
Tin tức
Suy luận MLPerf™ v1.1 trên GPU ảo hóa và đa phiên bản
Giới thiệu
Bộ xử lý đồ họa (GPU) cung cấp khả năng tăng tốc vượt trội để cung cấp năng lượng cho khối lượng công việc Trí tuệ nhân tạo (AI) và Học sâu (DL) hiện đại. Phân bổ và cách ly tài nguyên GPU là một số thành phần chính mà các nhà khoa học dữ liệu làm việc trong môi trường dùng chung sử dụng để chạy thử nghiệm DL của họ một cách hiệu quả. Nhu cầu phân bổ và cách ly này trở nên rõ ràng khi một người dùng chỉ sử dụng một tỷ lệ nhỏ GPU, dẫn đến tài nguyên không được sử dụng đúng mức. Do sự phức tạp của thiết kế và kiến trúc, việc tối đa hóa việc sử dụng tài nguyên GPU trong môi trường dùng chung là một thách thức. Việc giới thiệu các khả năng GPU đa phiên bản (MIG) trong kiến trúc GPU NVIDIA Ampere cung cấp cách phân vùng GPU NVIDIA A100 và cho phép cách ly hoàn toàn giữa các phiên bản GPU. Thiết kế được xác thực của Dell thể hiện những lợi ích của ảo hóa đối với khối lượng công việc AI và phân tích hiệu suất MIG. Thiết kế này sử dụng phiên bản mới nhất của VMware vSphere cùng với bộ NVIDIA AI Enterprise trên máy chủ Dell PowerEdge và Cơ sở hạ tầng siêu hội tụ VxRail (HCI). Ngoài ra, kiến trúc này còn kết hợp với bộ lưu trữ Dell PowerScale nhằm cung cấp hiệu suất phân tích cần thiết và tính song song trên quy mô lớn để cung cấp các thuật toán AI ngốn nhiều dữ liệu nhất một cách đáng tin cậy.
Trong blog này, chúng tôi xem xét một số khái niệm chính, cách thiết lập và đặc tính hiệu suất MLPerf Inference v1.1 cho các máy ảo được lưu trữ trên máy chủ Dell PowerEdge R750xa được định cấu hình với cấu hình MIG trên GPU NVIDIA A100 80 GB. Chúng tôi so sánh kết quả suy luận cho các mô hình ResNet50 và Biểu diễn bộ mã hóa hai chiều từ Transformers (BERT).
Ý chính
Các khái niệm chính bao gồm:
- GPU đa phiên bản (MIG) —Khả năng MIG là một công nghệ tiên tiến được phát hành cùng với GPU NVIDIA A100 cho phép phân vùng GPU A100 lên đến bảy phiên bản hoặc các thiết bị MIG độc lập. Mỗi thiết bị MIG hoạt động song song và được trang bị bộ nhớ, bộ đệm và bộ xử lý đa luồng riêng.
Trong hình dưới đây, mỗi khối hiển thị cấu hình thiết bị MIG có thể có trong một GPU A100 80 GB:
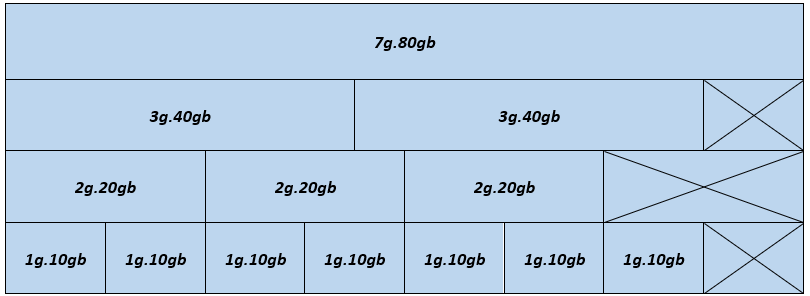
Hình 1- Cấu hình thiết bị MIG – GPU A100 80 GB
Hình minh họa vị trí vật lý của các phiên bản GPU sau khi chúng được khởi tạo trên GPU. Vì các phiên bản GPU được tạo và hủy ở nhiều vị trí khác nhau nên có thể xảy ra hiện tượng phân mảnh. Vị trí vật lý của một phiên bản GPU ảnh hưởng đến việc có thể tạo thêm nhiều phiên bản GPU bên cạnh nó hay không.
