
Tin tức
Chuyển CUDA p2pbandwidthLatencyTest sang môi trường HIP trên Máy chủ Dell PowerEdge bằng GPU AMD
Giới thiệu
Khi viết mã trong CUDA, điều tự nhiên là bạn sẽ hỏi liệu mã đó có thể được mở rộng sang các GPU khác hay không. Tiện ích mở rộng này có thể cho phép mô hình lập trình “viết một lần, chạy mọi nơi” thành hiện thực. Mặc dù mô hình lập trình này là một mục tiêu cao cả nhưng chúng tôi có thể đạt được những lợi ích của việc chuyển mã từ CUDA (dành cho GPU NVIDIA) sang HIP (dành cho GPU AMD) mà không cần nỗ lực nhiều. Khả năng tương tác này mang lại giá trị gia tăng vì các nhà phát triển không phải viết lại mã ngay từ đầu. Nó không chỉ tiết kiệm thời gian mà còn tiết kiệm nỗ lực của quản trị viên hệ thống để chạy khối lượng công việc trên trung tâm dữ liệu tùy thuộc vào tính khả dụng của tài nguyên phần cứng.
Blog này cung cấp thông tin tổng quan ngắn gọn về nền tảng AMD ROCm™. Nó mô tả một trường hợp sử dụng chuyển bài kiểm tra độ trễ băng thông GPU ngang hàng (p2pbandwidthlatencytest) từ CUDA sang Giao diện điện toán không đồng nhất cho tính di động (HIP) để chạy trên GPU AMD.
Giới thiệu về ROCm và HIP
ROCm là một nền tảng phần mềm nguồn mở dành cho điện toán tăng tốc GPU của AMD. Nó hỗ trợ chạy khối lượng công việc HPC và AI trên các nhà cung cấp khác nhau. Các số liệu sau đây cho thấy các thành phần và khả năng cốt lõi của ROCm:
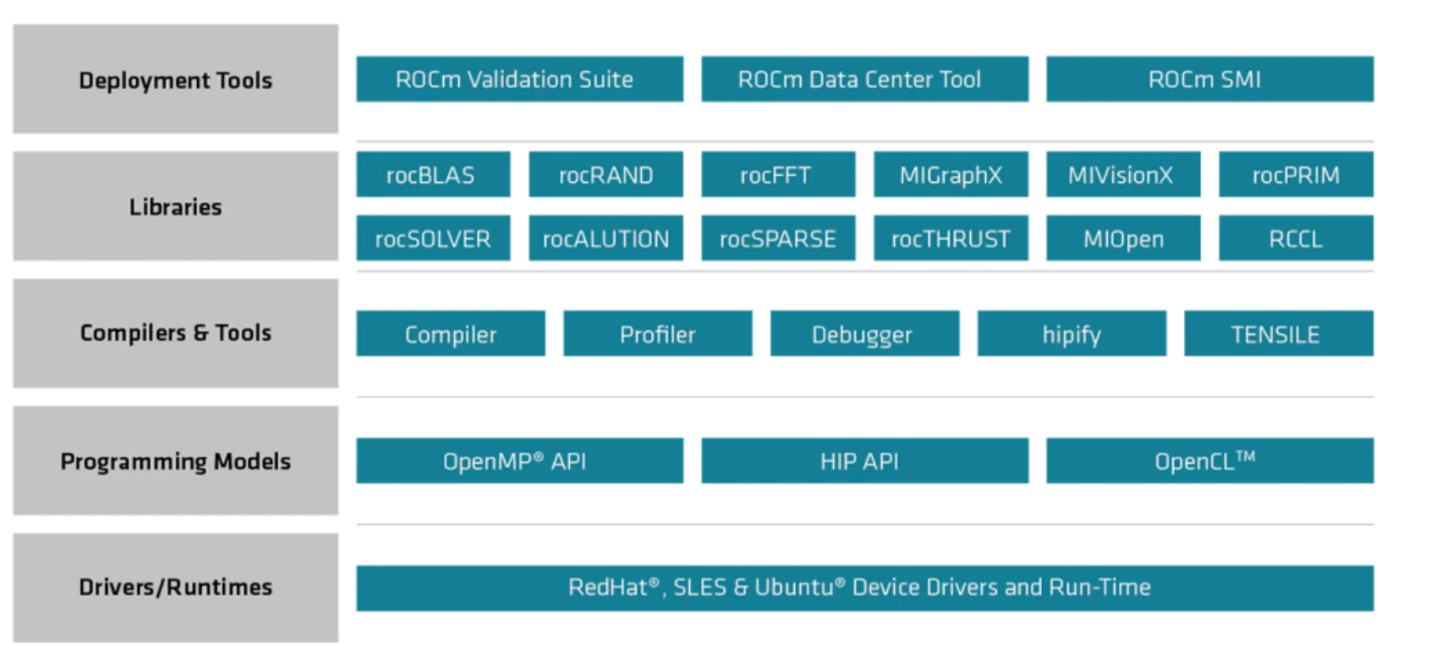
Hình 1: Ngăn xếp thư viện ROCm

Hình 2: Ngăn xếp ROCm
