
Tin tức
Tối ưu hóa GPU với Run:ai Atlas (2)
Xác thực Run:ai Atlas
Tổng quan
Chúng tôi đã triển khai nền tảng Run:ai Atlas trong cụm Kubernetes trên Nền tảng Symcloud. Bảng sau đây mô tả phần cứng và phần mềm của cấu hình được sử dụng để xác thực thiết kế này:
Bảng 1. Thiết lập xác thực
| Loại cài đặt | Cổ điển (SaaS) | tự lưu trữ |
| May chủ | 4 x máy chủ PowerEdge R7525, mỗi máy chủ có hai GPU NVIDIA A100 | 4 x máy chủ PowerEdge R7525 (3 máy chủ có 2 GPU NVIDIA A100 và 1 máy chủ có 1 GPU NVIDIA A30) |
| điều phối container | Nền tảng Symcloud phiên bản 5.3.11 | Nền tảng Symcloud phiên bản 5.4.2 |
| Kho | Lưu trữ riêng trên đám mây Symcloud | Lưu trữ riêng trên đám mây Symcloud |
| thiết bị chuyển mạch mạng |
Dell S5248F-ON (dành cho khối lượng công việc và quản lý) Dell S4148T-ON OOB |
Dell S5248F-ON (dành cho khối lượng công việc và quản lý)
Dell S4148T-ON OOB
|
| Nhà điều hành GPU NVIDIA | Phiên bản 22.2.9 | Phiên bản 22.2.9 |
| Chạy:ai Atlas | Phiên bản cụm 2.8.14 | Phiên bản mặt phẳng điều khiển 2.9.5, Phiên bản cụm 2.8.14 |
Dell Validated Design for Analytics—Data Lakehouse kết hợp Nền tảng Symcloud phiên bản 5.3.x. Chúng tôi đã tiến hành xác thực việc triển khai Run:ai Classic (SaaS) trên phiên bản này. Xem Thiết kế được xác thực của Dell dành cho Analytics—Hướng dẫn thiết kế Data Lakehouse để biết thêm thông tin về kiến trúc tham chiếu. Chúng tôi đã chạy quá trình triển khai và xác thực Run:ai Atlas tự lưu trữ trên phiên bản mới hơn của Nền tảng Symcloud. Phiên bản này vẫn chưa được xác thực khi xuất bản tài liệu này như một phần của Thiết kế được xác thực của Dell dành cho phân tích – Data Lakehouse.
Bảng điều khiển và phân tích
Nền tảng Run:ai Atlas cung cấp bảng điều khiển để giám sát việc phân bổ và sử dụng GPU.

Hình 3. Bảng điều khiển Run:ai Atlas
Phân tích này giúp bạn đưa ra quyết định tốt hơn và cải thiện giá trị kinh doanh.
Đào tạo và xây dựng tương tác
Khối lượng công việc học sâu có thể có hai loại chung:
- Các phiên “xây dựng” tương tác ─Nhà khoa học dữ liệu mở một phiên tương tác bằng cách sử dụng bash, Jupyter Notebook, PyCharm từ xa hoặc một công cụ tương tự để truy cập trực tiếp vào tài nguyên GPU.
- Các buổi “đào tạo” không giám sát ─Nhà khoa học dữ liệu chuẩn bị khối lượng công việc tự chạy và gửi khối lượng công việc đó để thực thi. Trong quá trình thực hiện, nhà khoa học dữ liệu có thể kiểm tra kết quả.
Để chạy một phiên đào tạo không giám sát, chúng tôi đã sử dụng lệnh gửi runai . Chúng tôi đã thực hiện đào tạo bằng cách sử dụng hình ảnh runai-quickstart :
runai submit qf-a2 -i gcr.io/run-ai-demo/quickstart -g 1

Hình 4. Phân bổ và sử dụng GPU cho công việc đào tạo
Hình này cho thấy một GPU được phân bổ cho công việc và được sử dụng đầy đủ bởi công việc đào tạo.
Phân số GPU
Run:ai Atlas cung cấp hệ thống chia sẻ GPU phân đoạn cho khối lượng công việc được chứa trên Kubernetes. GPU phân số phù hợp với các tác vụ AI nhẹ như suy luận và phát triển mô hình. Hệ thống GPU phân đoạn cho phép các nhóm khoa học dữ liệu và kỹ thuật AI chạy đồng thời nhiều khối lượng công việc trên một GPU duy nhất. Do đó, các công ty có thể chạy nhiều khối lượng công việc hơn như thị giác máy tính, nhận dạng giọng nói và xử lý ngôn ngữ tự nhiên trên cùng một phần cứng để giảm chi phí.
