
Tin tức
Học máy sử dụng nền tảng Red Hat OpenShift Container (3)
Tổng quan
Khởi chạy sổ ghi chép Jupyter
Jup y ter là một công cụ cộng tác mà các nhà khoa học dữ liệu sử dụng để phát triển và thực thi mã, tài liệu và trực quan hóa trong quy trình phát triển mô hình ML của họ. Để biết thêm thông tin, hãy xem tại đây
Để tạo và quản lý máy chủ notebook trong triển khai Kubeflow của bạn :
- Trong bảng điều khiển Kubeflow, nhấp vào Notebooks .
Một cửa sổ quản lý sổ ghi chép sẽ mở ra, như thể hiện trong Hình 4.

Hình 4. Cửa sổ Jupyter Notebook Servers
- Nhấp vào Máy chủ mới ở góc trên cùng bên phải của ngăn Máy chủ Máy tính xách tay.
Hình 5 hiển thị menu hiện có sẵn để định cấu hình máy chủ sổ ghi chép với nhiều tùy chọn khác nhau. Người dùng nên ở mức tối thiểu
- Đặt tên cho máy chủ sổ ghi chép mới .
- Chọn không gian tên mà máy chủ sổ ghi chép sẽ thuộc về.
- Chọn một trong các hình ảnh máy chủ sổ ghi chép TensorFlow tiêu chuẩn đi kèm trong quá trình triển khai Kubeflow.
- Sau khi bạn đã chọn các tùy chọn của mình , hãy nhấp vào Đẻ trứng ở cuối cửa sổ .
Một nhóm được triển khai bằng cách sử dụng hình ảnh bộ chứa TensorFlow mà bạn đã chỉ định và có thể xác minh nhóm này bằng cách mở phần Notebook của bảng điều khiển Kubeflow, như minh họa trong Hình 6.
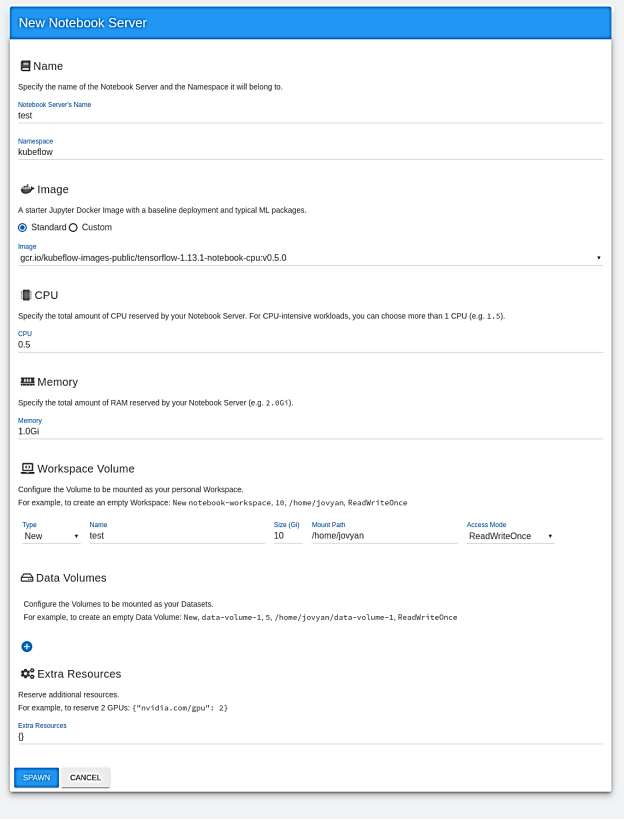
Hình 5. Tạo Máy chủ Máy tính xách tay Jupyter
Máy chủ sổ ghi chép được tạo bằng cách sử dụng các tùy chọn đã chọn của bạn , như thể hiện trong hình sau:
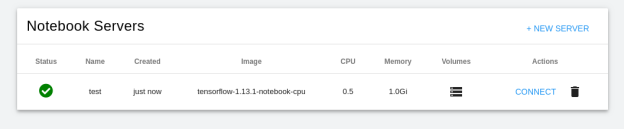
Hình 6. Máy chủ Notebook được định cấu hình
- Nhấp vào Kết nối .
Jupyter n notebook mở ra , như thể hiện trong Hình 7.

Hình 7. Máy tính xách tay Jupyter n
- Để xác minh rằng phiên bản TensorFlow chính xác đã được cài đặt , hãy nhấp vào Mới .
