
Quá trình huấn luyện mạng lưới thần kinh sâu giống như việc tìm giá trị tối thiểu của một hàm trong một không gian có nhiều chiều. Mạng lưới thần kinh sâu thường được huấn luyện bằng cách sử dụng phương pháp giảm độ dốc ngẫu nhiên (hoặc một trong các biến thể của nó). Một lô nhỏ (thường là 16-512), được lấy mẫu ngẫu nhiên từ tập huấn luyện, được sử dụng để tính gần đúng độ dốc của hàm mất mát (mục tiêu tối ưu hóa) đối với các trọng số. Độ dốc được tính toán về cơ bản là giá trị trung bình của các độ dốc cho từng điểm dữ liệu trong lô. Cách tự nhiên để song song việc đào tạo trên nhiều nút/công nhân là tăng kích thước lô và yêu cầu mỗi nút tính toán độ dốc trên một đoạn khác nhau của lô. Học sâu phân tán khác với khối lượng công việc HPC truyền thống khi việc mở rộng quy mô chỉ ảnh hưởng đến cách phân phối tính toán chứ không ảnh hưởng đến kết quả.
Những thách thức của đào tạo hàng loạt lớn
Người ta đã nhận thấy một cách nhất quán rằng việc sử dụng các lô lớn sẽ dẫn đến hiệu suất khái quát hóa kém, có nghĩa là các mô hình được đào tạo với các lô lớn sẽ hoạt động kém trên dữ liệu thử nghiệm. Một trong những lý do chính cho điều này là các lô lớn có xu hướng hội tụ về cực tiểu rõ ràng của hàm huấn luyện, có xu hướng khái quát hóa kém hơn. Các lô nhỏ có xu hướng thiên về giá trị cực tiểu phẳng dẫn đến khả năng khái quát hóa tốt hơn . Tính ngẫu nhiên được tạo ra bởi các lô nhỏ khuyến khích các trọng lượng thoát khỏi vùng hấp dẫn của cực tiểu sắc nét. Ngoài ra, các mô hình được huấn luyện với các đợt nhỏ được hiển thị để hội tụ xa điểm bắt đầu hơn. Các lô lớn có xu hướng bị thu hút ở mức tối thiểu gần điểm xuất phát nhất và thiếu các đặc tính thăm dò của các lô nhỏ.
Số lượng cập nhật gradient trên mỗi lượt truyền dữ liệu sẽ giảm khi sử dụng các lô lớn. Điều này đôi khi được bù đắp bằng cách tăng tỷ lệ học theo kích thước lô. Nhưng chỉ cần sử dụng tỷ lệ học cao hơn có thể làm mất ổn định quá trình đào tạo. Một cách tiếp cận khác là huấn luyện mô hình lâu hơn, nhưng điều này có thể dẫn đến tình trạng trang bị quá mức. Do đó, đào tạo phân tán có nhiều thứ hơn là chỉ mở rộng quy mô ra nhiều nút.
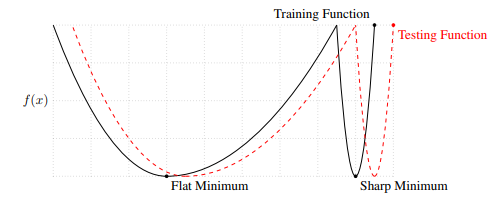 Một minh họa cho thấy mức độ tối thiểu rõ ràng dẫn đến khả năng khái quát hóa kém như thế nào. Mức tối thiểu rõ ràng của hàm huấn luyện tương ứng với mức tối đa của hàm kiểm tra, làm ảnh hưởng đến hiệu suất của mô hình trên dữ liệu thử nghiệm
Một minh họa cho thấy mức độ tối thiểu rõ ràng dẫn đến khả năng khái quát hóa kém như thế nào. Mức tối thiểu rõ ràng của hàm huấn luyện tương ứng với mức tối đa của hàm kiểm tra, làm ảnh hưởng đến hiệu suất của mô hình trên dữ liệu thử nghiệm
Làm thế nào chúng ta có thể thực hiện các lô lớn?
Gần đây đã có rất nhiều nghiên cứu thú vị trong việc làm cho việc đào tạo hàng loạt lớn trở nên khả thi hơn. Thời gian đào tạo cho ImageNet hiện đã giảm từ vài tuần xuống còn vài phút bằng cách sử dụng các lô lớn tới 32K mà không làm giảm độ chính xác. Các phương pháp sau đây được biết là có thể giảm bớt một số vấn đề được mô tả ở trên:
- Chia tỷ lệ tốc độ học
Tốc độ học được nhân với k , khi kích thước lô được nhân với k . Tuy nhiên, quy tắc này không được áp dụng trong vài giai đoạn đầu tiên của quá trình luyện tập vì trọng lượng đang thay đổi nhanh chóng. Điều này có thể được giảm bớt bằng cách sử dụng giai đoạn khởi động. Ý tưởng là bắt đầu với một giá trị nhỏ của tốc độ học và tăng dần lên giá trị được chia tỷ lệ tuyến tính. - Tỉ lệ tốc độ thích ứng theo lớp
Một tốc độ học khác nhau được sử dụng cho mỗi lớp. Tốc độ học tập toàn cầu được chọn và nó được chia tỷ lệ cho từng lớp theo tỷ lệ giữa định mức Euclide của trọng số và định mức Euclide của độ dốc cho lớp đó. - Sử dụng SGD thông thường với động lượng thay vì Adam
Adam được biết là giúp cho sự hội tụ nhanh hơn và ổn định hơn. Nó thường là lựa chọn tối ưu hóa mặc định khi đào tạo các mô hình sâu. Tuy nhiên, Adam dường như thích sử dụng mức tối thiểu kém tối ưu hơn, đặc biệt khi sử dụng lô lớn. Sử dụng SGD thông thường có động lượng, mặc dù ồn hơn Adam nhưng đã cho thấy tính khái quát được cải thiện. - Cấu trúc liên kết cũng tạo nên sự khác biệt
Trong một bài đăng trên blog trước đây , đồng nghiệp Luke của tôi đã chỉ ra cách sử dụng VGG16 thay vì DenseNet121 đã tăng tốc đáng kể việc đào tạo cho một mô hình xác định các bệnh lý lồng ngực từ chụp X-quang ngực đồng thời cải thiện khu vực theo ROC ở nhiều danh mục. Các mô hình nông thường dễ huấn luyện hơn, đặc biệt khi sử dụng các lô lớn.
Phần kết luận
Đào tạo phân tán theo lô lớn có thể giảm đáng kể thời gian đào tạo nhưng nó cũng có những thách thức riêng. Cải thiện khả năng khái quát hóa khi sử dụng các lô lớn là một lĩnh vực nghiên cứu tích cực và khi các phương pháp mới được phát triển, thời gian đào tạo một mô hình sẽ tiếp tục giảm xuống.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...