
Tin tức
Hiệu quả của việc đào tạo hàng loạt lớn cho dịch máy thần kinh với Intel Xeon
Chúng tôi biết rằng việc sử dụng kích thước lô thực sự lớn trong quá trình đào tạo có thể khiến các mô hình có khả năng khái quát hóa kém. Nhưng các lô lớn thực sự ảnh hưởng như thế nào đến việc khái quát hóa và tối ưu hóa các mô hình mạng lưới thần kinh? Năm 2018 là một năm tuyệt vời cho nghiên cứu về Dịch máy thần kinh (NMT). Chúng tôi đã chứng kiến sự bùng nổ về số lượng tài liệu nghiên cứu được xuất bản trong lĩnh vực này, từ mô tả các kiến trúc mới và thú vị đến các kỹ thuật đào tạo hiệu quả. Các tài liệu nghiên cứu đã chỉ ra rằng quy mô lô lớn hơn và độ chính xác giảm có thể giúp cải thiện cả thời gian và chất lượng đào tạo.
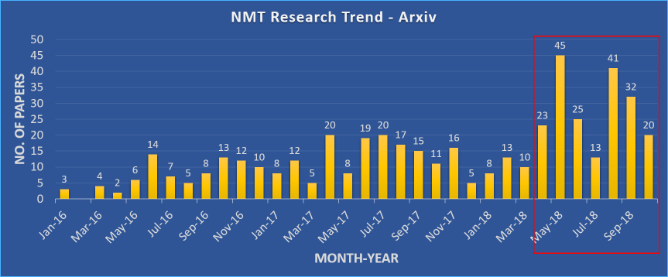
Hình 1: Số lượng bài báo được xuất bản trên Arxiv với ‘bản dịch máy thần kinh’ trong tiêu đề hoặc phần tóm tắt trong danh mục ‘cs’.
Trong các blog trước đây, chúng tôi đã trình bày cách mở rộng quy mô hệ thống NMT một cách hiệu quả cũng như một số thách thức liên quan đến việc mở rộng quy mô. Trong blog này, chúng ta sẽ khám phá tính hiệu quả của việc đào tạo hàng loạt lớn bằng bộ xử lý Intel® Xeon® có khả năng mở rộng. Công việc được thảo luận trong blog dựa trên quá trình đào tạo mạng lưới thần kinh được thực hiện bằng siêu máy tính Zenith tại Phòng thí nghiệm đổi mới AI và HPC của Dell EMC .
Thông tin hệ thống
| Mẫu CPU | CPU Intel® Xeon® Gold 6148 @ 2,40GHz |
| Hệ điều hành | Red Hat Enterprise Linux Server phát hành 7.4 (Maipo) |
| Phiên bản Tensorflow | Anaconda TensorFlow 1.12.0 với Intel® MKL |
| Phiên bản Horovod | 0,15,2 |
| MPI | MVAPICH2 2.1 |
Hiệu suất mở rộng mạnh mẽ đáng kinh ngạc giúp giảm đáng kể thời gian giải quyết mô hình. Để hình dung rõ nhất điều này, hãy xem xét hình 2. Thời gian giải quyết giảm từ khoảng 1 tháng trên một nút xuống chỉ còn hơn 6 giờ khi sử dụng 200 nút. Giải pháp nhanh hơn 121 lần này sẽ giúp tăng đáng kể năng suất của các nhà nghiên cứu NMT sử dụng cơ sở hạ tầng HPC dựa trên CPU. Các kết quả được quan sát dựa trên các mô hình đạt được điểm BLEU cơ bản (phân biệt chữ hoa chữ thường) là 27,5.
