
Trừu tượng
Phòng thí nghiệm đổi mới HPC & AI của Dell Technologies gần đây đã gửi kết quả cho bộ điểm chuẩn MLPerf Inference v1.1. Những kết quả này cung cấp cho khách hàng của chúng tôi thông tin minh bạch về hiệu suất của máy chủ Dell EMC. Blog này nêu bật những cải tiến giữa các bản đệ trình MLPerf ™ Inference v1.0 và MLPerf Inference v1.1 từ Dell Technologies. Những cải tiến này bao gồm hiệu suất GPU được cải thiện và phần mềm mới để trích xuất hiệu suất. Ngoài ra, blog này so sánh các cấu hình máy chủ và GPU từ các lần gửi MLPerf Inference v1.0 và v1.1.
So sánh cấu hình
Trọng tâm của các bài nộp Suy luận MLPerf là vượt trội so với những kỳ vọng do MLPerf vạch ra. Để có phần giới thiệu về kết quả hiệu suất MLPerf Inference v1.0, chúng tôi khuyên bạn nên đọc blog này do Dell Technologies xuất bản.
Bảng sau đây cung cấp các cấu hình ngăn xếp phần mềm từ hai lần gửi cho các điểm chuẩn phân chia khép kín:
Bảng 1: Ngăn xếp phần mềm MLPerf Inference v1.0 và v1.1
| v1.0 | v1.1 | |
| TenorRT | 7.2.3 | 8.0.2 |
| CUDA | 11.1 | 11.3 |
| cuDNN | 8.1.1 | 8.2.1 |
| trình điều khiển GPU | 460.32.03 | 470.42.01 |
| ĐẠI LÝ | 0.30.0 | 0.31.0 |
| triton | 21.07 |
Bảng sau đây hiển thị các máy chủ Dell EMC được sử dụng để gửi MLPerf Inference v1.0 và v1.1:
Bảng 2: Các máy chủ được sử dụng để gửi MLPerf Inference v1.0 và v1.1
| v1.0 | v1.1 | |
| Người phục vụ | Máy gia tốc | Máy gia tốc |
| DSS 8440 | 10 x A100-PCIe-40GB
10 x A40 |
10 x NVIDIA A100-PCIE-80GB
8 x A30 (TensorRT) 8 x A30 (Triton) |
| PowerEdge R7525 | 3 x Quadro RTX 8000
2 x A100-PCIe-40GB 3 x A100-PCIe-40GB |
3 x A100-PCIE-40GB
3 x A30 3 x LƯỚI A100-40C |
| PowerEdge R740 | 3 x NVIDIA A100-PCIe-40GB
4 x A100-PCIe-40GB |
|
| PowerEdge R750 | ICX-6330(2S 28C)
ICX-8352M(2S 32C) |
|
| PowerEdge R750xa | 4 x A100-PCIE-40GB, MaxQ
4 x A100-PCIE-80GB-MIG-7x1g.10gb 4 x A100-PCIE-80GB (TensorRT) 4 x A100-PCIE-80GB (Triton) |
|
| PowerEdge XE2420 | 4 x T4 | 2 x A10 |
| PowerEdge XE8545 | 4 x A100-SXM-40GB
4 x A100-SXM-80GB |
4 x A100-SXM-80GB-7x1g.10gb
4 x A100-SXM-80GB (TensorRT) 4 x A100-SXM-80GB (Triton) |
| PowerEdge XR12 | 2 x A10 |
Bên cạnh những nâng cấp trong ngăn xếp phần mềm được trình bày chi tiết trong bảng trước và kết quả từ phần cứng mới nhất, sự khác biệt giữa các lần gửi MLPerf Inference v1.0 và v1.1 bao gồm:
- Kịch bản Đa luồng không được dùng nữa trong MLPerf v1.1.
- Tổng số người gửi tăng từ 17 lên 21.
- Có tổng cộng 1725 lần gửi tới MLCommons™ trong phiên bản 1.1.
