
Đổi mới liên tục với các thiết kế được Dell xác thực cho AI tạo sinh với NVIDIA
Kể từ khi Dell Technologies và NVIDIA giới thiệu dự án mà khi đó được gọi là Project Helix cách đây chưa đầy một năm, rất nhiều thứ đã thay đổi. Tốc độ phát triển và ứng dụng AI tạo sinh đã nhanh hơn bất kỳ công nghệ nào trong lịch sử loài người.
Ngay từ đầu, Dell và NVIDIA đã đặt mục tiêu cung cấp một kiến trúc mô-đun và có khả năng mở rộng, hỗ trợ mọi khía cạnh của vòng đời AI tạo sinh trong một môi trường tại chỗ an toàn. Kiến trúc này được hỗ trợ bởi phần cứng máy chủ, lưu trữ và mạng hiệu suất cao của Dell, cùng với phần cứng tăng tốc và mạng của NVIDIA và phần mềm AI.
Kể từ lần ra mắt đó, Dell Validated Designs for Generative AI đã phát triển mạnh mẽ và liên tục được cập nhật để bổ sung thêm nhiều tùy chọn máy chủ, bộ lưu trữ và GPU nhằm phục vụ nhiều khách hàng, từ những người mới bắt đầu đến các hoạt động sản xuất cao cấp.
Kiến trúc mô-đun, có khả năng mở rộng được tối ưu hóa cho AI
Hành trình này được khởi đầu bằng việc phát hành sách trắng về Trí tuệ nhân tạo tạo ra trong doanh nghiệp .
Hướng dẫn thiết kế này đặt nền móng cho một loạt tài nguyên toàn diện nhằm tích hợp AI vào các cài đặt doanh nghiệp tại chỗ, tập trung vào cơ sở hạ tầng sản xuất có khả năng mở rộng và mô-đun khi hợp tác với NVIDIA.
Dell, nổi tiếng với chuyên môn không chỉ về cơ sở hạ tầng hiệu năng cao mà còn trong việc quản lý các thiết kế được kiểm chứng toàn diện, đã hợp tác với NVIDIA để thiết kế các giải pháp AI tổng hợp toàn diện, kết hợp công nghệ phần cứng và phần mềm tiên tiến. Bản chất năng động của AI đặt ra một thách thức trong việc theo kịp những tiến bộ nhanh chóng, nơi các mô hình tiên tiến hiện nay có thể nhanh chóng trở nên lỗi thời. Dell tạo nên sự khác biệt bằng cách cung cấp những hiểu biết sâu sắc và khuyến nghị thiết yếu cho các ứng dụng cụ thể, giúp hành trình khám phá thế giới AI đang phát triển nhanh chóng trở nên dễ dàng hơn.
Nền tảng của kiến trúc chung là tính mô-đun, mang đến thiết kế linh hoạt đáp ứng đa dạng trường hợp sử dụng, lĩnh vực và yêu cầu tính toán. Một cơ sở hạ tầng AI thực sự theo mô-đun được thiết kế để có khả năng thích ứng và sẵn sàng cho tương lai, với các thành phần có thể được kết hợp và kết hợp dựa trên các yêu cầu cụ thể của dự án, trải rộng từ đào tạo mô hình, tùy chỉnh mô hình bao gồm nhiều phương pháp tinh chỉnh khác nhau, cho đến suy luận về nơi chúng tôi đưa mô hình vào hoạt động.
