
Hiệu suất đầu vào/đầu ra
Phần này trình bày kết quả của các bài kiểm tra hiệu năng I/O đối với Thiết kế đã được Xác thực của Dell Technologies dành cho hệ thống Lưu trữ NFS. Tất cả các thử nghiệm hiệu suất đã được tiến hành trong một kịch bản không có lỗi để đo lường khả năng tối đa của giải pháp. Các thử nghiệm này tập trung vào ba loại mẫu I/O: số lần đọc và ghi tuần tự lớn, số lần đọc và ghi ngẫu nhiên nhỏ và ba thao tác siêu dữ liệu (tạo, thống kê và xóa tệp). Giống như phiên bản trước của giải pháp, Thiết kế cho Lưu trữ NFS này sử dụng bộ lập lịch I/O thời hạn và 256 daemon NFS.
Hệ thống tệp XFS với 569TiB dung lượng có thể sử dụng (kích thước lưu trữ thô 840TB) được định cấu hình và xuất qua NFS 4 và được đo điểm chuẩn với kết nối IPoIB qua HDR100, sử dụng datagram và MTU 4096 cho máy khách và máy chủ (thông qua Trình quản lý mạng con trên bộ chuyển mạch Mellanox QM8700) . Cụm điện toán 16 nút được sử dụng để tạo khối lượng công việc cho các bài kiểm tra điểm chuẩn. Mỗi thử nghiệm được chạy trên một loạt các luồng trên các nút máy khách để kiểm tra khả năng mở rộng của giải pháp khi số lượng người dùng tăng lên.
Vì cụm chỉ có 16 nút nên các điểm dữ liệu 32 và 64 luồng thu được với mỗi trong số 16 máy khách chạy 2 và 4 luồng tương ứng để thu được các giá trị hiệu suất bền vững. Bộ nhớ đệm của máy khách bị ngăn chặn bởi mỗi nút máy khách ngắt kết nối hệ thống tệp NFS và loại bỏ tất cả các bộ đệm của hệ điều hành trước khi kết nối lại NFS giữa mọi hoạt động, chẳng hạn như ghi và đọc tuần tự hoặc loại bỏ tất cả các bộ đệm của hệ điều hành trên máy khách và máy chủ khi tất cả các tệp bị xóa (kiểm tra siêu dữ liệu ).
Điểm chuẩn kiểm tra IOzone và MD được sử dụng trong nghiên cứu này. IOzone được sử dụng cho các bài kiểm tra tuần tự và ngẫu nhiên. Đối với các thử nghiệm tuần tự khối lớn, kích thước yêu cầu là 1024KiB đã được sử dụng trên các tệp lớn. Tổng lượng dữ liệu được truyền là 512 GiB được chia cho các luồng máy khách được sử dụng. Các thử nghiệm ngẫu nhiên đã sử dụng kích thước yêu cầu 4KiB và từng luồng máy khách, đọc và sau đó ghi ngẫu nhiên 4GiB trên tệp được tạo trước sau khi loại bỏ bộ nhớ đệm như được mô tả và bộ nhớ khả dụng của máy chủ cho bộ nhớ đệm bị hạn chế để đạt được hiệu suất bền vững mà không cần sử dụng gấp đôi RAM máy chủ. Kiểm tra siêu dữ liệu được thực hiện bằng cách sử dụng mdtest với OpenMPI và bao gồm các thao tác tạo, thống kê và xóa tệp.
