
Tin tức
Khối lượng công việc biên MLPerf™ Inference v2.0 được cung cấp bởi máy chủ Dell PowerEdge
Dell Technologies gần đây đã gửi kết quả tới bộ điểm chuẩn MLPerf Inference v2.0. Blog này kiểm tra kết quả của hai máy chủ biên đặc biệt: máy chủ Dell PowerEdge XE2420 với GPU NVIDIA T4 Tensor Core và máy chủ Dell PowerEdge XR12 với GPU NVIDIA A2 Tensor Core .
Giới thiệu
Bây giờ là 6 giờ sáng thứ bảy. Bạn lê mình ra khỏi giường, tạt nước lên mặt, chải tóc rồi đi vào nhà bếp thiếu ánh sáng để ăn nhẹ trước khi chạy bộ buổi sáng. Hôm nay, bạn quyết định khám phá một khu vực mới trong khu phố vì mũi chú chó của bạn cần những bụi cây mới để đánh hơi. Khi đợi bánh mì nướng, bạn hỏi trợ lý giọng nói của mình “thời tiết thế nào?” Trong vòng vài giây, bạn biết rằng mình cần phải lấy thêm một lớp vì có thể sẽ có mưa nhỏ. Điện toán biên đã cứu hoạt động buổi sáng của bạn.
Mặc dù trường hợp sử dụng này được đề cập trong các điểm chuẩn MLPerf Mobile, nhưng dữ liệu được thảo luận trong blog này là từ điểm chuẩn Suy luận MLPerf đã được chạy trên các máy chủ Dell.
Điện toán biên là điện toán diễn ra ở “biên mạng”. Biên mạng đề cập đến nơi các thiết bị như điện thoại, máy tính bảng, máy tính xách tay, loa thông minh và thậm chí cả robot công nghiệp có thể truy cập vào phần còn lại của mạng. Trong trường hợp này, loa thông minh có thể thực hiện nhận dạng giọng nói thành văn bản để giảm tải quá trình xử lý thường phải được thực hiện trên đám mây. Việc giảm tải này không chỉ cải thiện thời gian phản hồi mà còn giảm lượng dữ liệu nhạy cảm được gửi và lưu trữ trên đám mây. Phạm vi của điện toán biên mở rộng vượt xa trợ lý giọng nói với các trường hợp sử dụng bao gồm xe tự hành, điện toán di động 5G, thành phố thông minh, bảo mật, v.v.
Máy chủ Dell PowerEdge XE2420 và PowerEdge XR 12 được thiết kế cho khối lượng công việc điện toán biên. Tiêu chí thiết kế dựa trên các tình huống thực tế như nhiệt độ cực cao, bụi và độ rung từ sàn nhà máy chẳng hạn. Tuy nhiên, mặc dù các máy chủ này không được đặt ở trung tâm dữ liệu nhưng độ tin cậy và hiệu suất của máy chủ không bị ảnh hưởng.
Máy chủ PowerEdge XE2420
Máy chủ PowerEdge XE2420 là máy chủ biên đặc biệt mang lại hiệu suất cao trong môi trường khắc nghiệt. Máy chủ này được thiết kế cho các ứng dụng biên đòi hỏi khắt khe như phân tích phát trực tuyến, hậu cần sản xuất, xử lý tế bào 5G và các ứng dụng AI khác. Đây là máy chủ 2U có độ sâu ngắn, dày đặc, ổ cắm kép, có thể xử lý áp lực môi trường lớn đối với các thành phần điện và vật lý của nó. Ngoài ra, máy chủ này còn lý tưởng cho các ứng dụng biên có độ trễ thấp và dung lượng lưu trữ lớn vì nó hỗ trợ 16x DDR4 RDIMM/LR-DIMM (12 DIMM được cân bằng) lên đến 2993 MT/s. Điều quan trọng là máy chủ này có thể hỗ trợ các cấu hình thẻ GPU/Flash PCI sau:
- Lên đến 2 x PCIe x16, thẻ FHFL thụ động lên tới 300 W (ví dụ: NVIDIA V100/s hoặc NVIDIA RTX6000)
- Lên đến 4 x PCIe x8; 75 W thụ động (ví dụ: GPU NVIDIA T4)
- Lên đến 2 x thẻ mở rộng lưu trữ FE1 (tối đa 20 x ổ M.2 trên mỗi thẻ)
Các hình sau đây hiển thị máy chủ PowerEdge XE2420 ( nguồn ):

Hình 1: Mặt trước của máy chủ PowerEdge XE2420

Hình 2: Mặt sau của máy chủ PowerEdge XE2420
Máy chủ PowerEdge XR12
Máy chủ PowerEdge XR12 là một phần của dòng máy chủ chắc chắn mang lại hiệu suất và độ tin cậy cao trong điều kiện khắc nghiệt. Máy chủ này là máy chủ 2U socket đơn, tuân thủ hàng hải, cung cấp các dịch vụ nâng cao cho biên. Nó bao gồm một CPU có tới 36 lõi x86, hỗ trợ bộ tăng tốc, DDR4, PCIe 4.0, bộ nhớ liên tục và tối đa sáu ổ đĩa. Ngoài ra, máy chủ PowerEdge XR12 còn cung cấp Bộ xử lý có khả năng mở rộng Intel Xeon thế hệ thứ 3.