Các cấu hình được hỗ trợ cho GPU A100 80GB bao gồm:
- 1g.10gb
- 2g.20gb
- 3g.40gb
- 4g.40gb
- 7g.80gb
Trong Hình 1, một sự kết hợp hợp lệ được xây dựng bằng cách bắt đầu với một hồ sơ cá thể ở bên trái và tiến dần sang bên phải, đảm bảo rằng không có hai hồ sơ nào trùng nhau theo chiều dọc. Để biết thông tin chi tiết về cấu hình NVIDIA MIG, hãy xem Hướng dẫn sử dụng GPU đa phiên bản NVIDIA .
- MLPERF —MLCommons™ là tập đoàn gồm các nhà nghiên cứu hàng đầu về AI từ học viện, phòng thí nghiệm nghiên cứu và ngành công nghiệp. Nhiệm vụ của nó là “phát triển các tiêu chuẩn công bằng và hữu ích” nhằm cung cấp các đánh giá khách quan về hiệu suất đào tạo và suy luận cho phần cứng, phần mềm và dịch vụ—tất cả đều trong điều kiện được kiểm soát. Nền tảng của MLCommons bắt đầu với điểm chuẩn MLPerf vào năm 2018, điểm chuẩn này nhanh chóng được mở rộng thành một tập hợp các chỉ số ngành để đo lường hiệu suất học máy và thúc đẩy tính minh bạch của các kỹ thuật học máy. Để theo kịp xu hướng của ngành, MLPerf luôn phát triển, thực hiện các thử nghiệm mới và bổ sung khối lượng công việc mới thể hiện tính nghệ thuật trong AI.
Thiết lập suy luận MLPerf
Hệ thống đang được thử nghiệm bao gồm máy chủ ESXi có thể được vận hành từ vSphere.
Chi tiết hệ thống
Bảng sau đây cung cấp thông tin chi tiết về hệ thống.
Bảng 1: Chi tiết hệ thống
| Máy chủ | Dell PowerEdge R750xa (Hệ thống được NVIDIA chứng nhận) |
| Bộ xử lý | 2 x CPU Intel Xeon Gold 6338 @ 2,00 GHz |
| GPU | 4 x NVIDIA A100 PCIe (PCI Express) 80 GB |
| Bộ điều hợp mạng | Cổng kép Mellanox ConnectX-6 100 GbE |
| Kho | Dell PowerScale |
| phiên bản ESXi | 7.0.3 |
| phiên bản sinh học | 1.1.3 |
| Phiên bản trình điều khiển GPU | 470.82.01 |
| phiên bản CUDA | 11.4 |
Cấu hình hệ thống cho Suy luận MLPerf
Cấu hình cho Suy luận MLPerf trên môi trường ảo hóa yêu cầu các bước sau:
- Khởi động máy chủ bằng ESXi (xem Cài đặt ESXi trên máy chủ quản lý ), cài đặt trình điều khiển bootbank NVIDIA, bật MIG và khởi động lại máy chủ.
- Tạo một máy ảo (VM) trên máy chủ ESXi với chế độ khởi động EFI ( xem Sử dụng GPU với Máy ảo trên vSphere – Phần 2: VMDirectPath I/O ) và thêm các cài đặt cấu hình nâng cao sau:
pciPassthru.use64bitMMIO: ĐÚNG pciPassthru.allowP2P: ĐÚNG pciPassthru.64bitMMIOSizeGB: 64
- Thay đổi cài đặt VM và thêm thiết bị PCIe mới có cấu hình MIG (xem Sử dụng GPU với Máy ảo trên vSphere – Phần 3: Cài đặt Công nghệ GPU ảo NVIDIA ).
- Khởi động hệ điều hành dựa trên Linux và chạy các bước sau trong VM.
- Cài đặt Docker, CMake (xem Cài đặt CMake ), gói xây dựng cần thiết và CURL
- Tải xuống và cài đặt trình điều khiển NVIDIA MIG (trình điều khiển lưới).
- Cài đặt kho lưu trữ nvidia-docker ( xem Hướng dẫn cài đặt Bộ công cụ bộ chứa NVIDIA ) để chạy nvidia-container.
- Định cấu hình dịch vụ nvidia-grid để sử dụng cài đặt vGPU trên VM ( xem Sử dụng GPU với Máy ảo trên vSphere – Phần 3: Cài đặt Công nghệ GPU ảo NVIDIA ) và cập nhật giấy phép.
- Chạy lệnh sau để xác minh rằng thiết lập thành công:
nvidia-smi
Lưu ý : Mỗi VM bao gồm 32 vCPU và bộ nhớ 64 GB.
