
Tin tức
Hiệu suất Động lực học phân tử ở cấp độ nano (NAMD) với GPU Dell EMC PowerEdge R750xa & NVIDIA A series
Tổng quan
Trong thập kỷ qua, GPU đã trở nên phổ biến trong điện toán khoa học vì khả năng tuyệt vời của chúng trong việc khai thác mức độ song song cao. NVIDIA đã tối ưu hóa các ứng dụng khoa học đời sống để chạy trên các GPU đa năng của họ. Thật không may, những GPU này chỉ có thể được lập trình với CUDA, OpenACC hoặc khung OpenCL. Hầu hết cộng đồng khoa học đời sống không quen thuộc với các khuôn khổ này nên rất ít nhà sinh vật học hoặc nhà tin sinh học có thể sử dụng hiệu quả kiến trúc GPU. Tuy nhiên, GPU đã xâm nhập vào lĩnh vực mô phỏng động lực học phân tử (MDS) kể từ khi MD được phát triển vào những năm 1950. MDS yêu cầu công việc tính toán nặng nề để mô phỏng các cấu trúc phân tử sinh học hoặc các tương tác của chúng.
Trong blog này, hiệu suất của một ứng dụng MDS phổ biến, NAMD , được trình bày với nhiều GPU NVIDIA A-series như A100, A10, A30 và A40 . NAMD là gói MD song song mã nguồn mở và miễn phí được thiết kế để phân tích các chuyển động vật lý của nguyên tử và phân tử.
Dell Technologies đã phát hành máy chủ PowerEdge R750xa mới , một nền tảng khối lượng công việc GPU được thiết kế để hỗ trợ trí tuệ nhân tạo, máy học và các giải pháp điện toán hiệu năng cao. Nền tảng ổ cắm kép/2U hỗ trợ Bộ xử lý có thể mở rộng Intel Xeon thế hệ thứ 3 (tên mã là Ice Lake). Nó hỗ trợ tối đa 40 lõi trên mỗi bộ xử lý, có tám kênh bộ nhớ trên mỗi CPU và tối đa 32 DIMM DDR4 ở tốc độ DIMM 3200 MT/s. Máy chủ này có thể chứa tối đa bốn GPU PCIe hai chiều được đặt ở phía trước bên trái và phía trước bên phải của máy chủ. Cấu hình máy chủ thử nghiệm được tóm tắt trong Bảng 1 và thông số kỹ thuật của GPU NVIDIA thử nghiệm được liệt kê trong Bảng 2.
Bảng 1: Cấu hình nút điện toán đã thử nghiệm
| giường thử nghiệm | ||||
| Người phục vụ | Dell EMC PowerEdge R750xa | Dell EMC PowerEdge R740 | ||
| CPU | CPU Intel(R) Xeon(R) Platinum 8380 @ 2,30 GHz | CPU Intel(R) Xeon(R) Platinum 8360Y @ 2,40 GHz | CPU Intel(R) Xeon(R) Vàng 6248 @ 2,50 GHz | |
| GPU NVIDIA | 4 x A100 | 4 x A10 | 4 x A30 | 2 x A40 |
| ĐẬP | DDR4 1024 GB (32 x 32 GB) 3200 tấn/giây | DDR4 384 GB (24 x 16 GB) 2933 tấn/giây | ||
| Hệ điều hành | RHEL 8.3 (4.18.0-240.el8.x86_64) | |||
| mạng hệ thống tập tin | Mellanox InfiniBand HDR100 | |||
| Hệ thống tập tin | Giải pháp sẵn sàng của Dell EMC cho Bộ lưu trữ dung lượng cao HPC BeeGFS | |||
| Hồ sơ hệ thống BIOS | Hiệu suất được tối ưu hóa | |||
| bộ xử lý logic | Vô hiệu hóa | |||
| công nghệ ảo hóa | Vô hiệu hóa | |||
| Cuda/Bộ công cụ | 11.2 | |||
| OpenMPI | 4.1.1 | |||
| NAMD | NAMD_Git-2021-04-01_Source | |||
Bảng 2: Thông số kỹ thuật của GPU NVIDIA đã thử nghiệm
| GPU NVIDIA | ||||
| A100 | A10 | A30 | A40 | |