Các hình sau đây hiển thị máy chủ PowerEdge XR12 ( nguồn ):

Hình 3: Mặt trước của máy chủ PowerEdge XR12

Hình 4: Mặt sau của máy chủ PowerEdge XR12
Thảo luận về hiệu suất
Hình dưới đây cho thấy so sánh hiệu suất ResNet 50 Ngoại tuyến của các cấu hình máy chủ và GPU khác nhau, bao gồm:
- Máy chủ PowerEdge XE8545 với GPU đa phiên bản A100 (MIG) 80 GB với bảy phiên bản của một phiên bản điện toán của cấu hình bộ nhớ 10gb
- Máy chủ PowerEdge XR12 với GPU A2
- Máy chủ PowerEdge XE2420 với GPU T4 và A30
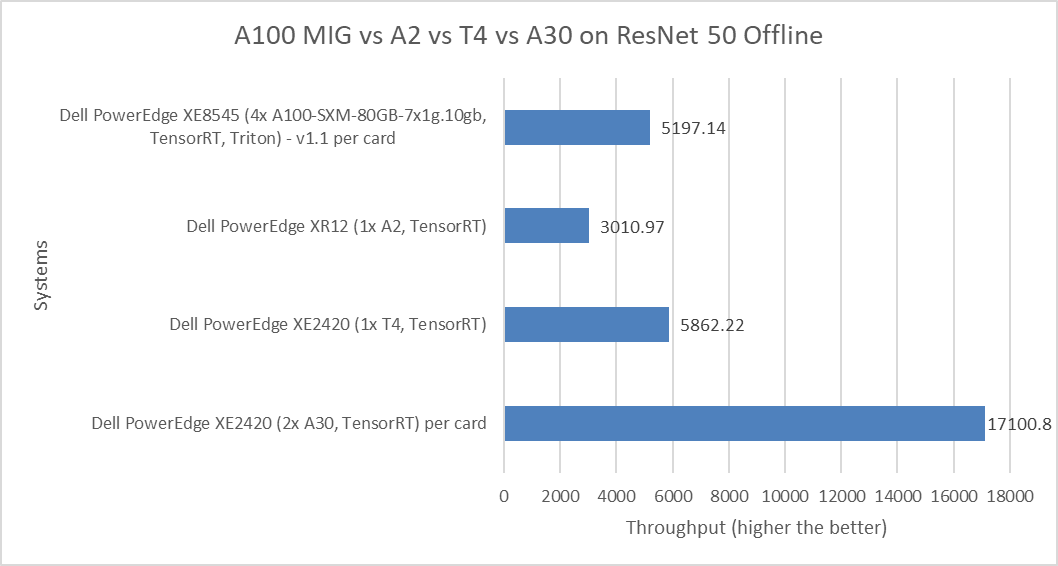
Hình 5: Hiệu suất ngoại tuyến của MLPerf Inference ResNet 50
ResNet 50 thuộc danh mục ứng dụng thị giác máy tính vì nó bao gồm khối lượng công việc phân loại hình ảnh, phát hiện đối tượng và phát hiện phân loại đối tượng.
Số MIG trên mỗi thẻ và được chia cho 28 do bốn thẻ GPU vật lý trong hệ thống được nhân với phiên bản thứ hai của cấu hình MIG. Các số không phải MIG cũng có trên mỗi thẻ.
