
Tin tức
Code Llama – Trợ lý mã hóa nguồn mở có thể nhận được Meta như thế nào?
Giới thiệu
Vài năm qua là một cuộc phiêu lưu thú vị trong lĩnh vực AI, khi các mô hình AI ngày càng phức tạp tiếp tục được phát triển để phân tích và hiểu được lượng dữ liệu khổng lồ. Từ việc dự đoán cấu trúc protein đến lập biểu đồ giải phẫu thần kinh của ruồi giấm cho đến tạo ra các phép toán tối ưu giúp tăng tốc siêu máy tính, AI đã đạt được những thành tích ấn tượng trên nhiều lĩnh vực khác nhau. Các mô hình ngôn ngữ lớn (LLM) cũng không ngoại lệ. Mặc dù việc tạo ra ngôn ngữ giống con người thu hút sự chú ý nhưng các mô hình ngôn ngữ lớn cũng được tạo ra để tạo mã. Bằng cách đào tạo trên các tập dữ liệu mã khổng lồ, các hệ thống này có thể viết mã bằng cách dự đoán mã thông báo tiếp theo theo trình tự.
Các công ty như Google, Microsoft, OpenAI và Anthropic đang phát triển LLM thương mại để mã hóa như Codex, GitHub Copilot và Claude. Ngược lại với các hệ thống đóng, Meta đã mở công cụ mã hóa AI Code Llama , một trợ lý mã hóa AI nhằm mục đích tăng năng suất của nhà phát triển phần mềm. Nó được phát hành theo giấy phép cho phép cho cả mục đích thương mại và nghiên cứu. Code Llama là một LLM có khả năng tạo mã và mô tả mã bằng ngôn ngữ tự nhiên từ cả đoạn mã và lời nhắc do người dùng thiết kế để tự động hóa các tác vụ mã hóa lặp đi lặp lại và nâng cao quy trình làm việc của nhà phát triển. Bản phát hành nguồn mở cho phép cộng đồng công nghệ rộng lớn hơn xây dựng dựa trên mô hình nền tảng của Meta về xử lý ngôn ngữ tự nhiên và mã thông minh. Để biết thêm thông tin về bản phát hành, hãy xem blog của Meta Giới thiệu Code Llama, Công cụ AI dành cho Mã hóa .
Code Llama là trợ lý AI mới đầy hứa hẹn dành cho các lập trình viên. Nó có thể tự động hoàn thành mã, tìm kiếm trong cơ sở mã, tóm tắt mã, dịch giữa các ngôn ngữ và thậm chí khắc phục sự cố. Phạm vi chức năng ấn tượng này khiến Code Llama gần như kỳ diệu—giống như giấc mơ của một lập trình viên trở thành hiện thực! Với các trợ lý mã hóa như Code Llama, việc xây dựng các ứng dụng có thể trở nên dễ dàng hơn nhiều. Thay vì viết từng dòng mã, một ngày nào đó chúng ta có thể mô tả những gì chúng ta muốn chương trình thực hiện bằng lời nhắc ngôn ngữ tự nhiên và mô hình có thể tạo mã cần thiết cho chúng ta. Quy trình làm việc trong tương lai này có thể cho phép các lập trình viên tập trung vào logic và kiến trúc cấp cao của ứng dụng mà không bị sa lầy vào các chi tiết triển khai.
Bắt đầu và sử dụng Code Llama rất đơn giản và nhanh chóng. Meta đã phát hành phiên bản 7 B, 13 B và 34 B của mô hình bao gồm các mô hình hướng dẫn đã được huấn luyện với khả năng điền vào giữa (FIM). Điều này cho phép các mô hình chèn vào mã hiện có, thực hiện hoàn thành mã và chấp nhận lời nhắc bằng ngôn ngữ tự nhiên. Sử dụng Dell PowerEdge R740XD được trang bị GPU Nvidia A100 40GB duy nhất đã thử nghiệm với mô hình 7 tỷ tham số nhỏ hơn, CodeLlama-Instruct-7 B. Chúng tôi đã sử dụng Cụm Rattler trong Phòng thí nghiệm đổi mới AI HPC để tận dụng các máy chủ PowerEdge XE8545 được trang bị bốn GPU Nvidia A100 40 GB cho mô hình tham số 34 tỷ lớn hơn (CodeLlama-Instruct-34 B). Các ví dụ do Meta cung cấp đã chạy vài phút sau khi tải xuống các tệp mô hình và chúng tôi bắt đầu thử nghiệm các lời nhắc bằng ngôn ngữ tự nhiên để tạo mã. Bằng cách thiết kế các lời nhắc một cách chiến lược, chúng tôi hướng đến việc tạo ra nền tảng cho dịch vụ web bao bọc mô hình Code Llama bằng một API có thể truy cập được qua web.