Trình tự ghi và đọc IPoIB NN
Để đánh giá hiệu suất di chuyển các tệp lớn, điểm chuẩn IOzone phiên bản 3.492 được sử dụng để đọc và ghi tuần tự bằng cách sử dụng các lần truyền 1 MiB, kích thước truyền NFS tối đa cho các hoạt động đọc hoặc ghi. Các thử nghiệm này được tiến hành trên nhiều số lượng luồng bắt đầu từ 1 luồng và tăng dần theo lũy thừa của 2, tối đa 64 luồng. Tại mỗi lần đếm luồng, số lượng tệp bằng nhau được tạo, vì thử nghiệm này hoạt động trên một tệp cho mỗi luồng hoặc trường hợp NN. Kích thước tệp tổng hợp là 512GiB đã được chọn, vì nó gấp đôi dung lượng RAM trong máy chủ để tránh các hiệu ứng bộ đệm ngăn cản việc nhận được kết quả hiệu suất ổn định đáng tin cậy. 512GiB dữ liệu được chia đều cho số luồng máy khách được sử dụng trong bất kỳ thử nghiệm cụ thể nào. Ngoài ra, sau mỗi bước, ghi hoặc đọc tuần tự, các nút máy khách sẽ ngắt kết nối hệ thống tệp NFS và loại bỏ tất cả các bộ đệm của hệ điều hành trước khi kết nối lại NFS để tiếp tục với thao tác tiếp theo.
Hình 2 cung cấp sự so sánh về hiệu suất I/O tuần tự của Dell Technologies Validate Design cho NFS Storage và phiên bản trước đó. Từ hình này, có thể thấy rằng các hệ thống hiện tại và trước đó có hiệu suất cao nhất tương tự nhau, với mức tăng hiệu suất nhỏ trên Thiết kế mới cho Bộ lưu trữ NFS.
Hiệu suất cao nhất cho giải pháp mới đối với các đỉnh đọc tuần tự ở tốc độ 7,25 GB/giây ở 16 luồng (một luồng trên mỗi nút máy khách) và đối với ghi tuần tự ở tốc độ gần 5 GB/giây với 8 luồng. Hiệu suất đọc tuần tự cao hơn so với thông số kỹ thuật đọc của bộ điều khiển Dell EMC PowerVault ME4084 ở mức 7 GiB/giây, nhưng khi được chuyển đổi thành lũy thừa mười đơn vị, 7 GiB/giây cao hơn 7,5 GB/giây một chút.
Hiệu suất ghi tăng lên, chủ yếu ở số lượng luồng thấp, 2, 4, 8 và 32 luồng lần lượt là 11,5%, 29%, 34,9% và 11,6%. Hiệu suất đọc ghi nhận mức tăng nhỏ hơn ở 4, 8 và 64 luồng là 17,7%, 15,9% và 11,3%. Vì RHEL 8 đã cải thiện một số thành phần trong đường dẫn dữ liệu (bao gồm Lớp khối IO và hệ thống tệp XFS), bộ nhớ đệm hiệu quả hơn, các thành phần máy chủ nhanh hơn (bộ nhớ 3200 MT/s, CPU có nhiều LLC hơn, tốc độ nhắn tin HDR cao hơn), kết quả là hiệu suất cao hơn ở những khu vực mà bộ điều khiển lưu trữ Dell EMC PowerVault ME4084 chưa đạt đến giới hạn hiệu suất của chúng . Các biến thể âm và dương nhỏ hơn (~10%) đã được quan sát thấy ở số lượng luồng khác, nhưng ở những khu vực này, bộ điều khiển PowerVault ME4084 đã đạt đến giới hạn của chúng.
Theo quan sát trong phiên bản cuối cùng của giải pháp Lưu trữ HPC NFS, hiệu suất đọc giảm sau mức cao nhất và giảm nhanh hơn ở 64 luồng. Là một phần của cuộc điều tra nguyên nhân gốc rễ, IOzone được thực thi cục bộ trên máy chủ mà không có các thành phần mạng và NFS đóng vai trò nào. Hiệu suất ghi không bắt đầu giảm xuống còn 128 luồng. Hiệu suất đọc đạt mức cao nhất ở 16 và 32 luồng, sau đó bắt đầu giảm.
