
Tin tức
Chạy khối lượng công việc ML/DL bằng Red Hat OpenShift Container Platform v3.11 (2)
Đào tạo TensorFlow tăng tốc GPU bằng TFJobs
Giới thiệu
Đào tạo mô hình là phần tính toán chuyên sâu nhất của ML/DL. Kubeflow sử dụng TFJobs , một tài nguyên tùy chỉnh của Kubernetes, để chạy các công việc đào tạo TensorFlow theo cách tự động và cho phép các nhà khoa học dữ liệu theo dõi tiến độ công việc bằng cách xem kết quả . GPU Nvidia được sử dụng để tăng tốc đào tạo mô hình mạng thần kinh và đào tạo.
Thời gian thực hiện cũng có thể giảm bằng cách chạy đào tạo phân tán TensorFlow , tận dụng khả năng tính toán của nhiều GPU để hoạt động trên cùng một đào tạo mạng thần kinh. Nhiều thành phần đóng vai trò cho phép đào tạo phân tán : các nút công nhân , nơi diễn ra quá trình tính toán (đào tạo mô hình) và Máy chủ tham số (PS) , chịu trách nhiệm lưu trữ các tham số cần thiết cho từng công nhân.
Kubeflow cung cấp một đại diện YAML cho TFJobs.
Ví dụ đào tạo mẫu
Để thể hiện các khả năng của nền tảng Kubeflow trong việc thực hiện các công việc đào tạo ML/DL cũng như hiệu quả mở rộng quy mô của Nền tảng bộ chứa OpenShift , chúng tôi đã chạy tiêu chuẩn TensorFlow CNN để đào tạo mô hình Res n et50 , như thể hiện trong hình sau:
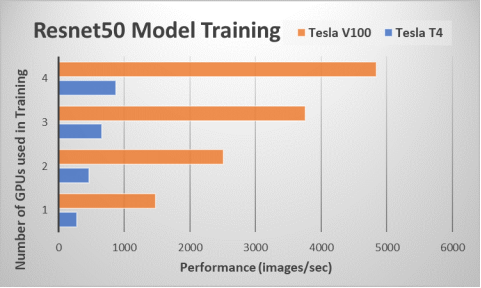
Hình 3. Ví dụ đào tạo: Mô hình Resnet50
Chúng tôi đã chạy điểm chuẩn TensorFlow CNN bằng cách sử dụng TFJobs , một giao diện Kubeflow để thực hiện đào tạo TENSORFLOW và theo dõi quá trình đào tạo. Hình 3 cho thấy hiệu suất của các công việc đào tạo bằng cách sử dụng chỉ số thông lượng (hình ảnh/giây). Kết quả hiệu suất cho điểm chuẩn ResNet-50 được vẽ cho cả GPU NVIDIA Tesla V100 và T4. Đúng như dự đoán, việc sử dụng nhiều GPU hơn để đào tạo mô hình sẽ mang lại hiệu suất cao hơn. Chúng tôi đã sử dụng thư viện Horovod do Uber phát triển để mở rộng quy mô công việc đào tạo nhằm thực hiện đào tạo phân tán đa nút. Công việc GPU Tesla V100 thực thi số hình ảnh/giây nhiều hơn khoảng 5 lần so với GPU Tesla T4 , mặc dù đồng bằng TFLOP lý thuyết của chúng lớn hơn hai lần .
GPU Tesla V100 sử dụng bộ nhớ HBM2 nhanh hơn, điều này có tác động đáng kể đến hiệu suất đào tạo DL . Mẫu GPU Tesla V100 có công suất và mức giá cao hơn so với Tesla T4. Chúng tôi giới thiệu một môi trường linh hoạt nơi người dùng có thể sử dụng Tesla T4, Tesla V100 hoặc cả hai GPU trên Nền tảng bộ chứa OpenShift và cung cấp cho các kỹ sư ML thông qua Kubeflow. Lựa chọn và số lượng GPU sẽ phụ thuộc vào yêu cầu khối lượng công việc và mục tiêu giá cho môi trường ML/DL.
Bảng sau đây hiển thị tệp YAML mà chúng tôi đã sử dụng để triển khai TFJob trên bốn GPU T4 :
Bảng 1. Tệp YAML để triển khai TFJob
| tf_nvidia_cnn.yml | |
| apiVersion: kubeflow.org/v1beta2
loại: TFJob metadata: nhãn: thí nghiệm: thí nghiệm tên: nvidiatfjob không gian tên: mặc định thông số kỹ thuật: tfReplicaSpecs: |
|
| tái bút:
nútChọn: nvidia: t4 bản sao: 1 bản mẫu: metadata: tạoDấu thời gian: null thông số kỹ thuật: imagePullPolicy: Luôn luôn nútChọn: nvidia: t4 hộp đựng: – lập luận: – con trăn – /opt/điểm chuẩn/tf_cnn_benchmarks.py – –batch_size=256 – –model=resnet50 – –num_batches=100 – –num_gpus=1 – –variable_update=horovod – –use_fp16=Đúng – –xla=Đúng hình ảnh: nvcr.io/nvidia/tensorflow:19.06-py3 tên: tensorflow cổng: – cảng container: 2222 tên: cổng tfjob tài nguyên: Hạn mức: nvidia.com/gpu: 1 workingDir: /home/benchmarks/tf_cnn_benchmarks.py khởi động lạiPolicy: OnFailure |
Công nhân:
imagePullPolicy: Luôn luôn nútChọn: giới thiệu: công nhân bản sao: 4 bản mẫu: metadata: tạoDấu thời gian: null thông số kỹ thuật: nútChọn: nvidia: t4 hộp đựng: – lập luận: – con trăn – /opt/điểm chuẩn/tf_cnn_benchmarks.py – –batch_size=256 – –model=resnet50 – –num_batches=100 – –num_gpus=1 – –variable_update=horovod – –use_fp16=Đúng – –xla=Đúng hình ảnh: nvcr.io/nvidia /tensorflow:19.06-py3 tên: tensorflow cổng: – cảng container: 2222 tên: cổng tfjob tài nguyên: Hạn mức: nvidia.com/gpu: 1 workingDir: /home/benchmarks/tf_cnn_benchmarks.py khởi động lạiPolicy: OnFailure |
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...