Chấp nhận đầu vào của người dùng từ dòng lệnh
Các ví dụ được cung cấp trong example_instructions.py phải được chỉnh sửa thủ công để thêm lời nhắc của người dùng mong muốn. Để làm cho Code Llama dễ sử dụng hơn một chút, chúng tôi đã sao chép example_instructions.py vào test_instructions.py và thêm khả năng gửi lời nhắc từ dòng lệnh.
Tệp đầy đủ với các thay đổi:
# Bản quyền (c) Meta Platforms, Inc. và các chi nhánh. # Phần mềm này có thể được sử dụng và phân phối theo các điều khoản của Thỏa thuận cấp phép cộng đồng Llama 2. từ việc nhập nhập Tùy chọn lửa nhập khẩu từ llama nhập khẩu Llama chắc chắn chính( ckpt_dir: str, tokenizer_path: str, nội dung: str, nhiệt độ: phao = 0,2, top_p: float = 0,95, max_seq_len: int = 512, max_batch_size: int = 8, max_gen_len: Tùy chọn[int] = Không, ): máy phát điện = Llama.build( ckpt_dir=ckpt_dir, tokenizer_path=đường dẫn tokenizer_path, max_seq_len=max_seq_len, max_batch_size=max_batch_size, ) hướng dẫn = [ [ { "vai trò": "người dùng", "nội dung": nội dung, } ] ] kết quả = Generator.chat_completion( hướng dẫn, # gõ: bỏ qua max_gen_len=max_gen_len, nhiệt độ=nhiệt độ, top_p=top_p, ) để được hướng dẫn, kết quả là zip(hướng dẫn, kết quả): cho tin nhắn trong hướng dẫn: print(f"{msg['role'].capitalize()}: {msg['content']}\n") in( f"> {kết quả['thế hệ']['role'].capitalize()}: {result['thế hệ']['nội dung']}" ) print("\n=====================================\n") nếu __name__ == "__main__": lửa.Fire (chính)
Có thể chạy lệnh torchrun tiêu chuẩn với tùy chọn –content để chuyển vào dấu nhắc. Thay vì đánh giá mô hình dựa trên các nhiệm vụ phức tạp, chúng tôi bắt đầu với những thử thách mã hóa đơn giản. Để kiểm tra mô hình, chúng tôi đã thiết kế một số thử nghiệm liên quan đến các lời nhắc mã hóa đơn giản đặt ra các vấn đề lập trình cơ bản. Quy trình thủ công nhắc trực tiếp mô hình cho phép chúng tôi đánh giá điểm mạnh và điểm yếu trong việc tạo mã bằng mô hình này.
