
Tin tức
Dịch máy thần kinh mở rộng quy mô – Những thách thức và giải pháp
Chất lượng dịch thuật của hệ thống dịch máy thần kinh (NMT) đã được cải thiện đáng kể trong những năm gần đây. Tuy nhiên, những mô hình này vẫn mất thời gian đáng kể để đào tạo và có rất ít công việc được tập trung vào việc cải thiện thời gian giải quyết chúng. Việc đào tạo phân tán trên nhiều nút điện toán có thể cải thiện thời gian đào tạo nhưng có nhiều thách thức khác nhau liên quan đến việc đào tạo mở rộng quy mô hệ thống NMT.
Trong blog này, chúng tôi nêu bật các giải pháp được phát triển tại Dell EMC nhằm giải quyết một số vấn đề phổ biến gặp phải khi mở rộng kiến trúc NMT như mô hình Transformer trong TensorFlow, nêu bật các lợi ích về hiệu suất liên quan đến các giải pháp này. Tất cả các thử nghiệm và kết quả thu được đều sử dụng Zenith, siêu máy tính dựa trên bộ xử lý Intel® Xeon® có thể mở rộng của DellEMC, được đặt trong Phòng thí nghiệm đổi mới Dell EMC HPC & AI ở Austin, Texas.
Suy giảm hiệu suất và lỗi OOM
Một trong những rào cản chính đối với việc mở rộng quy mô mô hình NMT là bộ nhớ cần thiết để tích lũy độ dốc. Khi đào tạo mạng nơ-ron, độ dốc là vectơ – hoặc mảng định hướng – gồm các số gần tương ứng với sự khác biệt giữa trọng số mạng hiện tại và tập hợp trọng số cung cấp giải pháp tốt hơn. Về cơ bản, độ dốc hướng từng giá trị trọng số theo một hướng khác nhau và hy vọng rằng hướng tốt hơn sẽ dẫn đến các giải pháp tốt hơn. Trong khi các mạng thần kinh tích chập để phân loại hình ảnh sử dụng các vectơ gradient dày đặc có thể dễ dàng làm việc, thì thiết kế của mô hình máy biến áp sử dụng lớp nhúng không nhất thiết phải mở rộng tốt cho nhiều máy chủ.
Thiết kế này gây ra sự suy giảm hiệu suất nghiêm trọng và lỗi hết bộ nhớ (OOM) do TensorFlow không tích lũy độ dốc của lớp nhúng một cách chính xác. Độ dốc từ lớp nhúng thưa thớt, trong khi độ dốc từ ma trận chiếu dày đặc. TensorFlow sau đó tích lũy cả hai tensor này thành các đối tượng thưa thớt. Điều này có tác động đáng kể đến chiến lược tích lũy độ dốc của TensorFlow và sau đó đến tổng kích thước của tenxơ độ dốc tích lũy. Điều này dẫn đến bộ đệm thông báo lớn có quy mô tuyến tính theo số lượng quy trình, do đó gây ra lỗi phân đoạn hoặc lỗi hết bộ nhớ.
Các tensor giả định thưa thớt giúp Horovod (khung đào tạo phân tán được sử dụng với TensorFlow) thực hiện tích lũy độ dốc bằng MPI_Gather thay vì MPI_Reduce. Để khắc phục sự cố này, chúng ta có thể chuyển đổi tất cả các tensor thưa thớt giả định thành tensor dày đặc. Điều này được thực hiện bằng cách thêm cờ “sparse_as_dense=True” trong phương thức DistributedOptimizer của Horovod.
