
Tổng quan
Chúng tôi đã suy đoán rằng AMD Milan với các lõi Zen3 cho phép nhiều lõi hơn chia sẻ cùng một bộ đệm L3 có thể hoạt động tốt hơn cho các ứng dụng Trình tự thế hệ tiếp theo (NGS). So với AMD EPYC Rome tiền nhiệm, số lượng lõi chia sẻ bộ đệm L3 được tăng gấp đôi từ 4 lên 8 đối với kiểu bộ xử lý 64 lõi. Thêm vào đó, bộ đệm (cả L1 và L2) được nâng cấp với các trình tìm nạp trước mới và băng thông bộ nhớ được cải thiện.
Vì Milan và Rome dùng chung ổ cắm SP3, nên Dell EMC PowerEdge R6525 đã được chọn cho nghiên cứu điển hình và có thể giảm thiểu sự khác biệt giữa các hệ thống. Cấu hình máy chủ thử nghiệm được tóm tắt trong Bảng 1.
Bảng 1. Cấu hình nút điện toán đã thử nghiệm
| Dell EMC PowerEdge R6525 | |
| CPU | Đã thử nghiệm AMD Milan:
2x 7763 (Milan), 64 lõi, 2,45GHz – 3,5GHz Base-Boost, TDP 280W, 256 MB L3 Cache 2x 7713 (Milan), 64 lõi, 2.0GHz – 3.7GHz Base-Boost, TDP 225W, 256 MB L3 Cache 7543 (Milan), 32 lõi, 2,8 GHz – 3,7 GHz Base-Boost, TDP 225W, 256 MB bộ nhớ đệm L3 Đã thử nghiệm AMD Rome: 7702 (Rome), 64 nhân, 2,0 GHz – 3,35 GHz Base-Boost, TDP 200W, 256 MB bộ nhớ đệm L3 |
| ĐẬP | DDR4 256G (16Gb x 16) 3200 tấn/giây |
| hệ điều hành | RHEL 8.3 (4.18.0-240.el8.x86_64) |
| Mạng hệ thống tập tin | Mellanox InfiniBand HDR100 |
| Hệ thống tập tin | Giải pháp sẵn sàng của Dell EMC cho Bộ lưu trữ dung lượng cao HPC BeeGFS |
| Hồ sơ hệ thống BIOS | Hiệu suất được tối ưu hóa |
| Bộ xử lý logic | Vô hiệu hóa |
| Công nghệ ảo hóa | Vô hiệu hóa |
| BWA | 0.7.15-r1140 |
| sambamba | 0.7.0 |
| Samtools | 1.6 |
| GATK | 3.6-0-g89b7209 |
Dữ liệu thử nghiệm được chọn từ một trong các Gen bạch kim của Illumina. ERR194161 đã được xử lý với Illumina HiSeq 2000 do Illumina gửi và có thể được lấy từ EMBL-EBI . Định danh DNA của cá nhân này là NA12878. Mô tả dữ liệu từ trang web được liên kết cho thấy rằng mẫu này có độ bao phủ >30x và đạt ~53x.
Đánh giá hiệu suất
Mô tả các bước trong Đường ống BWA-GATK
Trong một quy trình BWA-GATK điển hình, có nhiều bước và mỗi bước bao gồm các ứng dụng khác nhau hoạt động khác biệt. Như được hiển thị trong Bảng 3, các ứng dụng trong một số bước không hỗ trợ hoạt động đa luồng. Các bước này có vấn đề vì chỉ có một số cách để cải thiện hiệu suất.