Lời nhắc đầu tiên của chúng tôi: “Hiển thị một ví dụ về đệ quy trong Python”
Yêu cầu:
torchrun test_instructions.py \ --nproc_per_node 1 \ --ckpt_dir CodeLlama-7b-Instruct/ \ --tokenizer_path CodeLlama-7b-Instruct/tokenizer.model \ --max_seq_len 512 \ --max_batch_size 1 \ --content "Hiển thị ví dụ về đệ quy trong Python"
Đầu ra:
> Trợ lý: Chắc chắn rồi! Đây là một ví dụ về đệ quy trong Python: ``` giai thừa def (n): nếu n == 0: trở lại 1 khác: trả về n * giai thừa(n-1) ``` Trong ví dụ này, hàm `giai thừa` lấy số nguyên `n` làm đầu vào và trả về giai thừa của nó. Hàm gọi chính nó với đối số `n-1` cho đến khi đạt đến trường hợp cơ sở, trong đó `n` bằng 0. Trường hợp cơ sở trả về 1 và các cuộc gọi đệ quy trả về giai thừa của `n-1`. Kết quả cuối cùng là tích của `n` và giai thừa của `n-1`. Đây là một ví dụ về cách hàm sẽ hoạt động với các giá trị khác nhau của `n`: * `giai thừa(5)` sẽ gọi `giai thừa(4)`, sẽ gọi `giai thừa(3)`, sẽ gọi `giai thừa(2)`, sẽ gọi `giai thừa(1)`, sẽ gọi `giai thừa(1)`, sẽ trả về 1 . Kết quả cuối cùng sẽ là 5! = 120. * `giai thừa(0)` sẽ trả về 1. * `giai thừa(-1)` sẽ đưa ra `ValueError` vì số âm không được phép. Đệ quy có thể là một công cụ mạnh mẽ để giải quyết các vấn đề có cấu trúc đệ quy, nhưng nó cũng có thể khó hiểu và khó gỡ lỗi. Điều quan trọng là sử dụng đệ quy một cách thận trọng và đảm bảo rằng đó là cách tiếp cận tốt nhất cho vấn đề bạn đang cố gắng giải quyết. =====================================
Mô hình không chỉ tạo mã ví dụ mà còn giải thích cách mã hoạt động thông qua các ví dụ. Bằng cách cung cấp cả đoạn mã và mô tả rõ ràng, mô hình cho phép hiểu sâu hơn về chức năng. Người dùng có thể vừa xem các triển khai cụ thể vừa tìm hiểu lý do căn bản đằng sau chúng. Giờ đây, chúng tôi đã giúp việc cung cấp lời nhắc cho mô hình trở nên dễ dàng hơn, hãy xây dựng điểm cuối API bằng cách nhắc Code Llama xây dựng máy chủ của riêng nó.
Tạo điểm cuối API cho Code Llama