opt = hvd.DistributedOptimizer(opt, spzzy_as_dense=True)
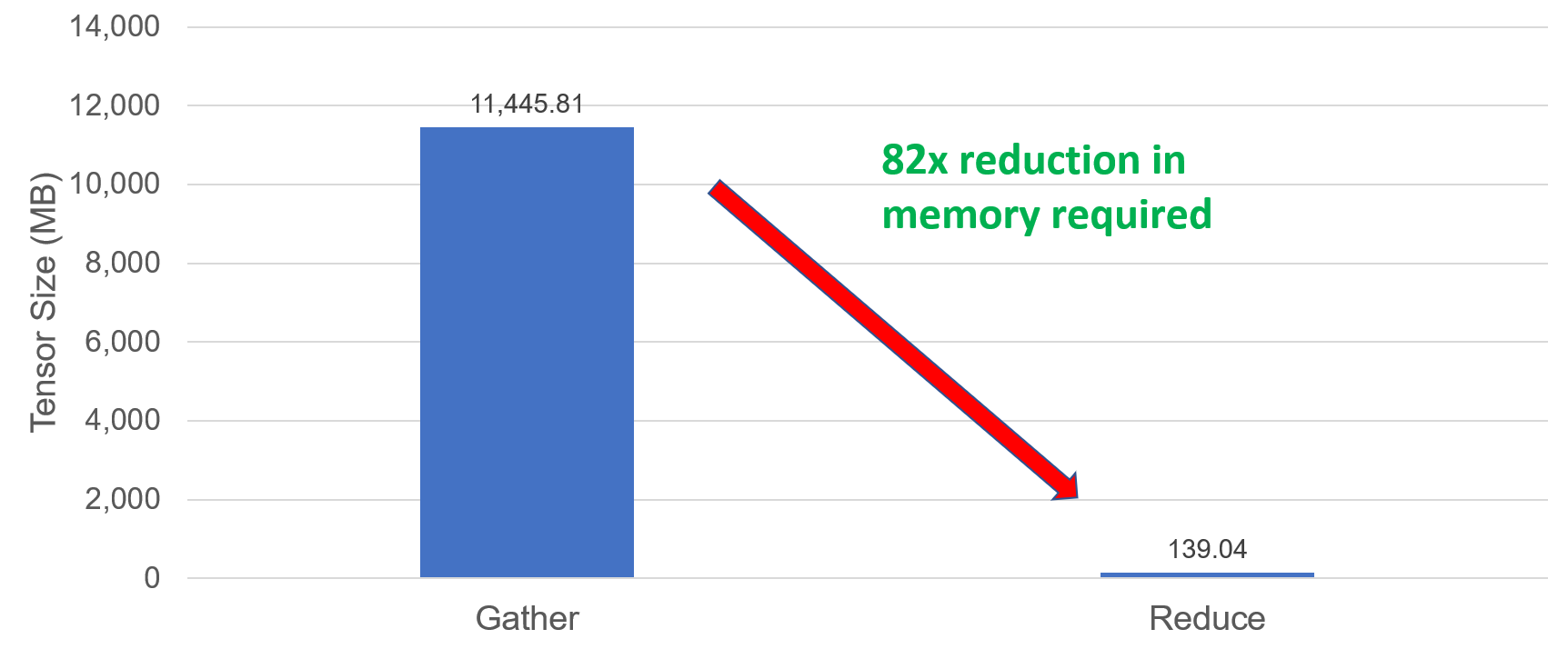
Hình 1: Kích thước tích lũy
Hình 1 hiển thị kích thước tích lũy khi sử dụng 64 nút (1ppn, batch_size=5000 mã thông báo). Kích thước tích lũy giảm 82 lần khi các tensor thưa thớt giả định được chuyển thành dày đặc. Giải pháp này cho phép mở rộng quy mô và huấn luyện mô hình bằng cách sử dụng 100 nút.
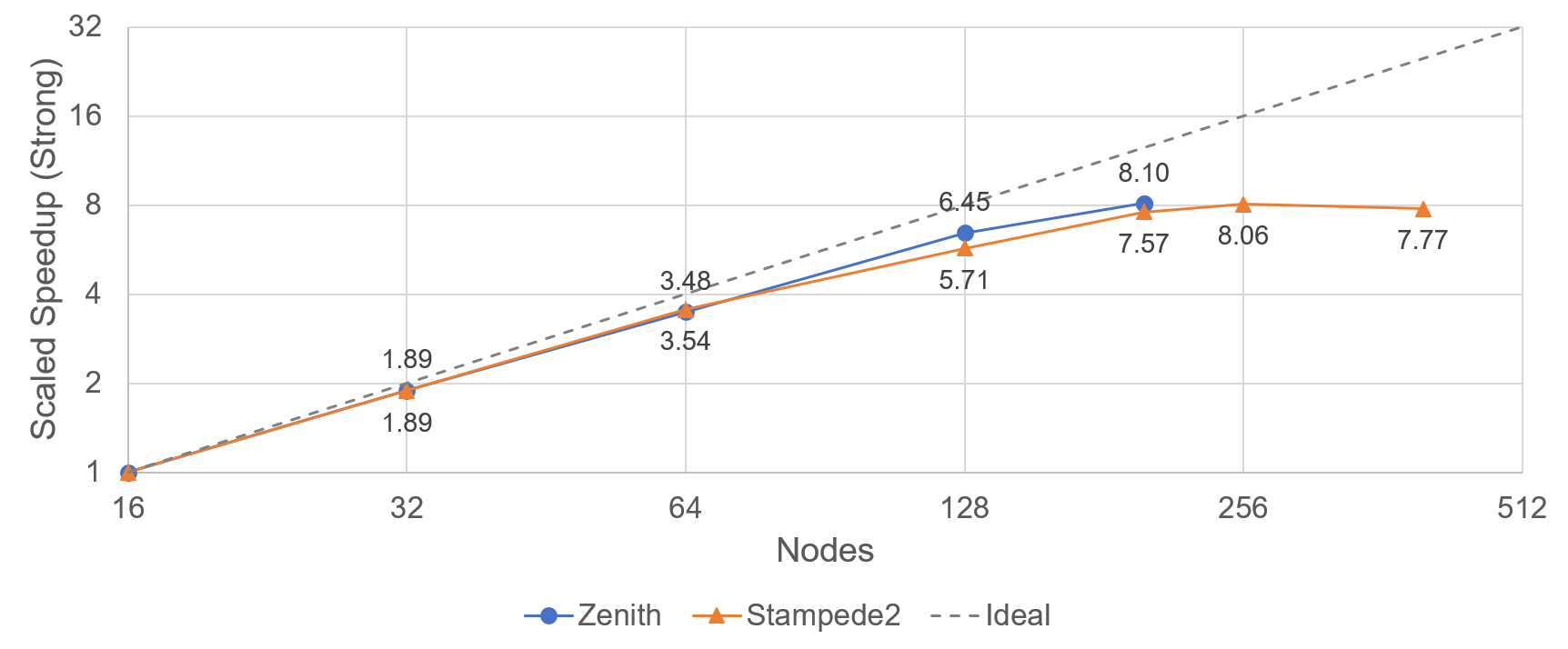
Hình 2: Hiệu suất tăng tốc (mạnh) theo tỷ lệ.
Ngoài lợi ích về hiệu suất chia tỷ lệ yếu được trình bày trong blog trước của chúng tôi , kích thước độ dốc giảm cũng cung cấp một cách để thực hiện chia tỷ lệ mạnh hiệu quả. Hình 2 cho thấy khả năng tăng tốc mở rộng mạnh mẽ được thực hiện trên siêu máy tính zenith và stampede2 sử dụng tối đa 200 nút trên Zenith (Dell EMC) và 256 nút trên Stampede2 (TACC). Khả năng mở rộng quy mô mạnh mẽ hiệu quả giúp giảm đáng kể thời gian đào tạo mô hình
Đào tạo đa dạng
Mặc dù việc xây dựng mô hình một cách nhanh chóng là quan trọng nhưng điều quan trọng là phải đảm bảo rằng mô hình thu được cũng chính xác. Đào tạo phân kỳ, trong đó mô