Điều đó có nghĩa là NFS hoặc kết nối mạng chịu trách nhiệm một phần về việc giảm hiệu suất ở số lượng luồng từ 32 trở lên, ít nhất là đối với ghi tuần tự. Hiệu suất ở số lượng luồng cao hơn có thể bị ảnh hưởng bởi nhiều yếu tố. Ví dụ: các mẫu IO tuần tự đồng thời từ quá nhiều quy trình đồng thời gây ra ngày càng nhiều hoạt động tìm kiếm di chuyển từ tệp này sang tệp khác khi các luồng khác nhau lấy lõi để chạy và đối với mảng lưu trữ, tải IO bắt đầu hoạt động giống như một tải ngẫu nhiên khi số lượng hoạt động tìm kiếm tăng lên. Một cuộc điều tra có thể điều chỉnh là số lượng quy trình máy chủ NFS, nhưng hiệu suất không được cải thiện khi sử dụng 512 quy trình nfsd (thay vì 256). Do đó, việc giảm hiệu suất ở số lượng chuỗi cao hơn cần được điều tra thêm.


IPoIB viết và đọc ngẫu nhiên NN
Để đánh giá hiệu suất cho các ứng dụng HPC trong đó nhiều nút truy cập tệp đồng thời với các mẫu IO ngẫu nhiên, IOzone phiên bản 3.492 được sử dụng ở chế độ ngẫu nhiên. Các thử nghiệm được tiến hành trên số lượng luồng bắt đầu từ 1 đến 64 tăng dần theo lũy thừa của hai.

Kích thước bản ghi được chọn là 4KB để có các lần truyền phù hợp với kích thước trang của hệ điều hành, đây thường là kích thước truyền nhỏ tối ưu cho hệ điều hành. Trước tiên, mỗi khách hàng đọc và sau đó ghi ngẫu nhiên 4GiB dữ liệu vào một tệp được tạo trước để mô phỏng các truy cập dữ liệu ngẫu nhiên nhỏ đồng thời bằng cách sử dụng các tệp lớn vừa phải khác nhau. Hình dưới đây cho thấy sự so sánh về hiệu năng ghi và đọc I/O ngẫu nhiên của Thiết kế đã được xác thực cho Bộ lưu trữ NFS và phiên bản trước đó có tên là NSS7.4-HA.
Từ hình này, có thể thấy rằng Thiết kế được xác thực cho Bộ lưu trữ HPC NFS có hiệu suất ghi ngẫu nhiên tương tự như phiên bản trước của giải pháp cho hầu hết các điểm dữ liệu, đạt tối đa 7281 IOps ở 32 luồng trên giải pháp mới. Số lượng luồng là 1 và 2, Bộ lưu trữ NFS mới có hiệu suất cao hơn 69,5% và 49% so với NSS7.4-HA. Những mức tăng hiệu suất đó, ở những khu vực mà bộ điều khiển PowerVault ME4084 chưa đạt đến giới hạn, đặc biệt là với 1 hoặc 2 luồng, là do các thành phần máy chủ nhanh hơn, bao gồm bộ nhớ 3200 MT/s, CPU có nhiều LLC hơn, tốc độ nhắn tin HDR cao hơn và các yếu tố khác cải tiến hệ điều hành. Sau thời điểm đó, hiệu suất của cả hai giải pháp gần như giống nhau khi chúng đạt được hiệu suất duy trì tối đa, vì các thao tác phải được ghi vào đĩa trước khi hoàn thành (do NFSv4 sử dụng giá treo đồng bộ hóa theo mặc định),
Mặt khác, hiệu suất đọc ngẫu nhiên có sự khác biệt lớn giữa các kết quả đối với hai giải pháp — hầu hết cho thấy IOps thấp hơn trên hệ thống mới, ngoại trừ trường hợp 2 luồng, trong đó có sự cải thiện 73,7%. Giải pháp này dường như có một cao nguyên đọc ở số lượng luồng thấp, sau đó tăng từ 8 lên số lượng luồng cao hơn, đạt hiệu suất cao nhất là 11.405 IOps ở 64 luồng. Trong bản phát hành trước NSS7.4-HA, hiệu suất cao nhất là 16.607 IOps cũng đạt được ở 64 luồng, cao hơn 31,3%% so với giải pháp hiện tại.