Đối với điểm chuẩn ResNet 50, máy chủ PowerEdge XE2420 với GPU T4 cho thấy hiệu suất cao hơn gấp đôi so với máy chủ PowerEdge XR12 với GPU A2. Máy chủ PowerEdge XE8545 với A100 MIG cho thấy hiệu năng cạnh tranh khi so sánh với máy chủ PowerEdge XE2420 với GPU T4. Đồng bằng hiệu suất 12,8 phần trăm ủng hộ hệ thống PowerEdge XE2420. Tuy nhiên, máy chủ PowerEdge XE2420 với card GPU A30 chiếm vị trí hàng đầu trong cuộc so sánh này vì nó cho thấy hiệu suất gần như gấp ba lần so với máy chủ PowerEdge XE2420 với GPU T4.
Hình sau đây cho thấy sự so sánh về hiệu suất ngoại tuyến SSD-ResNet 34 của máy chủ PowerEdge XE8545 với A100 MIG và máy chủ PowerEdge XE2420 với GPU A30.
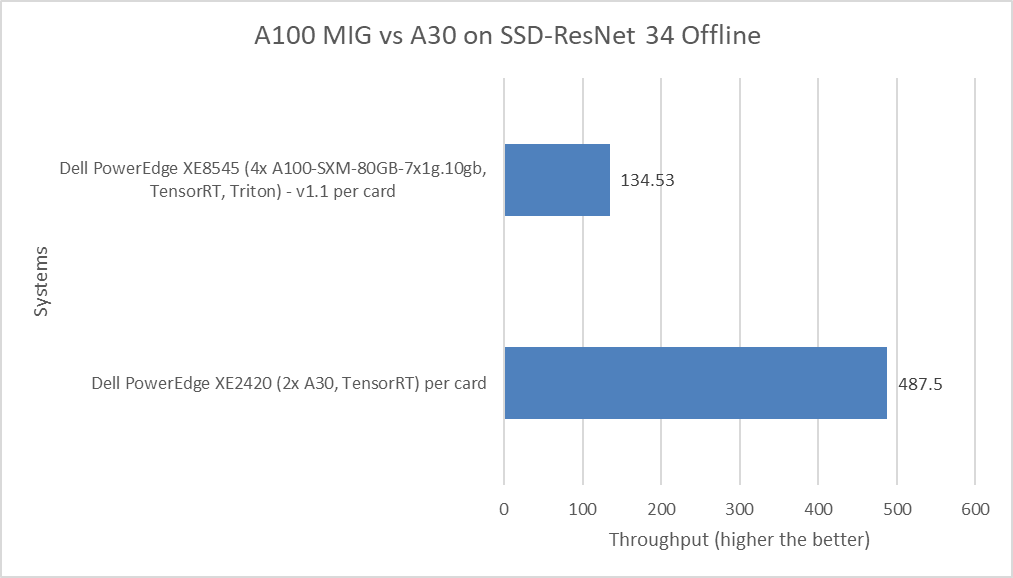
Hình 6: Hiệu suất ngoại tuyến của SSD-ResNet 34 suy luận MLPerf
Mẫu SSD-ResNet 34 thuộc danh mục thị giác máy tính vì nó thực hiện chức năng phát hiện đối tượng. Máy chủ PowerEdge XE2420 với card GPU A30 hoạt động tốt hơn ba lần so với máy chủ PowerEdge XE8545 với A100 MIG.
Hình sau đây thể hiện sự so sánh về hiệu suất ngoại tuyến của Bộ chuyển đổi mạng thần kinh tái phát (RNNT) của máy chủ PowerEdge XR12 với GPU A2 và máy chủ PowerEdge XE2420 với GPU T4:
