
Tin tức
Cách chạy các mô hình AI lượng tử hóa trên máy trạm chính xác
Generative AI (GenAI) đã làm sụp đổ thế giới điện toán và khách hàng của chúng tôi muốn bắt đầu làm việc với các mô hình ngôn ngữ lớn (LLM) để phát triển các khả năng cải tiến mới nhằm thúc đẩy năng suất, hiệu quả và sự đổi mới trong công ty của họ. Dell Technologies có danh mục cơ sở hạ tầng AI rộng nhất thế giới trải dài từ đám mây đến thiết bị khách, tất cả ở một nơi*—cung cấp các giải pháp và dịch vụ AI toàn diện được thiết kế để đáp ứng khách hàng mọi lúc mọi nơi trong hành trình AI của họ. Dell cũng cung cấp các giải pháp phần cứng được thiết kế để hỗ trợ khối lượng công việc AI, từ máy trạm (di động và cố định) đến máy chủ để tính toán hiệu năng cao, lưu trữ dữ liệu, cơ sở hạ tầng được xác định bằng phần mềm gốc trên nền tảng đám mây, chuyển mạch mạng, bảo vệ dữ liệu, HCI và các dịch vụ. Nhưng một trong những câu hỏi lớn nhất từ khách hàng của chúng tôi là làm cách nào để xác định liệu PC có thể hoạt động hiệu quả với một LLM cụ thể hay không. Chúng tôi sẽ cố gắng giúp trả lời câu hỏi đó và cung cấp một số hướng dẫn về các lựa chọn cấu hình mà người dùng nên cân nhắc khi làm việc với GenAI.
Trước tiên, hãy xem xét một số điều cơ bản về những gì hữu ích khi xử lý LLM trong PC. Mặc dù các quy trình AI có thể được xử lý trong CPU hoặc một loại mạch AI chuyên dụng mới gọi là NPU, nhưng GPU NVIDIA RTX hiện giữ vị trí dẫn đầu về xử lý AI trong PC có mạch chuyên dụng gọi là lõi Tensor. Các lõi RTX Tensor được thiết kế để hỗ trợ tính toán toán học có độ chính xác hỗn hợp vốn là trọng tâm của quá trình xử lý AI. Nhưng việc thực hiện phép toán chỉ là một phần của câu chuyện, LLM có sự cân nhắc bổ sung về không gian bộ nhớ khả dụng dựa trên dấu chân bộ nhớ tiềm năng của chúng. Để tối đa hóa hiệu suất của AI trong GPU, bạn muốn quá trình xử lý LLM phù hợp với GPU VRAM. Dòng GPU của NVIDIA có khả năng mở rộng trên cả dòng máy trạm di động và máy trạm cố định để cung cấp các tùy chọn về số lượng lõi Tensor và GPU VRAM, nhờ đó, hệ thống có thể dễ dàng điều chỉnh kích thước cho phù hợp. Hãy nhớ rằng một số máy trạm cố định có thể lưu trữ nhiều khả năng mở rộng GPU hơn nữa.
Ngày càng có nhiều LLM đa dạng xuất hiện trên thị trường, nhưng một trong những cân nhắc quan trọng nhất để xác định yêu cầu phần cứng là kích thước tham số của LLM được chọn. Lấy Llama-2 LLM của Meta AI. Nó có sẵn ở ba kích cỡ tham số khác nhau—bảy, 13 và 70 tỷ tham số. Nói chung, với kích thước tham số cao hơn, người ta có thể mong đợi độ chính xác cao hơn từ LLM và khả năng ứng dụng cao hơn cho các ứng dụng kiến thức tổng quát.
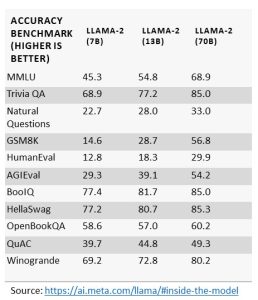
Cho dù mục tiêu của khách hàng là lấy mô hình nền tảng và chạy nó như để suy luận hay điều chỉnh nó cho phù hợp với trường hợp sử dụng và dữ liệu cụ thể của họ, thì họ cần phải nhận thức được các yêu cầu mà LLM sẽ đặt ra cho máy và cách quản lý tốt nhất người mẫu. Phát triển và đào tạo một mô hình dựa trên trường hợp sử dụng cụ thể bằng cách sử dụng dữ liệu dành riêng cho khách hàng là nơi khách hàng nhận thấy sự đổi mới và lợi nhuận lớn nhất từ các dự án AI của họ. Các mô hình có kích thước tham số lớn nhất có thể đưa ra các yêu cầu về hiệu suất cực cao cho máy khi phát triển các tính năng và ứng dụng mới với LLM, vì vậy, các nhà khoa học dữ liệu đã phát triển các phương pháp giúp giảm chi phí xử lý và đồng thời quản lý độ chính xác của đầu ra LLM.
Lượng tử hóa là một trong những cách tiếp cận đó. Đây là một kỹ thuật được sử dụng để giảm kích thước của LLM bằng cách sửa đổi độ chính xác toán học của các tham số bên trong của chúng (tức là trọng số). Việc giảm độ chính xác của bit có hai tác động đến LLM, giảm dấu chân xử lý và yêu cầu bộ nhớ, đồng thời cũng ảnh hưởng đến độ chính xác đầu ra của LLM. Lượng tử hóa có thể được xem tương tự như nén hình ảnh JPEG, trong đó việc nén nhiều hơn có thể tạo ra hình ảnh hiệu quả hơn, nhưng việc nén quá nhiều có thể tạo ra những hình ảnh có thể không đọc được trong một số trường hợp sử dụng.
Hãy xem một ví dụ về cách lượng tử hóa LLM có thể làm giảm bộ nhớ GPU cần thiết.

