
Tin tức
Giới thiệu về Hiệu năng MLPerf™ Inference v1.0 với Máy chủ Dell EMC
Blog này cung cấp các kết quả đã đóng của trung tâm dữ liệu suy luận MLPerf v1.0 trên các máy chủ Dell chạy các tiêu chuẩn suy luận MLPerf . Kết quả của chúng tôi cho thấy hiệu suất suy luận tối ưu cho các hệ thống và cấu hình mà chúng tôi đã chọn để chạy điểm chuẩn suy luận.
Bộ điểm chuẩn MLPerf đo lường hiệu suất của khối lượng công việc máy học (ML). Hiện tại, các điểm chuẩn này cung cấp một cách nhất quán để đo lường độ chính xác và thông lượng cho các khía cạnh sau của vòng đời ML:
- Đào tạo —Bộ điểm chuẩn đào tạo MLPerf đo tốc độ hệ thống có thể đào tạo các mô hình ML.
- Suy luận —Điểm chuẩn suy luận MLPerf đo tốc độ một hệ thống có thể thực hiện suy luận ML bằng cách sử dụng một mô hình được đào tạo trong các tình huống triển khai khác nhau.
MLPerf hiện là một phần của Hiệp hội MLCommons™ . MLCommons là một tập đoàn kỹ thuật mở thúc đẩy tăng tốc đổi mới máy học. Các giải pháp kỹ thuật hợp tác mở của nó hỗ trợ nhu cầu máy học của bạn. MLCommons cung cấp:
- Điểm chuẩn và số liệu
- Bộ dữ liệu và mô hình
- Thực hành tốt nhất
Tổng quan về suy luận MLPerf
Kể từ tháng 3 năm 2021, suy luận MLPerf đã gửi ba phiên bản: v0.5, v0.7 và v1.0. Phiên bản mới nhất, v1.0, sử dụng cùng điểm chuẩn như v0.7 với các ngoại lệ sau:
- Gửi nhanh — Hỗ trợ gửi nhanh, là một trình bao bọc xung quanh gửi suy luận.
- Mã kết nối lỗi (ECC) —ECC phải được đặt thành BẬT.
- Thời gian chạy 10 phút —Thời gian chạy điểm chuẩn mặc định là 10 phút.
- Số lần chạy cần thiết để gửi và kiểm tra kiểm tra —Số lần chạy cần thiết để gửi Kịch bản máy chủ là một.
v1.0 đáp ứng các yêu cầu của v0.7, do đó kết quả v1.0 có thể so sánh với kết quả v0.7. Do các lần gửi MLPerf v1.0 bị hạn chế hơn nên kết quả v0.7 không đáp ứng các yêu cầu của v1.0.
Trong khung đánh giá suy luận MLPerf, trình tạo tải LoadGen gửi các truy vấn suy luận đến hệ thống đang được kiểm tra (SUT). Trong trường hợp của chúng tôi, SUT là máy chủ Dell EMC với nhiều cấu hình GPU khác nhau. SUT sử dụng chương trình phụ trợ (ví dụ: TensorRT, TensorFlow hoặc PyTorch) để thực hiện suy luận và trả kết quả về LoadGen.
MLPerf đã xác định bốn kịch bản khác nhau cho phép thử nghiệm đại diện cho nhiều nền tảng suy luận và trường hợp sử dụng khác nhau. Sự khác biệt chính giữa các kịch bản này dựa trên cách gửi và nhận truy vấn:
- Ngoại tuyến —Một truy vấn với tất cả các mẫu được gửi đến SUT. SUT có thể gửi lại kết quả một lần hoặc nhiều lần theo bất kỳ thứ tự nào. Số liệu hiệu suất là mẫu mỗi giây.
- Máy chủ —Các truy vấn được gửi đến SUT theo phân phối Poisson (để lập mô hình các sự kiện ngẫu nhiên trong thế giới thực). Một truy vấn có một mẫu. Chỉ số hiệu suất là số truy vấn mỗi giây (QPS) trong giới hạn độ trễ.
- Single-stream —Một mẫu cho mỗi truy vấn được gửi đến SUT. Truy vấn tiếp theo không được gửi cho đến khi nhận được phản hồi trước đó. Chỉ số hiệu suất là độ trễ phân vị thứ 90.
- Đa luồng —Một truy vấn có N mẫu được gửi với một khoảng thời gian cố định. Chỉ số hiệu suất là N tối đa khi độ trễ của tất cả truy vấn nằm trong giới hạn độ trễ.
Quy tắc suy luận MLPerf mô tả các quy tắc suy luận chi tiết và các ràng buộc về độ trễ. Blog này tập trung vào các kịch bản Ngoại tuyến và Máy chủ, được thiết kế cho môi trường trung tâm dữ liệu. Các kịch bản đơn luồng và đa luồng được thiết kế cho cài đặt không phải trung tâm dữ liệu (cạnh và IoT).
Kết quả suy luận MLPerf được gửi theo một trong các bộ phận sau:
- Bộ phận khép kín— Bộ phận khép kín cung cấp sự so sánh “tương tự như” giữa các nền tảng phần cứng hoặc khung phần mềm. Nó yêu cầu sử dụng cùng một mô hình và trình tối ưu hóa như triển khai tham chiếu.
Bộ phận Đóng yêu cầu sử dụng tiền xử lý, hậu xử lý và mô hình tương đương với triển khai tham chiếu hoặc thay thế. Nó cho phép hiệu chuẩn để lượng tử hóa và không cho phép đào tạo lại. MLPerf cung cấp triển khai tham chiếu cho từng điểm chuẩn. Việc triển khai điểm chuẩn phải sử dụng một mô hình tương đương, như được định nghĩa trong Quy tắc suy luận MLPerf, với mô hình được sử dụng trong quá trình triển khai tham chiếu.