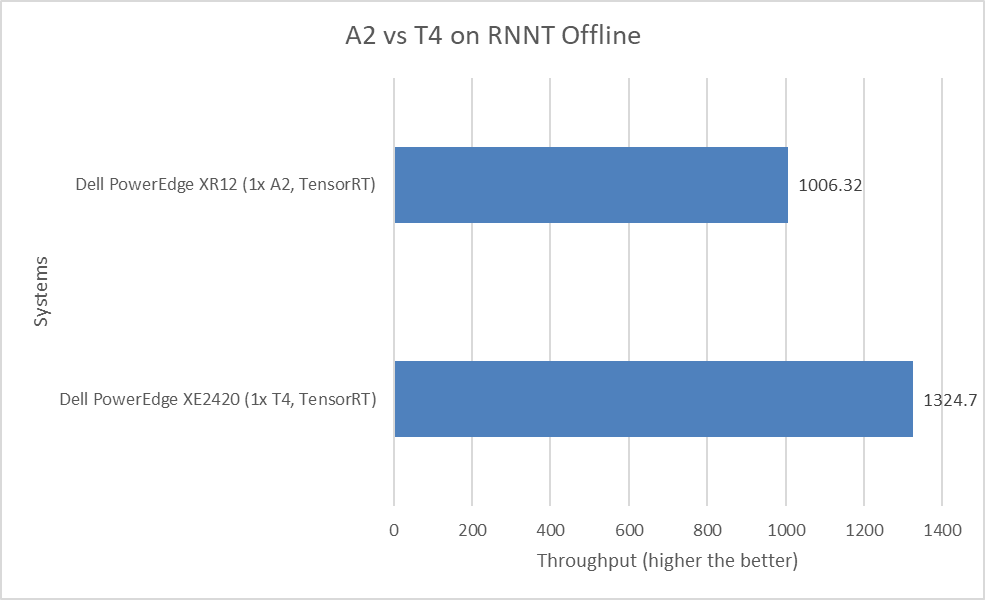
Hình 7: MLPerf Suy luận RNNT Hiệu suất ngoại tuyến
Mô hình RNNT thuộc danh mục nhận dạng giọng nói, có thể được sử dụng cho các ứng dụng như phụ đề tự động trong video YouTube và ra lệnh bằng giọng nói trên điện thoại thông minh. Tuy nhiên, đối với khối lượng công việc nhận dạng giọng nói, máy chủ PowerEdge XE2420 với GPU T4 và máy chủ PowerEdge XR12 với GPU A2 gần nhau hơn về hiệu suất. Chỉ có đồng bằng hiệu suất 32 phần trăm.
Hình sau đây cho thấy sự so sánh về hiệu suất BERT ngoại tuyến của các lần chạy mặc định và độ chính xác cao của máy chủ PowerEdge XR12 với GPU A2 và máy chủ PowerEdge XE2420 với GPU A30:
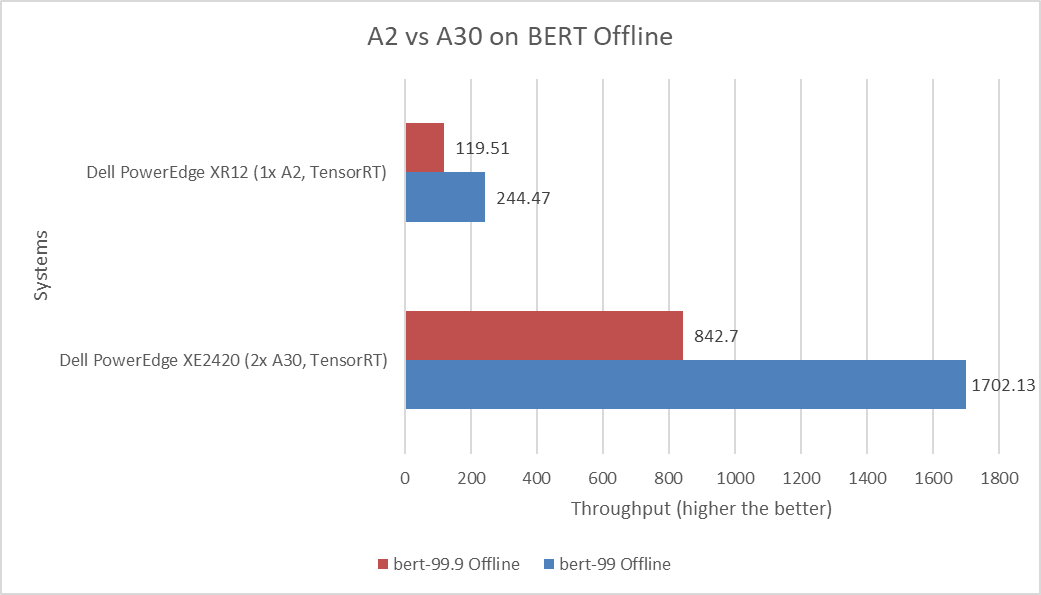
Hình 8: Hiệu suất ngoại tuyến BERT suy luận MLPerf
BERT là một mô hình biểu diễn ngôn ngữ hiện đại dành cho các ứng dụng Xử lý ngôn ngữ tự nhiên như phân tích tình cảm. Mặc dù máy chủ PowerEdge XE2420 với GPU A30 cho thấy hiệu suất tăng đáng kể, nhưng máy chủ PowerEdge XR12 với GPU A2 lại vượt trội hơn khi xét đến hiệu suất đạt được dựa trên số tiền bỏ ra.