Suy luận MLPerf v1.0 so với Suy luận MLPerf v1.1
Chúng tôi đã so sánh các lần gửi MLPerf v1.0 và v1.1 bằng cách xem kết quả từ một máy chủ giống hệt nhau và cùng một cấu hình GPU được sử dụng trong cả hai vòng gửi. Đối với cả hai lần gửi, Dell Technologies đã gửi kết quả cho máy chủ Dell EMC PowerEdge XE8545 được định cấu hình với bốn GPU A100 SXM 80 GB. Máy chủ PowerEdge XE8545 sử dụng kết hợp CPU AMD mới nhất và GPU NVIDIA A100 Tensor Core mạnh mẽ. Bảng thông số kỹ thuật PowerEdge XE8545 cung cấp thêm chi tiết về máy chủ.
Hình dưới đây cho thấy hiệu suất gần như ngang bằng giữa hai lần gửi, cho phép so sánh công bằng giữa các lần gửi. Ngoài ra, điều đó cho thấy rằng chúng ta cần lưu ý về các nâng cấp phần mềm được liệt kê trong Bảng 1, bất kể mức độ tối thiểu như thế nào.
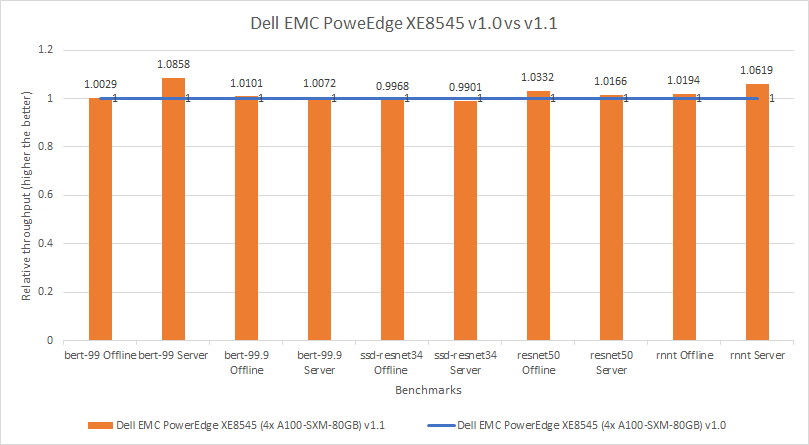
Hình 1: So sánh hiệu suất tương đối của PowerEdge XE8545 4 x A100 SXM 80 GB trong MLPerf v1.0 và v1.1
Cải tiến hệ thống Dell EMC cho MLPerf Inference v1.1
Phần này cung cấp các so sánh chi tiết về các GPU khác nhau trong các lần gửi MLPerf Inference v1.0 và v1.1 để cho thấy sự mở rộng của máy chủ Dell EMC và các cấu hình GPU khả dụng.
GPU A100 40 GB so với GPU A100 80 GB
Máy chủ Dell EMC DSS 8440
Máy chủ Dell EMC DSS 8440 mang lại hiệu suất cao với chi phí thấp hơn so với các đối thủ cạnh tranh của chúng tôi. Bằng cách cung cấp hỗ trợ cho bốn, tám hoặc 10 GPU, máy chủ này vượt trội về khả năng xử lý cùng với cơ sở hạ tầng linh hoạt. Máy chủ DSS 8440 mang lại hiệu suất cao cho khối lượng công việc máy học. Bảng Thông số DSS 8440 cung cấp thêm chi tiết về máy chủ.
Hình dưới đây so sánh hai máy chủ DSS 8440 được cấu hình với GPU NVIDIA A100 Tensor Core . Đối với lần gửi v1.0, máy chủ DSS 8440 đã được định cấu hình với GPU A100 40 GB (hiển thị màu xanh lam). Đối với lần gửi v1.1, máy chủ DSS 8440 đã được định cấu hình với GPU A100 80 GB (hiển thị màu cam). Trên các kiểu máy khác nhau, hiệu suất được cải thiện từ 3% đến 20%, ưu tiên hệ thống có GPU A100 80 GB. Cải thiện hiệu suất hơn 10 phần trăm có thể là do tần suất của mỗi thẻ; GPU A100 80 GB là thẻ 300W trong khi GPU A100 40 GB là thẻ 250W.
