
Tin tức
Hiệu suất học sâu trên MLPerf™ Training v1.0 với máy chủ Dell EMC DSS 8440
Blog này cung cấp kết quả đóng trung tâm dữ liệu MLPerf™ Training v1.0 cho các máy chủ Dell EMC DSS 8440 chạy điểm chuẩn đào tạo MLPerf . Kết quả của chúng tôi cho thấy hiệu suất đào tạo tối ưu cho cấu hình DSS 8440 mà chúng tôi đã chọn để chạy điểm chuẩn đào tạo. Ngoài ra, chúng ta có thể mong đợi mức tăng hiệu suất cao hơn bằng cách nâng cấp lên bộ tăng tốc NVIDIA A100 chạy khối lượng công việc học sâu trên máy chủ DSS 8440.
Lý lịch
Máy chủ DSS 8440 cho phép tối đa 10 GPU có chiều rộng gấp đôi trong PCIe. Cấu hình này làm cho nó trở thành một máy chủ phù hợp cho khả năng tính toán cao cần thiết để chạy các khối lượng công việc như đào tạo deep learning.
Các mô hình điểm chuẩn MLPerf Training v1.0 giải quyết các vấn đề như phân loại hình ảnh, phân đoạn hình ảnh y tế, phát hiện đối tượng có trọng lượng nhẹ và trọng lượng nặng, nhận dạng giọng nói, xử lý ngôn ngữ tự nhiên (NLP), cũng như học tập khuyến nghị và củng cố.
Kể từ tháng 6 năm 2021, chương trình Đào tạo MLPerf đã trưởng thành hơn và đã hoàn thành thành công phiên bản 1.0, đây là vòng nộp hồ sơ thứ tư của chương trình đào tạo MLPerf. Xem blog này để biết các tính năng mới của điểm chuẩn MLPerf Training v1.0.
giường thử nghiệm
Kết quả của các mô hình được gửi với máy chủ DSS 8440 bao gồm:
- 1 x DSS 8440 (x8 A100-PCIE-40GB)—Tất cả tám mẫu, bao gồm ResNet50, SSD, MaskRCNN, U-Net3D, BERT, DLRM, Minigo và RNN-T
- 2 x DSS 8440 (x16 A100-PCIE-40GB)—ResNet50 hai nút
- 3 x DSS 8440 (x24 A100-PCIe-40GB)—ResNet50 ba nút
- 1 x DSS 8440 (x8 A100-PCIE-40GB, được kết nối với Cầu nối NVLink)—BERT
Chúng tôi đã chọn BERT với NVLink Bridge vì BERT có nhiều giao tiếp giữa thẻ với thẻ mang lại lợi ích cho NVLink Bridge.
Bảng sau đây hiển thị môi trường phần mềm và cấu hình phần cứng DSS8440 một nút:
Bảng 1: Thông số nút DSS 8440
| Phần cứng | |
| Nền tảng | DSS 8440 |
| CPU trên mỗi nút | 2 x CPU Intel Xeon Gold 6248R @ 3,00 GHz |
| Bộ nhớ trên mỗi nút | 768 GB (24 x 32 GB) |
| GPU | 8 x NVIDIA A100-PCIE-40GB (250 W) |
| Lưu trữ máy chủ | 1×1,5TB NVMe + 2x512GB SSD |
| Mạng máy chủ | 1x ConnectX-5 IB EDR 100Gb/giây |
| Phần mềm | |
| Hệ điều hành | CentOS Linux phát hành 8.2.2004 (Lõi) |
| trình điều khiển GPU | 460.32.03 |
| OFED | 5.1-2.5.8.0 |
| CUDA | 11.2 |
| MXNet | NGC MXNet 21.05 |
| PyTorch | NGC PyTorch 21.05 |
| Dòng chảy căng | NGC TensorFlow 21.05-tf1 |
| cuBLAS | 11.5.1.101 |
| phiên bản NCCL | 2.9.8 |
| cuDNN | 8.2.0.51 |
| Phiên bản TensorRT | 7.2.3.4 |
| MPI mở | 4.1.1rc1 |
| Điểm kỳ dị | 3.6.4-1.el8 |
Kết quả benchmark MLPerf Training 1.0
Hiệu suất nút đơn
Hình dưới đây cho thấy hiệu suất của máy chủ DSS 8440 trên tất cả các mô hình đào tạo:
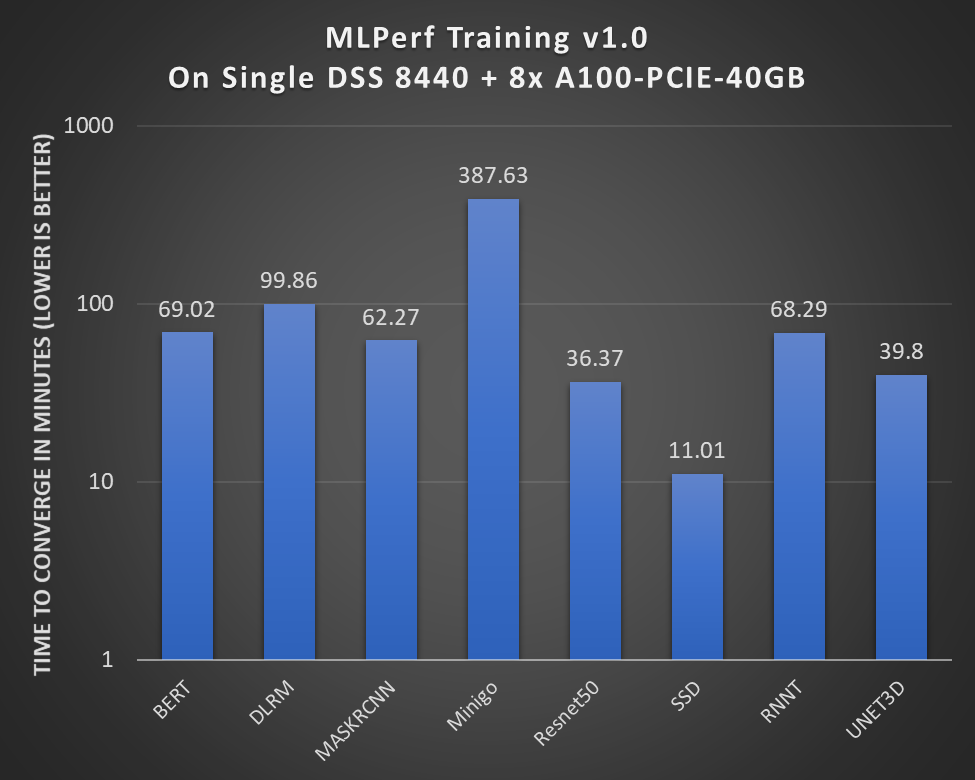
Hình 1: Hiệu suất của một nút DSS 8440 với 8 x GPU A100-PCIE-40GB
Trục y là trục có tỷ lệ theo cấp số nhân. Quá trình đào tạo MLPerf đo lường việc gửi bằng cách đánh giá xem hệ thống đang được thử nghiệm mất bao nhiêu phút để hội tụ đến độ chính xác mục tiêu đồng thời đáp ứng tất cả các quy tắc .
Những điểm chính bao gồm:
- Tất cả kết quả của chúng tôi đã được gửi chính thức tới Hiệp hội MLCommons ™ và được xác minh.
- Máy chủ DSS 8440 có thể chạy tất cả các mô hình trong điểm chuẩn MLPerf đào tạo v1.0 trên các lĩnh vực khác nhau như tầm nhìn, ngôn ngữ, thương mại và nghiên cứu.
- Máy chủ DSS8440 là một ứng cử viên sáng giá để phù hợp với loại hiệu suất cao trên mỗi watt.
- Với công suất thiết kế nhiệt (TDP) là 250 W, A100 PCIE 40 GB cung cấp thông lượng cao cho tất cả các điểm chuẩn. Thông lượng này, khi so sánh với các GPU khác có TDP cao hơn, cung cấp thông lượng gần như tương tự cho nhiều điểm chuẩn (xem kết quả tại đây ).