hình được tạo ra trở nên kém chính xác hơn (thay vì chính xác hơn) khi đào tạo liên tục là một vấn đề phổ biến không chỉ đối với đào tạo hàng loạt lớn mà nói chung đối với bất kỳ hệ thống NMT nào. Việc theo dõi biểu đồ tổn thất sẽ giúp hiểu được sự hội tụ của mô hình học sâu. Việc đặt tốc độ học thành giá trị tối ưu là rất quan trọng cho sự hội tụ của mô hình.
Các biện pháp có thể được thực hiện để ngăn chặn việc đào tạo lệch lạc. Các thí nghiệm cho thấy rằng việc có tỷ lệ học tập rất cao khi bắt đầu đào tạo sẽ gây ra sự phân kỳ trong đào tạo. Nhưng mặt khác, việc thiết lập tốc độ học quá thấp cũng sẽ khiến mô hình hội tụ chậm. Do đó, việc tìm ra tốc độ học lý tưởng cho mô hình là rất quan trọng.
Một giải pháp là giảm tốc độ học (hạ nhiệt hoặc giảm dần) hoặc tăng tốc độ học (khởi động), hoặc thường là kết hợp cả hai. Bằng cách cho phép tốc độ học tăng tuyến tính đến giá trị đã đặt cho một số bước nhất định sau đó nó phân rã dựa trên hàm đã chọn, mô hình kết quả có thể chính xác hơn và được tạo ra nhanh hơn. Đối với mô hình máy biến áp, độ suy giảm tỷ lệ thuận với căn bậc hai nghịch đảo của số bước.