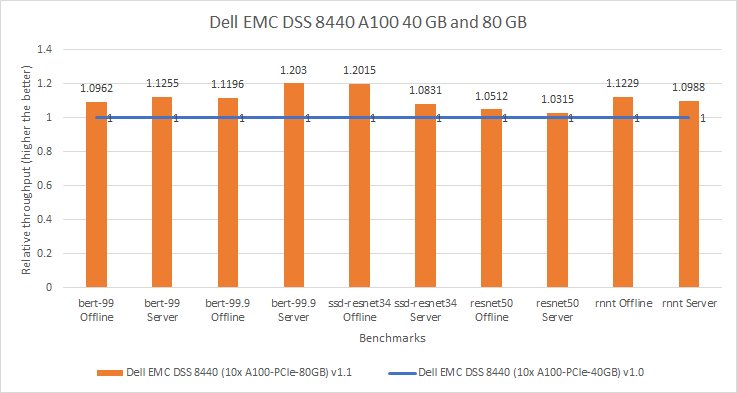
Hình 2: So sánh hiệu suất tương đối của DSS 8440 10 x A100 PCIe 40 GB và 80 GB trong MLPerf v1.0 và v1.1
Máy chủ Dell EMC PowerEdge R750xa
Máy chủ PowerEdge R750xa lý tưởng cho đào tạo và suy luận Trí tuệ nhân tạo (AI)/Học máy (ML)/Học sâu (DL), điện toán hiệu suất cao và ảo hóa. Xem Bảng thông số Dell EMC PowerEdge R750xa để biết thêm thông tin về máy chủ.
Đối với sự so sánh này, máy chủ cho cả hai lần gửi đều nhất quán. Để gửi MLPerf v1.0, máy chủ PowerEdge R750xa đã được định cấu hình với bốn GPU A100 40 GB. Để gửi MLPerf v1.1, máy chủ PowerEdge R750xa đã được định cấu hình với bốn GPU A100 80 GB. Hình dưới đây cho thấy rằng đối với việc gửi MLPerf v1.1, hiệu suất bổ sung đã được trích xuất từ hệ thống. Trên các mô hình khác nhau, kết quả MLPerf v1.1 tốt hơn từ 7% đến 22% so với kết quả từ lần gửi MLPerf v1.0. Trong điểm chuẩn Resnet50, kết quả MLPerf v1.1 ấn tượng hơn lần lượt là 15% và 19% trong các tình huống Ngoại tuyến và Máy chủ.
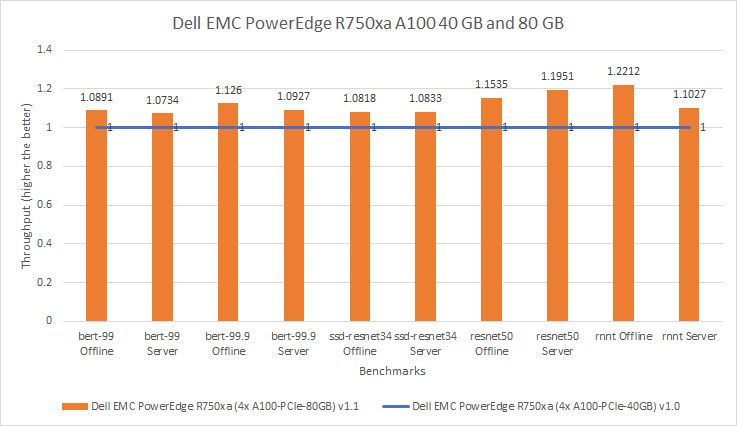
Hình 3: Hiệu suất tương đối của GPU PowerEdge R750xa 4 x A100 40 GB và 80 GB trong MLPerf v1.0 và v1.1 tương ứng
Máy chủ Dell EMC PowerEdge XE8545
Để gửi MLPerf v1.0, máy chủ PowerEdge XE8545 đã được định cấu hình với GPU A100 SXM4 40 GB (hiển thị màu xanh lam trong hình 4 và 5) và GPU A100 SXM4 80 GB (hiển thị màu cam trong hình 4 và 5). Để gửi MLPerf v1.1, máy chủ PowerEdge XE 8545 đã được định cấu hình với GPU A100 SXM4 80 GB (hiển thị màu xám trong hình 4 và 5). Người ta mong đợi rằng đối với việc gửi MLPerf v1.0, GPU A100 SXM4 80 GB sẽ hoạt động tốt hơn GPU A100 SXM4 40 GB. Trên các mẫu máy trong lần gửi MLPerf v1.1, GPU A100 SXM4 80 GB có hiệu suất nằm trong khoảng âm 1% (giá trị âm biểu thị mức thâm hụt hiệu suất, được lưu ý đối với SSD ResNet34 trong Hình 5) và tốt hơn 8% so với hệ thống giống hệt trong MLPerf trình v1.0. Thật thú vị, đối với điểm chuẩn SSD Resnet-34, GPU A100 trong MLPerf v1.