Bảng 2. Các bước trong quy trình BWA-GATK và các công cụ
| bước | Các ứng dụng | Hỗ trợ đa luồng |
| Ánh xạ & Sắp xếp | BWA, samtools, sambaba | Đúng |
| Đánh dấu trùng lặp | sambamba | Đúng |
| Tạo mục tiêu sắp xếp lại | GATK RealignerTargetCreator | Đúng |
| Chèn/Xóa Sắp xếp lại | GATK IndelRealigner | Không |
| Hiệu chuẩn lại cơ sở | GATK BaseRecalibrator | Đúng |
| haplotypercaller | GATK haplotypeCaller | Đúng |
| GVCF kiểu gen | Kiểu gen GATKGVCF | Đúng |
| Hiệu chuẩn lại biến thể | GATK VariantRecalibrator | Không |
| Áp dụng hiệu chỉnh lại biến thể | Áp dụng GATK Hiệu chỉnh lại | Không |
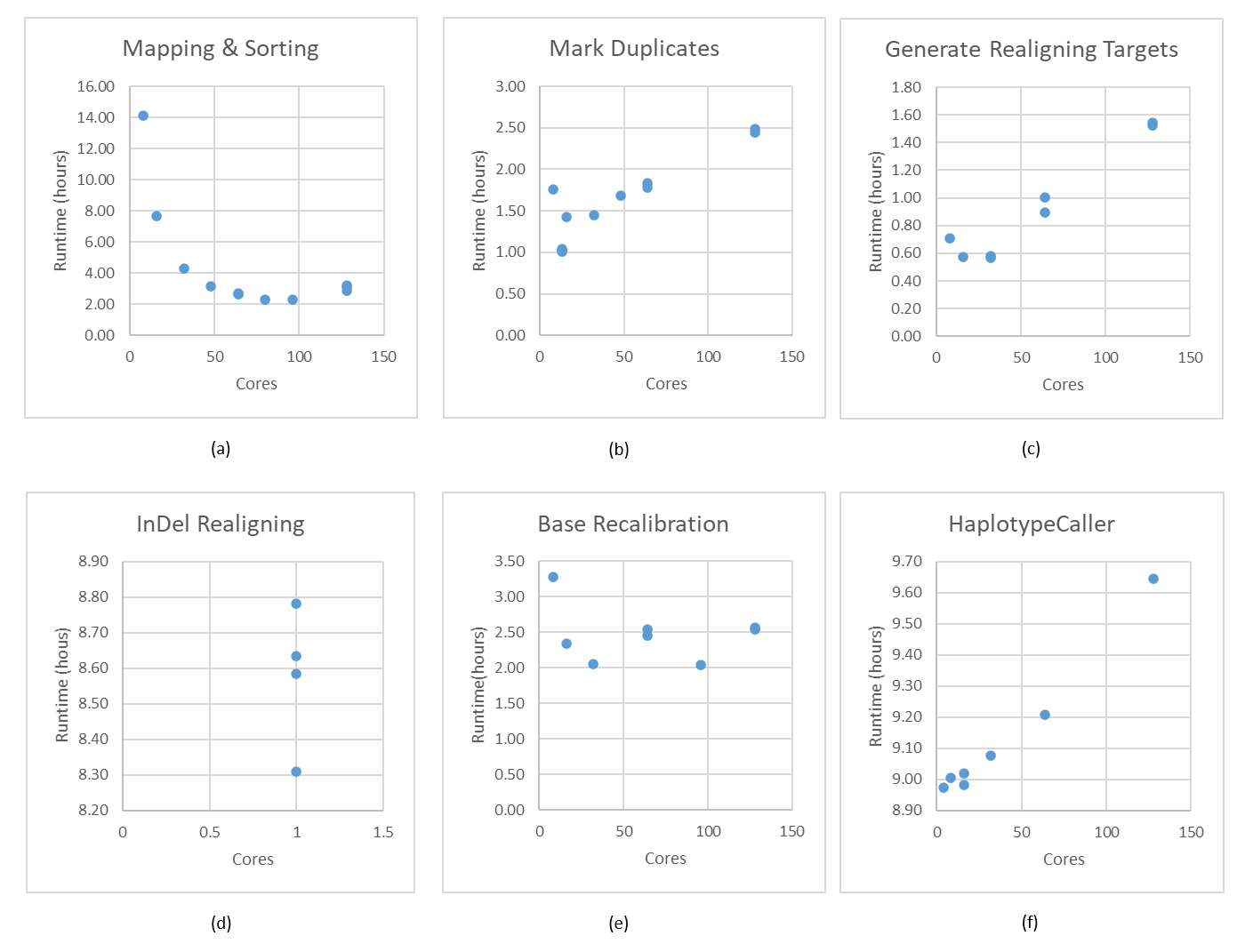
Các ứng dụng luồng đơn, đặc biệt là các bước Hiệu chỉnh lại biến thể và Áp dụng hiệu chỉnh lại biến thể không hiển thị biến thể thời gian chạy do thuật toán xác định và đầu vào cho các bước này nhỏ. Do đó, hai bước này không được báo cáo trong Hình 1. Bước đầu tiên, Ánh xạ & Sắp xếp mở rộng quy mô khi số lượng lõi tăng lên (Hình 1, (a)). Ngoài ra, GVCF kiểu gen không được bao gồm trong Hình 1 mặc dù nó hỗ trợ hoạt động đa luồng vì một lý do tương tự.