- Bộ phận mở— Bộ phận mở thúc đẩy các mô hình và trình tối ưu hóa nhanh hơn, đồng thời cho phép mọi phương pháp ML có thể đạt được chất lượng mục tiêu. Nó cho phép sử dụng tiền xử lý hoặc hậu xử lý tùy ý và mô hình, bao gồm đào tạo lại. Việc triển khai điểm chuẩn có thể sử dụng một mô hình khác để thực hiện cùng một nhiệm vụ.
Để cho phép so sánh tương tự các kết quả của Dell Technologies và cho phép khách hàng cũng như đối tác của chúng tôi lặp lại kết quả của chúng tôi, chúng tôi đã chọn thử nghiệm theo bộ phận Đóng, như kết quả trong blog này cho thấy.
Tiêu chí gửi kết quả điểm chuẩn MLPerf Inference v1.0
Đối với bất kỳ điểm chuẩn nào, kết quả gửi phải đáp ứng tất cả các thông số kỹ thuật được hiển thị trong bảng sau. Ví dụ: nếu chúng tôi chọn mô hình Resnet50 thì nội dung gửi phải đáp ứng độ chính xác mục tiêu là 76,46 phần trăm và độ trễ phải nằm trong khoảng 15 mili giây đối với tập dữ liệu hình ảnh tiêu chuẩn có kích thước 224 x 224 x 3.
Bảng 1: Điểm chuẩn phân chia đóng cho suy luận MLPerf v1.0 với kỳ vọng
| Diện tích | Nhiệm vụ | Người mẫu | tập dữ liệu | Kích thước QSL | Phẩm chất | Giới hạn độ trễ của máy chủ |
| Tầm nhìn | phân loại hình ảnh | Resnet50 – v1.5 | Bộ dữ liệu hình ảnh tiêu chuẩn (224 x 224 x3) | 1024 | 99% của FP32 (76,46%) | 15 mili giây |
| Tầm nhìn | Phát hiện đối tượng (lớn) | SSD-Resnet34 | COCO (1200 x 1200) | 64 | 99% của FP32 (0,20 mAP) | 100 mili giây |
| Tầm nhìn | Phân vùng hình ảnh y tế | Mạng 3D | BraTs 2019
(224 x 224 x 160) |
16 | 99% của FP32 và 99,9% của FP32 (điểm DICE trung bình là 0,85300) | không áp dụng |
| Lời nói | Chuyển giọng nói thành văn bản | RNNT | Librispeech dev-clean (mẫu < 15 giây) | 2513
|
99% của FP32 (1 – WER, trong đó WER=7,452253714852645%)
|
1000 mili giây |
| Ngôn ngữ | xử lý ngôn ngữ | BERT | SQuAD v1.1 (max_seq_len=384) | 10833
|
99% của FP32 và 99,9% của FP32 (f1_score=90,874%) | 130 mili giây |
| thương mại | sự giới thiệu | DLRM | Nhật ký lần nhấp 1 TB | 204800 | 99% của FP32 và 99,9% của FP32 (AUC=80,25%) | 30 mili giây |
Không bắt buộc phải nộp tất cả các điểm chuẩn. Tuy nhiên, nếu một điểm chuẩn cụ thể được gửi, thì tất cả các kịch bản bắt buộc cho điểm chuẩn đó cũng phải được gửi.
Mỗi điểm chuẩn của trung tâm dữ liệu yêu cầu các kịch bản trong bảng sau:
Bảng 2: Nhiệm vụ và các kịch bản yêu cầu tương ứng cho bộ điểm chuẩn trung tâm dữ liệu trong suy luận MLPerf v1.0.
| Diện tích | Nhiệm vụ | Kịch bản bắt buộc |
| Tầm nhìn | phân loại hình ảnh | Bộ trợ giúp không kết nối |
| Tầm nhìn | Phát hiện đối tượng (lớn) | Bộ trợ giúp không kết nối |
| Tầm nhìn | Phân vùng hình ảnh y tế | ngoại tuyến |
| Lời nói | Chuyển giọng nói thành văn bản | Bộ trợ giúp không kết nối |
| Ngôn ngữ | xử lý ngôn ngữ | Bộ trợ giúp không kết nối |
| thương mại | sự giới thiệu | Bộ trợ giúp không kết nối |
cấu hình SUT
Chúng tôi đã chọn các máy chủ sau với các loại GPU NVIDIA khác nhau làm SUT của mình để tiến hành các điểm chuẩn suy luận trung tâm dữ liệu. Bảng sau đây liệt kê các cấu hình hệ thống MLPerf:
Bảng 3: Cấu hình hệ thống MLPerf
| Nền tảng | Dell EMC DSS8440_A100 | Dell EMC DSS8440_A40 | PowerEdge R750xa | Cạnh điện
XE8545 |
| Mã hệ thống MLPerf | DSS8440_A100-PCIE-40GBx10_TRT | DSS8440_A40x10_TRT | R750xa_A100-PCIE-40GBx4_TRT | XE8545_7713_A100-SXM4-40GBx4 |
| Hệ điều hành | CentOS 8.2.2004 | CentOS 8.2.2004 | CentOS 8.2.2004 | CentOS 8.2.2004 |
| CPU | 2 x CPU Intel Xeon Gold 6248 @ 2,50 GHz | 2 x CPU Intel Xeon Gold 6248R @ 3,00 GHz | 2 x CPU Intel Xeon Gold 6338 @ 2,00 GHz | 2 x AMD EPYC 7713 |
| Kỉ niệm | 768 GB | 768 GB | 256 GB | 1 TB |
| GPU | NVIDIA A100-PCIe-40GB | NVIDIA A40 | NVIDIA A100-PCIE-40GB | NVIDIA A100-SXM4-40GB |
| Yếu tố hình thức GPU | PCIE | PCIE | PCIE | SXM4 |
| số lượng GPU | 10 | 10 | 4 | 4 |
| ngăn xếp phần mềm | TenorRT 7.2.3, CUDA 11.1, cuDNN 8.1.1, Trình điều khiển 460.32.03, DALI 0.30.0 | TenorRT 7.2.3, CUDA 11.1, cuDNN 8.1.1, Trình điều khiển 460.32.03, DALI 0.30.0 | TenorRT 7.2.3, CUDA 11.1, cuDNN 8.1.1, Trình điều khiển 460.32.03, DALI 0.30.0 | TenorRT 7.2.3, CUDA 11.1, cuDNN 8.1.1, Trình điều khiển 460.32.03, DALI 0.30.0 |
Kết quả điểm chuẩn MLPerf inference 1.0
Các biểu đồ sau bao gồm các chỉ số hiệu suất cho các kịch bản Ngoại tuyến và Máy chủ.
