
Tổng quan
Máy chủ Dell PowerEdge R7525 được trang bị bộ xử lý AMD EPYC thế hệ thứ 2 đã được phát hành như một phần của danh mục máy chủ Dell. Nó là một máy chủ dạng 2U có thể gắn trên giá được thiết kế cho khối lượng công việc HPC. Dell Technologies gần đây đã thêm hỗ trợ cho GPGPU NVIDIA A100 cho máy chủ PowerEdge R7525, hỗ trợ tối đa ba GPGPU NVIDIA băng thông kép dựa trên PCIe. Blog này mô tả hiệu suất một nút của các ứng dụng HPC được chọn với cả GPGPU một và hai NVIDIA A100 PCIe.
Máy gia tốc NVIDIA Ampere A100 là một trong những máy gia tốc tiên tiến nhất hiện có trên thị trường, hỗ trợ hai yếu tố hình thức:
- Phiên bản PCIe
- Phiên bản SXM4 thùng lửng
Máy chủ PowerEdge R7525 chỉ hỗ trợ phiên bản PCIe của bộ tăng tốc NVIDIA A100.
Bảng sau so sánh GPGPU NVIDIA A100 với GPGPU NVIDIA V100S:
| NVIDIA A100 GPGPU | GPGPU NVIDIA V100S | |||
| Yếu tố hình thức | SXM4 | PCIe Gen4 | SXM2 | PCIe thế hệ 3 |
| kiến trúc GPU | Ampe | Volta | ||
| Kích thước bộ nhớ | 40 GB | 40 GB | 32 GB | 32 GB |
| lõi CUDA | 6912 | 5120 | ||
| đồng hồ gốc | 1095 MHz | 765 MHz | 1290 MHz | 1245 MHz |
| Tăng tốc đồng hồ | 1410 MHz | 1530 MHz | 1597 MHz | |
| Đồng hồ ghi nhớ | 1215 MHz | 877 MHz | 1107 MHz | |
| hỗ trợ MIG | Đúng | Không | ||
| Băng thông bộ nhớ cao nhất | Lên đến 1555 GB/giây | Lên đến 900 GB/giây | Lên đến 1134 GB/giây | |
| Tổng công suất bảng | 400W | 250W | 300 W | 250W |
NVIDIA A100 GPGPU mang đến những đổi mới và tính năng cho các ứng dụng HPC như sau:
- GPU đa phiên bản (MIG)— NVIDIA A100 GPGPU có thể được chuyển đổi thành tối đa bảy phiên bản GPU, được cách ly hoàn toàn ở cấp độ phần cứng, mỗi phiên bản sử dụng lõi và bộ nhớ băng thông cao của riêng chúng.
- HBM2— NVIDIA A100 GPGPU đi kèm với 40 GB bộ nhớ băng thông cao (HBM2) và cung cấp băng thông lên tới 1555 GB/giây. Băng thông bộ nhớ với GPGPU NVIDIA A100 cao hơn 1,7 lần so với thế hệ GPU trước.
Cấu hình máy chủ
Bảng sau đây hiển thị cấu hình máy chủ PowerEdge R7525 mà chúng tôi đã sử dụng cho blog này:
| Người phục vụ | PowerEdge R7525 |
| bộ vi xử lý | AMD thế hệ thứ 2 EPYC 7502, 32C, 2.5Ghz |
| Kỉ niệm | 512 GB (16 x 32 GB @3200MT/giây) |
| GPGPU | Một trong những điều sau đây:
2 x NVIDIA A100 PCIe 40 GB 2 x NVIDIA V100S PCIe 32 GB |
| bộ xử lý logic | Vô hiệu hóa |
| Hệ điều hành | Bản phát hành CentOS Linux 8.1 (4.18.0-147.el8.x86_64) |
| CUDA | 11.0 (Phiên bản trình điều khiển – 450.51.05) |
| gcc | 9.2.0 |
| Bộ KH&ĐT | OpenMPI-3.0 |
| HPL | hpl_cuda_11.0_ompi-4.0_ampere_volta_8-7-20 |
| HPCG | xhpcg-3.1_cuda_11_ompi-3.1 |
| GROMACS | v2020.4 |
kết quả điểm chuẩn
Các phần sau đây cung cấp kết quả điểm chuẩn của chúng tôi với các quan sát.
Điểm chuẩn Linpack hiệu suất cao
High Performance Linpack (HPL) là một điểm chuẩn hệ thống HPC tiêu chuẩn. Điểm chuẩn này đo sức mạnh tính toán của toàn bộ cụm hoặc máy chủ. Đối với nghiên cứu này, chúng tôi đã sử dụng HPL được biên dịch bằng thư viện NVIDIA.