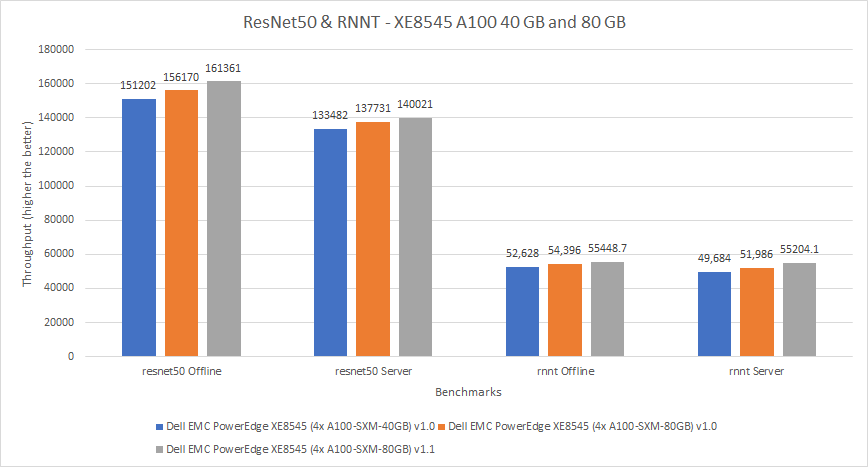
Hình 4: Hiệu suất của PowerEdge XE8545 4 x A100 40 GB và 80 GB trong MLPerf v1.0 và 80 GB trong MLPerf v1.1 cho ResNet50 và RNNT
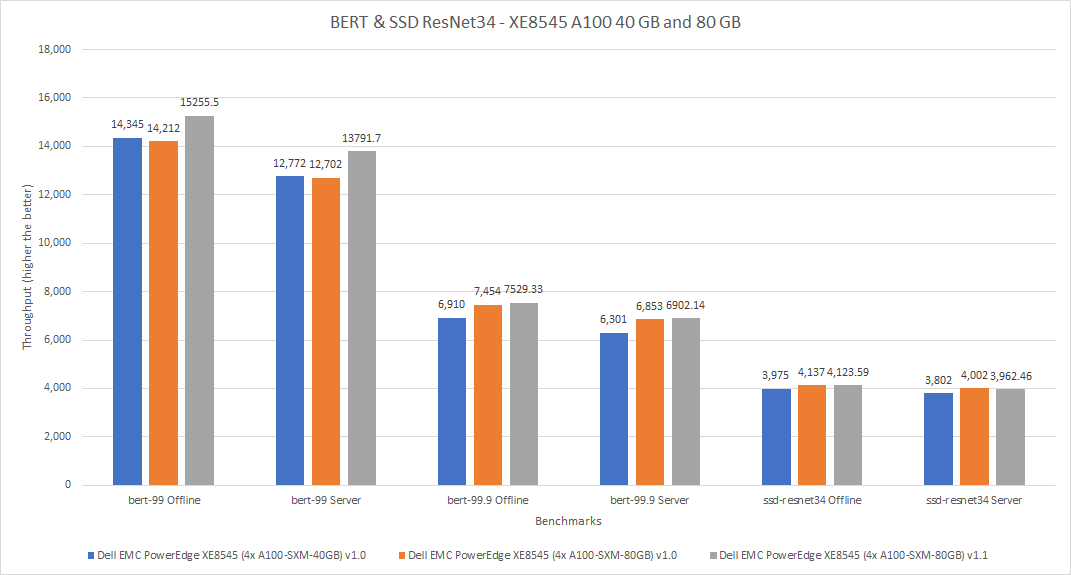
Hình 5: Hiệu suất của PowerEdge XE8545 4 x A100 40 GB và 80 GB trong MLPerf v1.0 và 80 GB trong MLPerf v1.1 cho BERT và SSD ResNet34
GPU NVIDIA A30 so với GPU NVIDIA A40
So sánh này xem xét GPU NVIDIA A40 và NVIDIA A30 Tensor Core . Để so sánh công bằng giữa hai GPU, cấu hình máy chủ DSS 8440 nhất quán trong hai lần gửi. Để gửi MLPerf v1.0, máy chủ DSS 8440 đã được định cấu hình với mười GPU A40. Để gửi MLPerf v1.1, máy chủ đã được định cấu hình với tám GPU A30. Để hiểu rõ hơn về hai GPU, kết quả trong Hình 6 được trình bày dưới dạng số