Đối với kịch bản Ngoại tuyến, chỉ số hiệu suất là Mẫu ngoại tuyến mỗi giây. Đối với kịch bản Máy chủ, chỉ số hiệu suất là số truy vấn mỗi giây (QPS). Nói chung, các số liệu đại diện cho thông lượng. Một thông lượng cao hơn là một kết quả tốt hơn.
Resnet50 kết quả
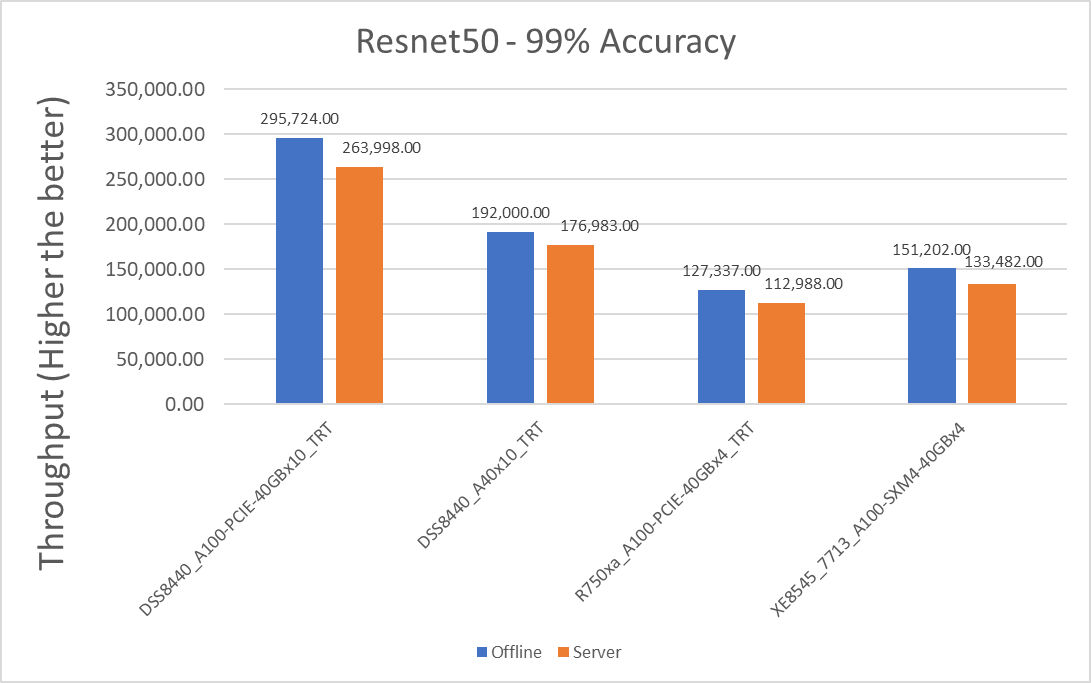
Hình 1: Kịch bản máy chủ và ngoại tuyến Resnet50 v1.5 với mục tiêu chính xác 99 phần trăm
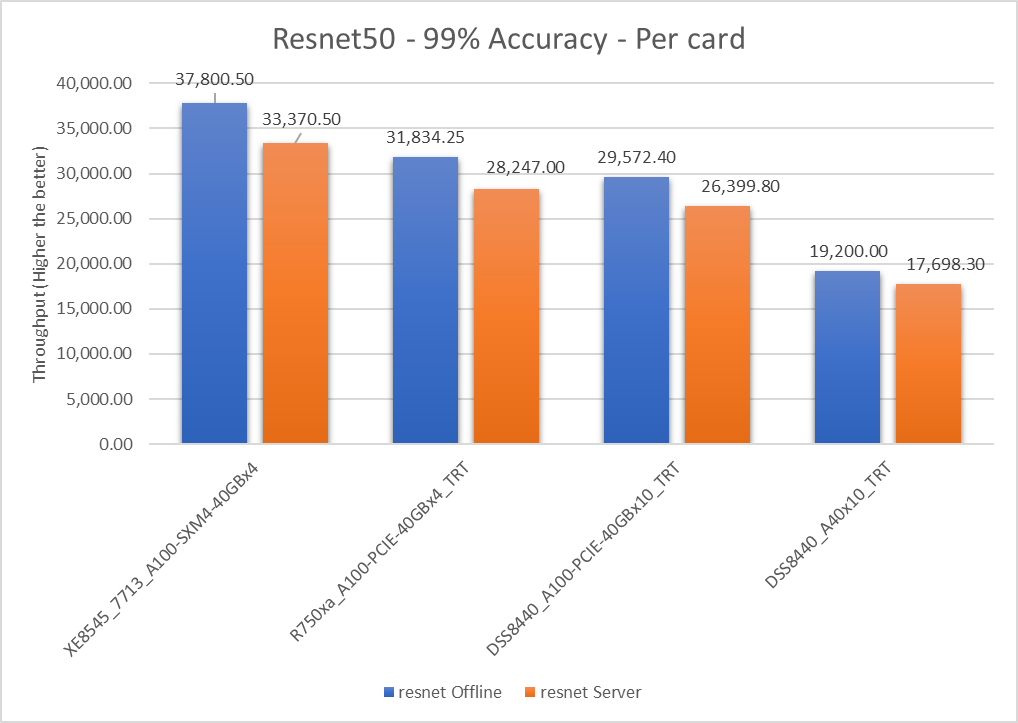
Hình 2: Kịch bản Máy chủ và Ngoại tuyến Resnet50 v1.5 với mục tiêu chính xác 99 phần trăm trên mỗi thẻ
Bảng 4: Mỗi số thẻ và chênh lệch tỷ lệ phần trăm theo kịch bản
| máy chủ Dell | ngoại tuyến
thông lượng |
Thông lượng máy chủ | Tỷ lệ phần trăm chênh lệch giữa các kịch bản |
| XE8545_7713_A100-SXM4-40GBx4 | 37800,5 | 33370.5 | 12,44 |
| R750xa_A100-PCIE-40GBx4_TRT | 31834.25 | 28247 | 11,94 |
| DSS8440_A100-PCIE-40GBx10_TRT | 29572.4 | 26399.8 | 11.33 |
| DSS8440_A40x10_TRT | 19200 | 17698.3 | 8.139 |
Thông lượng ngoại tuyến trên mỗi thẻ vượt quá Thông lượng máy chủ trên mỗi thẻ cho tất cả các máy chủ trong nghiên cứu này.