| FP64 (TFLOPS) | 9,7 | không xác định | 5.2 | không xác định |
| Lõi căng FP64 (TFLOPS) | 19,5 | không xác định | 10.3 | không xác định |
| FP32 (TFLOPS) | 19,5 | 31.2 | 10.3 | 37,4 |
| Tenor Float 32 (TFLOPS) | 156 | 312* | 62,5 | 125* | 82 | 165 * | 74,8 | 149,6* |
| Lõi căng BFLOAT16 (TFLOPS) | 312 | 624* | 125 | 250* | 165 | 330* | 149,7 | 299,4* |
| Lõi căng FP16 (TFLOPS) | 312 | 624* | 125 | 250* | 165 | 330* | 149,7 | 299,4* |
| Lõi Tenor INT8 (TOPS) | 624 | 1248* | 250 | 500* | 330 | 661* | 299.3 | 598,6* |
| Lõi Tenor INT4 (TOPS) | không xác định | 500 | 1.000* | 661 | 1321* | 598.7 | 1.197,4* |
| bộ nhớ GPU | 40GB HBM2 | 24GB GDDR6 | 24GB HBM2 | 48GB GDDR6 |
| Băng thông bộ nhớ GPU | 1.555 GB/giây | 600GB/giây | 933 GB/giây | 696GB/giây |
| Công suất thiết kế nhiệt tối đa (TDP) | 400W | 150W | 165W | 300W |
| GPU đa phiên bản | Lên đến 7 MIG @ 5 GB | không xác định | 4 phiên bản GPU @ 6 GB mỗi phiên bản
2 phiên bản GPU @ 12 GB mỗi phiên bản 1 phiên bản GPU @ 24 GB |
không xác định |
| Yếu tố hình thức | PCIe | Một khe, toàn chiều cao, toàn chiều (FHFL) | Khe kép, chiều cao đầy đủ, chiều dài đầy đủ (FHFL) | Khe kép 4,4″ (H) x 10,5″ (L) |
| kết nối | PCIe Gen4:
64GB/giây |
PCIe Gen4:
64GB/giây |
PCIe Gen4:
64GB/giây
|
PCIE Gen4 x 16 31,5 GB/giây (hai chiều) |
* Với sự thưa thớt
Đánh giá hiệu suất
NAMD
NAMD được biên dịch từ mã nguồn (NAMD_Git-2021-04-01_Source) bằng GCC 11.1 và CUDA 11.2. Chúng tôi đã sử dụng một bộ dữ liệu thử nghiệm, hệ thống 1,06 triệu nguyên tử của vi rút khảm thuốc lá vệ tinh (SMTV).
Hình 1 cho thấy hiệu suất của bốn GPU với bộ dữ liệu STMV. Các số liệu thể hiện những thay đổi về hiệu suất tính bằng nano giây mỗi ngày (ns/ngày) với nhiều số lượng lõi khác nhau được sử dụng với một, hai hoặc bốn GPU. Sự so sánh hợp lệ duy nhất giữa các GPU khác nhau là NVIDIA A100 và A10 do các hệ thống thử nghiệm được cấu hình giống hệt nhau. Mặc dù hiệu suất của NAMD bị ảnh hưởng bởi tốc độ xung nhịp của CPU, nhưng các hệ thống được thử nghiệm không có sự khác biệt đáng kể về tốc độ xung nhịp của CPU. A10 được đánh giá có FLOPS chính xác đơn cao gấp ba lần so với A30 và A10 hoạt động tốt hơn A30 trong hai bài kiểm tra GPU ngay cả với CPU chậm hơn một chút. A100 vượt trội hơn khoảng 25% và 16% trong các bài kiểm tra GPU đơn và hai GPU khi so sánh kết quả của A10 tương ứng.
Kết quả từ bốn thử nghiệm GPU trong Hình 1 cho thấy hiệu suất tương tự đối với các GPU khác nhau. Điều này rất phù hợp với kết quả thử nghiệm trước đây của chúng tôi rằng NAMD không mở rộng quy mô sau hai GPU. Chúng ta có thể loại trừ một lập luận tiềm năng rằng kích thước dữ liệu có thể quá nhỏ vì 3 triệu dữ liệu nguyên tử, hệ thống nguyên tử HECBioSim3000k , là một cặp tứ giác 1IVO và 1NQL hEGFR, hiển thị kết quả tương tự hoặc tệ hơn (những kết quả đó không được hiển thị ở đây) .