Hình sau đây thể hiện so sánh hiệu suất ngoại tuyến của Mô hình đề xuất học sâu (DLRM) cho máy chủ PowerEdge XE2420 với GPU T4 và máy chủ PowerEdge XR12 với GPU A2:
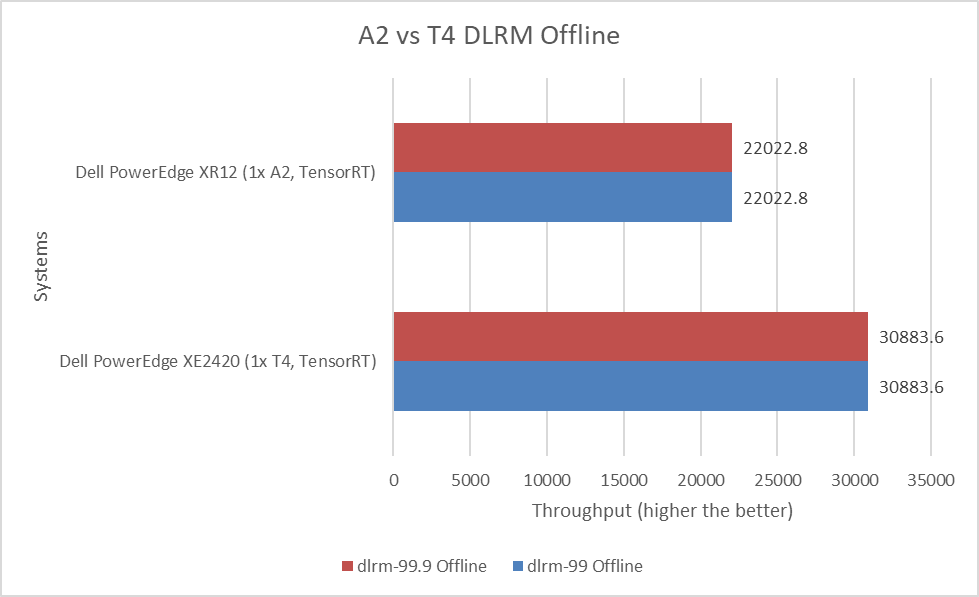
Hình 9: Hiệu năng ngoại tuyến của MLPerf Inference DLRM
DLRM sử dụng phương pháp lọc cộng tác và dựa trên phân tích dự đoán để đưa ra đề xuất, dựa trên tập dữ liệu được cung cấp. Hệ thống gợi ý cực kỳ quan trọng trong tìm kiếm, mua sắm trực tuyến và mạng xã hội trực tuyến. Hiệu suất của PowerEdge XE2420 T4 ở chế độ ngoại tuyến tốt hơn 40% so với máy chủ PowerEdge XR12 có GPU A2.
Mặc dù máy chủ PowerEdge XE2420 với GPU T4 có hiệu suất cao hơn nhưng máy chủ PowerEdge XR12 với GPU A2 là một lựa chọn tuyệt vời cho khối lượng công việc liên quan đến biên. GPU A2 được thiết kế để mang lại hiệu suất cao ở biên và tiêu thụ ít năng lượng hơn GPU T4 cho khối lượng công việc tương tự. Ngoài ra, GPU A2 là lựa chọn tiết kiệm chi phí hơn.
Thảo luận về quyền lực
Điều quan trọng là phải dự trù mức tiêu thụ điện năng cho tải trọng tới hạn trong trung tâm dữ liệu. Tải trọng tới hạn bao gồm các thành phần như máy chủ, bộ định tuyến, thiết bị lưu trữ và thiết bị bảo mật. Để gửi MLPerf Inference v2.0, Dell Technologies đã gửi số hiệu sức mạnh cho máy chủ PowerEdge XR12 với GPU A2. Hình 8 đến hình 11 thể hiện kết quả về hiệu suất và công suất đạt được trên hệ thống PowerEdge XR12. Các thanh màu xanh lam là kết quả hiệu suất và các thanh màu xanh lá cây là kết quả sức mạnh hệ thống. Đối với tất cả các lần cấp nguồn bằng GPU A2, Dell Technologies đã nhận được tuyên bố Số Một về hiệu suất trên mỗi watt đối với các tiêu chuẩn ResNet 50, RNNT, BERT và DLRM.