hiệu suất trên mỗi thẻ, có nghĩa là kết quả thông lượng từ GPU A40 được chia cho 10 và kết quả từ GPU A30 được chia cho 8 .
Hệ thống được định cấu hình với GPU A30 hoạt động tốt hơn từ 15 đến 111% so với GPU A40 trên các tiêu chuẩn khác nhau. GPU A30 lý tưởng để suy luận vì nó được định cấu hình với Bộ nhớ băng thông cao (HBM2) và tần số GPU cao hơn. GPU A40 được định vị nhiều hơn cho Cơ sở hạ tầng máy tính ảo (VDI) và các khối lượng công việc khác.
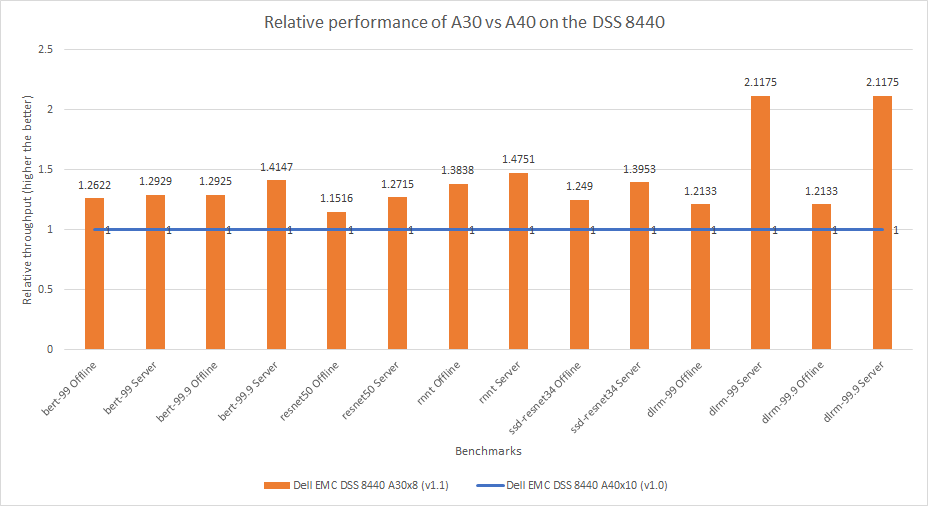
Hình 6: So sánh hiệu suất tương đối trên mỗi thẻ của máy chủ DSS 8440 với GPU A30 và A40 trong MLPerf v1.0 và v1.1
So sánh GPU NVIDIA T4, A30 và A10
So sánh này xem xét ba lần gửi trên ba máy chủ khác nhau. Các con số được chia để hiển thị hiệu suất mỗi thẻ.