API RESTful là một cách phổ biến để xây dựng các dịch vụ phụ trợ có thể được sử dụng bởi nhiều ứng dụng khác nhau qua mạng bằng các công cụ như cuộn tròn. Tuy nhiên, thay vì mã hóa thủ công, chúng tôi đã yêu cầu Code Llama viết mã cho máy chủ REST của riêng nó.
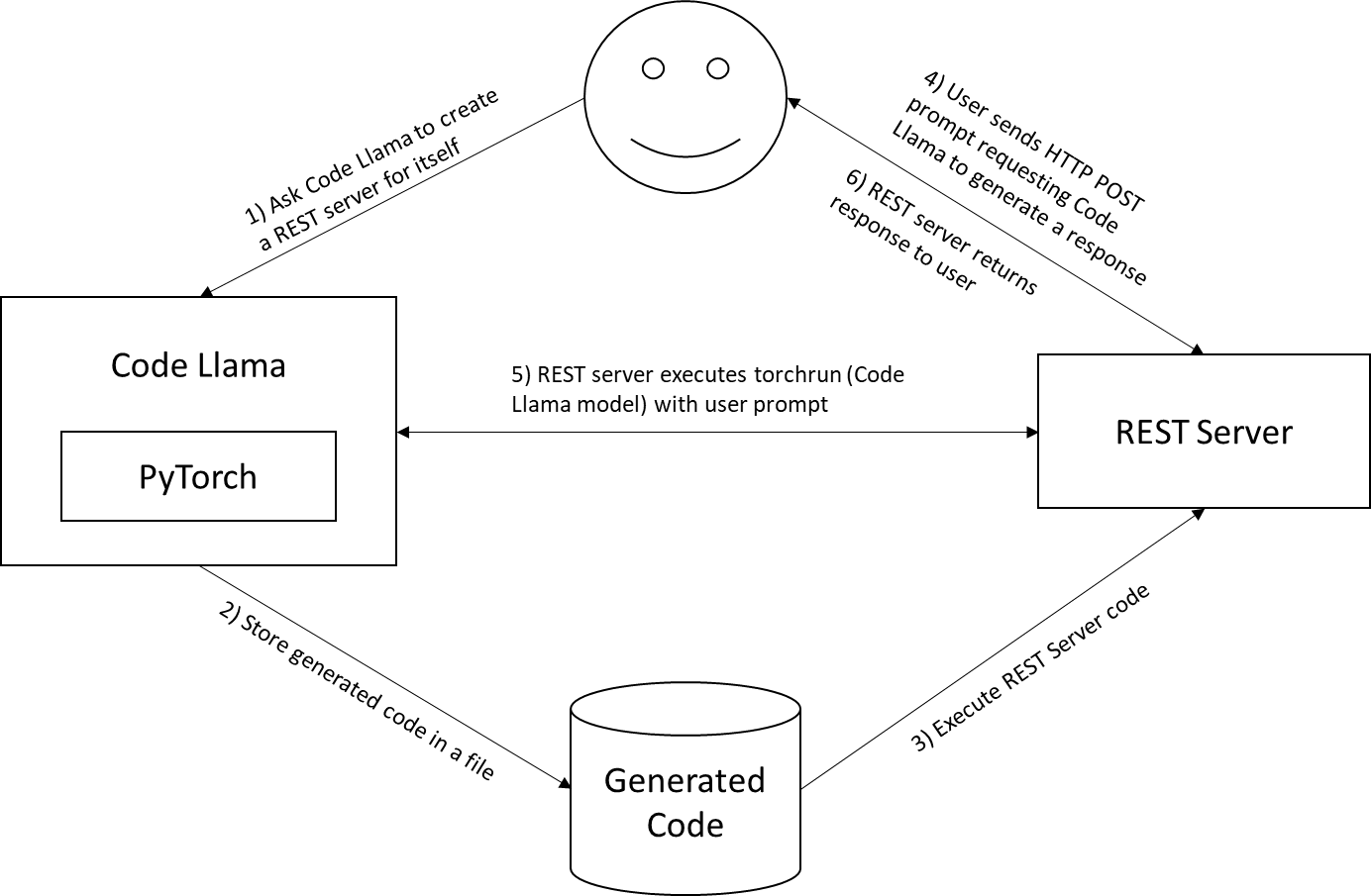
Quy trình sử dụng Code Llama của chúng tôi để tạo ra một dịch vụ web của chính nó:
- Bước 1: Yêu cầu Code Llama tạo máy chủ REST cho riêng mình
- Bước 2: Lưu trữ mã được tạo trong một tệp
- Bước 3: Chạy ứng dụng REST trên cùng một máy chủ hỗ trợ GPU
- Bước 4: Gửi lời nhắc bằng cách sử dụng yêu cầu HTTP POST tới dịch vụ Code Llama trên máy chủ cục bộ
- Bước 5: Máy chủ REST chạy lệnh torchrun với lời nhắc của người dùng
- Bước 6: Máy chủ REST trả về phản hồi cho người dùng
Chúng tôi cần thêm một số ngữ cảnh vào lời nhắc để Code Llama tạo mã chính xác, vì lời nhắc được thiết kế phức tạp hơn một chút và bao gồm cách gọi torchrun với các tham số chính xác:
chạy đuốc \ --nproc_per_node 1 \ test_instructions.py \ --ckpt_dir CodeLlama-7b-Instruct/ \ --tokenizer_path CodeLlama-7b-Instruct/tokenizer.model\ --max_seq_len 512 \ --max_batch_size 1 \ --content "Tạo máy chủ REST bằng Python có URL POST /codellama, mong đợi tải trọng JSON có trường 'nội dung', sử dụng subprocess.run(['torchrun', '--nproc_per_node', '1', ' test_instructions.py', '--ckpt_dir', 'CodeLlama-7b-Instruct/', '--tokenizer_path', 'CodeLlama-7b-Instruct/tokenizer.model', '--max_seq_len', '512', '- -max_batch_size', '1', '--content', content], stdout=subprocess.PIPE) và trả về thiết bị xuất chuẩn từ subprocess.run"
Tất cả các tùy chọn dòng lệnh torchrun , ngoại trừ –content, đều được xác định bởi chính Code Llama . Hãy chia nhỏ những gì lời nhắc thiết kế của chúng tôi đang yêu cầu:
- “Tạo máy chủ REST bằng Python” – Không có khung nào được xác định; Mã Llama đã chọn Bình
- “với URL POST /codellama” – Mong đợi nhận được POST HTTP tới URL /codellama
- “mong đợi tải trọng JSON có trường ‘nội dung’” – Yêu cầu khóa ‘nội dung’ trong POST JSON. Điều này giữ lời nhắc của người dùng.