Hình dưới đây cho thấy so sánh hiệu suất HPL cho máy chủ PowerEdge R7525 với GPGPU NVIDIA A100 hoặc NVIDIA V100S:
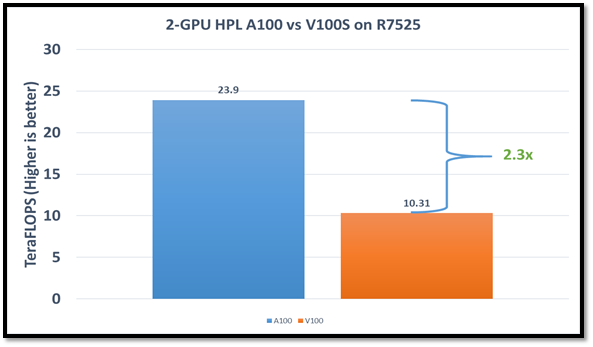
Hình 1: Hiệu suất HPL trên máy chủ PowerEdge R7525 với NVIDIA A100 GPGPU so với NVIDIA V100SGPGPU
Kích thước sự cố (N) lớn hơn đối với GPGPU NVIDIA A100 do dung lượng bộ nhớ GPU lớn hơn. Chúng tôi đã điều chỉnh kích thước khối (NB) được sử dụng với:
- NVIDIA A100 GPGPU đến 288
- NVIDIA V100S GPGPU đến 384
Bộ xử lý AMD EPYC cung cấp các tùy chọn cho nhiều kết hợp NUMA. Chúng tôi nhận thấy rằng giá trị tốt nhất là 4 NUMA trên mỗi ổ cắm (NPS=4), với NUMA trên mỗi ổ cắm 1 và 2 sẽ làm giảm hiệu suất lần lượt là 10% và 5%. Trong một nút PowerEdge R7525 duy nhất, NVIDIA A100 GPGPU cung cấp 12 TF trên mỗi thẻ bằng cách sử dụng cấu hình này mà không cần cầu nối NVLINK. Máy chủ PowerEdge R7525 với hai GPGPU NVIDIA A100 mang lại hiệu suất HPL cao hơn 2,3 lần so với cấu hình GPGPU NVIDIA V100S. Sự cải thiện về hiệu suất này là nhờ các Lõi Tensor có độ chính xác kép mới giúp tăng tốc toán học FP64.
Hình dưới đây cho thấy mức tiêu thụ năng lượng của máy chủ trong khi chạy HPL trên NVIDIA A100 GPGPU theo chuỗi thời gian. Mức tiêu thụ điện năng được đo bằng iDRAC. Máy chủ đạt 1038 Watts ở mức cao nhất do số GFLOPS cao hơn.
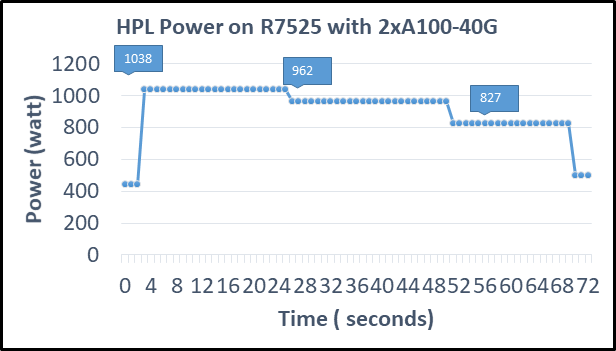
Hình2: Điện năng tiêu thụ khi chạy HPL
Điểm chuẩn Gradient liên hợp hiệu suất cao
Điểm chuẩn Gradient liên hợp hiệu suất cao (HPCG) dựa trên bộ giải gradient liên hợp, trong đó điều kiện tiên quyết là một phương pháp đa lưới phân cấp ba cấp sử dụng phương pháp Gauss-Seidel.