ROCm là gói đầy đủ tất cả những gì cần thiết để chạy các khối lượng công việc HPC và AI khác nhau. Nó bao gồm một tập hợp các trình điều khiển, API và các công cụ GPU khác hỗ trợ GPU AMD Instinct™ cũng như các bộ tăng tốc khác. Để đáp ứng mục tiêu chạy khối lượng công việc trên các máy gia tốc khác, HIP đã được giới thiệu.
HIP là mô hình lập trình GPU của AMD để thiết kế hạt nhân trên phần cứng GPU. Nó là API thời gian chạy C++ và ngôn ngữ lập trình phục vụ các ứng dụng trên các nền tảng khác nhau.
Một trong những tính năng chính của HIP là khả năng chuyển đổi mã CUDA sang HIP, cho phép chạy các ứng dụng CUDA trên GPU AMD. Khi mã được chuyển sang HIP, có thể chạy mã HIP trên GPU NVIDIA bằng cách sử dụng trình biên dịch được nền tảng CUDA hỗ trợ (HIP là mã C++ và nó cung cấp các tiêu đề hỗ trợ dịch giữa các API thời gian chạy HIP sang các API thời gian chạy CUDA). HIPify đề cập đến các công cụ dịch mã nguồn CUDA sang HIP C++.
Giới thiệu về CUDA p2pbandwidthLatencyTest
P2pbwLatencyTest xác định tốc độ truyền dữ liệu giữa các GPU bằng độ trễ tính toán và băng thông. Thử nghiệm này rất hữu ích để định lượng tốc độ giao tiếp giữa các GPU và đảm bảo rằng các GPU này có thể giao tiếp.
Ví dụ: trong quá trình đào tạo các mô hình học sâu song song với mô hình và dữ liệu quy mô lớn, bắt buộc phải đảm bảo rằng GPU có thể giao tiếp sau khi bế tắc hoặc các sự cố khác trong khi xây dựng và gỡ lỗi mô hình. Có các trường hợp sử dụng khác cho thử nghiệm này, chẳng hạn như cải thiện hiệu suất cấu hình BIOS, ý nghĩa về hiệu suất cập nhật trình điều khiển, v.v.
