
Tin tức
Tăng tốc thông tin chi tiết với Deep Learning phân tán
Trí tuệ nhân tạo (AI) đang thay đổi cách các doanh nghiệp cạnh tranh trên thị trường ngày nay. Cho dù đó là cải thiện trí tuệ kinh doanh, hợp lý hóa chuỗi cung ứng hay hiệu quả hoạt động hay tạo ra sản phẩm, dịch vụ hoặc khả năng mới cho khách hàng, AI phải là một thành phần chiến lược trong quá trình chuyển đổi kỹ thuật số của bất kỳ công ty nào.
Mạng lưới thần kinh sâu đã chứng tỏ khả năng đáng kinh ngạc trong việc xác định đối tượng, phát hiện hành vi gian lận, dự đoán xu hướng, giới thiệu sản phẩm, cho phép nâng cao hỗ trợ khách hàng thông qua chatbot, chuyển đổi giọng nói thành văn bản và dịch ngôn ngữ này sang ngôn ngữ khác và tạo ra vô số lợi ích khác cho các công ty và Các nhà nghiên cứu. Họ có thể phân loại và tóm tắt hình ảnh, văn bản và bản ghi âm bằng khả năng của con người, nhưng để làm được điều đó trước tiên họ cần phải được đào tạo.
Học sâu, quá trình đào tạo mạng lưới thần kinh, đôi khi có thể mất vài ngày, vài tuần hoặc vài tháng và cần có nỗ lực cũng như chuyên môn để tạo ra một mạng lưới thần kinh có đủ chất lượng để tin tưởng vào các quyết định kinh doanh hoặc nghiên cứu của bạn dựa trên các đề xuất của nó. Hầu hết các hệ thống sản xuất thành công đều trải qua nhiều lần huấn luyện, điều chỉnh và thử nghiệm trong quá trình phát triển. Học sâu phân tán có thể tăng tốc quá trình này, giảm tổng thời gian điều chỉnh và kiểm tra để nhóm khoa học dữ liệu của bạn có thể phát triển mô hình phù hợp nhanh hơn, nhưng yêu cầu một phương pháp cho phép tổng hợp kiến thức giữa các hệ thống.
Có một số phương pháp đang phát triển để triển khai hiệu quả việc học sâu phân tán và cách bạn phân phối việc đào tạo mạng lưới thần kinh phụ thuộc vào môi trường công nghệ của bạn. Cho dù môi trường điện toán của bạn là môi trường chứa gốc, điện toán hiệu năng cao (HPC) hay cụm Hadoop/Spark để phân tích Dữ liệu lớn, thì thời gian tìm hiểu sâu sắc của bạn đều có thể được tăng tốc bằng cách sử dụng học sâu phân tán. Trong bài viết này, chúng tôi sẽ giải thích và so sánh các hệ thống sử dụng cách tiếp cận máy chủ tham số tập trung hoặc nhân rộng, cách tiếp cận ngang hàng và cuối cùng là sự kết hợp của cả hai phương pháp này được phát triển riêng cho môi trường dữ liệu lớn phân tán của Hadoop.
Học sâu phân tán trong môi trường gốc vùng chứa
Bộ chứa gốc (ví dụ: Kubernetes, Docker Swarm, OpenShift, v.v.) đã trở thành tiêu chuẩn cho nhiều môi trường DevOps, trong đó các bản cập nhật phần mềm trong quá trình sản xuất nhanh chóng là tiêu chuẩn và các đợt tính toán có thể được chuyển sang đám mây công cộng. Hầu hết các khung học sâu đều hỗ trợ học sâu phân tán cho các loại môi trường này bằng cách sử dụng mô hình dựa trên máy chủ tham số cho phép nhiều quy trình xem xét dữ liệu đào tạo cùng một lúc, đồng thời tổng hợp kiến thức vào một mô hình trung tâm duy nhất.
Quá trình thực hiện đào tạo dựa trên máy chủ tham số bắt đầu bằng việc chỉ định số lượng nhân viên (quy trình sẽ xem xét dữ liệu đào tạo) và máy chủ tham số (quy trình sẽ xử lý việc tổng hợp thông tin giảm lỗi, truyền ngược các điều chỉnh đó và cập nhật nhân viên). Các máy chủ tham số bổ sung có thể hoạt động như bản sao để cải thiện cân bằng tải.
