
Tin tức
Chia sẻ tình yêu dành cho GPU trong Machine Learning

Bất kỳ ai làm việc với các mô hình học máy được đào tạo bằng các phương pháp tối ưu hóa như giảm độ dốc ngẫu nhiên (SGD) đều biết về sức mạnh của các bộ tăng tốc phần cứng chuyên dụng trong việc thực hiện một số lượng lớn các phép toán ma trận cần thiết. Sẽ thật tuyệt nếu tất cả chúng ta đều có siêu máy tính dày đặc máy gia tốc của riêng mình? Thật không may, những người quản lý ngân sách không phê duyệt kế hoạch đó, vì vậy chúng tôi cần tìm ra sự kết hợp khả thi giữa công nghệ và, vâng, khái niệm đáng sợ, quy trình để cải thiện khả năng làm việc với các bộ tăng tốc phần cứng trong môi trường dùng chung.
Chúng tôi đã nhận được rất nhiều câu hỏi từ một khách hàng đang cố gắng tăng tỷ lệ sử dụng máy bằng máy gia tốc chuyên dụng. Tin tốt là có rất nhiều công ty công nghệ lớn đang nghiên cứu các giải pháp. Phần còn lại của bài viết sẽ tập trung vào công nghệ của Dell EMC, NVIDIA và VMware hiện có và một số công nghệ sắp ra mắt. Chúng tôi cũng đưa ra một số nhận xét về quy trình mà bạn có thể xem xét. Vui lòng thêm suy nghĩ và câu hỏi của bạn trong phần bình luận bên dưới.
Chúng tôi đã bắt đầu vòng nghiên cứu GPU dưới dạng dịch vụ mới nhất này với một lượng nhỏ bộ công cụ tại Trung tâm Giải pháp Khách hàng Dell EMC ở Austin. Chúng tôi có một Dell EMC PowerEdge R740 với 4 GPU NVIDIA T4 được kết nối với hệ thống trên bus PCIe. Câu hỏi nghiên cứu của chúng tôi là “làm cách nào một nhóm các nhà khoa học dữ liệu làm việc trên các mô hình khác nhau với các công cụ phát triển khác nhau có thể chia sẻ bốn GPU này?” Chúng ta sẽ so sánh hai lựa chọn công nghệ khác nhau:
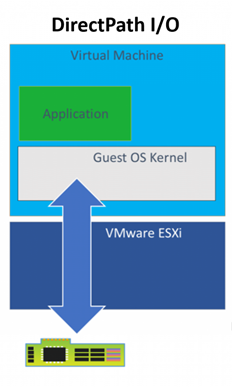
- Đường dẫn I/O trực tiếp của VMware
- GPU NVIDIA LƯỚI 9.0
Máy chủ của chúng tôi đã cài đặt ESXi và được định cấu hình là cụm 1 nút trong vCenter. Tôi sẽ bỏ qua phần cấu hình BIOS máy chủ và ESXi và chuyển thẳng sang phần tạo VM. Chúng tôi bắt đầu với tùy chọn I/O Đường dẫn Trực tiếp. Bạn nên xem lại bài viết “ Sử dụng GPU với Máy ảo trên vSphere – Phần 2: VMDirectPath I/O ” của VMware trước khi thử tại nhà. Nó có rất nhiều chi tiết mà chúng tôi sẽ không nhắc lại ở đây.
Có nhiều phương pháp tiếp cận sẵn có để quản lý hình ảnh máy ảo mà quản trị viên VMware có thể thiết lập nhưng đối với dự án này, chúng tôi giả định rằng các nhà khoa học dữ liệu của chúng tôi đang xây dựng và duy trì các hình ảnh mà họ sử dụng. Kịch bản của chúng tôi là cho thấy cách một nhóm người dùng Python có thể có một hình ảnh và người dùng R có thể có một hình ảnh khác mà cả hai đều sử dụng GPU khi cần. Cả hai nhóm đều sử dụng chủ yếu TensorFlow và Keras.
Trước khi cài đặt HĐH, chúng tôi đã thay đổi cài đặt chương trình cơ sở thành EFI trong menu Tùy chọn khởi động VM theo bài viết trên. Chúng tôi cũng đã sử dụng các tùy chọn VM để gán một GPU vật lý cho VM bằng cách sử dụng I/O Đường dẫn Trực tiếp trước khi tiến hành bất kỳ cài đặt phần mềm nào. Điều quan trọng là phải có một thiết bị trong quá trình định cấu hình mặc dù sau này VM có thể được sử dụng dù có hoặc không có GPU được chỉ định để tạo điều kiện chia sẻ giữa những người dùng và/hoặc nhóm.