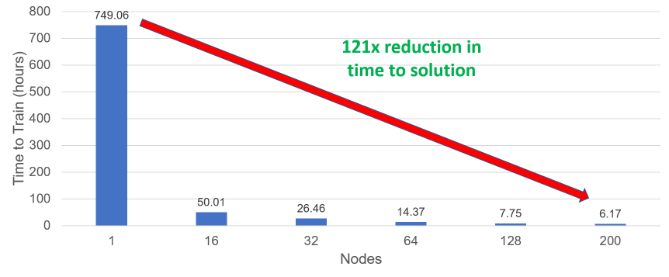
Hình 2: Thời gian huấn luyện mô hình để giải quyết
Đối với trường hợp một nút, chúng tôi đã sử dụng kích thước lô lớn nhất có thể vừa với bộ nhớ của nút, 25.600 mã thông báo cho mỗi công nhân. Đối với tất cả các trường hợp khác, chúng tôi sử dụng kích thước lô toàn cầu là 819.200, dẫn đến kích thước lô trên mỗi công nhân là 25.600 trong trường hợp 16 nút, giảm xuống chỉ còn 2.048 trong trường hợp 200 nút. Số lần lặp huấn luyện là tương tự đối với tất cả các thử nghiệm trong phạm vi 16-200 nút và được tăng lên theo hệ số 16 đối với trường hợp một nút (để bù cho lô lớn hơn).
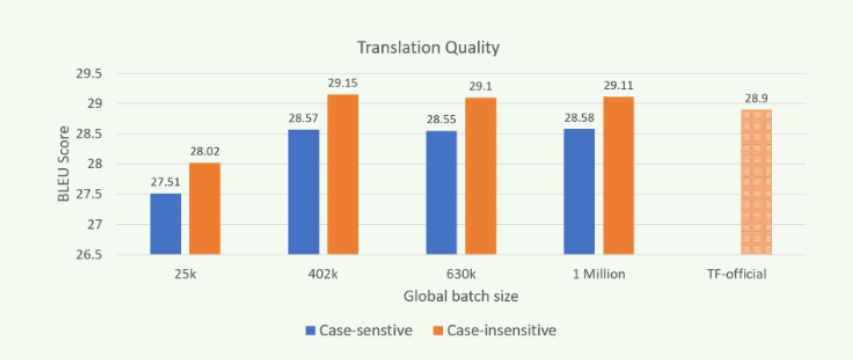
Hình 3: Chất lượng dịch thuật (BLEU) khi được đào tạo với các kích cỡ lô khác nhau trên Zenith.
Mở rộng quy mô đào tạo mô hình “máy biến áp” bằng MPI và Horovod sẽ cải thiện hiệu suất thông lượng trong khi tạo ra các mô hình có chất lượng dịch tương tự như trong Hình 3. Kết quả thu được bằng cách sử dụng newstest2014 làm bộ thử nghiệm. Các mô hình có chất lượng tương đương có thể được huấn luyện trong khoảng thời gian ngắn hơn bằng cách mở rộng tính toán trên nhiều nút hơn và với kích thước lô toàn cầu lớn hơn (GBZ). Các thử nghiệm của chúng tôi trên Zenith chứng minh khả năng đào tạo các mô hình có chất lượng dịch tương đương hoặc cao hơn (được đo bằng điểm BLEU) so với mô hình chính thức của TensorFlow được báo cáo, ngay cả khi đào tạo với hàng triệu mã thông báo trở lên.
Lưu ý: Kết quả hiển thị trong hình 3 có được bằng cách sử dụng các cài đặt được đề cập trong blog trước của chúng tôi và bằng cách sử dụng Open MPI.
Phần kết luận
Ở đây trong blog này, chúng tôi đã trình bày tổng quát về đào tạo hàng loạt lớn của mô hình NMT. Chúng tôi cũng cho thấy bộ xử lý có khả năng mở rộng Intel® Xeon® có khả năng mở rộng quy mô và giảm thời gian giải quyết hiệu quả như thế nào. Chúng tôi hy vọng điều này sẽ mang lại lợi ích cho năng suất của cộng đồng nghiên cứu NMT sử dụng cơ sở hạ tầng HPC dựa trên CPU.
Srinivas Varadharajan – Nhà phát triển Machine Learning/Deep Learning
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...