- Mô hình DLRM mất nhiều thời gian hơn để hội tụ vì việc triển khai khung Merlin HurgeCTR cơ bản được tối ưu hóa cho hệ số dạng SXM4. Máy chủ Dell EMC PowerEdge XE8545 của chúng tôi hỗ trợ kiểu dáng này.
Nhìn chung, bằng cách nâng cấp bộ tăng tốc lên NVIDIA A100 PCIE 40 GB, hiệu suất có thể được cải thiện gấp 2,1 đến 2,4 lần so với vòng MLPerf Training v0.7 trước đó sử dụng GPU NVIDIA V100 PCIe thế hệ trước.
Chia tỷ lệ đa nút
Đào tạo đa nút rất quan trọng đối với khối lượng công việc học máy lớn. Nó cung cấp một lượng sức mạnh tính toán đáng kể, giúp tăng tốc quá trình đào tạo một cách tuyến tính. Trong khi việc huấn luyện một nút chắc chắn sẽ hội tụ thì việc huấn luyện đa nút mang lại thông lượng cao hơn và hội tụ nhanh hơn.
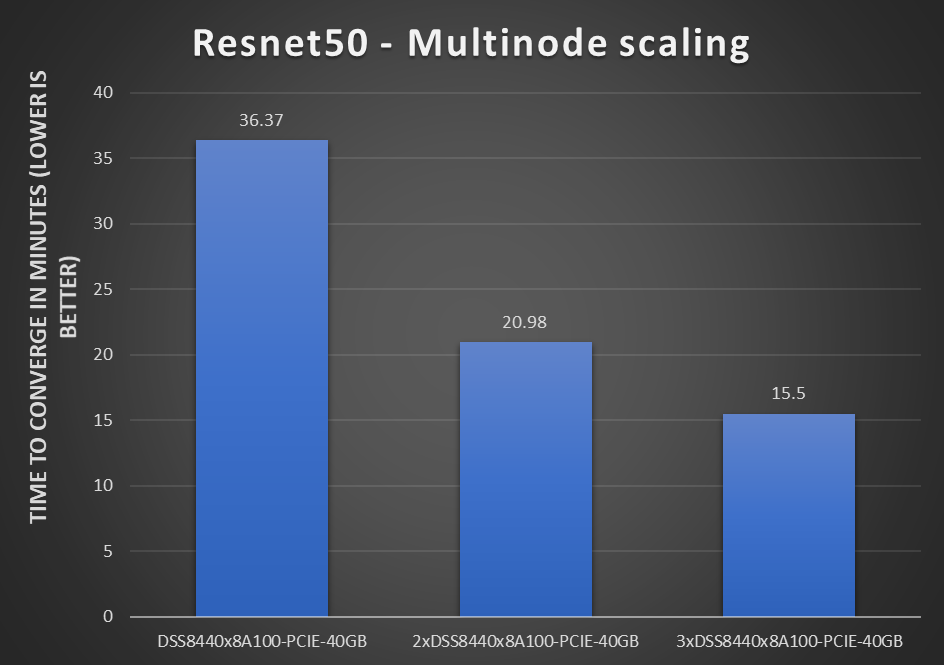
Hình 2: Chia tỷ lệ đa nút Resnet50 trên máy chủ DSS8440 với một, hai và ba nút
Những kết quả này dành cho nhiều (tối đa ba) máy chủ DSS 8440 được thử nghiệm với mô hình Resnet50.
Lưu ý những điều sau về những kết quả này:
- Việc thêm nhiều nút hơn vào cùng một nhiệm vụ đào tạo sẽ giúp giảm thời gian thực hiện tổng thể của quá trình đào tạo. Mức giảm này giúp các nhà khoa học dữ liệu điều chỉnh mô hình của họ một cách nhanh chóng. Một số mô hình lớn hơn có thể chạy nhiều ngày trên máy chủ GPU đơn nhanh nhất; đào tạo đa nút có thể giảm thời gian xuống còn vài giờ hoặc vài phút.
- Để có thể so sánh và tuân thủ các quy tắc RCP trong chương trình đào tạo MLPerf v1.0, chúng tôi giữ nguyên kích thước lô toàn cầu với hai và ba nút. Cấu hình này được coi là có khả năng mở rộng mạnh mẽ vì khối lượng công việc và kích thước lô toàn cầu không tăng theo số GPU cho cài đặt chia tỷ lệ đa nút. Do các ràng buộc của RCP, chúng ta không thể thấy tỷ lệ tuyến tính.