Sau khi hệ điều hành được cài đặt và định cấu hình với các tài khoản người dùng và bản cập nhật, chúng tôi đã cài đặt phần mềm liên quan đến GPU NVIDIA và tạo hai bản sao của hình ảnh đó vì cả thiết lập môi trường R và Python đều cần cùng các thư viện và trình điều khiển hỗ trợ để sử dụng GPU khi được thêm vào VM thông qua I/O đường dẫn trực tiếp. Việc có hình ảnh cơ sở với hệ điều hành cộng với thư viện NVIDIA sẽ tiết kiệm rất nhiều thời gian nếu bạn muốn có một loại môi trường nhà phát triển mới.
Với phần lớn quá trình thiết lập đã hoàn tất, chúng tôi có thể bắt đầu thử nghiệm việc gán và xóa các thiết bị GPU giữa hai máy ảo của mình. Chúng tôi sử dụng các tùy chọn VM để thêm và xóa thiết bị nhưng chỉ khi VM tắt nguồn. Ví dụ: chúng tôi có thể chỉ định 2 GPU cho mỗi VM, 4 GPU cho một VM và không có GPU nào cho VM kia hoặc bất kỳ sự kết hợp nào khác không vượt quá 4 thiết bị có sẵn của chúng tôi. Các thiết bị hiện được gán cho các máy ảo khác không có sẵn trong giao diện người dùng để gán, do đó về mặt vật lý không thể tạo xung đột giữa các máy ảo. Chúng tôi có thể sử dụng Giao diện quản lý hệ thống của NVIDIA (nvidia-smi) để liệt kê các thiết bị có sẵn trên mỗi VM.
Hãy nhớ ở trên khi chúng ta nói về quy trình, đây là lúc chúng ta cần xem lại điều đó. Cách duy nhất để thiết lập như thế này hoạt động là nếu mọi người giải phóng GPU khỏi máy ảo khi họ không cần chúng. Đi sâu hơn, có thể sẽ đến lúc một người dùng hoặc nhóm có thể tận dụng GPU nhưng sẽ chọn không sử dụng GPU để công việc khác có khả năng quan trọng hơn có thể có được nó. Kiểu chia sẻ tài nguyên này không phải là mới đối với hoạt động nghiên cứu và phát triển. Tất cả các nguồn lực hữu ích đều khan hiếm và có thể đạt được rất nhiều hiệu quả nếu có công nghệ, quy trình và thái độ phù hợp.
.Trước khi nói về việc cài đặt các khung và thư viện dành cho nhà phát triển, hãy xem lại kết quả mà chúng ta mong muốn. Chúng tôi có 2 nhóm nhà phát triển trở lên có thể hưởng lợi từ việc sử dụng GPU vào các thời điểm khác nhau trong quy trình làm việc của họ nhưng không phải lúc nào cũng vậy. Họ muốn giảm thiểu số lượng hình ảnh VM mà họ cần và có, đồng thời muốn duy trì ít phiên bản mã hơn ngay cả khi chuyển đổi giữa các tác vụ có thể có hoặc không có quyền truy cập vào GPU khi chạy. Ở trên chúng ta đã nói về việc chuyển đổi GPU giữa các máy nhưng điều gì xảy ra về mặt phần mềm? Tiếp theo, chúng ta sẽ nói về một số thuộc tính TensorFlow giúp việc này trở nên dễ dàng hơn.
TensorFlow có hai loại chính để cài đặt tensorflow và tensorflow-gpu. Cái đầu tiên có lẽ nên được gọi là “tensorflow-cpu” cho rõ ràng. Đối với công việc này, chúng tôi chỉ cài đặt phiên bản hỗ trợ GPU vì chúng tôi muốn máy ảo của mình có thể sử dụng GPU cho mọi hoạt động mà TF hỗ trợ cho các thiết bị GPU. Lý do mà tôi cũng không cần phiên bản CPU khi VM của tôi chưa được gán bất kỳ GPU nào là vì nhiều hoạt động có sẵn trong phiên bản TF hỗ trợ GPU có cả CPU và GPU được cấy ghép. Khi một thao tác được chạy mà không có sự chỉ định thiết bị cụ thể, mọi thiết bị GPU có sẵn sẽ được ưu tiên ở vị trí đó. Khi VM không có sẵn thiết bị GPU, hoạt động sẽ sử dụng việc triển khai CPU.
Có rất nhiều ví dụ trực tuyến để kiểm tra xem bạn có hệ thống được cấu hình đúng cách với thiết bị GPU hoạt động hay không. Mẫu nhân ma trận đơn giản này là một điểm khởi đầu tốt. Sau khi phương pháp này hoạt động, bạn có thể chuyển sang đào tạo mô hình toàn diện với tập dữ liệu mẫu như mô hình nhận dạng ký tự MNIST . Hãy thử thiết lập môi trường sandbox bằng bài viết này và loạt blog VMware ở trên. Sau đó, hãy tích lũy một số kinh nghiệm về việc phân bổ và phân bổ GPU cho máy ảo và chứng minh rằng mọi thứ đang hoạt động với một ứng dụng nhỏ. Nếu bạn có bất kỳ câu hỏi hoặc nhận xét nào, hãy gửi chúng trong phần phản hồi bên dưới.
Cảm ơn vì đã đọc.
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...