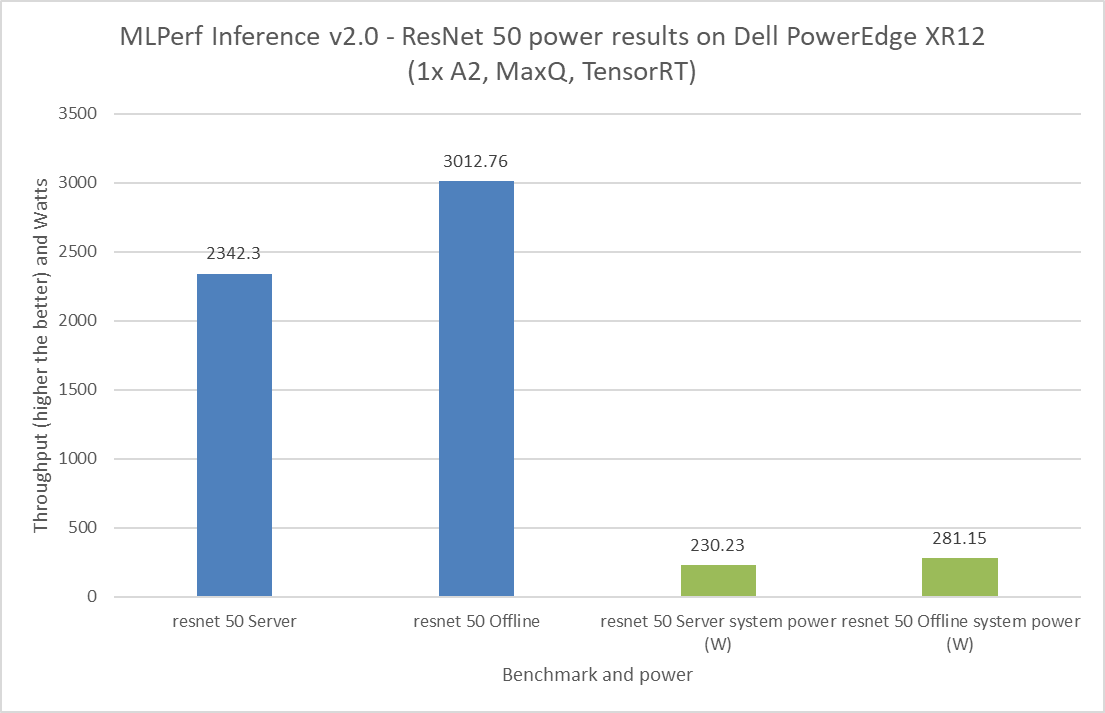
Hình 10: Kết quả cấp nguồn MLPerf Inference v2.0 ResNet 50 trên máy chủ Dell PowerEdge XR12
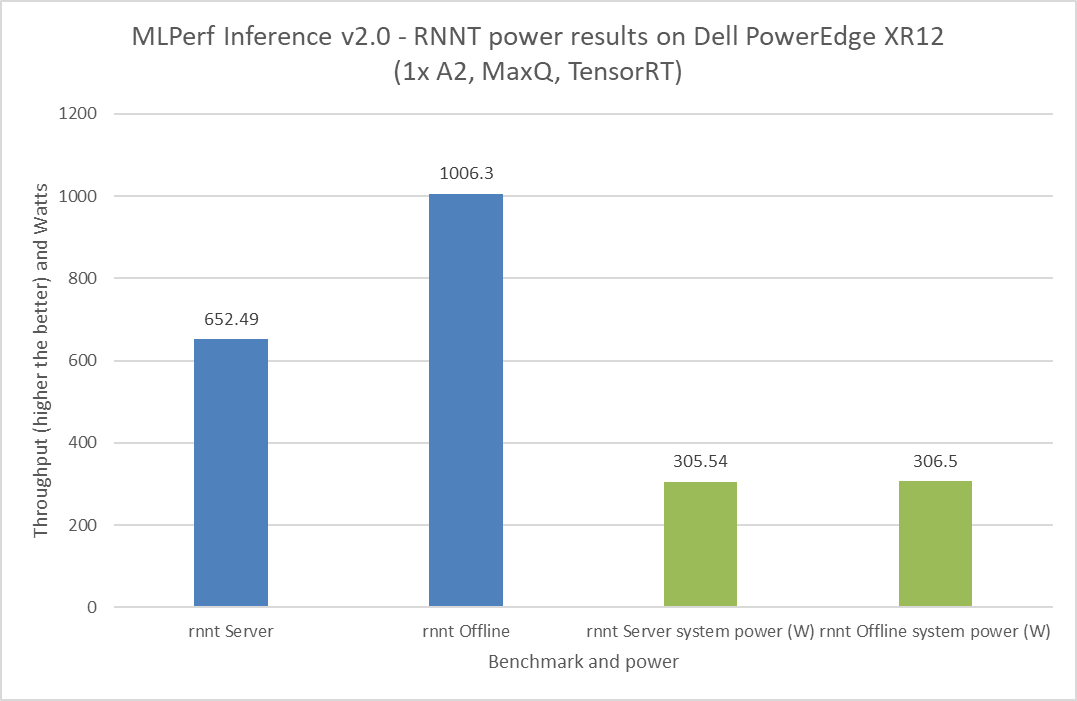
Hình 11: Kết quả cấp nguồn MLPerf Inference v2.0 RNNT trên máy chủ Dell PowerEdge XR12
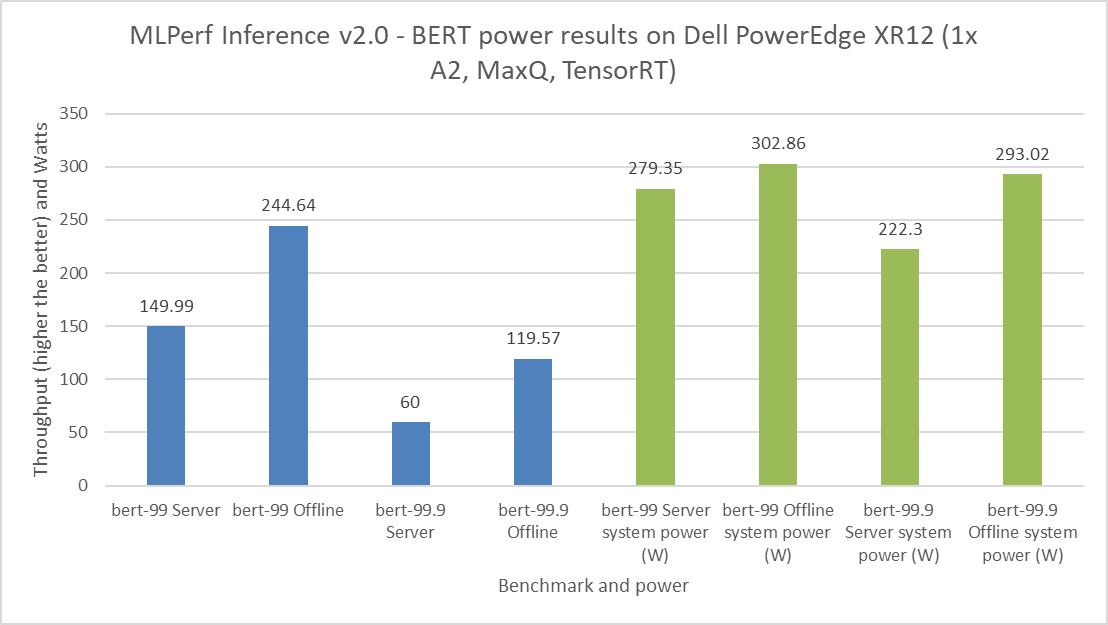
Hình 12: Kết quả cấp nguồn BERT MLPerf Inference v2.0 trên máy chủ Dell PowerEdge XR12