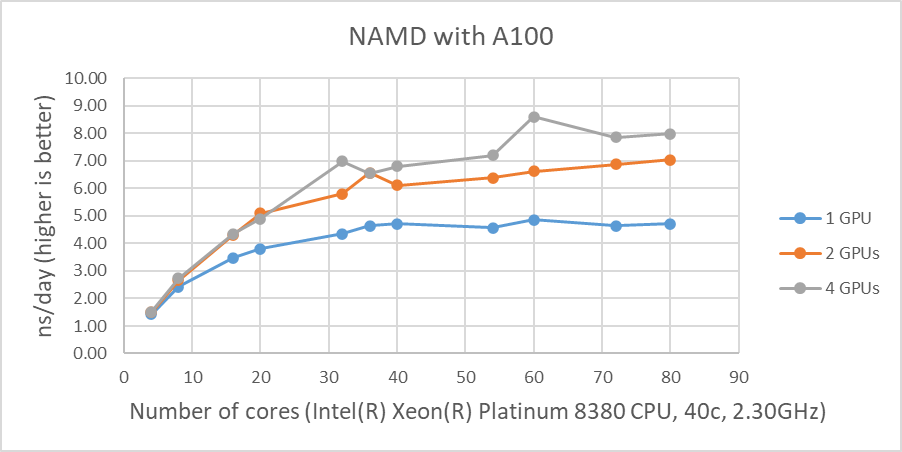
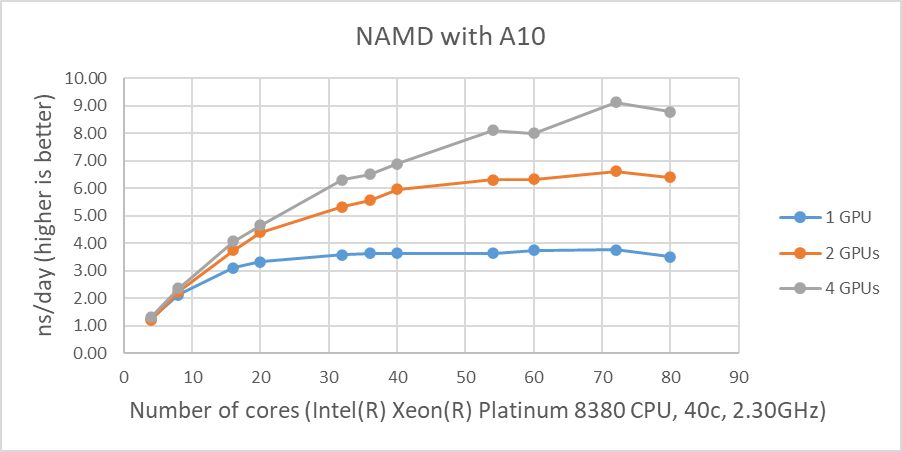
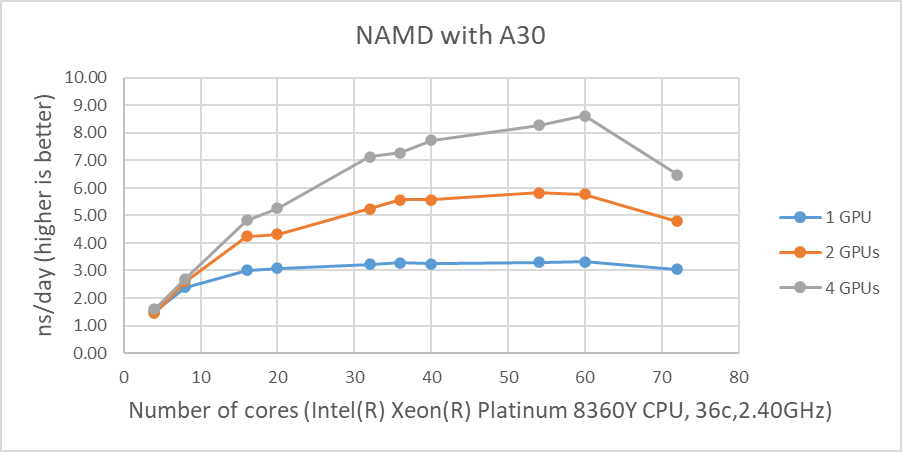
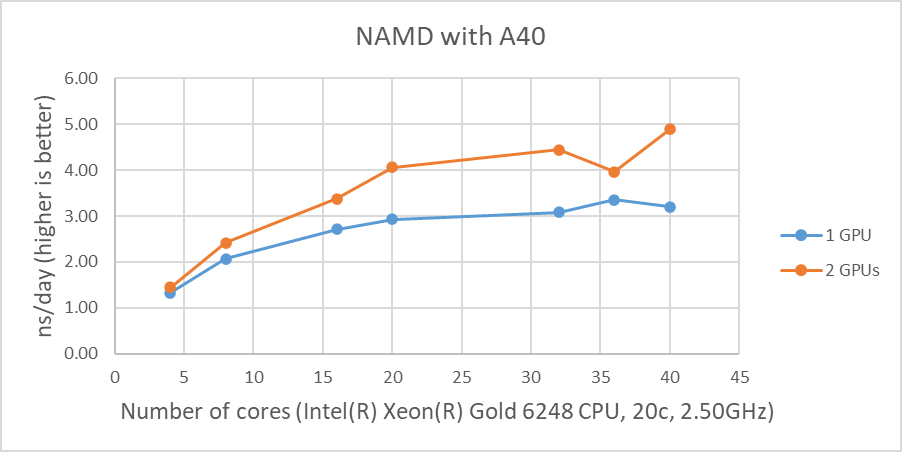
| Hình 1: Hiệu suất NAMD với STMV, hệ thống 1 triệu nguyên tử |
Như được hiển thị trong Hình 1, khi bốn GPU được thử nghiệm , tất cả các GPU ngoại trừ A40 đều đạt ~9 ns/ngày mô phỏng. Và xét về hiệu suất tối đa, A10 thực hiện số lượng mô phỏng cao nhất, 9,121 ns/ngày. Tuy nhiên, những con số này không phản ánh đúng hiệu suất do những hạn chế về khả năng mở rộng. Mặc dù cả bốn kết quả kiểm tra GPU đều tương tự nhau nhưng A100 có thông lượng tốt hơn so với các GPU khác đối với bài kiểm tra hai GPU như trong Hình 2. Ngoài ra, điều đáng chú ý là A10 và A40 không phù hợp với máy tính đa năng do đến việc thiếu hỗ trợ độ chính xác kép.
