
Tin tức
Hiệu suất đào tạo Deep Learning trên Máy chủ Dell EMC PowerEdge R7525 với GPU NVIDIA A100
Tổng quan
Máy chủ Dell EMC PowerEdge R7525 , được phát hành gần đây, hỗ trợ GPU NVIDIA A100 Tensor Core . Đây là một máy chủ dựa trên giá đỡ 2U, hai ổ cắm, được thiết kế để chạy các khối lượng công việc phức tạp sử dụng bộ nhớ, dung lượng I/O và các tùy chọn mạng có khả năng mở rộng cao. Hệ thống này dựa trên bộ xử lý AMD EPYC thế hệ thứ 2 (tối đa 64 lõi), có tối đa 32 DIMM và có các khe cắm mở rộng hỗ trợ PCI Express (PCIe) 4.0. Máy chủ hỗ trợ các ổ đĩa SATA, SAS và NVMe và tối đa ba bộ tăng tốc 300 W chiều rộng gấp đôi hoặc sáu bộ tăng tốc 75 W chiều rộng đơn.
Hình dưới đây cho thấy giao diện phía trước của máy chủ:

Hình 1: Máy chủ Dell EMC PowerEdge R7525
Blog này tập trung vào hiệu suất đào tạo deep learning của một máy chủ PowerEdge R7525 với hai GPU NVIDIA A100-PCIe. Kết quả của việc sử dụng hai GPU NVIDIA V100S trong cùng một hệ thống PowerEdge R7525 được trình bày dưới dạng dữ liệu tham khảo. Chúng tôi cũng trình bày kết quả từ bài kiểm tra GEMM cuBLAS và mô hình ResNet-50 tạo thành điểm chuẩn MLPerf Training v0.7.
Bảng sau đây cung cấp chi tiết cấu hình của hệ thống PowerEdge R7525 đang thử nghiệm:
| Thành phần | Sự mô tả |
| bộ vi xử lý | Bộ vi xử lý 32 nhân AMD EPYC 7502 |
| Kỉ niệm | 512 GB (32 GB 3200 tấn/giây * 16) |
| đĩa cục bộ | SSD 2 x 1,8 TB (Không RAID) |
| Hệ điều hành | Máy chủ Linux dành cho doanh nghiệp RedHat 8.2 |
| GPU | Một trong những điều sau đây:
|
| trình điều khiển CUDA | 450.51.05 |
| bộ công cụ CUDA | 11,0 |
| Cài đặt bộ xử lý > Bộ xử lý logic | Vô hiệu hóa |
| Hồ sơ hệ thống | Màn biểu diễn |
Đại số tuyến tính cơ bản CUDA
Thư viện Đại số tuyến tính cơ bản CUDA (cuBLAS) là phiên bản CUDA của các chương trình con đại số tuyến tính cơ bản tiêu chuẩn, một phần của CUDA-X. NVIDIA cung cấp nhị phân cublasMatmulBench, có thể được sử dụng để kiểm tra hiệu suất của phép nhân ma trận chung (GEMM) trên một GPU. Kết quả của thử nghiệm này phản ánh hiệu suất của một ứng dụng lý tưởng chỉ chạy phép nhân ma trận ở dạng TFLOPS cao nhất mà GPU có thể mang lại. Mặc dù kết quả điểm chuẩn GEMM có thể không đại diện cho hiệu suất ứng dụng trong thế giới thực, nhưng đây vẫn là điểm chuẩn tốt để chứng minh khả năng thực hiện của các GPU khác nhau.
Các định dạng chính xác như FP64 và FP32 rất quan trọng đối với khối lượng công việc HPC; các định dạng chính xác như INT8 và FP16 rất quan trọng đối với suy luận học sâu. Chúng tôi dự định thảo luận về những màn trình diễn được quan sát này trong các blog suy luận và HPC sắp tới của chúng tôi.
Vì các định dạng chính xác của FP16, FP32 và TF32 là bắt buộc đối với hiệu suất đào tạo deep learning nên blog tập trung vào các định dạng này.