Chuyển p2pbandwidthLatencyTest
Các bước sau đây chuyển p2pbandwidthLatencyTest từ CUDA sang HIP:
- Đảm bảo rằng ROCm và HIP được cài đặt trong máy của bạn. Làm theo hướng dẫn cài đặt trong Hướng dẫn cài đặt ROCm tại:
https://rocmdocs.amd.com/en/latest/Installation_Guide/Installation_new.html#rocm-installation-guide-v4-5
Lưu ý : Phiên bản mới nhất của ROCm là v5. 2.0. Blog này mô tả một kịch bản chạy với ROCm v4.5. Bạn có thể chạy ROCm v5. x , tuy nhiên, bạn nên xem Hướng dẫn cài đặt ROCm v5.1.3 tại:
https://docs.amd.com/bundle/ROCm-Installation-Guide-v5.1.3/page/Overview_of_ROCm_Installation_Methods.html . - Xác minh cài đặt của bạn bằng cách chạy các lệnh được mô tả trong:
https://rocmdocs.amd.com/en/latest/Installation_Guide/Installation_new.html#verifying-rocm-installation - Theo tùy chọn, hãy đảm bảo rằng HIP được cài đặt như mô tả tại:
https://github.com/ROCm-Developer-Tools/HIP/blob/master/INSTALL.md#verify-your-installation
Chúng tôi khuyên bạn nên thực hiện bước này để đảm bảo rằng kết quả đầu ra mong đợi được sản xuất. - Cài đặt CUDA trên máy cục bộ của bạn để có thể chuyển đổi mã nguồn CUDA sang HIP.
Để căn chỉnh các phần phụ thuộc của phiên bản cần CUDA và LLVM +CLANG, hãy xem:
https://github.com/ROCm-Developer-Tools/HIPIFY#dependency - Xác minh rằng cài đặt của bạn thành công bằng cách kiểm tra quá trình biên dịch và chuyển đổi nguồn mẫu. Xem hướng dẫn tại:
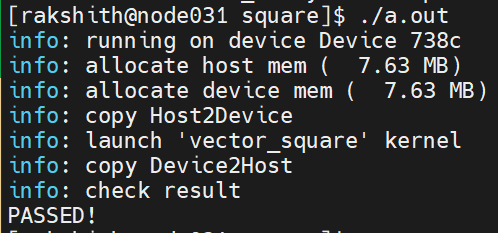
https://github.com/ROCm-Developer-Tools/HIP/tree/master/samples/0_Intro/square#squaremd Sao chép reponày để thực hiện kiểm tra xác thực. Nếu bạn có thể chạy chương trình Square.cpp sau thì quá trình cài đặt đã thành công: Xin chúc mừng! Bây giờ bạn có thể chạy quá trình chuyển đổi cho p2pbwLatencyTest.

- Nếu bạn sử dụng Trình quản lý cụm sáng, hãy tải mô-đun CUDA như sau:
tải mô-đun cuda11.1/toolkit/11.1.0
Chuyển đổi p2pbwLatencyTest từ CUDA sang HIP
Sau khi bạn tải xuống p2pbandwidthLatencyTest, hãy chuyển đổi bài kiểm tra từ CUDA sang HIP.
Có hai cách tiếp cận để chuyển đổi CUDA sang HIP:
- hipify-perl —Một tập lệnh Perl sử dụng các biểu thức chính quy để chuyển đổi các thay thế CUDA thành HIP. Nó rất hữu ích khi việc thay thế trực tiếp có thể giải quyết được vấn đề chuyển. Nó là một công cụ chuyển đổi đơn giản không kiểm tra mã CUDA hợp lệ. Một nhược điểm của tập lệnh là nó không thể chuyển đổi một số cấu trúc. Để biết thêm thông tin, hãy xem https://github.com/ROCm-Developer-Tools/HIPIFY#-hipify-perl .
- hipify-clang —Một công cụ dịch mã nguồn CUDA thành cây cú pháp trừu tượng, được duyệt qua bởi các trình so khớp chuyển đổi. Sau khi thực hiện tất cả các phép biến đổi, đầu ra HIP được tạo ra. Để biết thêm thông tin, hãy xem https://github.com/ROCm-Developer-Tools/HIPIFY#-hipify-clang .
Để biết thêm thông tin về HIPify, hãy xem Hướng dẫn tham khảo HIPify tại https://docs.amd.com/bundle/HIPify-Reference-Guide-v5.1/page/HIPify.html .