Hệ thống GPU phân đoạn từ Run:ai Atlas tạo ra các GPU logic một cách hiệu quả với bộ nhớ và không gian tính toán riêng mà các bộ chứa có thể sử dụng và truy cập như thể chúng là các bộ xử lý độc lập. Phương pháp này cho phép một số khối lượng công việc chạy trong các vùng chứa cạnh nhau trên cùng một GPU mà không can thiệp lẫn nhau. Giải pháp minh bạch, đơn giản và di động; nó không yêu cầu thay đổi đối với các thùng chứa.
Một trường hợp sử dụng điển hình có thể có từ hai đến tám tác vụ chạy trên cùng một GPU, nghĩa là bạn có thể thực hiện tác vụ gấp tám lần với cùng một phần cứng.
Chúng tôi sử dụng các lệnh sau để xác thực GPU phân đoạn:
nhóm dự án cấu hình runai-a
runai gửi frac05 -i gcr.io/run-ai-demo/quickstart -g 0.5 –interactive
runai gửi frac03 -i gcr.io/run-ai-demo/quickstart -g 0.3
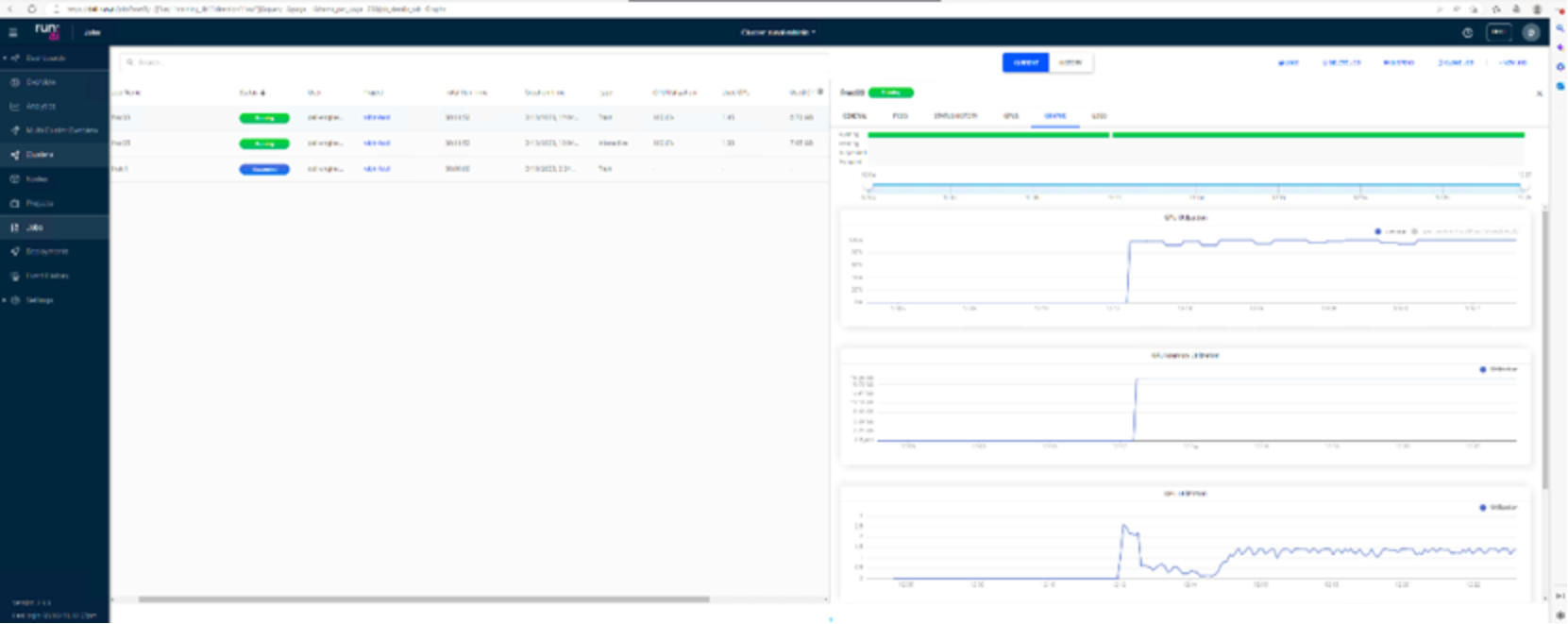
Hình 5. Phân bổ GPU cho các phân số GPU
Hình này cho thấy GPU đang chạy hai tác vụ đồng thời và mức sử dụng GPU tổng thể là 80 phần trăm (50 phần trăm cho tác vụ frac05 và 30 phần trăm cho tác vụ frac03 ).
Tối ưu hóa siêu tham số
Tối ưu hóa siêu tham số là quá trình chọn một tập hợp các siêu tham số tối ưu cho thuật toán học. Giá trị của siêu tham số được sử dụng để kiểm soát quá trình học, để xác định kiến trúc mô hình hoặc quy trình tiền xử lý dữ liệu, v.v. Ví dụ về siêu tham số bao gồm tốc độ học tập, kích thước lô, trình tối ưu hóa khác nhau và số lớp.