Điều đó có thể một phần là do bộ nhớ đệm phía máy chủ sau khi tạo tệp, cần nỗ lực đáng kể để giảm bớt hoặc loại bỏ và việc lạm dụng nó có thể dễ dàng ngăn cản mọi hoạt động tối ưu hóa hệ điều hành, ngăn cản việc đạt được hiệu suất bền vững đáng tin cậy.
Một cách để tránh vấn đề đó là sử dụng tổng dữ liệu đủ lớn gấp đôi dung lượng RAM trong máy chủ (hoặc 512 GiB), nhưng vì IOps do ổ cứng cung cấp tương đối thấp nên việc thực hiện đo điểm chuẩn như vậy có thể mất vài tuần. Hơn nữa, vì IOzone không trả về bất kỳ giá trị nào cho đến khi hoàn thành giai đoạn ghi hoặc đọc, nên quá trình kiểm tra không thể bị gián đoạn hoặc thất bại mà không cần phải bắt đầu lại quá trình kiểm tra đã thất bại mà không có bất kỳ kết quả nào. Kiểu đầu tư thời gian đó không phải lúc nào cũng là một lựa chọn khả thi.
Do tính năng ghi ngẫu nhiên yêu cầu bộ điều khiển ME4 tính toán hai bộ chẵn lẻ trên mỗi ổ đĩa nên hiệu suất đọc ngẫu nhiên dự kiến sẽ cao hơn hiệu suất ghi, nhưng chỉ ở một mức độ nào đó do phương tiện quay IOps ngẫu nhiên có thể cung cấp có giới hạn. Cũng ảnh hưởng đến hiệu suất, đọc trước là một tối ưu hóa thường được thực hiện bởi lớp IO của Khối hệ điều hành có thể giúp đọc hiệu suất tỷ lệ thuận với số lần truy cập bộ đệm. Tuy nhiên, số lần truy cập bộ đệm sẽ giảm khi tổng kích thước dữ liệu tăng lên (giảm xác suất các khối ngẫu nhiên cần thiết đã có trong bộ nhớ), tạo ra sự phân bổ bộ đệm thừa và lãng phí thời gian cũng như tài nguyên để đọc dữ liệu mà rất có thể sẽ không được sử dụng.
Dựa trên nghiên cứu quan hệ nhân quả sơ bộ với Iozone và FIO (không có trong báo cáo này), kết quả với IOPS 4KiB đặc biệt lớn trên các kết quả đọc ngẫu nhiên một phần là do máy chủ đọc dữ liệu từ bộ đệm, tránh thao tác đọc đĩa. Tuy nhiên, việc ngăn chặn hoàn toàn bất kỳ bộ nhớ đệm nào của máy chủ (ví dụ: sử dụng một quy trình chiếm hầu hết bộ nhớ máy chủ và giữ nó được ghim trong quá trình kiểm tra) sẽ dẫn đến hiệu suất cực kỳ thấp, do Hệ điều hành không thể tối ưu hóa bất kỳ thứ gì trên tất cả các lớp Hệ điều hành khác nhau, và một số thành phần của hệ điều hành thậm chí có thể ngừng hoạt động (ví dụ: nếu OS Out of Memory Killer -OOMK được kích hoạt, sẽ chấm dứt một số daemon HA và các quy trình thiết yếu khác). Ngoài ra, bộ điều khiển ME4 yêu cầu áp suất IO cao (yêu cầu được xếp hàng đợi) để đạt được hiệu suất đọc ngẫu nhiên thô tối đa. Vì nó được thiết lập bằng cách sử dụng FIO trên các thiết bị thô (để loại