Để chuyển đổi p2pbwLatencyTest từ CUDA sang HIP:
- Sao chép kho lưu trữ mẫu CUDA và chạy chuyển đổi:
bản sao git https://github.com/NVIDIA/cuda-samples.git cd cuda-samples/Samples/5_Domain_Specific/p2pBandwidthLatencyTest hipify-Perl p2pBandwidthLatencyTest.cu > hip_converted.cpp hipcc hip_converted.cpp -o p2pamd.ou
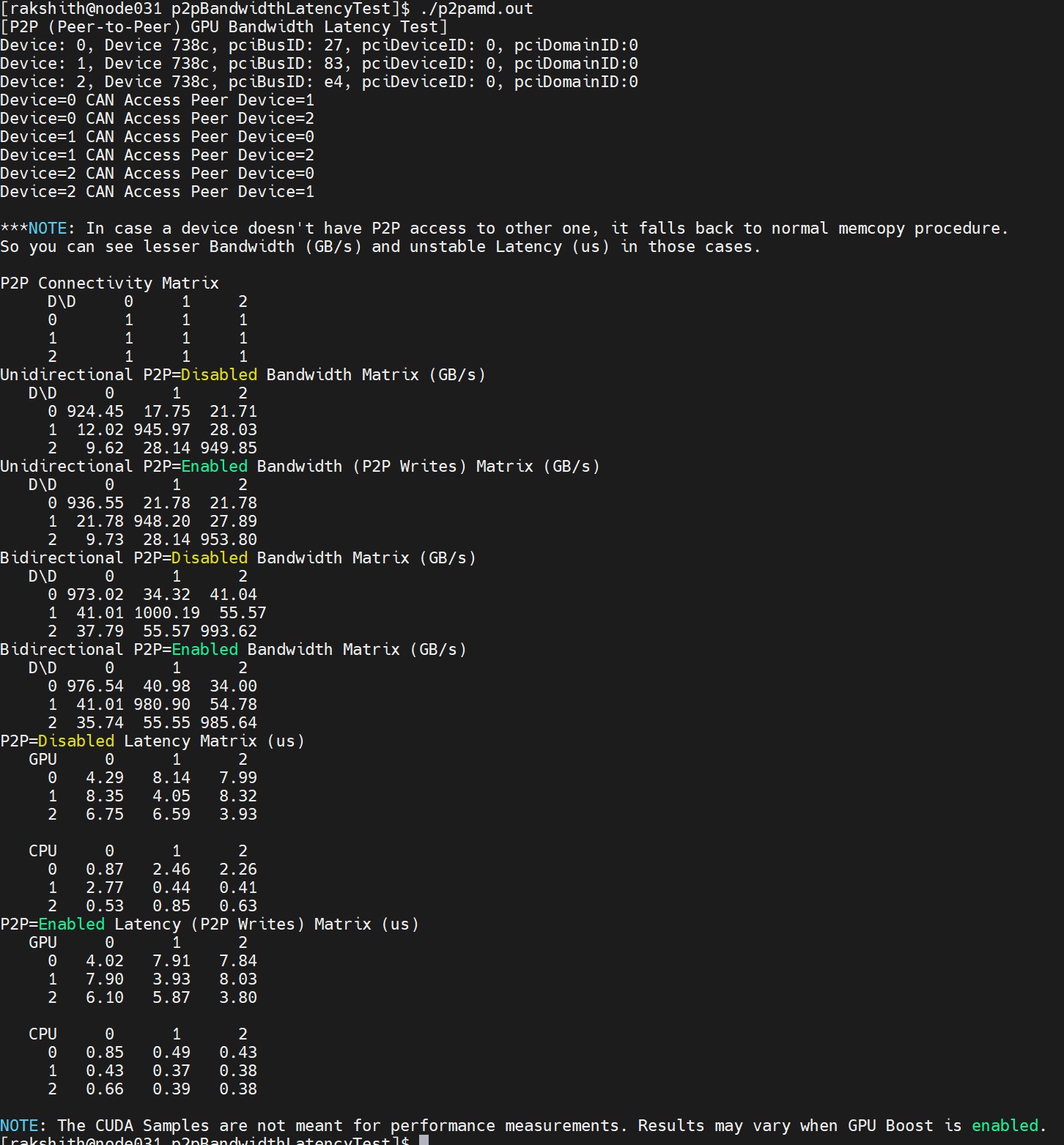
Ví dụ sau đây cho thấy đầu ra của chương trình:
Hình 3: Đầu ra của cuộc chạy thử nghiệm CUDAP2PBandWidthLatency trên GPU AMDĐầu ra phải bao gồm tất cả các GPU. Trong trường hợp sử dụng này, có ba GPU: 0, 1, 2.