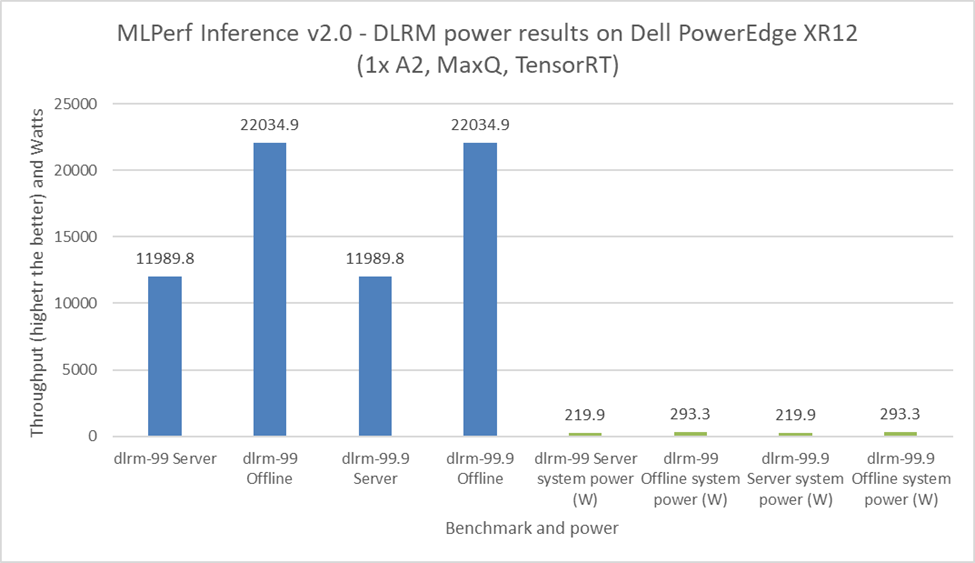 Hình 13: Kết quả cấp nguồn DLRM MLPerf Inference v2.0 trên máy chủ Dell PowerEdge XR12
Hình 13: Kết quả cấp nguồn DLRM MLPerf Inference v2.0 trên máy chủ Dell PowerEdge XR12
Lưu ý : Trong quá trình chúng tôi gửi tới MLPerf Inference v2.0 bao gồm cả số công suất, máy chủ PowerEdge XR12 đã không được điều chỉnh để có hiệu suất tối ưu trên mỗi điểm watt. Những kết quả này phản ánh số lượng điện năng tiêu thụ được tối ưu hóa hiệu suất của máy chủ.