Nói một cách thực tế, những khách hàng muốn chạy mẫu Llama-2 được lượng tử hóa ở độ chính xác 4 bit có nhiều lựa chọn trong dòng máy trạm Dell Precision.

Chạy ở độ chính xác cao hơn (BF16) sẽ nâng cao yêu cầu, nhưng Dell có các giải pháp có thể phục vụ mọi kích thước LLM và bất kỳ độ chính xác nào cần thiết.

Do những tác động tiềm tàng đến độ chính xác đầu ra, một kỹ thuật khác gọi là tinh chỉnh có thể cải thiện độ chính xác bằng cách huấn luyện lại một tập hợp con các tham số LLM trên dữ liệu cụ thể của bạn để cải thiện độ chính xác đầu ra cho một trường hợp sử dụng cụ thể. Tinh chỉnh điều chỉnh trọng số của một số tham số đã huấn luyện và có thể đẩy nhanh quá trình huấn luyện cũng như cải thiện độ chính xác đầu ra. Việc kết hợp tinh chỉnh với lượng tử hóa có thể tạo ra các mô hình ngôn ngữ nhỏ dành riêng cho ứng dụng, lý tưởng để triển khai trên nhiều loại thiết bị hơn với yêu cầu về sức mạnh xử lý AI thậm chí còn thấp hơn. Một lần nữa, nhà phát triển muốn tinh chỉnh LLM có thể tự tin sử dụng máy trạm Precision làm hộp cát trong quy trình xây dựng giải pháp GenAI.
Một kỹ thuật khác để quản lý chất lượng đầu ra của LLM là kỹ thuật được gọi là Thế hệ tăng cường truy xuất (RAG). Cách tiếp cận này cung cấp thông tin cập nhật trái ngược với các kỹ thuật đào tạo AI thông thường, vốn tĩnh và lỗi thời theo thông tin được sử dụng khi chúng được đào tạo. RAG tạo ra kết nối động giữa LLM và thông tin liên quan từ các nguồn kiến thức có thẩm quyền, được xác định trước. Bằng cách sử dụng RAG, các tổ chức có quyền kiểm soát tốt hơn đối với kết quả đầu ra được tạo ra và người dùng hiểu rõ hơn về cách LLM tạo ra phản hồi.
Những kỹ thuật khác nhau khi làm việc với LLM không loại trừ lẫn nhau và thường mang lại hiệu suất và độ chính xác cao hơn khi được kết hợp và tích hợp.
Tóm lại, có những quyết định quan trọng liên quan đến quy mô của LLM và kỹ thuật nào có thể cung cấp thông tin tốt nhất cho cấu hình của hệ thống máy tính cần thiết để hoạt động hiệu quả với LLM. Dell Technologies tự tin rằng bất kể khách hàng muốn đi theo hướng nào trên hành trình AI của họ, chúng tôi đều có các giải pháp , từ máy tính để bàn đến trung tâm dữ liệu, để hỗ trợ họ.
*Dựa trên phân tích của Dell, tháng 8 năm 2023.
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...