Hình sau đây cho thấy góc nhìn tổng quan về kiến trúc tổng thể, bao gồm các thành phần phần cứng chính và ngăn xếp phần mềm:
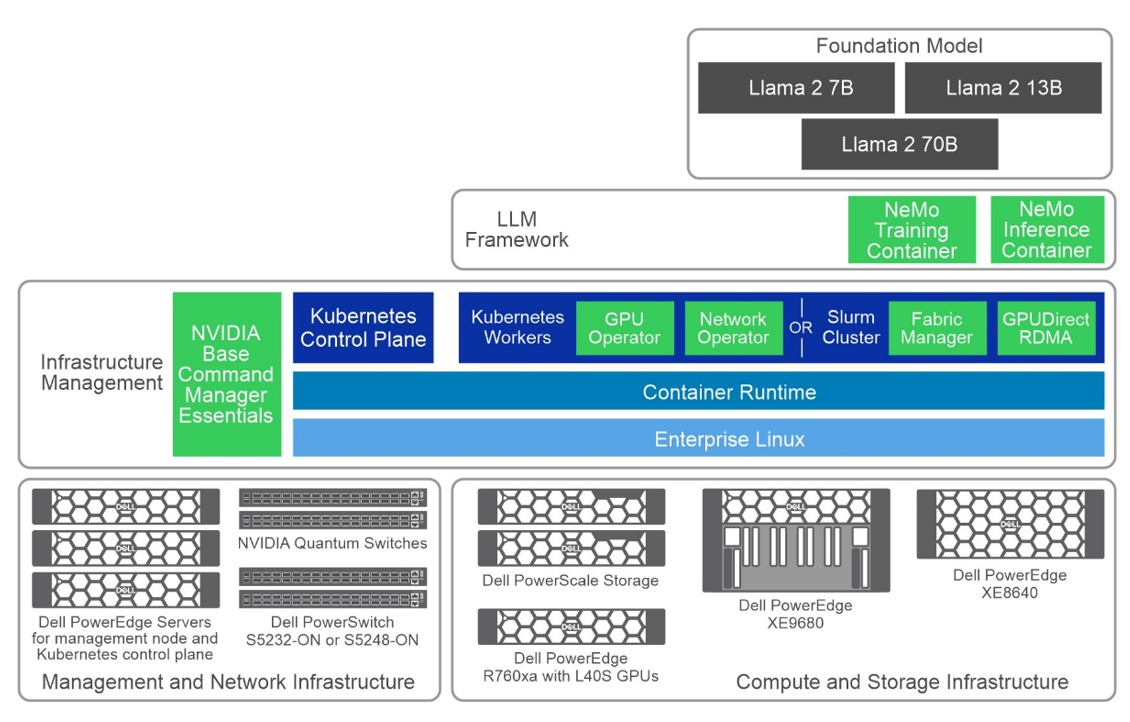
Hình 1: Kiến trúc cấp cao phổ biến
Suy luận AI tạo sinh
Tiếp theo sách trắng giới thiệu, hướng dẫn thiết kế được xác thực đầu tiên được phát hành dành cho Suy luận AI tạo sinh vào tháng 7 năm 2023, dựa trên các khái niệm sáng tạo đã giới thiệu trước đó.
Sự phức tạp của việc xây dựng một cơ sở hạ tầng AI, thường liên quan đến sự kết hợp phức tạp giữa các thành phần nguồn mở và độc quyền, có thể rất đáng gờm. Dell Technologies giải quyết vấn đề phức tạp này bằng cách cung cấp các giải pháp được xác thực đầy đủ, trong đó mọi yếu tố đều được kiểm tra kỹ lưỡng, đảm bảo chức năng và tối ưu hóa cho việc triển khai. Việc xác thực này mang lại cho người dùng sự tự tin để tiếp tục, khi biết rằng cơ sở hạ tầng AI của họ được xây dựng trên một nền tảng vững chắc và có cơ sở.
Những điểm chính
- Vào tháng 10 năm 2023, hướng dẫn đã nhận được bản cập nhật đầu tiên, mở rộng phạm vi với các chi tiết xác thực và cấu hình bổ sung cho máy chủ Dell PowerEdge XE8640 và XE9680. Bản cập nhật này cũng giới thiệu hỗ trợ cho NVIDIA Base Command Manager Essentials và NVIDIA AI Enterprise 4.0, đánh dấu sự cải tiến đáng kể về chiều rộng và chiều sâu của hướng dẫn.
- Hướng dẫn này tiếp tục được phát triển vào tháng 3 năm 2024 với phiên bản thứ ba, bao gồm hỗ trợ cho máy chủ PowerEdge R760xa được trang bị GPU NVIDIA L40S.
- Thiết kế hiện hỗ trợ nhiều tùy chọn cho các thành phần tăng tốc GPU NVIDIA trên nhiều tùy chọn máy chủ Dell. Trong thiết kế này, chúng tôi giới thiệu ba máy chủ Dell PowerEdge với nhiều tùy chọn GPU được thiết kế riêng cho mục đích AI tạo sinh:
- Máy chủ PowerEdge R760xa, hỗ trợ tối đa bốn GPU NVIDIA H100 hoặc bốn GPU NVIDIA L40S
- Máy chủ PowerEdge XE8640, hỗ trợ tối đa bốn GPU NVIDIA H100
- Máy chủ PowerEdge XE9680, hỗ trợ tối đa tám GPU NVIDIA H100
Việc lựa chọn kết hợp máy chủ và GPU thường cân bằng giữa hiệu suất, chi phí và tính khả dụng, tùy thuộc vào quy mô và độ phức tạp của khối lượng công việc.