Máy chủ Dell EMC PowerEdge XE2420 là một máy chủ biên đặc biệt hỗ trợ các ứng dụng đòi hỏi khắt khe ở biên, ứng dụng bán lẻ và phân tích, ứng dụng sản xuất và hậu cần cũng như xử lý tế bào 5G. Xem Bảng thông số PowerEdge XE2420 để biết thêm thông tin. Phòng thí nghiệm của chúng tôi đã định cấu hình hệ thống với bốn GPU NVIDIA Tesla T4 đã được tối ưu hóa để có hiệu suất sử dụng cao đồng thời hoạt động theo cách tiết kiệm năng lượng. Kết quả từ hệ thống này đã được xuất bản trong MLPerf Inference v1.0 Kết quả .
Máy chủ thứ hai trong so sánh này là máy chủ DSS 8440, được cấu hình với tám GPU NVIDIA A30. Máy chủ cuối cùng trong phần so sánh này là máy chủ PowerEdge XE2420, được cấu hình với hai GPU NVIDIA A10 .
Ba thẻ trong so sánh này có các yếu tố hình thức khác nhau; GPU A10 và A30 lớn hơn GPU T4. Hình dưới đây cho thấy GPU A30 hoạt động tốt hơn hai GPU còn lại. Trên các điểm chuẩn khác nhau, GPU A30 hoạt động tốt hơn từ 204% đến 360% so với GPU T4 và tốt hơn từ 5% đến 57% so với GPU A10.
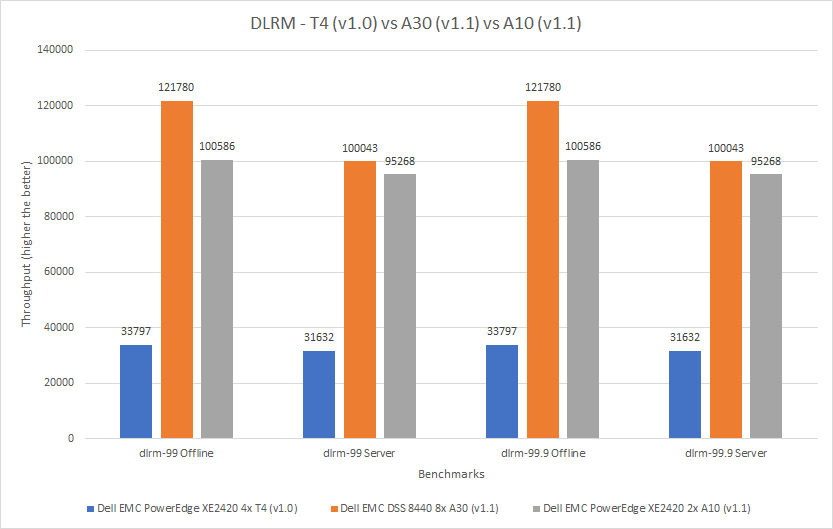
Hình 7: So sánh GPU T4, A30 và A10 cho DLRM
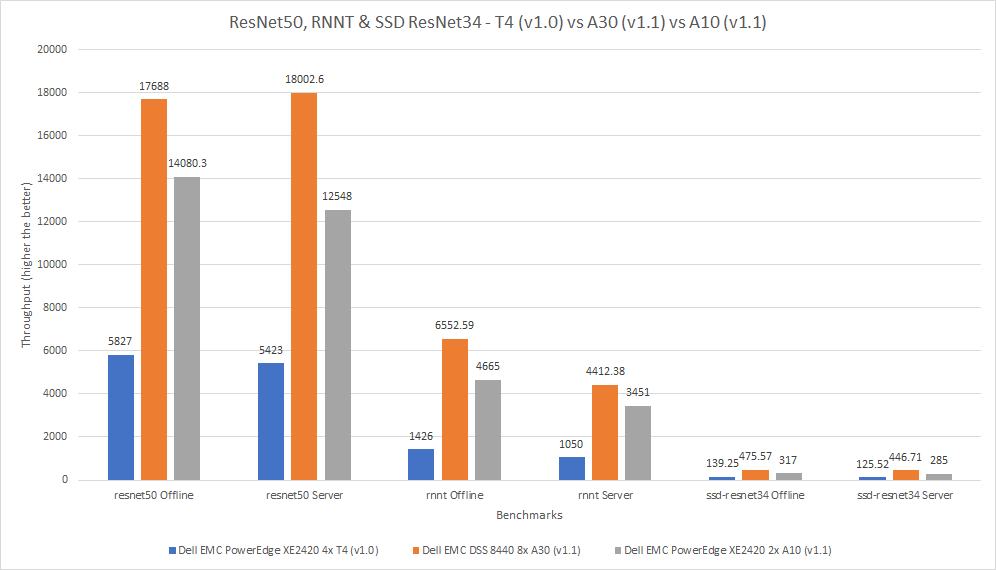
Hình 8: So sánh GPU T4, A40 và A10 cho ResNet50, RNNT và SSD ResNet34
So sánh GPU NVIDIA T4, GPU đa phiên bản A30 (MIG) và A100 MIG
So sánh này cũng xem xét ba lần gửi trên ba máy chủ khác nhau. Kết quả từ điểm chuẩn Resnet50 và SSD Resnet34 đã được chia để hiển thị hiệu suất của mỗi thẻ.