Hình 2 cho thấy sự so sánh hiệu suất giữa các GPU khác nhau mà chúng tôi đã thử nghiệm trong nghiên cứu này. Một lần nữa, A30 hoạt động tốt hơn A10 tới 16 lõi. Rất khó để xác định lý do tại sao A30 không hoạt động tốt với số lượng lớn lõi CPU đang hoạt động (20 lõi trở lên).
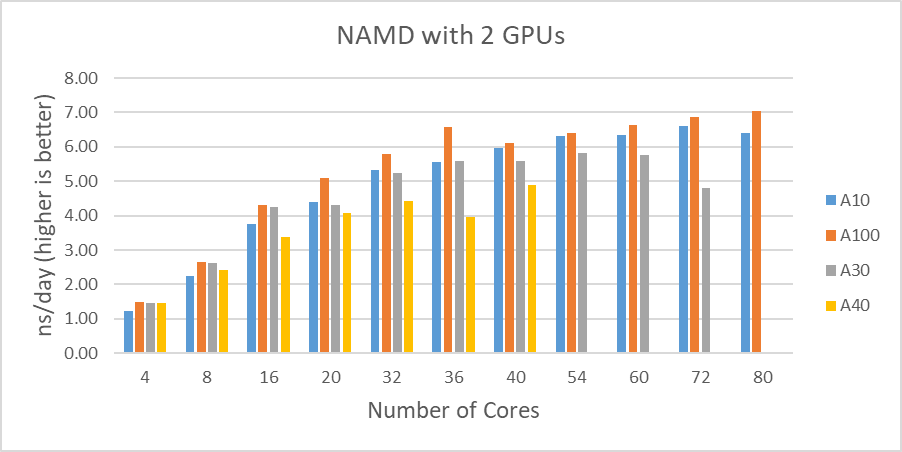
| Hình 2: So sánh kết quả thử nghiệm STMV với hai GPU |
Phần kết luận
A100 cho thấy hiệu suất vượt trội và là thẻ có khả năng cao nhất trong số các GPU dòng A. Mặc dù A30 không hoạt động tốt như A10 trong thử nghiệm của chúng tôi, nhưng đây là một lựa chọn nổi bật khác cho các ứng dụng đa năng.
A10 hoạt động tốt so với A30 và nó là sản phẩm kế thừa của T4, là giải pháp tiết kiệm chi phí nhất cho các ứng dụng cụ thể như phân tích dữ liệu bộ gen.
Vì không thể có được sự khác biệt chính xác về hiệu suất giữa các GPU dòng A từ nghiên cứu này, nên cần phải điều tra thêm để có được bức tranh rõ ràng về các GPU có mục đích chung này.
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...