa một quy trình gọi là Bộ nhớ đệm Khóa-Giá trị (KV). Bằng cách chuyển bộ nhớ đệm KV từ bộ nhớ GPU sang bộ nhớ hiệu năng cao và truy xuất nó thay vì tính toán lại, bạn có thể cải thiện đáng kể hiệu suất, giảm độ trễ và mang lại lợi nhuận cao hơn cho khoản đầu tư AI của mình.
Bài viết này giới thiệu giải pháp giảm tải bộ nhớ đệm KV Cache hàng đầu của Dell. Chúng tôi sẽ cho bạn thấy cách các Công cụ Lưu trữ hiệu suất cao, có khả năng mở rộng của chúng tôi giúp bạn triển khai các LLM quy mô lớn với hiệu quả cao hơn và chi phí thấp hơn.
Chi phí cao của AI kém hiệu quả
Để hiểu giải pháp, trước tiên chúng ta cần xem xét vấn đề. Trong suy luận LLM, Bộ nhớ đệm KV lưu trữ các phép tính trung gian, do đó mô hình không phải tính toán lại cùng một thông tin cho mỗi mã thông báo mới được tạo ra. Điều này giúp tăng tốc thời gian phản hồi, được đo bằng Thời gian đến Mã thông báo Đầu tiên (TTFT).
Tuy nhiên, khi số lượng mô hình tăng lên và nhu cầu của người dùng tăng lên, KV Cache có thể ngốn hàng gigabyte, thậm chí hàng terabyte bộ nhớ. Điều này nhanh chóng làm quá tải bộ nhớ GPU, dẫn đến hai hậu quả không mong muốn:
- Giảm hiệu suất : Hệ thống của bạn chậm lại, gây ra trải nghiệm kém cho người dùng.
- Khối lượng công việc không thành công : Tình trạng tắc nghẽn dung lượng bộ nhớ khiến các tiến trình bị lỗi hoàn toàn.
Giải pháp thông thường là tăng khả năng tính toán và tài nguyên bộ nhớ. Cách tiếp cận này tạo ra một chu kỳ chi phí leo thang, tiêu thụ điện năng tăng và cơ sở hạ tầng phức tạp hơn. Nó giải quyết triệu chứng chứ không phải nguyên nhân gốc rễ, và cuối cùng làm giảm ROI AI của bạn.
Một bước đột phá trong hiệu quả AI: lưu trữ là giải pháp
Dell cung cấp một giải pháp thay thế mang tính đột phá: chuyển giao bộ nhớ đệm KV sang các công cụ lưu trữ AI hiệu suất cao của chúng tôi. Thay vì chỉ dựa vào khả năng mở rộng tính toán, bạn có thể nâng cao khoản đầu tư GPU bằng cách tận dụng bộ lưu trữ có khả năng mở rộng, tiết kiệm chi phí – mang lại cơ sở hạ tầng AI hiệu quả và bền vững hơn.
Bộ phần mềm đã được chúng tôi kiểm chứng, bao gồm công cụ suy luận vLLM, LMCache với đầu nối Dell tích hợp, và thư viện truyền dữ liệu NIXL từ NVIDIA Dynamo – được Dell mở rộng với plugin S3-over-RDMA cho ObjectScale. Bộ phần mềm này tích hợp liền mạch với danh mục lưu trữ của Dell – PowerScale và ObjectScale. Với khả năng hỗ trợ cả lưu trữ tệp và lưu trữ đối tượng, bạn có thể chọn giải pháp phù hợp nhất cho môi trường và khối lượng công việc của mình.
Chiến lược này cho phép bạn mở rộng dung lượng bộ nhớ đệm KV vượt xa giới hạn của bộ nhớ GPU. Đây là giải pháp đột phá cho các tổ chức muốn mở rộng quy mô suy luận LLM một cách hiệu quả, tiết kiệm và bền vững.
Hiệu suất nói lên tất cả
Chúng tôi đã đánh giá hiệu suất của bộ vLLM + LMCache + NVIDIA NIXL để đo thời gian đạt được mã thông báo đầu tiên (TTFT) với tỷ lệ truy cập bộ nhớ đệm KV là 100%. Kịch bản này phân tách hiệu quả của việc truy xuất bộ nhớ đệm KV đã được điền sẵn đầy đủ từ bộ nhớ ngoài. Các thử nghiệm được chạy trên 4 GPU NVDIA H100 trên các hệ thống lưu trữ backend của Dell.