bỏ ảnh hưởng của hệ thống tệp), với quyền truy cập IO trực tiếp vào LUN (để loại bỏ bộ đệm) và cài đặt đọc trước thành 0 (để chỉ chuyển các khối 4KiB được yêu cầu và không có dữ liệu bổ sung ). IOzone dường như không phải là điểm chuẩn lý tưởng để đạt được hiệu suất đọc duy trì tối đa của tải IO ngẫu nhiên 4KiB. FIO có thể là một ứng cử viên phù hợp vì nó có nhiều quyền kiểm soát hơn đối với một số khía cạnh của tải IO và theo thời gian thực hiện (ví dụ: dừng khi đạt được hiệu suất bền vững, tốc độ thay đổi sẽ nhỏ hơn một số ngưỡng), nhưng cần phải điều tra sâu hơn. IOzone dường như không phải là điểm chuẩn lý tưởng để đạt được hiệu suất đọc duy trì tối đa của tải IO ngẫu nhiên 4KiB. FIO có thể là một ứng cử viên phù hợp vì nó có nhiều quyền kiểm soát hơn đối với một số khía cạnh của tải IO và theo thời gian thực hiện (ví dụ: dừng khi đạt được hiệu suất bền vững, tốc độ thay đổi sẽ nhỏ hơn một số ngưỡng), nhưng cần phải điều tra sâu hơn. IOzone dường như không phải là điểm chuẩn lý tưởng để đạt được hiệu suất đọc duy trì tối đa của tải IO ngẫu nhiên 4KiB. FIO có thể là một ứng cử viên phù hợp vì nó có nhiều quyền kiểm soát hơn đối với một số khía cạnh của tải IO và theo thời gian thực hiện (ví dụ: dừng khi đạt được hiệu suất bền vững, tốc độ thay đổi sẽ nhỏ hơn một số ngưỡng), nhưng cần phải điều tra sâu hơn.
Hoạt động siêu dữ liệu IPoIB
Để biết được mức tối đa cho hiệu suất siêu dữ liệu điển hình của hệ thống, MDTest phiên bản 3.3.0 được sử dụng trong các thử nghiệm này. Cách mà công cụ này được sử dụng có thể được coi là mô phỏng khá đơn giản của giải pháp thư mục chính, với nhiều người dùng đồng thời, trong đó người dùng có cấu trúc thư mục phân cấp đơn giản, sử dụng tệp 3K trên mỗi thư mục con, tăng số lượng người dùng từ 1 lên 512 trong sức mạnh của hai. Việc sử dụng các tệp trống cung cấp số trần cho các tệp được tạo và xóa trong trường hợp sử dụng đó.
Để tất cả các nút có thể truy cập được, MDtest đã được biên dịch và sau đó được cài đặt trên mỗi máy khách. Vì MDtest phải được sử dụng với mpirun trên một cụm, OpenMPI phiên bản 4.0.4rc3-1.51237 đã được chọn, vì nó được bao gồm trong Mellanox OFED được triển khai trên các máy khách. Phiên bản OpenMPI đó đã được sao chép trên một hệ thống được sử dụng để bắt đầu thử nghiệm (một máy chủ PowerEdge R750 khác không liên quan đến máy khách hoặc máy chủ NFS) và với phiên bản MPI đã chọn (với bộ chọn mpi), để có cấu hình nhất quán.
