
Tin tức
Suy luận mạng thần kinh bằng cách sử dụng Intel® OpenVINO™
Được xuất bản lần đầu vào ngày 9 tháng 11 năm 2018 2:12:18 chiều
Triển khai các mô hình mạng thần kinh đã được đào tạo để suy luận trên các nền tảng khác nhau là một nhiệm vụ đầy thách thức. Môi trường suy luận thường khác với môi trường đào tạo thường là trung tâm dữ liệu hoặc trang trại máy chủ. Nền tảng suy luận có thể bị hạn chế về năng lượng và bị giới hạn từ góc độ phần mềm. Mô hình này có thể được đào tạo bằng cách sử dụng một trong nhiều khung học sâu có sẵn như Tensorflow, PyTorch, Keras, Caffe, MXNet, v.v. Intel® OpenVINO™ cung cấp các công cụ để chuyển đổi các mô hình đã đào tạo thành một biểu diễn khung bất khả tri, bao gồm các công cụ để giảm bộ nhớ dấu chân của mô hình bằng cách sử dụng lượng tử hóa và tối ưu hóa đồ thị. Nó cũng cung cấp các API suy luận chuyên dụng được tối ưu hóa cho các nền tảng phần cứng cụ thể, chẳng hạn như Thẻ tăng tốc lập trình Intel® và Bộ xử lý thị giác Intel® Movidius™.
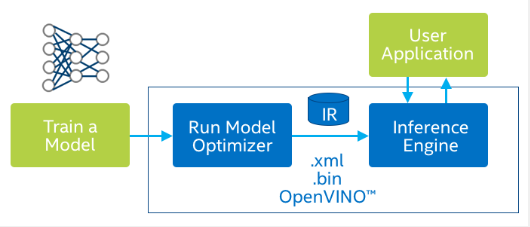
Các thành phần
- Trình tối ưu hóa mô hình là một công cụ dòng lệnh đa nền tảng tạo điều kiện thuận lợi cho việc chuyển đổi giữa môi trường đào tạo và triển khai, thực hiện phân tích mô hình tĩnh và điều chỉnh các mô hình học sâu để thực thi tối ưu trên các thiết bị đích điểm cuối. Đó là một tập lệnh Python lấy đầu vào là mô hình Tensorflow/Caffe đã được huấn luyện và tạo ra Biểu diễn trung gian (IR) bao gồm tệp .xml chứa định nghĩa mô hình và tệp .bin chứa trọng số mô hình.
- Công cụ suy luận là một thư viện C++ với một tập hợp các lớp C++ để suy ra dữ liệu đầu vào (hình ảnh) và nhận kết quả. Thư viện C++ cung cấp API để đọc Biểu diễn trung gian, đặt định dạng đầu vào và đầu ra cũng như thực thi mô hình trên thiết bị. Mỗi thiết bị mục tiêu được hỗ trợ đều có một plugin là thư viện DLL/chia sẻ. Nó cũng hỗ trợ thực thi không đồng nhất để phân phối khối lượng công việc trên các thiết bị. Nó hỗ trợ triển khai các lớp tùy chỉnh trên CPU trong khi thực thi phần còn lại của mô hình trên thiết bị tăng tốc.
Quy trình làm việc
- Sử dụng Trình tối ưu hóa mô hình, chuyển đổi mô hình được đào tạo để tạo ra Biểu diễn trung gian (IR) được tối ưu hóa của mô hình dựa trên cấu trúc liên kết, trọng số và giá trị sai lệch của mạng được đào tạo.
- Kiểm tra mô hình ở định dạng Biểu diễn trung gian bằng Công cụ suy luận trong môi trường đích với ứng dụng xác thực hoặc ứng dụng mẫu .
- Tích hợp Công cụ suy luận vào ứng dụng của bạn để triển khai mô hình trong môi trường đích.
Sử dụng Trình tối ưu hóa mô hình để chuyển đổi mô hình Keras sang IR
Trình tối ưu hóa mô hình không hỗ trợ các tệp mô hình Keras. Tuy nhiên, vì Keras sử dụng Tensorflow làm phụ trợ nên mô hình Keras có thể được lưu dưới dạng điểm kiểm tra Tensorflow có thể được tải vào trình tối ưu hóa mô hình. Mô hình Keras có thể được chuyển đổi thành IR bằng các bước sau
- Lưu mô hình Keras làm điểm kiểm tra Tensorflow. Đảm bảo giai đoạn học tập được đặt thành 0. Lấy tên của nút đầu ra.