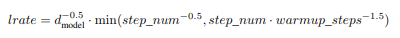
Hình 3: Phân rã tốc độ học được sử dụng trong mô hình Transformer
Dựa trên các thử nghiệm của chúng tôi, chúng tôi nhận thấy rằng đối với các kích thước lô lớn (mã thông báo 130k, 402k, 630k, 1 triệu), việc đặt tốc độ học thành 0,001 – 0,005 sẽ ngăn chặn việc đào tạo phân kỳ của mô hình lớn.
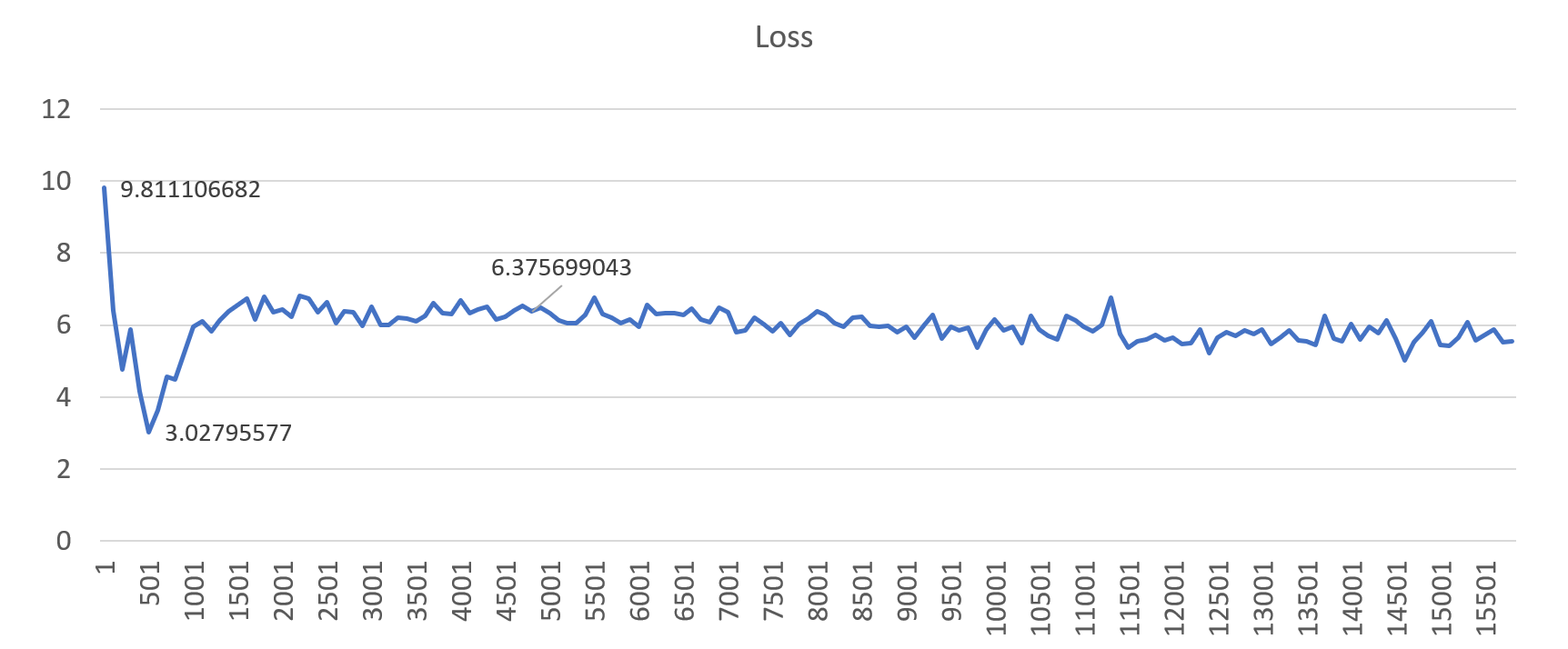
Hình 4: Một ví dụ về hồ sơ tổn thất thể hiện quá trình huấn luyện phân kỳ (gbz=130k, lr=0,01)
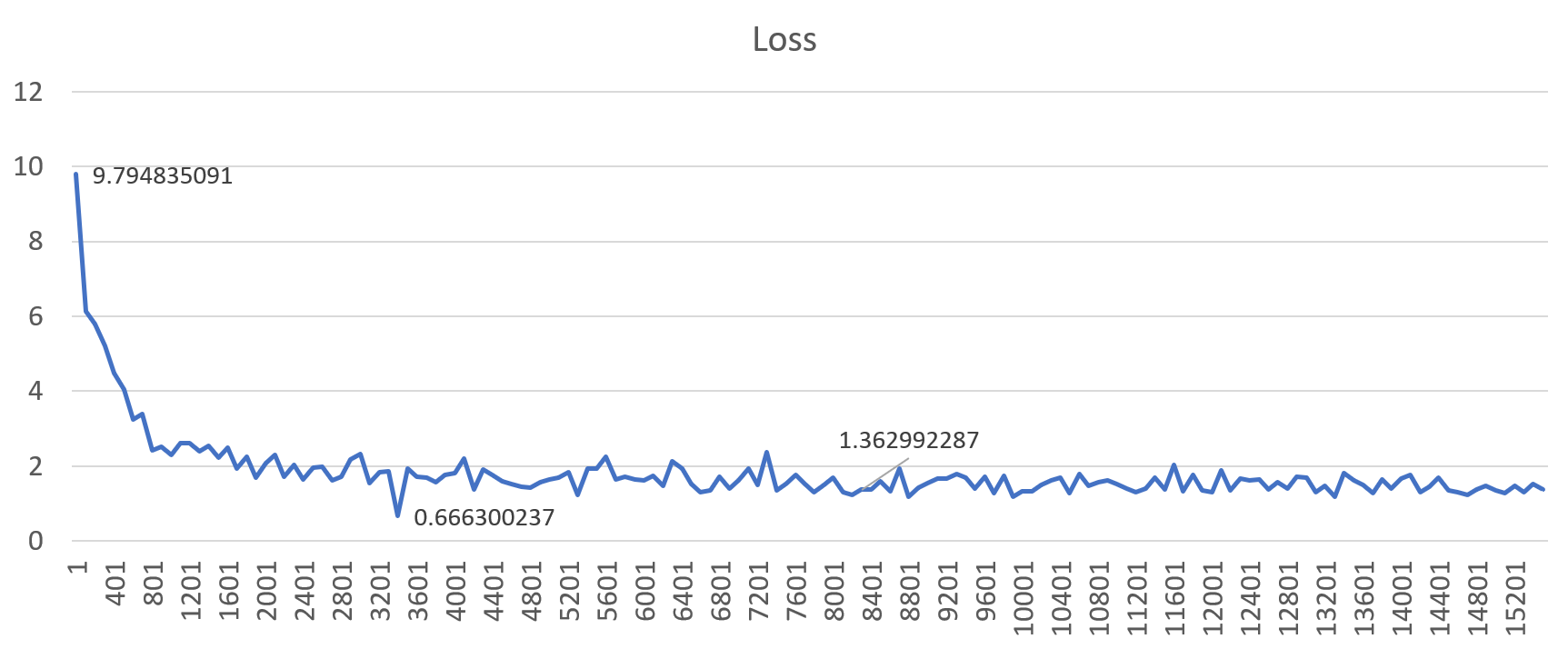
Hình 5: Một ví dụ về hồ sơ mất mát thể hiện hành vi huấn luyện đúng (gbz=130k, lr=0,001)
Hình 4 và 5 hiển thị cấu hình tổn thất khi được đào tạo với quy mô lô toàn cầu là 130k. Đặt tốc độ học thành giá trị “cao” (0,01) dẫn đến đào tạo phân kỳ, nhưng khi đặt thành 1e-3 (0,001), mô hình sẽ hội tụ tốt hơn. Điều này dẫn đến chất lượng dịch tốt trên mô hình cuối cùng. Kết quả tương tự cũng được quan sát thấy ở tất cả các lô cỡ lớn khác.
Phần kết luận
Trong blog này, chúng tôi đã nêu bật một số thách thức phổ biến khi thực hiện đào tạo phân tán mô hình máy biến áp cho dịch máy thần kinh (NMT). Các giải pháp do Dell EMC phối hợp với Uber, Amazon, Intel và SURFsara phát triển đã giúp cải thiện đáng kể khả năng mở rộng quy mô và độ chính xác của mô hình. Các kết quả hiện đã được bổ sung vào một phần bài nghiên cứu của chúng tôi được chấp nhận tại hội nghị Hiệu suất cao ISC 2019. Bài viết cung cấp thêm thông tin chi tiết về những sửa đổi đối với Horovod và những cải tiến về mặt sử dụng bộ nhớ, hiệu quả mở rộng quy mô, giảm thời gian đào tạo và chất lượng dịch thuật. Công việc đã được tích hợp vào Horovod để cộng đồng nghiên cứu có thể khám phá tiềm năng mở rộng hơn nữa và tạo ra các mô hình NMT hiệu quả hơn.
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...