Bảng sau đây mô tả các đối số dòng lệnh MDtest được sử dụng từ các phiên bản trước của giải pháp này, được chọn để có thể so sánh kết quả hoạt động với giải pháp Lưu trữ NFS trước đó là NSS7.4-HA. Một mục tiêu là sử dụng ít nhất 1 triệu tệp cho mỗi thao tác siêu dữ liệu và vì số lượng tệp trên mỗi thư mục ảnh hưởng đến kết quả nên con số đó được giữ cố định ở mức 3000. Số lượng thư mục trên mỗi luồng đã được sửa đổi theo số lượng luồng được sử dụng, để có gần 1 triệu tệp trở lên cho mỗi lần kiểm tra siêu dữ liệu, cho mỗi lần lặp lại. Do đó, công việc này đã sử dụng các tham số sau:
Bảng 6. Kiểm tra siêu dữ liệu bảng: Phân phối tệp và thư mục trên các luồng
|
# Đề |
# Tệp trên mỗi thư mục |
# Thư mục mỗi chủ đề |
Tổng số tệp |
|
1 |
3000 |
320 |
960000 |
|
2 |
3000 |
160 |
960000 |
|
4 |
3000 |
80 |
960000 |
|
số 8 |
3000 |
40 |
960000 |
|
16 |
3000 |
20 |
960000 |
|
32 |
3000 |
10 |
960000 |
|
64 |
3000 |
số 8 |
1536000 |
|
128 |
3000 |
4 |
1536000 |
|
256 |
3000 |
4 |
3072000 |
|
512 |
3000 |
4 |
6144000 |
Vì cụm có 16 nút tính toán, nên trong các biểu đồ bên dưới, mỗi máy khách đã thực thi một luồng trên mỗi nút đối với số luồng lên tới 16. Đối với số luồng là 32, 64, 128, 256 và 512, mỗi nút máy khách được thực thi lần lượt là 2, 4, 8, 16 và 32 luồng đồng thời.
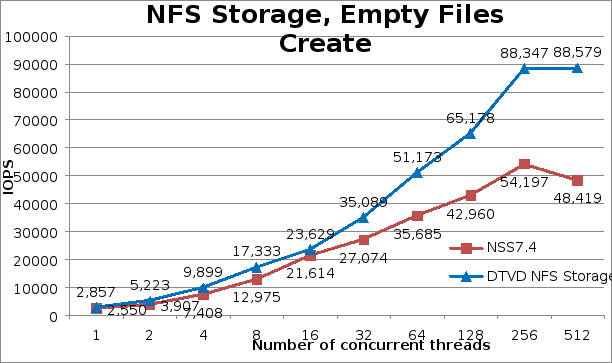
Về mặt tạo tệp nói chung, giải pháp mới có những cải tiến đáng kể so với phiên bản trước NSS7.4-HA. Có sự cải thiện 12% cho một luồng và sau đó cải thiện 34% từ 2 đến 8 luồng. Ở 16 luồng, chỉ cải thiện được 9% nhưng sau thời điểm đó, hiệu suất tăng đều đặn, đạt mức cao hơn 82,9% so với phiên bản giải pháp trước đó ở 512 luồng, trong đó quan sát thấy hiệu suất cao nhất tạo ra 88.579 thao tác mỗi giây.
Các hoạt động thống kê đã đăng ký hiệu suất thấp hơn so với phiên bản trước NSS7.4-HA cho số lượng luồng thấp, tương ứng là -18%, -14% và -7% cho 1,2 và 8 luồng. Sau đó, ở số lượng luồng cao, hầu hết hiệu suất được cải thiện cao hơn khoảng 10%, ngoại trừ 64 và 512 luồng, trong đó cao hơn lần lượt là 17,3% và 25,6%. Một lần nữa, ở 512 luồng, người ta đã quan sát thấy hiệu suất thống kê cao nhất là 581.734 thao tác mỗi giây.
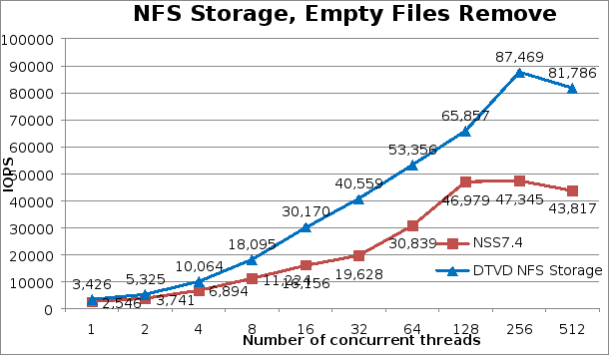
Nhìn chung, các thao tác xóa đã có những cải thiện đáng kể về hiệu suất so với giải pháp NSS7.4-HA trước đây, thậm chí còn cao hơn các thao tác tạo. Bắt đầu ở mức cao hơn 34% ở 1 luồng, tăng mức cải thiện tương đối cho đến khi đạt 106,6% ở 32 luồng, sau đó giảm mức cải thiện tương đối xuống 40% ở 128 luồng và tăng lại ở số lượng luồng cao hơn cho đến khi đạt mức cải thiện 86,7% ở 512 luồng. Hiệu suất loại bỏ cao nhất là 87.469 thao tác mỗi giây đạt được ở 256 luồng.