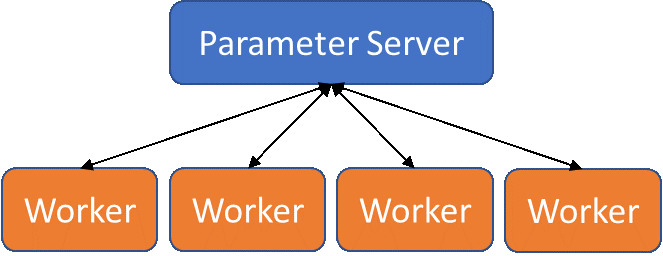 Mô hình máy chủ tham số cho deep learning phân tán
Mô hình máy chủ tham số cho deep learning phân tán
Các quy trình của công nhân được cung cấp một lô dữ liệu đào tạo nhỏ để kiểm tra và đánh giá, sau khi hoàn thành lô nhỏ đó, hãy báo cáo lại sự khác biệt (độ dốc) giữa đầu ra được sản xuất và đầu ra dự kiến cho (các) máy chủ tham số. Sau đó, (các) máy chủ tham số sẽ xử lý việc đào tạo mạng và truyền các bản sao của mô hình đã cập nhật lại cho công nhân để sử dụng trong vòng tiếp theo.
Mô hình này lý tưởng cho môi trường gốc vùng chứa, nơi các quy trình máy chủ tham số và quy trình công nhân có thể được tách biệt một cách tự nhiên. Các hệ thống điều phối, chẳng hạn như Kubernetes, cho phép đào tạo các mô hình mạng thần kinh trong môi trường gốc chứa nhiều tài nguyên phần cứng để cải thiện thời gian đào tạo. Ngoài ra, nhiều khung học sâu hỗ trợ đào tạo phân tán dựa trên tham số trên máy chủ, chẳng hạn như TensorFlow, PyTorch, Caffe2 và Bộ công cụ nhận thức.
Học sâu phân tán trong môi trường HPC
Môi trường điện toán hiệu năng cao (HPC) thường được xây dựng để hỗ trợ thực thi các ứng dụng nhiều nút được phát triển và thực thi bằng phương pháp quy trình đơn, nhiều dữ liệu (SPMD), trong đó việc trao đổi dữ liệu được thực hiện trên các mạng băng thông cao, độ trễ thấp , chẳng hạn như Mellanox InfiniBand và Intel OPA. Các mã đa nút này tận dụng lợi thế của các mạng này thông qua Giao diện truyền tin nhắn (MPI), giao diện này tóm tắt thông tin liên lạc thành các cấu trúc gửi/nhận và tập thể.
Học sâu có thể được phân phối với MPI bằng cách sử dụng mẫu giao tiếp có tên Ring-AllReduce. Trong Ring-AllReduce, mỗi quy trình đều giống hệt nhau, không giống như trong mô hình máy chủ tham số trong đó các quy trình là máy chủ hoặc máy chủ. Gói Horovod của Uber (có sẵn cho TensorFlow, Keras và PyTorch) và các đóng góp mpi_collectives từ Baidu (có sẵn trong TensorFlow) sử dụng MPI Ring-AllReduce để trao đổi thông tin mất mát và độ dốc giữa các bản sao của mạng lưới thần kinh đang được đào tạo. Cách tiếp cận dựa trên ngang hàng này có nghĩa là tất cả các nút trong giải pháp đang hoạt động để huấn luyện mạng, thay vì một số nút chỉ hoạt động như bộ tổng hợp/nhà phân phối (như trong mô hình máy chủ tham số). Điều này có khả năng dẫn đến sự hội tụ mô hình nhanh hơn.
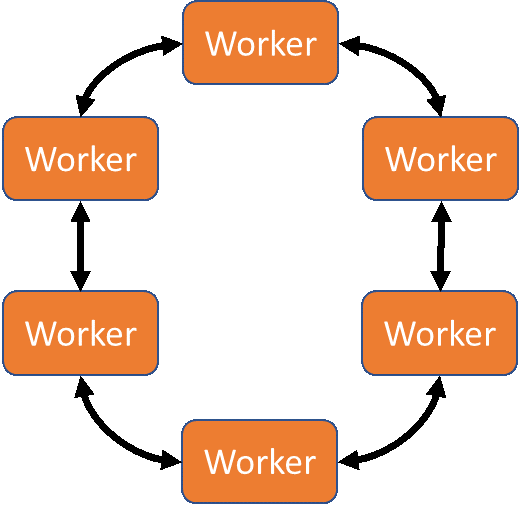 Mô hình Ring-AllReduce cho học sâu phân tán
Mô hình Ring-AllReduce cho học sâu phân tán
Giải pháp sẵn sàng của Dell EMC dành cho AI, Deep Learning với NVIDIA cho phép người dùng tận dụng mạng Mellanox InfiniBand EDR băng thông cao, bộ lưu trữ Dell EMC Isilon nhanh , tính toán tăng tốc với GPU NVIDIA V100 và TensorFlow, Keras hoặc Pytorch được tối ưu hóa với khung Horovod để giúp tạo ra những hiểu biết nhanh hơn.