Bảng 5: Chênh lệch tỷ lệ phần trăm trên mỗi thẻ từ hệ thống XE8545_7713_A100-SXM4-40GBx4
| máy chủ Dell | Ngoại tuyến (tính theo phần trăm) | Máy chủ (tính theo phần trăm) |
| XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
| R750xa_A100-PCIE-40GBx4_TRT | 17.13 | 16,63 |
| DSS8440_A100-PCIE-40GBx10_TRT | 24,42 | 26,39 |
| DSS8440_A40x10_TRT | 65.26 | 61.37 |
Kết quả SSD-Resnet34
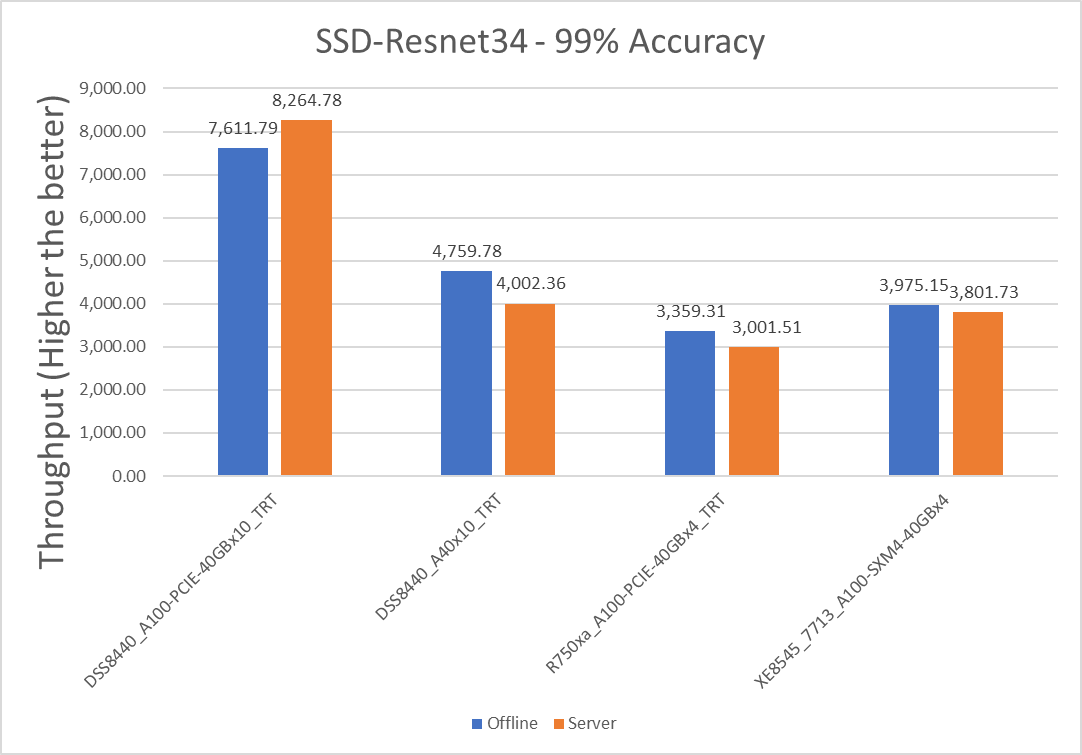
Hình 3: SSD với kịch bản Máy chủ và Ngoại tuyến Resnet34 với mục tiêu chính xác 99 phần trăm
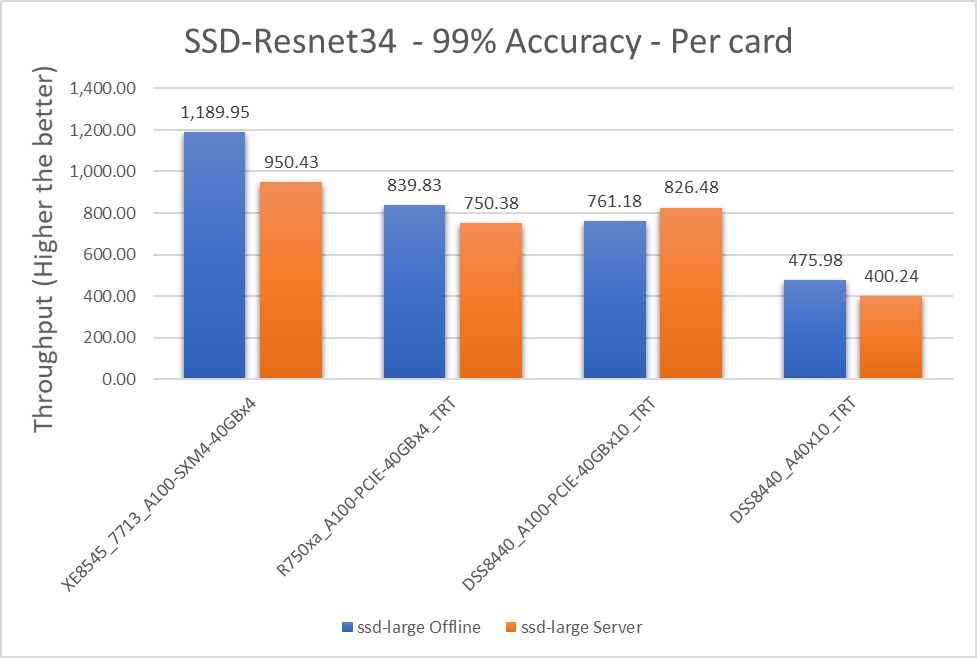
Hình 4: Kịch bản SSD-Resnet34, Ngoại tuyến và Máy chủ với các mục tiêu chính xác 99 phần trăm trên mỗi thẻ
Bảng 6: Số thẻ và chênh lệch tỷ lệ phần trăm kịch bản trên SSD-Resnet34
| máy chủ Dell | Thông lượng ngoại tuyến | Người phục vụ
thông lượng |
Tỷ lệ phần trăm chênh lệch giữa các kịch bản |
| XE8545_7713_A100-SXM4-40GBx4 | 1189.945 | 950.4325 | 22,38 |
| R750xa_A100-PCIE-40GBx4_TRT | 839.8275 | 750.3775 | 11 giờ 25 |
| DSS8440_A100-PCIE-40GBx10_TRT | 761.179 | 826.478 | -8.22 |
| DSS8440_A40x10_TRT | 475.978 | 400.236 | 17,28 |
Lưu ý : Giá trị chênh lệch phần trăm âm cho biết kịch bản Máy chủ hoạt động tốt hơn kịch bản Ngoại tuyến.