Một ô chứa mã trống sẽ mở ra, trong đó bạn có thể chạy mã Python để hiển thị phiên bản TensorFlow được cài đặt trong sổ tay điện tử . Hình 8 cho thấy phiên bản dự kiến, v1.13.1 :
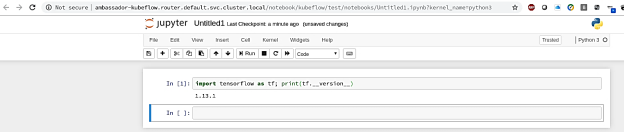
Hình 8. Xác minh cài đặt TensorFlow
Đào tạo kéo căng
Một trạng thái quan trọng khác trong vòng đời ML là đào tạo các mô hình mạng thần kinh. Vì đây là phần sử dụng nhiều tính toán nhất của ML/DL nên các nhà khoa học dữ liệu cần có kết quả càng nhanh càng tốt để đạt hiệu quả.
TFJob s
Kubeflow sử dụng tài nguyên tùy chỉnh Kubernetes , TFJobs , để chạy các công việc đào tạo TensorFlow theo cách tự động và cho phép các nhà khoa học dữ liệu theo dõi tiến độ công việc bằng cách xem kết quả . Kubeflow cung cấp một đại diện YAML cho TFJobs . Để biết thêm thông tin, hãy xem Đào tạo TensorFlow (TFJob) .
Để chạy các công việc đào tạo một cách hiệu quả và tận dụng lợi thế của các tính năng tối ưu hóa phần cứng có sẵn trong bộ xử lý có khả năng thay đổi kích thước mới nhất của Intel Xeon , Dell EMC khuyên bạn nên sử dụng Khuôn khổ ML Tensorflow được Tối ưu hóa của Intel . Khung ML TensorFlow được tối ưu hóa sử dụng các thư viện nguyên thủy MKL-DNN của Intel để tận dụng các tính năng kiến trúc của Intel như AVX2 để nhân ma trận dấu phẩy động và chạy các công việc đào tạo Tensorflow trên CPU Intel .
Đào tạo phân tán TensorFlow sử dụng khả năng tính toán của nhiều nút để hoạt động trên cùng một đào tạo mạng thần kinh , giúp giảm thời gian thực hiện . Nhiều thành phần đóng vai trò kích hoạt đào tạo phân tán g. Ví dụ: Máy chủ tham số (PS) lưu trữ các tham số mà từng công nhân cần , trong khi các nút công nhân chịu trách nhiệm tính toán hoặc đào tạo mô hình .
R mở một TFJob
Để chứng minh khả năng của bộ xử lý Intel Xeon Có thể thay đổi quy mô mới nhất trong việc chạy các công việc đào tạo ML/DL và hiệu quả mở rộng quy mô của Nền tảng OpenShift, chúng tôi đã chạy tiêu chuẩn TensorFlow CNN thường được sử dụng để đào tạo mô hình ResNet50.
Để triển khai TFJob, chúng tôi đã sử dụng tệp YAML sau :
|
tf_intel_cnn.yaml |
||
| apiVersion: kubeflow.org/v1beta2
loại: TFJob metadata: nhãn: thí nghiệm: thí nghiệm Tên: inteltfjob không gian tên: mặc định thông số kỹ thuật: tfReplicaSpecs:
|
tái bút:
nútChọn: giới thiệu: ps bản sao: 1 bản mẫu: metadata: tạoDấu thời gian: null thông số kỹ thuật: nútChọn: giới thiệu: ps hộp đựng: – lập luận: – nohup – bộ đệm – con trăn – /opt/điểm chuẩn/tf_cnn_benchmarks.py – –batch_size=256 – –model=resnet50 – –variable_update=parameter_server – –mkl=Đúng – –num_batches=100 – –num_inter_threads=2 – –num_intra_threads=40 – –data_format=NHWC – –kmp_blocktime=1 – –local_parameter_device=cpu hình ảnh: docker.io/intelaipg/intel-optimized-tensorflow tên: tensorflow cổng: – cảng container: 2222 tên: cổng tfjob tài nguyên: {} workingDir: /home/benchmarks/tf_cnn_benchmarks.py khởi động lạiPolicy: OnFailure
|
Công nhân:
nútChọn: giới thiệu: công nhân bản sao: 2 bản mẫu: metadata: tạoDấu thời gian: null thông số kỹ thuật: nútChọn: giới thiệu: công nhân hộp đựng: – lập luận: – nohup – bộ đệm – con trăn – /opt/điểm chuẩn/tf_cnn_benchmarks.py – –batch_size=500 – –model=resnet50 – –variable_update=parameter_server – –mkl=Đúng – –num_batches=100 – –num_inter_threads=2 – –num_intra_threads=40 – –data_format=NHWC – –kmp_blocktime=1 – –local_parameter_device=cpu hình ảnh: docker.io/intelaipg/intel-optimized-tensorflow tên: tensorflow cổng: – cảng container: 2222 tên: cổng tfjob tài nguyên: {} workingDir: /home/benchmarks/tf_cnn_benchmarks.py khởi động lạiPolicy: OnFailure
|
Lưu ý: Hình ảnh vùng chứa được chỉ định trong tệp docker.io/intelaipg/intel-optimized-tensorflow , sử dụng thư viện Intel MKL-DNN để tối ưu hóa hiệu suất TensorFlow trên bộ xử lý Intel Xeon. Các tham số do Intel đề xuất, chẳng hạn như sử dụng NUM_INTER_THREADS và NUM_INTRA_THREADS để chỉ định tính song song giữa các tác vụ và trong tác vụ , được chuyển thành đối số cho quá trình đào tạo để tận dụng tất cả các lõi có sẵn trên CPU Xeon và tối đa hóa tính song song .