Học sâu phân tán trong môi trường Hadoop/Spark
Hadoop và các nền tảng Dữ liệu lớn khác đạt được hiệu suất cực cao cho xử lý phân tán nhưng không được thiết kế để hỗ trợ các ứng dụng có trạng thái, chạy lâu dài. Có một số cách tiếp cận để thực hiện đào tạo phân tán trong Apache Spark. Yahoo đã phát triển TensorFlowOnSpark , hoàn thành mục tiêu bằng kiến trúc tận dụng Spark để lên lịch các hoạt động của Tensorflow và RDMA để liên lạc tensor trực tiếp giữa các máy chủ.
BigDL là thư viện deep learning phân tán dành cho Apache Spark. Không giống như TensorflowOnSpark của Yahoo, BigDL không chỉ cho phép đào tạo phân tán – nó được thiết kế ngay từ đầu để hoạt động trên các hệ thống Dữ liệu lớn. Để cho phép đào tạo phân tán hiệu quả, BigDL sử dụng phương pháp đào tạo song song dữ liệu với SGD lô nhỏ đồng bộ (Stochastic gradient Descent). Dữ liệu đào tạo được phân chia thành các mẫu RDD và phân phối cho từng công nhân. Việc đào tạo mô hình được thực hiện theo một quy trình lặp, trước tiên tính toán độ dốc cục bộ trên mỗi nhân viên bằng cách tận dụng các phân vùng được lưu trữ cục bộ của dữ liệu huấn luyện và mô hình để thực hiện chuyển đổi bộ nhớ. Sau đó, hàm AllReduce sẽ lên lịch cho công nhân các nhiệm vụ tính toán và cập nhật trọng số. Cuối cùng, một chương trình phát sóng sẽ đồng bộ hóa các bản sao được phân phối của mô hình với trọng số được cập nhật.
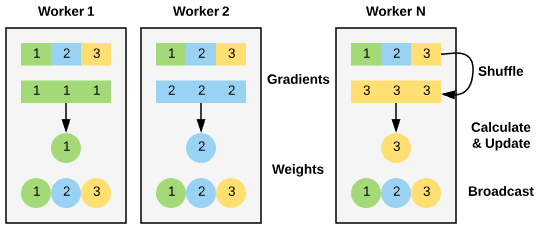 Triển khai BigDL chức năng AllReduce
Triển khai BigDL chức năng AllReduce
Giải pháp sẵn sàng của Dell EMC dành cho AI, Machine Learning với Hadoop được cấu hình để cho phép người dùng tận dụng sức mạnh của deep learning phân tán với Intel BigDL và Apache Spark. Nó hỗ trợ tải các mô hình và trọng số từ các khung khác như Tensorflow, Caffe và Torch để sau đó được tận dụng cho mục đích đào tạo hoặc hội thảo. BigDL là một cách tuyệt vời để người dùng nhanh chóng bắt đầu đào tạo mạng lưới thần kinh bằng cách sử dụng Apache Spark, được công nhận rộng rãi về mức độ đơn giản của việc xử lý dữ liệu.
Thêm một lưu ý nữa về môi trường Hadoop và Spark: Nhóm Intel làm việc trên BigDL đã xây dựng và biên soạn các API quy trình cấp cao, các mô hình học sâu tích hợp và các trường hợp sử dụng tham chiếu vào thư viện Intel Analytics Zoo . Analytics Zoo dựa trên BigDL nhưng giúp sử dụng dễ dàng hơn nữa thông qua các API quy trình cấp cao này được thiết kế để hoạt động với Spark Dataframes và được tích hợp sẵn các mô hình cho những việc như phát hiện đối tượng và phân loại hình ảnh.
Phần kết luận
Bất kể cơ sở hạ tầng máy chủ ưa thích của bạn là vùng chứa gốc, cụm HPC hay hồ dữ liệu hỗ trợ Hadoop/Spark, học sâu phân tán có thể giúp nhóm khoa học dữ liệu của bạn phát triển các mô hình mạng thần kinh nhanh hơn. Giải pháp sẵn sàng cho Trí tuệ nhân tạo Dell EMC của chúng tôi có thể hoạt động trong bất kỳ môi trường nào trong số này để giúp khởi động hành trình AI cho doanh nghiệp của bạn. Để biết thêm thông tin về Giải pháp sẵn sàng của Dell EMC cho trí tuệ nhân tạo, hãy truy cập delemc.com/readyforai .
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...