nhập tensorflow dưới dạng tf từ keras.applications nhập Resnet50 từ keras nhập phụ trợ dưới dạng K từ keras.models nhập Tuần tự, Mô hình K.set_learning_phase(0) # Đặt giai đoạn học thành 0 model = ResNet50(weights='imagenet', input_shape=(256, 256, 3)) config = model.get_config() trọng lượng = model.get_weights() model = Sequential.from_config(config) out_node = model.output.name.split(':')[0] # Chúng ta cần điều này trong bước tiếp theo graph_file = "resnet50_graph.pb" ckpt_file = "resnet50.ckpt" saver = tf.train.Saver(sharded=True) tf.train.write_graph(sess.graph_def, '', graph_file) saver.save(sess, ckpt_file)
2. Chạy chương trình Tensorflow Freeze_graph để tạo biểu đồ cố định từ điểm kiểm tra đã lưu.
tensorflow/bazel-bin/tensorflow/python/tools/freeze_graph --input_graph=./resnet50_graph.pb --input_checkpoint=./resnet50.ckpt --output_node_names=Softmax --output_graph=resnet_frozen.pb
3. Sử dụng tập lệnh mo.py và biểu đồ cố định để tạo IR. Các trọng số của mô hình có thể được lượng tử hóa thành FP16.
python mo.py --input_model=resnet50_frozen.pb --output_dir=./ --input_shape=[1,224,224,3] -- data_type=FP16
Sự suy luận
Thư viện C++ cung cấp các tiện ích để đọc IR, chọn plugin tùy thuộc vào thiết bị đích và chạy mô hình.
- Đọc Bản trình bày trung gian – Sử dụng lớp InferenceEngine::CNNNetReader, đọc tệp Trình bày trung gian vào lớp CNNNetwork. Lớp này đại diện cho mạng trong bộ nhớ máy chủ.
- Chuẩn bị định dạng đầu vào và đầu ra – Sau khi tải mạng, hãy chỉ định độ chính xác đầu vào và đầu ra cũng như bố cục trên mạng. Đối với các thông số kỹ thuật này, hãy sử dụng CNNNetwork::getInputInfo() và CNNNetwork::getOutputInfo()
- Chọn Plugin – Chọn plugin để tải mạng của bạn. Tạo plugin bằng lớp trợ giúp tải InferenceEngine::PluginDispatcher. Chuyển các cấu hình tải dành riêng cho từng thiết bị cho thiết bị này và đăng ký tiện ích mở rộng cho thiết bị này.
- Biên dịch và tải – Sử dụng lớp trình bao bọc giao diện plugin InferenceEngine::InferencePlugin để gọi API LoadNetwork() nhằm biên dịch và tải mạng trên thiết bị. Chuyển cấu hình tải theo mục tiêu cho hoạt động tải và biên dịch này.
- Đặt dữ liệu đầu vào – Khi mạng được tải, bạn có đối tượng ExecutableNetwork. Sử dụng đối tượng này để tạo InferRequest trong đó bạn báo hiệu bộ đệm đầu vào để sử dụng cho đầu vào và đầu ra. Chỉ định bộ nhớ được cấp phát cho thiết bị và sao chép trực tiếp vào bộ nhớ thiết bị hoặc yêu cầu thiết bị sử dụng bộ nhớ ứng dụng của bạn để lưu một bản sao.
- Thực thi – Với bộ nhớ đầu vào và đầu ra hiện đã được xác định, hãy chọn chế độ thực thi của bạn:
- Đồng bộ – Phương thức Infer(). Chặn cho đến khi suy luận kết thúc.
- Không đồng bộ – Phương thức StartAsync(). Kiểm tra trạng thái bằng phương thức wait() (0 thời gian chờ), chờ hoặc chỉ định lệnh gọi lại hoàn thành.
- Lấy đầu ra – Sau khi suy luận xong, lấy bộ nhớ đầu ra hoặc đọc bộ nhớ bạn đã cung cấp trước đó. Thực hiện việc này bằng API InferRequest GetBlob.
Các chương trìnhclass_sample vàclass_sample_async thực hiện suy luận bằng các bước được đề cập ở trên . Chúng tôi sử dụng các mẫu này trong phần tiếp theo để thực hiện suy luận trên Intel® FPGA.
Sử dụng Thẻ tăng tốc lập trình Intel® với Intel® Arria® 10GX FPGA để suy luận
Bộ công cụ OpenVINO hỗ trợ sử dụng PAC làm thiết bị mục tiêu để chạy suy luận công suất thấp. Quá trình tiền xử lý và xử lý hậu kỳ được thực hiện trên máy chủ trong khi việc thực thi mô hình được thực hiện trên thẻ. Bộ công cụ chứa dòng bit cho các cấu trúc liên kết khác nhau.
Lập trình dòng bit
chương trình aocl <device_id> <open_vino_install_directory>/a10_dcp_bitstreams/2-0-1_RC_FP16_ResNet50-101.aocx
Plugin Hetero có thể được sử dụng với CPU làm thiết bị dự phòng cho các lớp không được FPGA hỗ trợ. Cờ -pc in chi tiết hiệu suất cho từng lớp
./classification_sample_async -d HETERO:FPGA,CPU -i <path/to/input/image.png> -m <path/to/ir>/resnet50_frozen.xml
Phần kết luận
Bộ công cụ Intel® OpenVINO™ là một cách tuyệt vời để nhanh chóng tích hợp các mô hình đã được đào tạo vào các ứng dụng và triển khai chúng trong các môi trường sản xuất khác nhau. Bạn có thể tìm thấy tài liệu đầy đủ về bộ công cụ tại https://software.intel.com/en-us/openvino-toolkit/documentation/featured .
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...