Bảng 7: Chênh lệch tỷ lệ phần trăm trên mỗi thẻ từ hệ thống XE8545_7713_A100-SXM4-40GBx4 với thẻ A100 SXM4
| máy chủ Dell | Ngoại tuyến (tính theo phần trăm) | Máy chủ (tính theo phần trăm) |
| XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
| R750xa_A100-PCIE-40GBx4_TRT | 34.4982 | 23,52 |
| DSS8440_A100-PCIE-40GBx10_TRT | 43.95067 | 13,95 |
| DSS8440_A40x10_TRT | 85.71429 | 81,47 |
Kết quả BERT
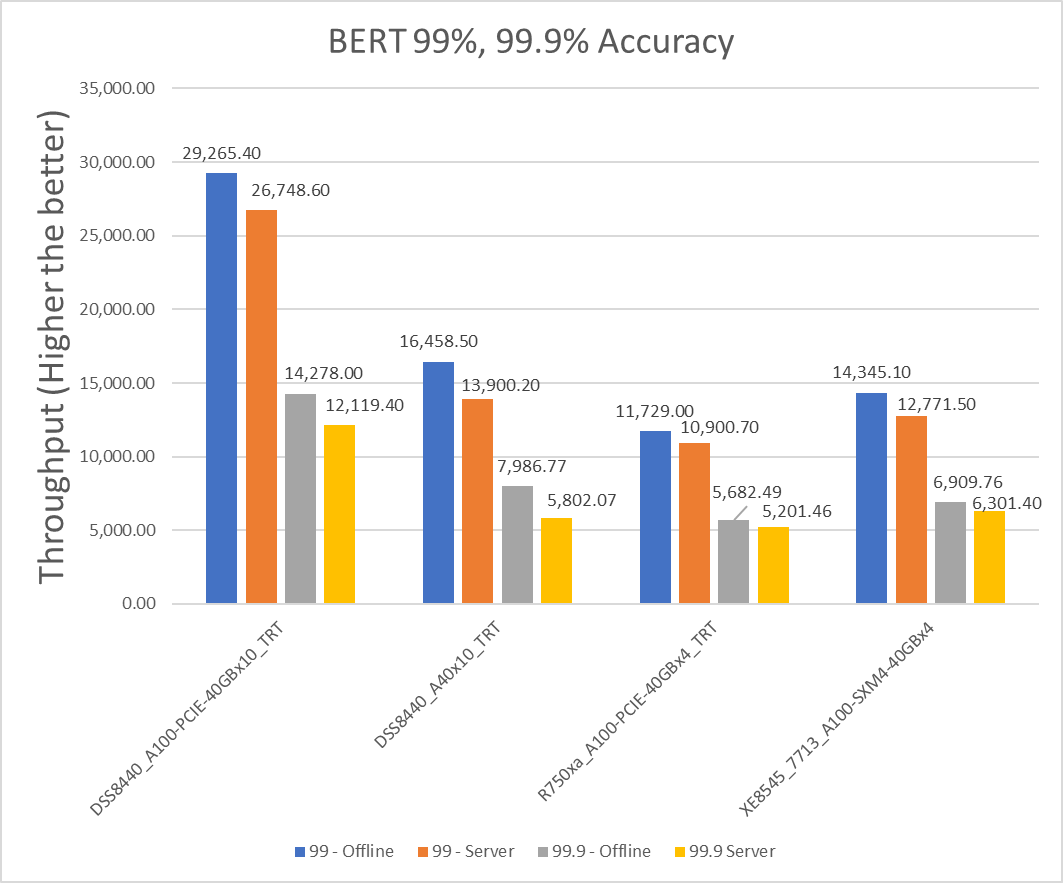
Hình 4: Kịch bản Máy chủ và Ngoại tuyến BERT với các mục tiêu chính xác 99% và 99,9%
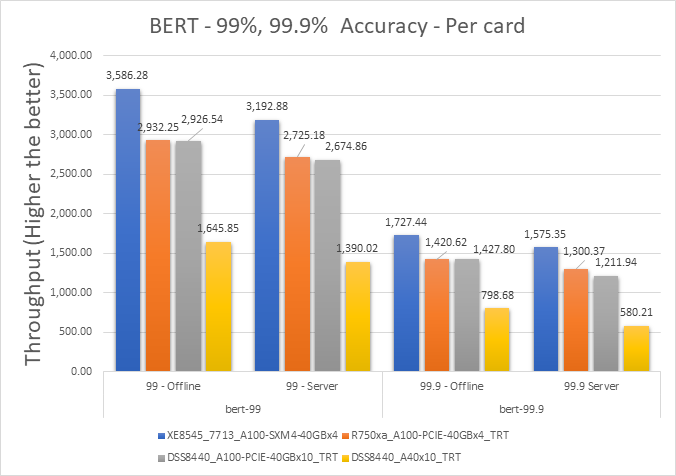
Hình 5: Kịch bản Máy chủ và Ngoại tuyến BERT với các mục tiêu chính xác 99% và 99,9% trên mỗi thẻ
Bảng 8: Mỗi số thẻ và chênh lệch phần trăm kịch bản trên BERT với mục tiêu chính xác 99 phần trăm
| máy chủ Dell | Thông lượng ngoại tuyến | Thông lượng máy chủ | Tỷ lệ phần trăm chênh lệch giữa các kịch bản |
| XE8545_7713_A100-SXM4-40GBx4 | 3586.275 | 3192.875 | 11.60617482 |
| R750xa_A100-PCIE-40GBx4_TRT | 2932.25 | 2725.175 | 7.320468234 |
| DSS8440_A100-PCIE-40GBx10_TRT | 2926.54 | 2674.86 | 8.986324847 |