Chúng tôi đã so sánh giải pháp chuyển tải lưu trữ của mình với giải pháp cơ sở trong đó Bộ nhớ đệm KV được tính toán từ đầu trên GPU, sử dụng LLaMA-3.3-70B Instruct, với Tensor Parallelism=4 (Hình 1).
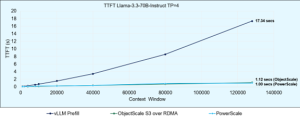
Kết quả thật đáng chú ý:
- Các công cụ lưu trữ của Dell—PowerScale và ObjectScale—đã cung cấp TTFT trong 1 giây ở cửa sổ ngữ cảnh đầy đủ gồm 131K mã thông báo.
- Điều này thể hiện sự cải thiện gấp 19 lần so với cấu hình vLLM tiêu chuẩn, vốn mất hơn 17 giây ở cùng kích thước ngữ cảnh.
- Ngay cả ở kích thước ngữ cảnh nhỏ là 1K mã thông báo, cả ba công cụ Dell đều truy xuất Bộ nhớ đệm KV từ bộ lưu trữ nhanh hơn tốc độ tính toán trên GPU, làm nổi bật hiệu quả độ trễ thấp của giải pháp của chúng tôi.
Việc giảm TTFT đáng kể này giúp giảm thiểu chi phí, cho phép tạo mã thông báo nhanh hơn và cuối cùng cải thiện khả năng sử dụng GPU và thông lượng suy luận tổng thể.
Giải pháp của Dell so với đối thủ cạnh tranh như thế nào
Chúng tôi cũng đã chạy thử nghiệm TTFT bằng mô hình Qwen3-32B để so sánh trực tiếp giải pháp của Dell với giải pháp của đối thủ cạnh tranh. Kết quả cho thấy PowerScale (0,82 giây) và ObjectScale (0,86 giây), cả hai đều vượt trội hơn VAST (1,5 giây) trong TTFT – đồng thời tăng tốc lên đến 14 lần so với vLLM tiêu chuẩn mà không cần giảm tải KV Cache (11,8 giây)¹.
Trong khi giải pháp của VAST chứng minh được khả năng tăng tốc, thì công cụ lưu trữ của Dell lại mang lại khả năng tăng tốc cao hơn và thời gian phản hồi truy vấn thấp hơn so với VAST¹.
Định hình tương lai của cơ sở hạ tầng AI
Việc chuyển tải bộ nhớ đệm KV không chỉ là một công cụ tối ưu hóa hiệu suất đáng kể cho khối lượng công việc hiện nay; nó còn là một khả năng nền tảng cho tương lai của AI. Những kết quả này chứng minh rằng giải pháp lưu trữ và truy xuất bộ nhớ đệm KV với các công cụ lưu trữ của Dell cho phép các tổ chức đạt được hiệu suất suy luận vượt trội. Để tìm hiểu sâu hơn về phương pháp luận và cấu hình thử nghiệm của chúng tôi, vui lòng xem blog kỹ thuật đầy đủ của chúng tôi .
Với Nền tảng Dữ liệu AI (AIDP) của Dell, chúng tôi không chỉ dừng lại ở khả năng tăng tốc suy luận. AIDP giải quyết toàn bộ vòng đời dữ liệu cho AI, đơn giản hóa hành trình của khách hàng từ dữ liệu thô đến dữ liệu đã chuyển đổi, đến việc tạo ra kiến thức, và cuối cùng là tăng tốc các mô hình suy luận và ứng dụng tác tử.
Giải pháp mở và mô-đun của Dell hỗ trợ mọi giai đoạn của vòng đời AI—từ thu thập dữ liệu đến đào tạo mô hình, suy luận và triển khai. Bằng cách kết hợp các công cụ lưu trữ hiệu suất cao của Dell, như PowerScale và ObjectScale, với các công cụ dữ liệu tiên tiến và tích hợp liền mạch với NVIDIA, Nền tảng Dữ liệu AI của Dell cho phép các tổ chức vận hành AI ở quy mô lớn.
Bạn đã sẵn sàng biến dữ liệu thành kết quả chưa? Hãy cùng lên lịch hội thảo để khám phá cách Nền tảng Dữ liệu AI của Dell có thể hỗ trợ trường hợp sử dụng cụ thể của bạn.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...