- Chúng tôi thấy số lượng thông lượng cao hơn với kích thước lô lớn hơn.
- Mô hình ResNet50 có quy mô tốt trên máy chủ DSS 8440.
Nói chung, việc bổ sung thêm nhiều máy chủ DSS 8440 vào một bài toán đào tạo deep learning quy mô lớn sẽ giúp giảm thời gian dành cho khối lượng công việc đào tạo đó.
Cầu NVLink
Cầu nối NVLINK là bảng cầu nối liên kết một cặp GPU để hỗ trợ khối lượng công việc trao đổi dữ liệu thường xuyên giữa các GPU. Các GPU PCIe A100 đó trên máy chủ DSS 8440 có thể hỗ trợ ba cầu nối cho mỗi cặp GPU. Hình dưới đây cho thấy sự khác biệt giữa mô hình BERT có và không có Cầu nối NVLink:
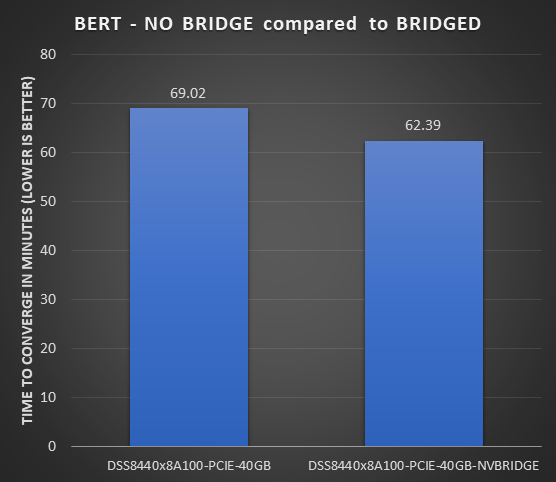
Hình 3: Chênh lệch thời gian hội tụ BERT khi không có và có Cầu nối NVLink trên máy chủ DSS 8440
- Cầu NVLink cung cấp khả năng hội tụ nhanh hơn 10% cho mô hình BERT.
- Do cấu trúc liên kết của phần cứng NVLink Bridge còn tương đối mới nên cấu trúc liên kết này có thể mang lại hiệu suất cao hơn khi phần mềm hỗ trợ hoàn thiện.
Kết luận và công việc tương lai
Máy chủ Dell EMC DSS 8440 rất phù hợp cho khối lượng công việc đào tạo deep learning hiện đại, giúp giải quyết các vấn đề khác nhau bao gồm phân loại hình ảnh, phân đoạn hình ảnh y tế, phát hiện đối tượng có trọng lượng nhẹ và trọng lượng nặng, nhận dạng giọng nói, xử lý ngôn ngữ tự nhiên (NLP), khuyến nghị và học tăng cường. Những máy chủ này cung cấp thông lượng cao và là phương tiện có khả năng mở rộng tuyệt vời để chạy các công việc đa nút. Chúng cung cấp khả năng hội tụ nhanh hơn trong khi đáp ứng các hạn chế về đào tạo. Việc kết hợp Cầu NVLink với bộ tăng tốc PCIE NVIDIA A100 có thể cải thiện thông lượng cho các mô hình giao tiếp giữa các GPU cao hơn như BERT. Hơn nữa, quản trị viên trung tâm dữ liệu có thể mong đợi cải thiện thông lượng đào tạo deep learning theo mức độ lớn bằng cách nâng cấp lên bộ tăng tốc NVIDIA A100 từ bộ tăng tốc thế hệ trước nếu trung tâm dữ liệu của họ đang sử dụng máy chủ DSS 8440.
Với sự hỗ trợ gần đây của GPU A100-PCIe-80GB trên máy chủ DSS8440, chúng tôi dự định tiến hành đo điểm chuẩn đào tạo MLPerf với 10 GPU trong mỗi máy chủ, điều này sẽ cho phép chúng tôi đưa ra so sánh về hiệu suất mở rộng và mở rộng quy mô.
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...