Có một số chiến lược để tìm kiếm không gian siêu tham số, chẳng hạn như Tìm kiếm ngẫu nhiên và Tìm kiếm theo lưới.
Chúng tôi đã chạy tối ưu hóa siêu tham số bằng cách sử dụng hai phiên bản GPU với hai nhóm đồng thời với tổng cộng bốn lần hoàn thành:
runai gửi hpo1 -I gcr.io/run-ai-demo/quickstart-hpo -g 2 \ –parallelism 2–-completions 4 -v /root/runai-robin-test:/nfs
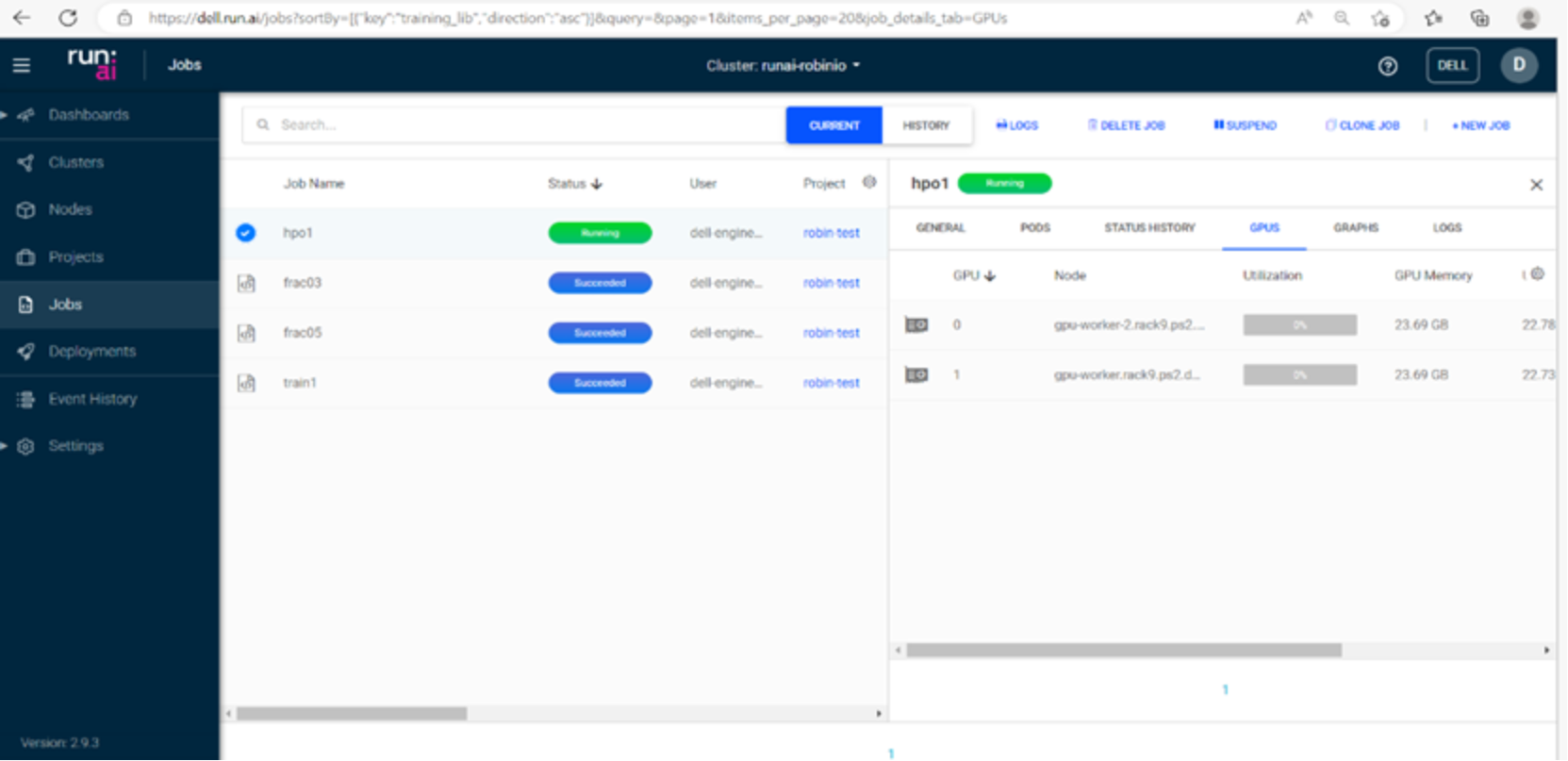
Hình 5. Điều chỉnh siêu tham số với Run:ai Atlas
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...