| DSS8440_A40x10_TRT | 1645.85 | 1390.02 | 16.85381785 |
Bảng 9: Chênh lệch tỷ lệ phần trăm trên mỗi thẻ từ hệ thống XE8545_7713_A100-SXM4-40GBx4 với thẻ A100 SXM4
| máy chủ Dell | 99% – Ngoại tuyến (tính theo phần trăm) | 99% – Máy chủ (tính theo phần trăm) |
| XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
| R750xa_A100-PCIE-40GBx4_TRT | 20.06 | 15,8 |
| DSS8440_A100-PCIE-40GBx10_TRT | 20,25 | 17,65 |
| DSS8440_A40x10_TRT | 74.17 | 78,67 |
Bảng 10: Mỗi số thẻ và chênh lệch tỷ lệ phần trăm kịch bản trên BERT với mục tiêu chính xác 99,9 phần trăm
| máy chủ Dell | 99,9% – Thông lượng ngoại tuyến | 99,9% thông lượng máy chủ | Tỷ lệ phần trăm chênh lệch giữa các kịch bản |
| XE8545_7713_A100-SXM4-40GBx4 | 1727.44 | 1575.35 | 9.2097893 |
| R750xa_A100-PCIE-40GBx4_TRT | 1420.6225 | 1300.365 | 8.8392541 |
| DSS8440_A100-PCIE-40GBx10_TRT | 1427.8 | 1211.94 | 16.354641 |
| DSS8440_A40x10_TRT | 798.677 | 580.207 | 31.687945 |
Bảng 11: Chênh lệch tỷ lệ phần trăm trên mỗi thẻ từ hệ thống XE8545_7713_A100-SXM4-40GBx4 với thẻ A100 SXM4