Burrows-Wheeler Aligner (BWA) là một trong những bộ căn chỉnh trình tự ngắn phổ biến nhất để phân tích căn chỉnh không có khoảng cách. BWA mở rộng tốt cho đến 32 lõi và mức sử dụng CPU giảm đáng kể sau 32 lõi. Việc cải thiện thời gian chạy trở nên không đáng kể với số lõi cao hơn lớn hơn 32. Sử dụng hơn 80 lõi cho bước này là lãng phí tài nguyên.
Sambamba tương thích với Picard được sử dụng để đánh dấu các lần đọc trùng lặp. Hành vi của sambaba được vẽ trong Hình 1, (b). Do tính chất song song cao của thiết kế, mức tiêu thụ bộ nhớ tăng lên để tạo ra nhiều bảng băm hơn cho các luồng bổ sung. Thật đáng ngạc nhiên, trình tự bộ gen toàn bộ con người 50x (WGS) không đủ lớn để sử dụng hơn 13 lõi cho phần mềm được thiết kế tốt.
Sau bước Đánh dấu trùng lặp, Bộ công cụ phân tích bộ gen, tức là GATK, được viết bằng Java đóng vai trò quan trọng trong việc đo lường hiệu suất và tạo câu trả lời. Các bước này hoàn toàn không mở rộng như trong Hình 1, (c) (d) (e) và (f). Một cách tiếp cận tốt hơn sẽ được thảo luận trong công việc trong tương lai để xử lý hành vi sai trái trong môi trường đa lõi và nhiều ổ cắm.
Hiệu suất mẫu đơn
So sánh ổ cắm với ổ cắm
Thử nghiệm này không phải là một phép so sánh công bằng vì phần lớn các bước sẽ không tận dụng được lợi thế của việc sử dụng tất cả các lõi ngoại trừ 7543 với 32 lõi. Tuy nhiên, sự so sánh này sẽ giúp quyết định xem CPU nào là tốt nhất cho bài kiểm tra thông lượng.
Bảng 3 tóm tắt thời gian chạy tổng thể cho đường dẫn BWA-GATK và khó có thể nói cái nào tốt hơn về tổng thời gian chạy. Cần nhiều thử nghiệm hơn để phân biệt sự khác biệt về hiệu suất trong các bước GATK. Ngoài ra, kết quả từ 7502 và 7402 là từ các thử nghiệm trước đó với các môi trường khác nhau.
Bước lập bản đồ & Sắp xếp là bước duy nhất mà chúng tôi có thể đạt được mức cao nhất của các biến thể hiệu suất thực trên các CPU khác nhau trong Bảng 3. Ước tính sơ bộ mức cải thiện hiệu suất từ 7702 lên 7763 là 7% trong khi mức tăng hiệu suất là 5% từ 7702 lên 7713.
Đáng ngạc nhiên là bước Hiệu chỉnh lại Cơ sở cho kết quả tương tự như bước Lập bản đồ & Sắp xếp, tức là cải thiện 8% và 3%.