Hình dưới đây cho thấy kết quả mà chúng tôi quan sát được:
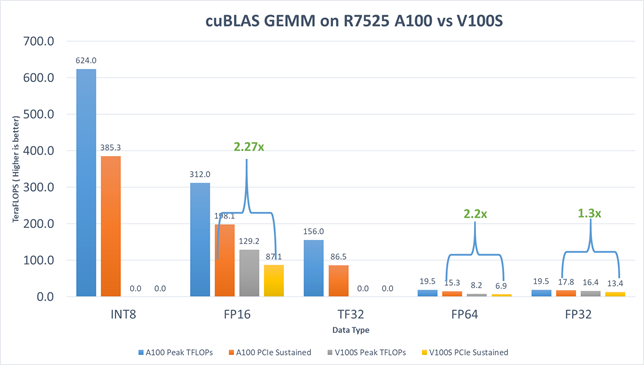
Hình 2: Hiệu suất GEMM cuBLAS trên máy chủ PowerEdge R7525 với GPU NVIDIA V100S-PCIe-32G và NVIDIA A100-PCIe-40G
Các kết quả bao gồm:
- Đối với FP16, HGEMM TFLOPs của GPU NVIDIA A100 nhanh hơn 2,27 lần so với GPU NVIDIA V100S.
- Đối với FP32, SGEMM TFLOPs của GPU NVIDIA A100 nhanh hơn 1,3 lần so với GPU NVIDIA V100S.
- Đối với TF32, dự kiến sẽ cải thiện hiệu suất mà không cần thay đổi mã cho các ứng dụng học sâu trên GPU NVIDIA A100 mới. Kỳ vọng này là do các hoạt động toán học được chạy trên GPU NVIDIA A100 Tensor Cores với định dạng chính xác TF32 mới. Mặc dù TF32 làm giảm độ chính xác đi một chút, nó vẫn duy trì phạm vi hoạt động của FP32 và đạt được sự cân bằng tuyệt vời giữa tốc độ và độ chính xác. Phép nhân ma trận tăng đáng kể từ 13,4 TFLOPS (FP32 trên GPU NVIDIA V100S) lên 86,5 TFLOPS (TF32 trên GPU NVIDIA A100).
Đào tạo MLPerf v0.7 ResNet-50
MLPerf là bộ điểm chuẩn đo hiệu suất của khối lượng công việc máy học (ML). Bộ điểm chuẩn Đào tạo MLPerf đo tốc độ hệ thống có thể đào tạo các mô hình ML.
Hình dưới đây cho thấy kết quả hoạt động của ResNet-50 theo tiêu chuẩn MLPerf Training v0.7:

Hình 3: Hiệu năng MLPerf Training v0.7 ResNet-50 trên máy chủ PowerEdge R7525 với GPU NVIDIA V100S-PCIe-32G và NVIDIA A100-PCIe-40G
Số liệu cho quá trình đào tạo ResNet-50 là số phút mà hệ thống đang thử nghiệm dành để đào tạo bộ dữ liệu nhằm đạt được độ chính xác 75,9%. Cả hai đều chạy bằng hai GPU NVIDIA A100 và hai GPU NVIDIA V100S được hội tụ ở kỷ nguyên thứ 40 . NVIDIA A100 chạy mất 166 phút để hội tụ, nhanh hơn 1,8 lần so với NVIDIA V100S chạy. Về thông lượng, hai GPU NVIDIA A100 có thể xử lý 5240 hình ảnh mỗi giây, cũng nhanh hơn 1,8 lần so với hai GPU NVIDIA V100S.
Sự kết luận
Máy chủ Dell EMC PowerEdge R7525 với hai GPU NVIDIA A100-PCIe thể hiện hiệu suất tối ưu cho khối lượng công việc đào tạo deep learning. GPU NVIDIA A100 cho thấy hiệu suất được cải thiện nhiều hơn so với GPU NVIDIA V100S.
Để đánh giá hiệu suất ứng dụng và khối lượng công việc học sâu và HPC với máy chủ PowerEdge R7525 được hỗ trợ bởi GPU NVIDIA, hãy liên hệ với HPC & AI Innovation Lab .
Bài viết mới cập nhật
Tăng tốc đổi mới và tính bền vững của AI: Dell PowerScale F910 mật độ cao, hiệu suất cao
Tăng tốc đổi mới và tính bền vững của AI: Dell ...
Khả năng hiển thị là điều bắt buộc tuyệt đối đối với an ninh
Tìm hiểu cách Dell và Absolute sử dụng dữ liệu từ ...
Dell Reconnect kỷ niệm 20 năm tái chế
Hãy kỷ niệm 20 năm Dell Reconnect và tái chế các ...
Nhật ký của một Kỹ sư Hệ thống VFX—Phần 1: Thống kê isi
Chào mừng bạn đến với bài đăng đầu tiên trong loạt ...