Các số liệu sau đây lần lượt hiển thị kết quả của các thao tác tạo, thống kê và xóa tệp. Các cải tiến hiệu suất cho hoạt động siêu dữ liệu, đặc biệt là để tạo và xóa, phải liên quan đến các cải tiến liên tục mà XFS đã nhận được kể từ khi Red Hat sử dụng nó làm hệ thống tệp chính cho hệ điều hành, các thành phần máy chủ nhanh hơn (bộ nhớ 3200 MT/s, CPU với nhiều LLC, HDR tốc độ nhắn tin cao hơn) và các cải tiến đối với các thành phần khác trong đường dẫn I/O. RHEL 8 cũng bao gồm một số tiện ích theo dõi, chẳng hạn như blktrace, bcc, bpftrace, pmtrace, fwtrace, llvm tools, Ftrace, perf và pcp) và một số trong số chúng có số lượng sự kiện XFS ấn tượng (như perf), có thể là rất hữu ích để hiểu những thách thức và để cải thiện .
Hình 3. Tệp IPoIB tạo hiệu suất
Hình 5. Hiệu suất loại bỏ tệp IPoIB 

MDtest cho kho lưu trữ thư mục chính
Một trong những trường hợp sử dụng chính của Thiết kế dành cho Lưu trữ NFS này là kho lưu trữ thư mục chính, thay vì chỉ kiểm tra siêu dữ liệu cho các tệp trống (không phải là trường hợp phổ biến) mà chỉ yêu cầu sửa đổi nút chứa siêu dữ liệu. Sẽ rất hữu ích khi khám phá hiệu suất của các tệp nhỏ yêu cầu phân bổ ít nhất một khối dữ liệu (phân bổ bổ sung tối thiểu). Vì kích thước khối dữ liệu của hệ thống tệp XFS được sử dụng là 4096 (4 KiB), đó là kích thước tệp được chọn cho các thử nghiệm siêu dữ liệu với các tệp nhỏ.
Có thể tìm thấy kết quả từ việc chạy MDtest với 4 tệp KiB và so sánh kết quả với các tệp trống trong Hình 7. Đúng như dự đoán, là siêu dữ liệu thuần túy, kết quả Thống kê hầu như không thay đổi, với đỉnh mới thấp hơn một chút là 567.753 IOP ở 512 luồng. Hoạt động đọc bắt đầu ở 5.636 IOPS cho một luồng, tăng tuyến tính lên đến 16 luồng, sau đó từ từ đạt đến mức ổn định với tối đa 150.909 IOP ở 512 luồng.

Tạo và xóa là các hoạt động bị ảnh hưởng nhiều nhất khi sử dụng các tệp 4KiB, vì chúng yêu cầu phân bổ hoặc giải phóng khối dữ liệu mà hầu hết thời gian sẽ yêu cầu hoạt động tìm kiếm ổ cứng. Các hoạt động tạo bị ảnh hưởng nhiều nhất, bắt đầu với khoảng một nửa hiệu suất tệp trống cho một luồng với 1.437 IOPS, với hiệu suất giảm ngày càng tăng cho đến khi đạt mức giảm hiệu suất tối đa là 82,4% ở 512 luồng và đạt tối đa 15.600 IOPS ở 256 chủ đề.
Hình 6. Hiệu suất siêu dữ liệu của tệp IPoIB 4KiB
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...