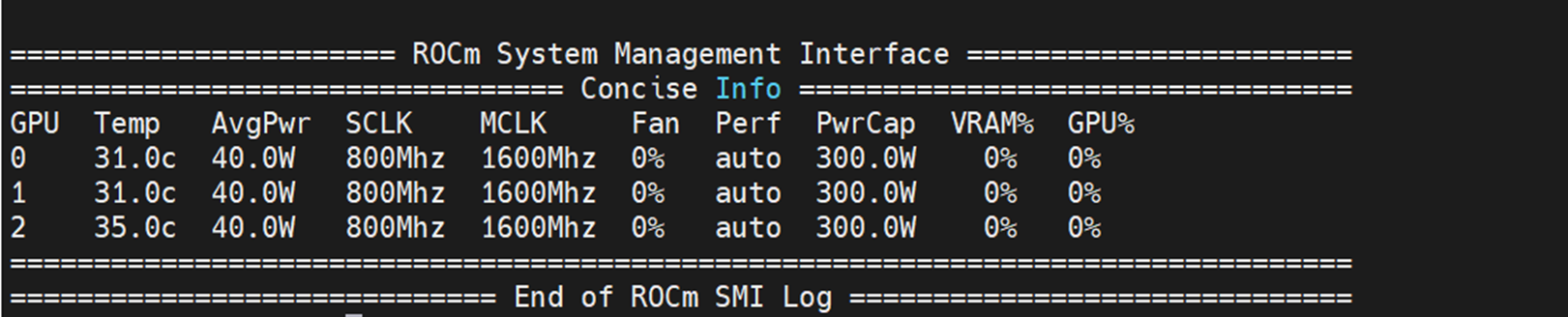
- Sử dụng lệnh rocminfo để xác định GPU trong máy chủ và sau đó bạn có thể sử dụng lệnh rocm-smi để xác định ba GPU trong máy chủ, như thể hiện trong hình sau:
Hình 4: Đầu ra của lệnh rocm-smi hiển thị cả ba GPU trong máy chủ
Phần kết luận
HIPify là một công cụ tiết kiệm thời gian để chuyển đổi mã CUDA để chạy trên bộ tăng tốc AMD Instinct. Bởi vì có những cải tiến nhất quán từ nhóm phần mềm AMD nên có các bản phát hành thường xuyên trong kho phần mềm. Đường dẫn HIPify là một cách tự động để hỗ trợ chuyển đổi từ CUDA sang khung tổng quát. Sau khi mã của bạn được chuyển sang HIP, chuyển đổi này cho phép chạy mã trên các chương trình tăng tốc khác nhau từ các nhà cung cấp khác nhau. Tính năng này giúp cho phép phát triển hơn nữa từ một nền tảng chung.
Blog này cho thấy cách chuyển đổi trường hợp sử dụng mẫu từ CUDA sang HIP bằng công cụ hipify-Perl.
Chạy thông tin hệ thống
Bảng 1: Chi tiết hệ thống
| Thành phần | Sự miêu tả |
| Hệ điều hành | CentOS Linux 8 (Lõi) |
| Phiên bản ROCm | 4,5 |
| phiên bản CUDA | 11.1 |
| Máy chủ | Dell PowerEdge R7525 |
| CPU | 2 x Bộ xử lý 32 nhân AMD EPYC 7543 |
| Máy gia tốc | Bản năng AMD MI210 |
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...