- Phiên bản mới nhất này cũng chứng kiến việc loại bỏ NVIDIA FasterTransformer, thay thế bằng TensorRT-LLM, phản ánh cam kết của Dell trong việc cập nhật hướng dẫn này với những công nghệ mới nhất và hiệu quả nhất. Khi nói đến việc tối ưu hóa các mô hình ngôn ngữ lớn, TensorRT-LLM là chìa khóa. Nó đảm bảo rằng các mô hình không chỉ mang lại hiệu suất cao mà còn duy trì hiệu quả trong nhiều ứng dụng khác nhau.
Thư viện bao gồm các kernel được tối ưu hóa, các bước tiền xử lý và hậu xử lý, cùng các nguyên hàm giao tiếp đa GPU/đa nút. Các tính năng này được thiết kế đặc biệt để nâng cao hiệu suất trên GPU NVIDIA.
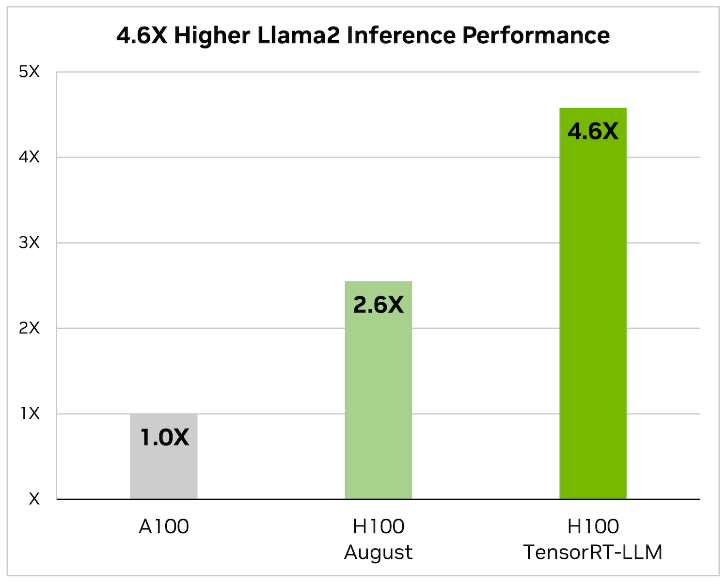
Nó sử dụng tính song song tenxơ để suy luận hiệu quả trên nhiều GPU và máy chủ mà không cần sự can thiệp của nhà phát triển hoặc thay đổi mô hình.
- Ngoài ra, bản cập nhật này còn bao gồm các bản sửa đổi cho các mô hình được sử dụng để xác thực, đảm bảo người dùng có quyền truy cập vào thông tin mới nhất và phù hợp nhất cho việc triển khai AI của họ. Hướng dẫn Thiết kế được Xác thực của Dell bao gồm Llama 2 và hiện tại là Mistral làm mô hình nền tảng cho suy luận với thiết kế cơ sở hạ tầng này với Triton Inference Server:
- Llama 2 7B, 13B và 70B
- Mistral
- Falcon 180B
- Cuối cùng (và quan trọng nhất), kết quả kiểm tra hiệu suất và các cân nhắc về kích thước cho thấy hiệu quả của kiến trúc cập nhật này trong việc xử lý các mô hình ngôn ngữ lớn (LLM) cho nhiều tác vụ suy luận khác nhau. Những điểm chính bao gồm:
- Độ trễ và thông lượng được tối ưu hóa — Thiết kế đạt được số liệu độ trễ ấn tượng, rất quan trọng đối với các ứng dụng thời gian thực như chatbot và số lượng token mỗi giây cao, cho thấy khả năng xử lý hiệu quả cho các tác vụ ngoại tuyến.
- Tác động của tính song song của mô hình — Hiệu suất của LLM thay đổi tùy theo sự điều chỉnh về tính song song của tenxơ và đường ống, làm nổi bật tầm quan trọng của các thiết lập tính song song tối ưu để tối đa hóa hiệu quả suy luận.
- Khả năng mở rộng với nhiều cấu hình GPU khác nhau — Các thử nghiệm trên nhiều GPU NVIDIA khác nhau, bao gồm các mẫu L40S và H100, đã chứng minh khả năng mở rộng của thiết kế và khả năng đáp ứng nhiều nhu cầu tính toán khác nhau.
- Hỗ trợ mô hình toàn diện — Hướng dẫn bao gồm dữ liệu hiệu suất cho nhiều mô hình (như chúng tôi đã thảo luận) trên nhiều cấu hình khác nhau, thể hiện tính linh hoạt của thiết kế trong việc xử lý nhiều LLM khác nhau.