- “use a subprocess.run(…)” – Đây là nơi chúng tôi nói với Code Llama cách gọi chính nó
- “return stdout from subprocess.run” – Trả về bất kỳ văn bản nào mà Code Llama tạo qua HTTP
Kết quả đầu ra:
> Trợ lý: Đây là ví dụ về cách bạn có thể tạo máy chủ REST bằng Python với URL POST /codellama yêu cầu tải trọng JSON có trường 'nội dung' và sử dụng lệnh subprocess.run để chạy lệnh torchrun với chỉ định tranh luận: ``` nhập json nhập khẩu quy trình con từ bình nhập khẩu Bình, yêu cầu ứng dụng = Bình(__name__) @app.route('/codellama', Method=['POST']) def codellama(): nếu request.method == 'POST': dữ liệu = request.get_json() nội dung = dữ liệu['nội dung'] args = ['torchrun', '--nproc_per_node', '1', 'test_instructions.py', '--ckpt_dir', 'CodeLlama-7b-Instruct/', '--tokenizer_path', 'CodeLlama-7b-Instruct /tokenizer.model', '--max_seq_len', '512', '--max_batch_size', '1', '--content', nội dung] kết quả = subprocess.run(args, stdout=subprocess.PIPE) trả về kết quả.stdout khác: trả về 'Yêu cầu không hợp lệ' nếu __name__ == '__main__': app.run(debug=True) ``` Mã này xác định ứng dụng Flask có một tuyến duy nhất, '/codellama', xử lý các yêu cầu POST. Tuyến đường yêu cầu tải trọng JSON có trường 'nội dung' và sử dụng lệnh subprocess.run để chạy lệnh torchrun với các đối số được chỉ định. Kết quả của =====================================
Chúng tôi đã cắt bớt mã do Code Llama tạo ra và dán nó vào server.py:
nhập json nhập khẩu quy trình con từ bình nhập khẩu Bình, yêu cầu ứng dụng = Bình(__name__) @app.route('/codellama', Method=['POST']) def codellama(): nếu request.method == 'POST': dữ liệu = request.get_json() nội dung = dữ liệu['nội dung'] args = ['torchrun', '--nproc_per_node', '1', 'test_instructions.py', '--ckpt_dir', 'CodeLlama-7b-Instruct/', '--tokenizer_path', 'CodeLlama-7b-Instruct /tokenizer.model', '--max_seq_len', '512', '--max_batch_size', '1', '--content', nội dung] kết quả = subprocess.run(args, stdout=subprocess.PIPE) trả về kết quả.stdout khác: trả về 'Yêu cầu không hợp lệ' nếu __name__ == '__main__': app.run(debug=True)
Sau khi chạy mã:
máy chủ python.py
… máy chủ giống REST sẽ chạy và chờ lệnh.