Như thể hiện trong hình dưới đây, HPCG hoạt động với tốc độ cao hơn 70 phần trăm với GPGPU NVIDIA A100 do băng thông bộ nhớ cao hơn:
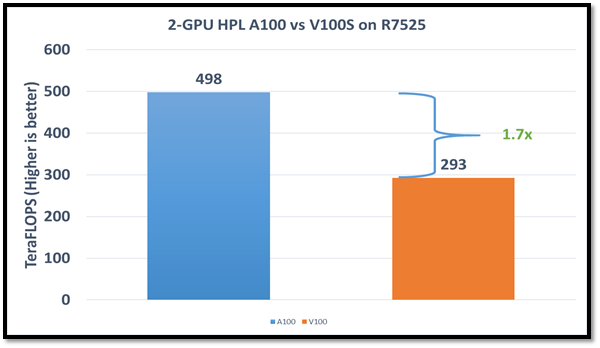
Hình 3: So sánh hiệu suất HPCG
Do kích thước bộ nhớ khác nhau, kích thước sự cố được sử dụng để đạt được hiệu suất tốt nhất trên NVIDIA A100 GPGPU là 512 x 512 x 288 và trên GPGPU NVIDIA V100S là 256 x 256 x 256. Đối với blog này, chúng tôi đã sử dụng NUMA trên mỗi ổ cắm (NPS )=4 và chúng tôi thu được kết quả mà không cần cầu nối NVLINK. Những kết quả này cho thấy rằng các ứng dụng như HPCG, phù hợp với bộ nhớ GPU, có thể tận dụng tối đa bộ nhớ GPU và hưởng lợi từ băng thông bộ nhớ cao hơn của NVIDIA A100 GPGPU.
GROMACS
Ngoài hai điểm chuẩn HPC cơ bản này (HPL và HPCG), chúng tôi cũng đã thử nghiệm GROMACS, một ứng dụng HPC. Chúng tôi đã biên soạn GROMACS 2020.4 với trình biên dịch CUDA và OPENMPI, như trong bảng sau:
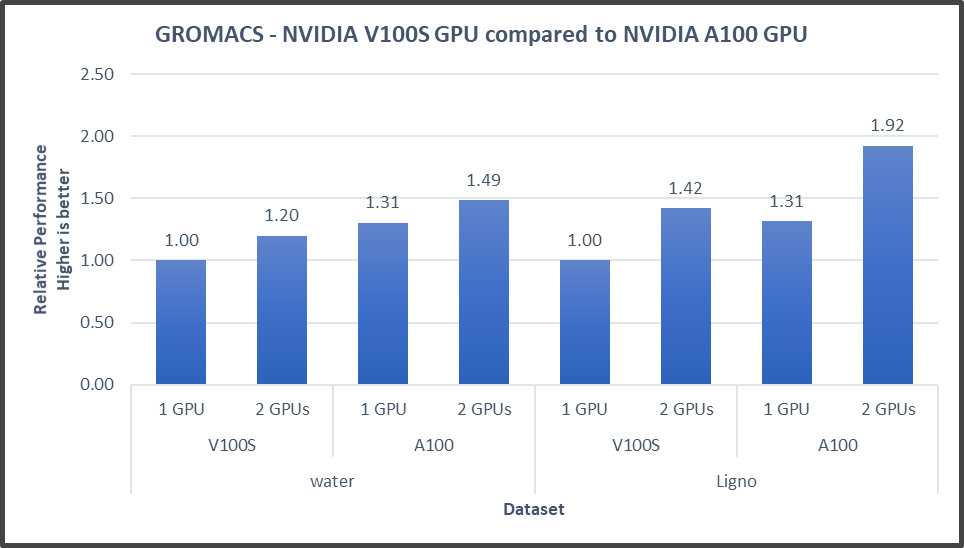
Hình 4: Hiệu năng GROMACS với NVIDIA GPGPU trên máy chủ PowerEdge R7525
Bản dựng GROMACS bao gồm MPI luồng (được tích hợp với gói GROMACS). Tất cả các số hiệu suất đã được ghi lại từ đầu ra “ns/ngày”. Chúng tôi đã đánh giá nhiều xếp hạng MPI, xếp hạng PME riêng biệt và các giá trị nstlist khác nhau để đạt được hiệu suất tốt nhất. Ngoài ra, chúng tôi đã sử dụng các cài đặt có biến môi trường tốt nhất cho GROMACS khi chạy. Việc chọn tổ hợp biến phù hợp giúp tránh được việc truyền dữ liệu tốn kém và mang lại hiệu suất tốt hơn đáng kể cho các bộ dữ liệu này.
Hiệu suất GROMACS dựa trên phân tích so sánh giữa GPGPU NVIDIA V100S và NVIDIA A100. Đoạn trích từ phân tích đa GPU một nút của chúng tôi cho hai bộ dữ liệu cho thấy hiệu suất được cải thiện khoảng 30 phần trăm với GPGPU NVIDIA A100. Kết quả này là do băng thông bộ nhớ của GPGPU NVIDIA A100 đã được cải thiện. (Để biết thông tin về cách thiết kế mã GROMACS cho phép giảm chi phí truyền bộ nhớ, hãy xem Blog của nhà phát triển: Tạo mô phỏng động lực học phân tử nhanh hơn với GROMACS 2020 .)
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...