Máy chủ PowerEdge XE2420 được cấu hình với bốn GPU NVIDIA Tesla T4. Kết quả cho hệ thống này là từ lần gửi MLPerf v1.0. Máy chủ PowerEdge R7525 được cấu hình với ba GPU NVIDIA A30. MIG đã được bật trên tất cả các GPU này với cấu hình 1g6gb. Chúng tôi đã không xuất bản kết quả A30 MIG trên máy chủ PowerEdge R7525 cho MLCommons, nhưng kết quả phù hợp.
Máy chủ PowerEdge R750xa được cấu hình với bốn GPU NVIDIA A100 80 GB, hỗ trợ GPU đa phiên bản (MIG) và Tốc độ kết nối thành phần ngoại vi (PCIe). MIG là một cải tiến dành cho GPU NVIDIA với kiến trúc Ampere cho phép bảy phân vùng bảo mật của các phiên bản GPU. Kiến trúc này có lợi vì nó cho phép tăng tính song song. Các kết quả từ hệ thống này đã được gửi trong bản gửi MLPerf Inference v1.1. Có nhiều kích cỡ khác nhau của lát cắt MIG. Cấu hình cho GPU A30 và A100 đã sử dụng phần nhỏ nhất có thể. Ví dụ: GPU A100 được chia thành bảy phần và GPU A30 thành bốn phần.
Các số liệu sau đây cho thấy kết quả trên các lần gửi MLPerf v1.0 và v1.1 từ Dell Technologies cho ResNet50 và SSD ResNet34. Hình 9 cho thấy mỗi kết quả GPU vật lý. Đối với điểm chuẩn ResNet50 Offline, GPU A30 hoạt động tốt hơn 232% so với GPU T4, trong khi GPU A100 hoạt động tốt hơn 76% so với GPU A30. Ở chế độ Máy chủ ResNet 50, GPU A30 hoạt động tốt hơn 50% so với GPU T4 và GPU A100 hoạt động tốt hơn 23% so với GPU A30. Chúng tôi đã quan sát thấy xu hướng tương tự trên các chế độ Máy chủ và Ngoại tuyến, trong đó GPU A100 hoạt động tốt hơn GPU A30 và GPU này hoạt động tốt hơn GPU T4.