Cấu hình suy luận MLPerf cho MIG
Khi hệ thống đã được cấu hình, hãy định cấu hình MLPerf v1.1 trên máy ảo MIG. Để chạy điểm chuẩn suy luận MLPerf trên hệ thống hỗ trợ MIG đang được thử nghiệm, hãy làm như sau:
- Thêm chi tiết MIG vào tệp cấu hình suy luận:
 Hình 2- Cấu hình ví dụ để chạy suy luận bằng máy ảo hỗ trợ MIG
Hình 2- Cấu hình ví dụ để chạy suy luận bằng máy ảo hỗ trợ MIG - Thêm thông số kỹ thuật MIG hợp lệ vào biến hệ thống trong tệp system_list.py.
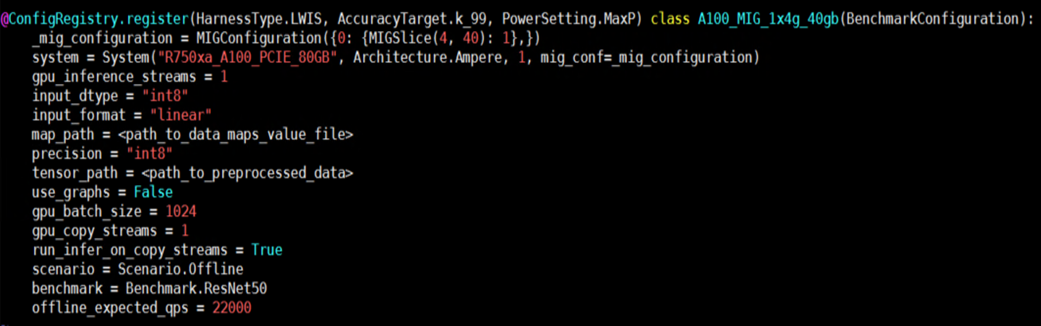
 Hình 3- Ví dụ về mục nhập hệ thống với cấu hình MIG
Hình 3- Ví dụ về mục nhập hệ thống với cấu hình MIG
Các bước này hoàn tất quá trình thiết lập hệ thống, sau đó là xây dựng hình ảnh, tạo công cụ và chạy điểm chuẩn. Để biết hướng dẫn chi tiết, hãy xem blog trước của chúng tôi về cách chạy MLPerf v1.1 trên các hệ thống kim loại trần.
Điểm chuẩn MLPerf v1.1
Kịch bản điểm chuẩn
Chúng tôi đã đánh giá độ trễ suy luận và thông lượng cho các mô hình ResNet50 và BERT bằng MLPerf Inference v1.1. Các tình huống trong bảng sau xác định số lượng máy ảo và cấu hình MIG tương ứng được sử dụng trong các bài kiểm tra hiệu năng. Tổng số lần kiểm tra cho mỗi kịch bản là 57. Kết quả được tính trung bình dựa trên ba lần chạy.
Lưu ý : Chúng tôi đã sử dụng MLPerf Inference v1.1 để đo điểm chuẩn nhưng kết quả hiển thị trong blog này không phải là một phần của bài nộp MLPerf chính thức.
Bảng 2: Cấu hình kịch bản
| Kịch bản | Hồ sơ MIG | Tổng số máy ảo |
| 1 | MIG nvidia-7-80c | 1 |
| 2 | MIG nvidia-4-40c | 1 |
| 3 | MIG nvidia-3-40c | 1 |
| 4 | MIG nvidia-2-20c | 1 |
| 5 | MIG nvidia-1-10c | 1 |
| 6 | MIG nvidia-4-40c + nvidia-2-20c + nvidia-1-10c | 3 |
| 7 | MIG nvidia-2-20c + nvidia-2-20c + nvidia-2-20c + nvidia-1-10c | 4 |
| số 8 | MIG nvidia-1-10c* 7 | 7 |
ResNet50
ResNet50 (xem Học tập dư thừa sâu để nhận dạng hình ảnh ) là một mạng nơ-ron tích chập sâu được sử dụng rộng rãi cho các ứng dụng thị giác máy tính khác nhau. Mạng nơ-ron này có thể giải quyết vấn đề độ dốc biến mất bằng cách cho phép độ dốc đi qua các lớp của mạng bằng cách sử dụng khái niệm bỏ qua kết nối. Hình sau đây hiển thị cấu hình ví dụ cho suy luận ResNet50:
Hình 4- Cấu hình chạy suy luận bằng mô hình Resnet50
Hình sau đây cho thấy hiệu suất suy luận ResNet50 dựa trên các kịch bản trong Bảng 2:
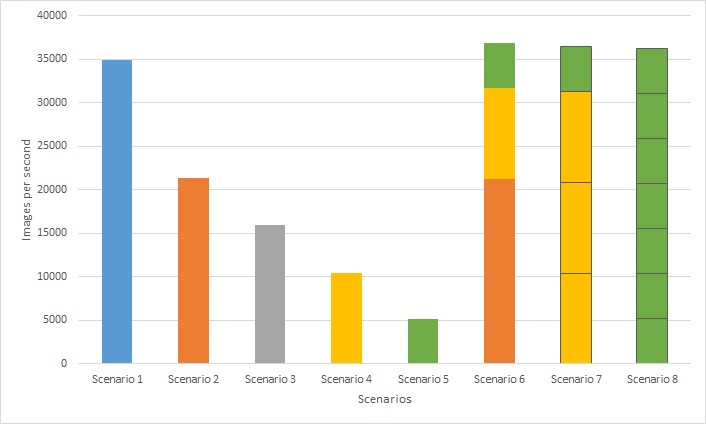
Hình 5- Thông lượng hiệu suất ResNet50 của MLPerf Inference v1.1 trên các máy ảo khác nhau có cấu hình MIG
Nhiều nhà khoa học dữ liệu có thể sử dụng tất cả tài nguyên GPU có sẵn trong khi chạy khối lượng công việc riêng lẻ của họ trên các phiên bản riêng biệt, cải thiện thông lượng tổng thể của hệ thống. Kết quả này được thấy rõ trên Kịch bản 6 đến 8, chứa nhiều phiên bản, so với Kịch bản 1 bao gồm một phiên bản duy nhất có cấu hình MIG lớn nhất cho A100 80 GB. Kịch bản 6 đạt được thông lượng hệ thống tổng thể cao nhất (cải thiện 5,77 phần trăm) so với Kịch bản 1. Ngoài ra, Kịch bản 8 cho thấy bảy máy ảo được trang bị các phiên bản GPU riêng lẻ có thể được xây dựng cho tối đa bảy nhà khoa học dữ liệu có thể tinh chỉnh các mô hình cơ sở ResNet50 của họ.
BERT
BERT (xem BERT: Đào tạo trước về Máy biến áp hai chiều sâu để hiểu ngôn ngữ ) là một mô hình biểu diễn ngôn ngữ hiện đại. BERT về cơ bản là một tập hợp các bộ mã hóa Transformer. Nó phù hợp cho dịch máy thần kinh, trả lời câu hỏi, phân tích tình cảm và tóm tắt văn bản, tất cả đều đòi hỏi kiến thức làm việc về ngôn ngữ đích.
BERT được đào tạo theo hai giai đoạn:
- Huấn luyện trước —Trong đó mô hình có được sự hiểu biết về ngôn ngữ và ngữ cảnh
- Tinh chỉnh —Trong đó mô hình thu được kiến thức về nhiệm vụ cụ thể như truy vấn và phản hồi.
Hình dưới đây hiển thị cấu hình ví dụ cho suy luận BERT:
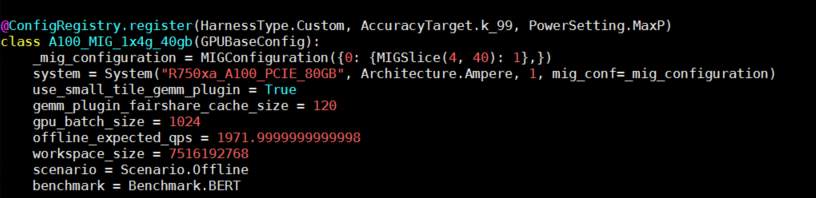
Hình 6- Cấu hình chạy suy luận sử dụng mô hình BERT
Hình dưới đây cho thấy hiệu suất suy luận BERT dựa trên các kịch bản trong Bảng 2:
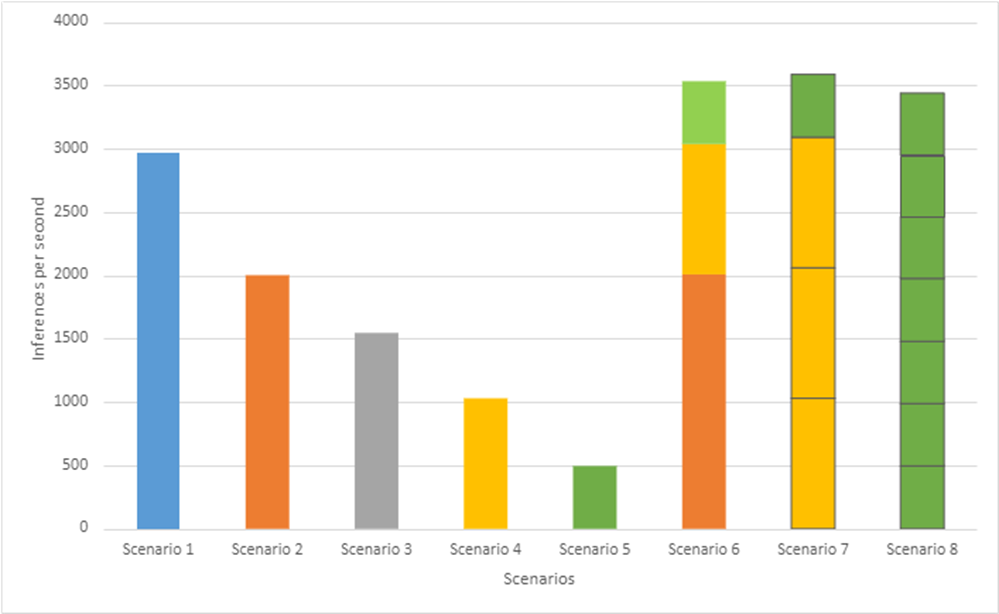 Hình 7- Thông lượng hiệu suất BERT của MLPerf Inference v1.1 trên các máy ảo khác nhau có cấu hình MIG
Hình 7- Thông lượng hiệu suất BERT của MLPerf Inference v1.1 trên các máy ảo khác nhau có cấu hình MIG