Bảng 3. So sánh hiệu suất BWA-GATK giữa Milan và Rome. Số lượng lõi được sử dụng cho thử nghiệm được đặt trong ngoặc đơn.
| bước | Thời gian chạy (giờ) | |||||
| AMD
7763 64c 2,45GHz |
AMD
7713 64c 2.0GHz |
AMD
7543 32c 2,8 GHz |
AMD
7702 64c 2.0GHz |
AMD
7502 32c 2,5 GHz |
AMD
7402 24c 3.0GHz |
|
| Ánh xạ & Sắp xếp | 2,44
(64) |
2,49
(64) |
3,69
(32) |
2,63
(64) |
4,68
(32) |
5,73
(24) |
| Đánh dấu trùng lặp | 1,07
(13) |
1.10
(13) |
1,01
(13) |
1,01
(13) |
0,93
(13) |
0,94
(13) |
| Tạo mục tiêu sắp xếp lại | 0,55
(32) |
0,56
(32) |
0,50
(32) |
0,58
(32) |
0,45
(32) |
0,44
(32) |
| Chèn/Xóa Sắp xếp lại | 8,73
(1) |
9.13
(1) |
7,73
(1) |
8,78
(1) |
8h30
(1) |
8.21
(1) |
| Hiệu chuẩn lại cơ sở | 2,27
(32) |
2,38
(32) |
2.17
(32) |
2,46
(32) |
2,52
(32) |
2,67
(24) |
| haplotypercaller | 10.20
(16) |
10.57
(16) |
9h15
(16) |
9.02
(16) |
9.33
(16) |
9,05
(16) |
| GVCF kiểu gen | 0,02
(32) |
0,02
(32) |
0,01
(32) |
0,02
(32) |
0,01
(32) |
0,01
(24) |
| Hiệu chuẩn lại biến thể | 0,31
(1) |
0,20
(1) |
0,17
(1) |
0,12
(1) |
0,21
(1) |
0,13
(1) |
| Áp dụng hiệu chỉnh lại biến thể | 0,01
(1) |
0,01
(1) |
0,01
(1) |
0,01
(1) |
0,01
(1) |
0,01
(1) |
| Tổng thời gian chạy (giờ) | 25,59 | 26,47 | 24,44 | 24,64 | 26,46 | 27,25 |
Hiệu suất nhiều mẫu – Thông lượng
Một cách thông thường để chạy đường dẫn NGS là xử lý nhiều mẫu trên một nút điện toán và sử dụng nhiều nút điện toán để tối đa hóa thông lượng. Tuy nhiên, lần này các thử nghiệm được thực hiện trên một nút điện toán duy nhất do số lượng máy chủ khả dụng tại thời điểm này là có hạn.
Đường ống hiện tại gọi một số lượng lớn các thao tác đường ống trong bước đầu tiên để giảm thiểu số lượng ghi tệp trung gian. Mặc dù điều này giúp tiết kiệm một ngày thời gian chạy và giảm đáng kể mức sử dụng bộ nhớ, nhưng chi phí gọi đường ống khá nặng. Do đó, điều này giới hạn số lượng xử lý mẫu đồng thời. Thông thường, một quá trình âm thầm thất bại khi không còn đủ tài nguyên để bắt đầu một quá trình bổ sung.
Tuy nhiên, những thất bại gặp phải trong nghiên cứu này khá khác so với những quan sát trước đó. 10 đường ống bắt đầu trong R6525 với 2x 7763 chỉ duy trì trung bình 6 đường ống với 50x WGS của con người. Bốn đường ống không thành công với lỗi đường ống bị hỏng cho thấy một số loại hoạt động của tệp. Bộ lưu trữ BeeGFS hiện tại dành cho thử nghiệm được thiết kế để có dung lượng cao, băng thông ghi tuần tự theo lý thuyết là 25 GB/giây. Tuy nhiên, bạn có thể đạt được khoảng 16 GB/giây khi không có mức sử dụng nhiều được tải trên bộ nhớ này trong môi trường bộ nhớ dùng chung. Đây không phải là một môi trường lý tưởng cho bất kỳ thực hành điểm chuẩn nào; tuy nhiên, các kết quả ở đây khá hữu ích để xem hiệu suất của các hệ thống này trông như thế nào trong cuộc sống thực.