| máy chủ Dell | 99,9% – Ngoại tuyến (tính theo phần trăm) | 99,9% – Máy chủ (tính theo phần trăm) |
| XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
| R750xa_A100-PCIE-40GBx4_TRT | 19,49 | 19.12 |
| DSS8440_A100-PCIE-40GBx10_TRT | 18,99 | 26.07 |
| DSS8440_A40x10_TRT | 73,53 | 92,33 |
Kết quả RNN-T
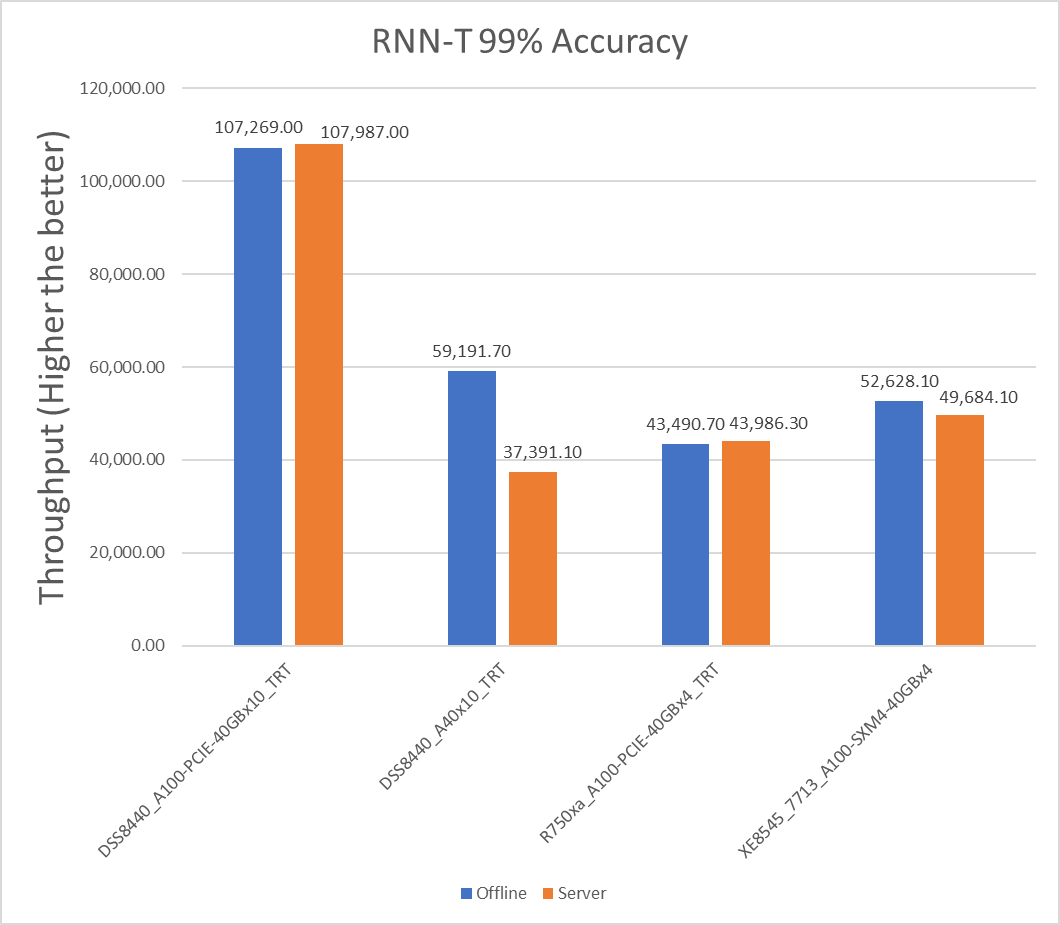
Hình 6: Kịch bản máy chủ và ngoại tuyến RNN-T với mục tiêu chính xác 99 phần trăm
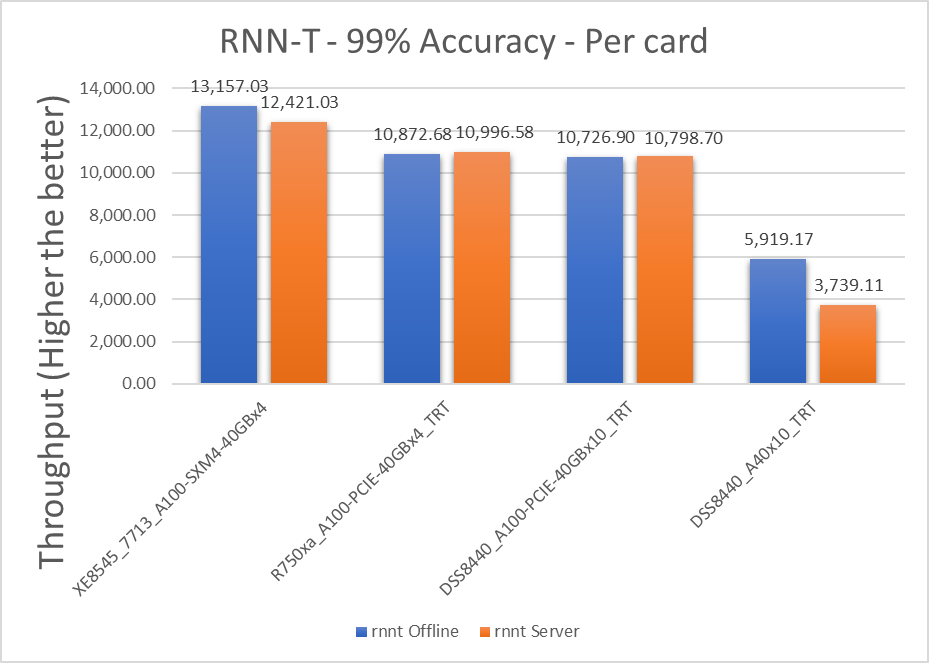
Hình 7: Kịch bản máy chủ và ngoại tuyến RNN-T với mục tiêu chính xác 99 phần trăm trên mỗi thẻ
Bảng 12: Mỗi số thẻ và chênh lệch phần trăm kịch bản trên RNNT với mục tiêu chính xác 99 phần trăm
| máy chủ Dell | Thông lượng ngoại tuyến | Người phục vụ
thông lượng |
Tỷ lệ phần trăm chênh lệch giữa các kịch bản |
| XE8545_7713_A100-SXM4-40GBx4 | 13157.025 | 12421.025 | 5.754934 |
| R750xa_A100-PCIE-40GBx4_TRT | 10872.675 | 10996.575 | -1.1331 |
| DSS8440_A100-PCIE-40GBx10_TRT | 10726.9 | 10798.7 | -0,66711 |
| DSS8440_A40x10_TRT | 5919.17 | 3739.11 | 45.14386 |
Lưu ý : Giá trị âm cho chênh lệch phần trăm cho biết rằng kịch bản Máy chủ hoạt động tốt hơn kịch bản Ngoại tuyến.