Giống như hiệu suất Suy luận Resnet50, chúng tôi thấy rõ rằng Kịch bản 6 đến 8, chứa nhiều phiên bản, hoạt động tốt hơn so với Kịch bản 1. Đặc biệt, Kịch bản 7 đạt được thông lượng hệ thống tổng thể cao nhất (cải thiện 21%) so với Kịch bản 1 trong khi đạt được độ chính xác 99,9%. mục tiêu. Ngoài ra, Kịch bản 8 cho thấy bảy máy ảo được trang bị các phiên bản GPU riêng lẻ có thể được xây dựng cho tối đa bảy nhà khoa học dữ liệu muốn tinh chỉnh các mô hình cơ sở BERT của họ.
Phần kết luận
Trong blog này, chúng tôi mô tả cách cài đặt và định cấu hình MLPerf Inference v1.1 trên máy chủ Dell PowerEdge 750xa bằng cơ sở hạ tầng ảo hóa VMware và GPU NVIDIA A100. Hơn nữa, chúng tôi kiểm tra hiệu suất của cấu hình một và nhiều MIG chạy trên GPU A100. Nếu khối lượng công việc ML của bạn chủ yếu tập trung vào suy luận và thời gian phản hồi không phải là vấn đề thì việc bật MIG trên GPU A100 có thể đảm bảo sử dụng GPU hoàn chỉnh với thông lượng tối đa. Các nhà phát triển có thể sử dụng máy ảo với tính toán GPU độc lập được phân bổ cho chúng. Ngoài ra, trong trường hợp sử dụng cấu hình MIG lớn nhất, hiệu suất có thể so sánh với các hệ thống kim loại trần. Kết quả suy luận từ các mô hình ResNet50 và BERT chứng minh rằng hiệu năng tổng thể của hệ thống sử dụng toàn bộ GPU hoặc nhiều máy ảo có phiên bản MIG được lưu trữ trên hệ thống R750xa với GPU VMware ESXi và NVIDIA A100 đã hoạt động tốt và tạo ra kết quả hợp lệ cho MLPerf Inference v1.1. Trong cả hai trường hợp, thông lượng trung bình và độ trễ đều bằng nhau. Kết quả này xác nhận rằng MIG cung cấp độ trễ và thông lượng có thể dự đoán được, độc lập với các quy trình khác hoạt động trên phiên bản MIG trên GPU.
Có giới hạn MIG đối với việc lập hồ sơ GPU trên máy ảo. Do tính chất chung của hiệu suất phần cứng trên tất cả các thiết bị MIG, chỉ một phiên lập hồ sơ GPU có thể chạy trên máy ảo; Không thể thực hiện được các phiên định hình GPU song song trên một máy ảo.
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...