Phần kết luận
Blog này xem xét kỹ hơn các bài nộp liên quan đến biên MLPerf Inference v2.0 của Dell Technologies. Bạn đọc có thể so sánh kết quả hiệu năng giữa máy chủ Dell PowerEdge XE2420 với GPU T4 và máy chủ Dell PowerEdge XR12 với GPU A2 với các hệ thống khác có bộ tăng tốc khác nhau. Sự so sánh này giúp người đọc đưa ra quyết định sáng suốt về khối lượng công việc ML ở biên. Hiệu suất, mức tiêu thụ điện năng và chi phí là những yếu tố quan trọng cần xem xét khi lập kế hoạch cho bất kỳ khối lượng công việc ML nào. Cả máy chủ PowerEdge XR12 và XE2420 đều là những lựa chọn tuyệt vời cho khối lượng công việc Deep Learning ở biên.
Bổ sung
Cấu hình SUT
Bảng sau đây mô tả các cấu hình Hệ thống đang thử nghiệm (SUT) từ các lần gửi MLPerf Inference v2.0:
Bảng 1: Cấu hình hệ thống MLPerf Inference v2.0 của máy chủ PowerEdge XE2420 và XR12
| Nền tảng | PowerEdge XE2420 1x T4, TensorRT | PowerEdge XR12 1x A2, TensorRT | PowerEdge XR12 1x A2, MaxQ, TensorRT | PowerEdge XE2420 2x A30, TensorRT |
| ID hệ thống MLPerf | XE2420_T4x1_edge_TRT | XR12_edge_A2x1_TRT | XR12_A2x1_TRT_MaxQ | XE2420_A30x2_TRT |
| Hệ điều hành | CentOS 8.2.2004 | Ubuntu 20.04.4 | ||
| CPU | CPU Intel Xeon Gold 6238 @ 2.10 GHz | CPU Intel Xeon Gold 6312U @ 2,40 GHz | CPU Intel Xeon Gold 6252N @ 2,30 GHz | |
| Ký ức | 256GB | 1 TB | ||
| GPU | NVIDIA T4 | NVIDIA A2 | NVIDIA A30 | |
| Yếu tố hình thức GPU | PCIe | |||
| số lượng GPU | 1 | 2 | ||
| ngăn xếp phần mềm | TenorRT 8.4.0
CUDA 11.6 cuDNN 8.3.2 Lái xe 510.47.03 ĐẠI LÝ 0.31.0 |
|||
Bảng 2: Cấu hình hệ thống MLPerf Inference v1.1 của máy chủ PowerEdge XE8545
| Nền tảng | PowerEdge XE8545 4x A100-SXM-80GB-7x1g.10gb, TensorRT, Triton |
| ID hệ thống MLPerf | XE8545_A100-SXM-80GB-MIG_28x1g.10gb_TRT_Triton |
| Hệ điều hành | Ubuntu 20.04.2 |
| CPU | AMD EPYC 7763 |
| Ký ức | 1 TB |
| GPU | NVIDIA A100-SXM-80GB (7x1g.10gb MIG) |
| Yếu tố hình thức GPU | SXM |
| số lượng GPU | 4 |
| ngăn xếp phần mềm | TenorRT 8.0.2
CUDA 11.3 cuDNN 8.2.1 Tài xế 470.57.02 ĐẠI LÝ 0.31.0 |
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...