Bảng 13: Chênh lệch tỷ lệ phần trăm trên mỗi thẻ từ hệ thống XE8545_7713_A100-SXM4-40GBx4 với thẻ A100 SXM4
| máy chủ Dell | Ngoại tuyến (tính theo phần trăm) | Máy chủ (tính theo phần trăm) |
| XE8545_7713_A100-SXM4-40GBx4 | 0 | 0 |
| R750xa_A100-PCIE-40GBx4_TRT | 19.01 | 12.16 |
| DSS8440_A100-PCIE-40GBx10_TRT | 20,34 | 13,97 |
| DSS8440_A40x10_TRT | 75,88 | 107,44 |
Kết quả 3D-UNet
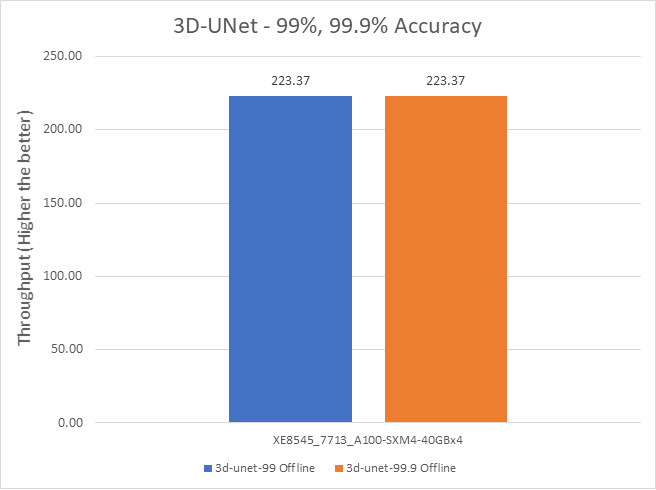
Hình 8: Kịch bản máy chủ và ngoại tuyến 3D-UNet với mục tiêu chính xác 99 phần trăm và 99,9 phần trăm
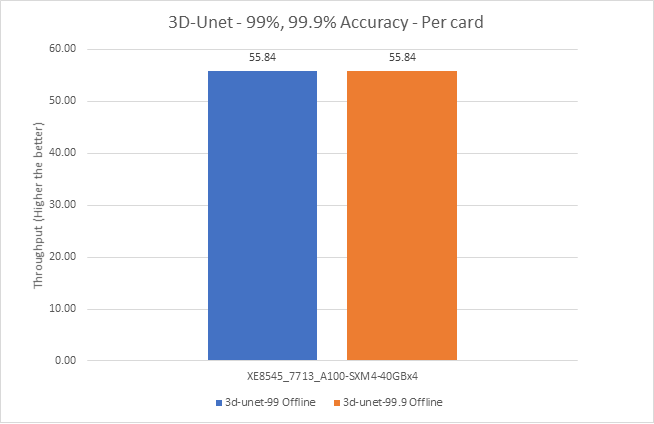
Hình 9: Kịch bản máy chủ và ngoại tuyến 3D-UNet với mục tiêu chính xác 99 phần trăm và 99,9 phần trăm
Sự kết luận
Trong blog này, chúng tôi đã định lượng hiệu suất suy luận MLCommons MLPerf v1.0 trên các máy chủ Dell EMC DSS8440, PowerEdge R750xa và PowerEdge XE8545 với hệ số dạng A100 PCIE và SXM bằng cách sử dụng các tiêu chuẩn như Resnet50, SSD w/Resnet34, BERT, RNN-T, và 3D-UNet. Các điểm chuẩn này mở rộng các nhiệm vụ từ tầm nhìn đến đề xuất. Các máy chủ Dell EMC mang lại hiệu suất suy luận hàng đầu được chuẩn hóa theo số lượng bộ xử lý trong số các kết quả có sẵn trên thị trường.
Máy chủ PowerEdge XE8545 vượt trội so với số thẻ trên mỗi máy chủ khác trong nghiên cứu này. Kết quả này có thể là do GPU SXM của nó, cung cấp tốc độ xung nhịp cơ bản và tăng cao hơn.
Mô hình phân đoạn hình ảnh SSD-Resnet34 được hưởng lợi đáng kể từ GPU dựa trên yếu tố hình thức SXM. Kết quả cho thấy chênh lệch hiệu suất xấp xỉ 34 phần trăm so với PCIE từ hệ số, so với các kiểu máy khác có mức chênh lệch trung bình khoảng 20 phần trăm.
Máy chủ PowerEdge R750xa với GPU A100 hoạt động tốt hơn trong kịch bản Máy chủ so với kịch bản Ngoại tuyến cho mô hình RNN-T.
Máy chủ DSS 8440 với GPU A100 hoạt động tốt hơn trong kịch bản Máy chủ so với kịch bản Ngoại tuyến đối với các kiểu máy BERT, RNN-T và SSD-Resnet34.
Ngoài ra, chúng tôi nhận thấy rằng hiệu suất của máy chủ DSS8440 với 10 thẻ A100 PCIE vượt quá các lần gửi MLCommons MLPerf inference v1.0 khác cho điểm chuẩn Máy chủ RNN-T.
Bước tiếp theo
Trong các blog trong tương lai, chúng tôi dự định mô tả cách:
- Chạy MLCommons Suy luận MLPerf v1.0
- Hiểu kết quả suy luận MLPerf MLCommons trên các máy chủ PowerEdge R750xa và PowerEdge XE8545 mới phát hành gần đây
- Chạy điểm chuẩn trên các máy chủ khác
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...