- Hướng dẫn về kích thước — Dựa trên số liệu hiệu suất, các ví dụ về kích thước được cập nhật có sẵn để giúp người dùng xác định cơ sở hạ tầng phù hợp dựa trên các yêu cầu suy luận cụ thể của họ (những hướng dẫn này rất được hoan nghênh)
Tất cả những điều này nhấn mạnh cam kết và khả năng của Dell trong việc cung cấp các giải pháp suy luận AI tạo ra hiệu suất cao, có khả năng mở rộng và hiệu quả, phù hợp với nhu cầu của doanh nghiệp.
Tùy chỉnh mô hình AI tạo sinh
Hướng dẫn thiết kế đã được xác thực cho Tùy chỉnh Mô hình AI Tạo sinh được phát hành lần đầu tiên vào tháng 10 năm 2023, được hỗ trợ bởi máy chủ PowerEdge XE9680. Hướng dẫn này trình bày chi tiết nhiều phương pháp tùy chỉnh mô hình, bao gồm các chi tiết cụ thể về kỹ thuật nhanh chóng, tinh chỉnh có giám sát và tinh chỉnh hiệu quả tham số.
Các bản cập nhật cho Hướng dẫn thiết kế đã được Dell xác thực từ tháng 10 năm 2023 đến tháng 3 năm 2024 bao gồm bản phát hành ban đầu, bổ sung các kịch bản đã được xác thực cho SFT đa nút và Kubernetes vào tháng 11 năm 2023, cập nhật kết quả kiểm tra hiệu suất và hỗ trợ mới cho máy chủ PowerEdge R760xa, máy chủ PowerEdge XE8640 và bộ lưu trữ hoàn toàn bằng flash PowerScale F710 kể từ tháng 3 năm 2024.
Những điểm chính
- Việc xác thực nhằm mục đích kiểm tra độ tin cậy, hiệu suất, khả năng mở rộng và khả năng tương tác của hệ thống bằng cách sử dụng tùy chỉnh mô hình trong khuôn khổ NeMo, đặc biệt tập trung vào việc kết hợp kiến thức chuyên ngành vào Mô hình ngôn ngữ lớn (LLM).
- Quá trình này bao gồm việc thử nghiệm các mô hình cơ bản có kích thước 7B, 13B và 70B từ dòng Llama 2. Nhiều kỹ thuật tùy chỉnh mô hình khác nhau đã được sử dụng, bao gồm:
- Kỹ thuật nhanh chóng
- Điều chỉnh tinh chỉnh có giám sát (SFT)
- P-Tuning và
- Sự thích ứng cấp thấp của các mô hình ngôn ngữ lớn (LoRA)
- Thiết kế hiện hỗ trợ nhiều tùy chọn cho các thành phần tăng tốc GPU NVIDIA trên nhiều tùy chọn máy chủ Dell. Trong thiết kế này, chúng tôi giới thiệu ba máy chủ Dell PowerEdge với nhiều tùy chọn GPU được thiết kế riêng cho mục đích AI tạo sinh:
- Máy chủ PowerEdge R760xa, hỗ trợ tối đa bốn GPU NVIDIA H100 hoặc bốn GPU NVIDIA L40S. Trong khi L40S tiết kiệm chi phí cho khối lượng công việc từ nhỏ đến trung bình, H100 thường được sử dụng cho các tác vụ quy mô lớn hơn, bao gồm cả SFT (Siêu dữ liệu).
- Máy chủ PowerEdge XE8640, hỗ trợ tối đa bốn GPU NVIDIA H100.
- Máy chủ PowerEdge XE9680, hỗ trợ tối đa tám GPU NVIDIA H100.
Như thường lệ, việc lựa chọn kết hợp máy chủ và GPU phụ thuộc vào quy mô và độ phức tạp của khối lượng công việc.
- Quá trình xác thực sử dụng cả cụm Slurm và Kubernetes cho các tài nguyên tính toán và liên quan đến hai tập dữ liệu: tập dữ liệu Dolly từ Databricks, bao gồm nhiều loại hành vi khác nhau, và tập dữ liệu Alpaca từ OpenAI, bao gồm 52.000 bản ghi theo lệnh. Quá trình đào tạo được thực hiện tối thiểu 50 bước, với mục tiêu là xác thực khả năng của hệ thống thay vì đạt được sự hội tụ của mô hình, để cung cấp thông tin chi tiết phù hợp với nhu cầu tiềm năng của khách hàng.
Kết quả xác thực cùng với phân tích của chúng tôi có thể được tìm thấy trong phần Đặc điểm hiệu suất của hướng dẫn thiết kế.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...