Như được hiển thị trong Bảng 4, số lượng mẫu tối đa có thể được xử lý cùng lúc là khoảng 4 hoặc 5 và thông lượng toàn bộ bộ gen của con người mỗi ngày là ~4,79 50x mỗi ngày có thể đạt được với môi trường hiện tại.
Bảng 4. Kiểm tra thông lượng cho Milan 7763
| bước | Thời gian chạy (giờ) | ||||
| 1 mẫu | 2 mẫu | 4 mẫu | 6 mẫu | 10 mẫu | |
| Số lượng mẫu không thành công | 0 | 0 | 0 | 1 | 4 |
| Ánh xạ & Sắp xếp | 2,44 | 2,91 | 4,33 | 5,86 | 8.33 |
| Đánh dấu trùng lặp | 1,07 | 1,40 | 1,69 | 1,31 | 5,51 |
| Tạo mục tiêu sắp xếp lại | 0,55 | 0,88 | 1,77 | 0,50 | 2.07 |
| Chèn/Xóa Sắp xếp lại | 8,73 | 8,97 | 8,92 | 8,92 | 9,70 |
| Hiệu chuẩn lại cơ sở | 2,27 | 2,50 | 2,79 | 3,26 | 3,67 |
| haplotypercaller | 10.20 | 10.57 | 10.27 | 9,91 | 9,96 |
| GVCF kiểu gen | 0,02 | 0,11 | 0,10 | 0,10 | 0,15 |
| Hiệu chuẩn lại biến thể | 0,31 | 0,25 | 0,20 | 0,21 | 0,36 |
| Áp dụng hiệu chỉnh lại biến thể | 0,01 | 0,02 | 0,01 | 0,01 | 0,03 |
| Tổng thời gian chạy (giờ) | 25,59 | 27,62 | 30.08 | 30.08 | 39,79 |
| Bộ gen mỗi ngày | 0,94 | 1,74 | 4,79 | 3,99 | 3,62 |
Phần kết luận
Lĩnh vực phân tích dữ liệu NGS đã và đang phát triển nhanh chóng về tốc độ tăng trưởng dữ liệu và các biến thể dữ liệu. Tuy nhiên, cộng đồng đã không làm được nhiều việc để thích nghi với các công nghệ mới có sẵn như máy gia tốc. Thay vì cải thiện chất lượng code, cộng đồng phải đối mặt với việc phân tích dữ liệu mà không xử lý đa luồng vì GATK phiên bản 4 trở lên không hỗ trợ đa luồng nữa trong khi số lượng lõi trong CPU tăng nhanh.
Đã đến lúc người dùng cần suy nghĩ về cách giải quyết vấn đề này. Một cách đơn giản để tránh vấn đề này là thực hiện song song hóa mức dữ liệu. Mặc dù việc đưa ra quyết định về thời điểm phân tách dữ liệu là khá khó khăn, nhưng chắc chắn có thể thực hiện được với các biện pháp can thiệp cẩn thận trong quy trình BWA-GATK hiện có mà không làm giảm sức mạnh thống kê với số lượng dữ liệu tuyệt đối. Nếu mỗi đoạn dữ liệu nhỏ hơn đi qua một đường ống riêng lẻ trên mỗi lõi và được hợp nhất ở cuối, thì có thể đạt được hiệu suất tốt hơn trên một mẫu đơn lẻ. Mức tăng hiệu suất này có thể dẫn đến thông lượng cao hơn nếu thời gian chạy tổng thể giảm đáng kể.
Tuy nhiên, Milan 7763 hoặc 7713 là một ứng cử viên xuất sắc để bao gồm cả các đường ống dựa trên đa luồng hiện tại và các đường ống dẫn hướng song song ở mức dữ liệu trong tương lai với nhiều lõi khả dụng hơn.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...