Sử dụng Curl , chúng ta có thể gửi lệnh qua mạng tới Code Llama ngay bây giờ:
Curl -X POST -H "Content-Type: application/json" -d '{"content": " Hiển thị ví dụ về đệ quy trong Python"}' http://localhost:5000/codellama
…và sẽ nhận được kết quả như sau:
> Trợ lý: Chắc chắn rồi! Đây là một ví dụ về đệ quy trong Python: ``` giai thừa def (n): nếu n == 0: trở lại 1 khác: trả về n * giai thừa(n-1) ``` Trong ví dụ này, hàm `giai thừa` lấy số nguyên `n` làm đầu vào và trả về giai thừa của nó. Hàm gọi chính nó với đối số `n-1` cho đến khi đạt đến trường hợp cơ sở, trong đó `n` bằng 0. Trường hợp cơ sở trả về 1 và các cuộc gọi đệ quy trả về giai thừa của `n-1`. Kết quả cuối cùng là tích của `n` và giai thừa của `n-1`. Đây là một ví dụ về cách hàm sẽ hoạt động với các giá trị khác nhau của `n`: * `giai thừa(5)` sẽ gọi `giai thừa(4)`, sẽ gọi `giai thừa(3)`, sẽ gọi `giai thừa(2)`, sẽ gọi `giai thừa(1)`, sẽ gọi `giai thừa(1)`, sẽ trả về 1 . Kết quả cuối cùng sẽ là 5! = 120. * `giai thừa(0)` sẽ trả về 1. * `giai thừa(-1)` sẽ tăng `ValueError` vì số âm không được phép Đệ quy có thể là một công cụ mạnh mẽ để giải quyết các vấn đề có cấu trúc đệ quy, nhưng nó cũng có thể khó hiểu và khó gỡ lỗi. Điều quan trọng là sử dụng đệ quy một cách thận trọng và đảm bảo rằng đó là cách tiếp cận tốt nhất cho vấn đề bạn đang cố gắng giải quyết. =====================================
Phần kết luận
Khả năng của AI và LLM tiếp tục phát triển nhanh chóng. Điều chúng tôi thấy hấp dẫn nhất về một mô hình nguồn mở như Code Llama là khả năng tùy chỉnh và bảo mật dữ liệu. Không giống như các mô hình độc quyền, đóng, các công ty có thể chạy Code Llama trên máy chủ của riêng họ và tinh chỉnh nó bằng cách sử dụng dữ liệu và ví dụ mã nội bộ. Điều này cho phép thực thi các kiểu mã hóa và các phương pháp hay nhất trong khi vẫn giữ mã và dữ liệu ở chế độ riêng tư. Thay vì dựa vào các nguồn và API bên ngoài, các nhóm có thể truy vấn một chuyên gia tùy chỉnh được đào tạo về dữ liệu duy nhất của họ trong trung tâm dữ liệu của riêng họ. Bất kể trường hợp sử dụng của bạn là gì, chúng tôi nhận thấy việc sử dụng phiên bản Code Llama bằng cách sử dụng máy chủ Dell được tăng tốc bằng GPU Nvidia là một giải pháp đơn giản và mạnh mẽ cho phép tạo ra sự đổi mới thú vị cho các nhóm phát triển cũng như doanh nghiệp.
Các trợ lý mã hóa AI như Code Llama có tiềm năng biến đổi việc phát triển phần mềm trong tương lai. Bằng cách tự động hóa các tác vụ mã hóa thông thường, những công cụ này có thể giúp nhà phát triển tiết kiệm đáng kể thời gian để có thể dành thời gian tốt hơn cho việc thiết kế và logic hệ thống cấp cao hơn. Với khả năng kiểm tra lỗi và sự không nhất quán, các lập trình viên AI cũng có thể góp phần cải thiện chất lượng mã và giảm nợ kỹ thuật. Tuy nhiên, các thử nghiệm của chúng tôi tái khẳng định rằng AI tổng quát vẫn dễ gặp phải những hạn chế như tạo ra mã chất lượng thấp hoặc không có chức năng. Bây giờ chúng tôi đã có điểm cuối API cục bộ cho Code Llama, chúng tôi dự định tiến hành thử nghiệm kỹ lưỡng hơn để đánh giá thêm các khả năng và hạn chế của nó. Chúng tôi khuyến khích các nhà phát triển tự mình dùng thử Code Llama bằng cách sử dụng các tài nguyên chúng tôi cung cấp ở đây. Trải nghiệm với mô hình nguồn mở này là một cách tuyệt vời để bắt đầu khám phá các khả năng của AI trong việc tạo mã đồng thời góp phần vào sự cải tiến liên tục của nó.
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...