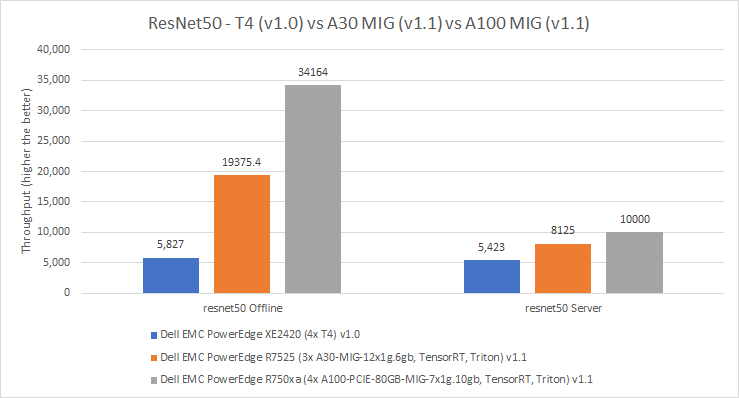
Hình 9: Hiệu năng trên mỗi card của GPU T4, A30 MIG và A100 MIG cho ResNet50
Trong điểm chuẩn SSD ResNet34, chúng tôi đã quan sát thấy một xu hướng tương tự trong đó hiệu suất của GPU A100 tốt hơn hiệu suất của GPU A30, GPU này hoạt động tốt hơn GPU T4. Ở chế độ Ngoại tuyến của điểm chuẩn SSD ResNet34, GPU A30 hoạt động tốt hơn 243% so với GPU T4 và GPU A100 hoạt động tốt hơn 77% so với GPU A30. Ở chế độ Máy chủ, GPU A100 hoạt động tốt hơn 93% so với GPU A30 và GPU A30 hoạt động tốt hơn 198% so với GPU T4.
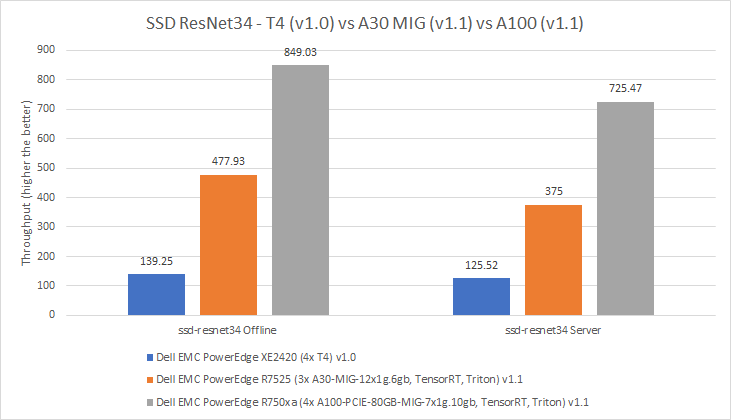
Hình 10: Hiệu suất trên mỗi thẻ của GPU T4, A30 MIG và A100 MIG cho SSD ResNet34
Sự kết luận
Blog này đã cung cấp phần giới thiệu ngắn gọn về đo điểm chuẩn MLPerf Inference và tóm tắt về bài nộp của Dell Technologies từ MLPerf Inference v1.0. Ngoài ra, nó nhấn mạnh sự khác biệt trong ngăn xếp phần mềm giữa các lần gửi MLPerf v1.0 và v1.1. Blog này đã định lượng kết quả từ các cấu hình máy chủ và GPU khác nhau qua hai vòng gửi MLPerf và hiển thị các so sánh hiệu suất đáng chú ý và có liên quan.
Khi so sánh GPU A100 40 GB với GPU A100 80 GB trên máy chủ Dell EMC DSS 8440, GPU sau cho thấy hiệu suất tăng 11%. Trên máy chủ Dell EMC PowerEdge R750xa, GPU A100 PCIe 80 GB hoạt động tốt hơn 12% so với GPU A100 PCIe 40 GB. Máy chủ Dell EMC PowerEdge XE8545 đã xác nhận kết quả này đối với việc gửi MLPerf v1.1; GPU A100 SXM 80 GB hoạt động tốt hơn ba phần trăm so với một hệ thống giống hệt từ lần gửi MLPerf v1.0.
So sánh GPU A30 và A40 cho thấy GPU trước đây đã đạt được mức cải thiện hiệu suất đáng chú ý là 42% trong khi duy trì máy chủ Dell EMC DSS 8440.
So sánh giữa GPU T4, A30 và A10 cho thấy GPU A30 hoạt động tốt hơn đáng kể so với GPU T4 và được coi là một bản nâng cấp tốt cho khối lượng công việc ML của bạn. GPU T4, A30 MIG và A100 MIG được so sánh dựa trên kết quả từ điểm chuẩn ResNet50 và SSD-ResNet34.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...