- Để đăng ký tệp YAML, hãy chạy lệnh sau:
$ oc áp dụng -f tf_intel_cnn.yaml
- Để chạy điểm chuẩn Tensorflow bằng cách thực thi TFJob, hãy đặt các biến bằng cách chạy các lệnh sau :
xuất $ KUBEFLOW_TAG=v0.5.0
$ export KUBEFLOW_SRC=${HOME}/kubeflow-${KUBEFLOW_TAG}
$ export KFAPP=kf-ứng dụng
$ xuất CNN_JOB_NAME=inteltfjob
- Tạo thành phần ks cho tf-job-simple-v1beta1 bằng cách chạy lệnh sau:
$ ks tạo tf-job-simple-v1beta1 ${CNN_JOB_NAME} –name=${CNN_JOB_NAME}
- Triển khai TFJob cho cụm bằng cách chạy lệnh sau:
$ ks áp dụng mặc định -c ${CNN_JOB_NAME}
- Để xem nhật ký của tfjob đang chạy , hãy chạy lệnh sau:
$ oc get -n kubeflow -o yaml tfjobs ${CNN_JOB_NAME}
TÊN TUỔI
inteltfjob 1m
- Kiểm tra xem các nhóm để chạy điểm chuẩn đã được khởi chạy chưa bằng cách chạy lệnh sau:
$ oc nhận nhóm
TÊN TÌNH TRẠNG SẴN SÀNG KHỞI ĐỘNG LẠI TUỔI
inteltfjob-ps-0 0/1 Đang chờ 0 4 phút
inteltfjob-worker-0 1/1 Đang chạy 0 4m
inteltfjob-worker-1 1/1 Đang chạy 0 4m
Sau khi khởi chạy TFJob thành công , nó được hiển thị trong bảng thông tin của TFJob , như thể hiện trong hình sau:
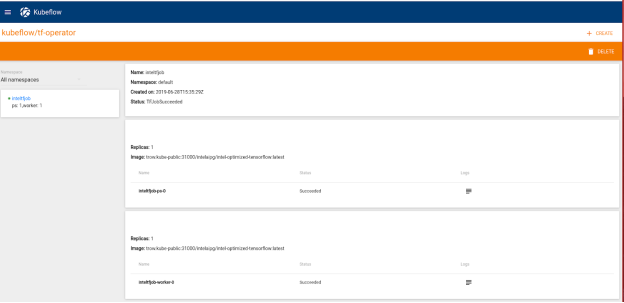
Hình 9. Bảng điều khiển TFJobs
So sánh đào tạo phân tán với không phân tán
So sánh hiệu suất
Chúng tôi đã so sánh kết quả hiệu suất từ việc thực thi điểm chuẩn TensorFlow trên một nút ứng dụng duy nhất (đào tạo không phân tán) với việc thực thi bằng cách sử dụng đào tạo trên hai nút ứng dụng ( một nút PS và hai nút worker) . Hình dưới đây cho thấy kết quả:
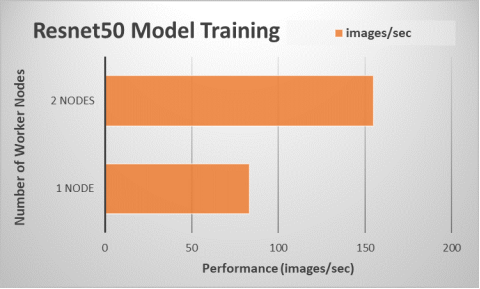
Hình 10. Định cỡ hiệu suất cho đào tạo mô hình bằng cách sử dụng nhiều nút máy chủ
Thông lượng chỉ ra rằng công việc đào tạo sử dụng hai nút ứng dụng nhanh hơn gần 1,9 lần so với công việc đào tạo sử dụng một nút ứng dụng duy nhất . Việc sử dụng phân phối khung Tensorflow được tối ưu hóa từ Intel và áp dụng các tham số thích hợp khi khởi chạy một công việc đào tạo cho phép người thực hành ML thực hiện các công việc Tensorflow của họ một cách hiệu quả trên bộ xử lý Intel Xeon Scalable.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...