
Tin tức
Triển khai Llama 7B Model với kỹ thuật lượng tử hóa nâng cao trên máy chủ Dell
Giới thiệu
Mô hình ngôn ngữ lớn (LLM) đã thu hút được sự quan tâm lớn trong công nghiệp và học thuật trong những năm gần đây. Các LLM khác nhau đã được áp dụng trong các ứng dụng khác nhau, chẳng hạn như: tạo nội dung, tóm tắt văn bản, phân tích tình cảm và chăm sóc sức khỏe. Sơ đồ tiến hóa LLM trong Hình 1 cho thấy các mô hình được đào tạo trước phổ biến kể từ năm 2017 khi kiến trúc máy biến áp lần đầu tiên được giới thiệu [1]. Không khó để nhận thấy xu hướng các mô hình nguồn mở lớn hơn và nhiều hơn theo dòng thời gian. Các mô hình nguồn mở đã thúc đẩy sự phổ biến của LLM bằng cách loại bỏ chi phí đào tạo khổng lồ liên quan đến quy mô lớn của cơ sở hạ tầng và thời gian đào tạo dài cần thiết. Một phần chi phí khác của các ứng dụng LLM đến từ việc triển khai trong đó cần có nền tảng suy luận hiệu quả.
Blog này tập trung vào cách triển khai LLM hiệu quả trên nền tảng Dell bằng các kỹ thuật lượng tử hóa khác nhau. Trước tiên, chúng tôi đánh giá độ chính xác của mô hình theo các kỹ thuật lượng tử hóa khác nhau. Sau đó, chúng tôi đã chứng minh các yêu cầu về hiệu suất và bộ nhớ khi chạy LLM theo các kỹ thuật lượng tử hóa khác nhau thông qua các thử nghiệm. Cụ thể, chúng tôi đã chọn mô hình nguồn mở Llama-2-7b-chat-hf vì tính phổ biến của nó [2]. Máy chủ được chọn là máy chủ dòng chính Dell R760xa với GPU NVIDIA L40 [3] [4]. Khung triển khai trong các thử nghiệm là TensorRT-LLM, cho phép các kỹ thuật lượng tử hóa khác nhau bao gồm lượng tử hóa 4bit nâng cao như được trình bày trong blog [5].
Hình 1: Sự phát triển của LLM
Lý lịch
Quá trình suy luận LLM có xu hướng chậm và ngốn điện do đặc điểm của LLM là kích thước trọng lượng lớn và có khả năng tự động hồi quy. Làm thế nào để làm cho quá trình suy luận hiệu quả hơn trong điều kiện tài nguyên phần cứng hạn chế là một trong những vấn đề quan trọng nhất đối với việc triển khai LLM. Lượng tử hóa là một kỹ thuật quan trọng được sử dụng rộng rãi để thúc đẩy triển khai LLM hiệu quả hơn. Nó có thể giảm bớt các yêu cầu lớn về tài nguyên phần cứng bằng cách giảm dung lượng bộ nhớ và năng lượng tính toán, cũng như cải thiện hiệu suất với thời gian truy cập bộ nhớ nhanh hơn so với việc triển khai bằng mô hình chưa lượng tử hóa ban đầu. Ví dụ: trong [6], hiệu suất về mặt thông lượng theo mã thông báo mỗi giây (mã thông báo/giây) cho mô hình Llama-2-7b được cải thiện hơn 2 lần bằng cách lượng tử hóa từ định dạng 16 bit dấu phẩy động sang số nguyên 8 bit . Nghiên cứu gần đây đã tạo ra các kỹ thuật lượng tử hóa mạnh mẽ hơn như 4-bit và có sẵn trong một số khung triển khai như TensorRT-LLM. Tuy nhiên, lượng tử hóa không miễn phí và thường đi kèm với việc mất độ chính xác. Bên cạnh chi phí, hiệu suất đáng tin cậy với độ chính xác chấp nhận được cho các ứng dụng cụ thể là điều người dùng quan tâm. Hai chủ đề chính được đề cập trong blog này là độ chính xác và hiệu suất. Trước tiên, chúng tôi đánh giá độ chính xác của mô hình ban đầu và các mô hình lượng tử hóa qua các nhiệm vụ khác nhau. Sau đó, chúng tôi triển khai những mô hình đó vào máy chủ Dell và đo hiệu suất của chúng. Chúng tôi đã đo thêm mức sử dụng bộ nhớ GPU cho từng trường hợp.
Thiết lập thử nghiệm
Mô hình đang được điều tra là Llama-2-7b-chat-hf [2]. Đây là LLM đã được tinh chỉnh với phản hồi của con người và được tối ưu hóa cho các trường hợp sử dụng đối thoại dựa trên mô hình được đào tạo trước 7 tỷ tham số Llama-2. Chúng tôi tải mô hình fp16 làm đường cơ sở từ mặt ôm bằng cách đặt torch_dtype thành float16.
Chúng tôi đã nghiên cứu hai kỹ thuật lượng tử hóa 4 bit nâng cao để so sánh với mô hình fp16 cơ sở. Một là lượng tử hóa trọng lượng nhận biết kích hoạt (AWQ) và hai là GPTQ [7] [8]. TensorRT-LLM tích hợp bộ công cụ cho phép lượng tử hóa và triển khai các mô hình lượng tử hóa 4 bit tiên tiến này.
Để đánh giá độ chính xác giữa các mô hình với các kỹ thuật lượng tử hóa khác nhau, chúng tôi chọn bộ dữ liệu Hiểu ngôn ngữ đa nhiệm lớn (MMLU). Điểm chuẩn này bao gồm 57 môn học khác nhau và có mức độ khó khác nhau cho cả bài kiểm tra kiến thức thế giới và khả năng giải quyết vấn đề [9]. Mức độ chi tiết và độ rộng của các chủ đề trong bộ dữ liệu MMLU cho phép chúng tôi đánh giá độ chính xác của mô hình trên các ứng dụng khác nhau. Để tóm tắt kết quả dễ dàng hơn, 57 chủ đề trong bộ dữ liệu MMLU có thể được nhóm thành 21 danh mục hoặc thậm chí 4 danh mục chính là STEM, nhân văn, khoa học xã hội và các danh mục khác (kinh doanh, y tế, linh tinh) [10].
Hiệu suất được đánh giá theo số token/số trên các kích cỡ lô khác nhau trên máy chủ Dell R760xa với một L40 được cắm vào các khe cắm PCIe. Cấu hình máy chủ R760xa và thông số kỹ thuật cấp cao của L40 được thể hiện trong Bảng 1 và 2 [3] [4]. Để so sánh dễ dàng hơn, chúng tôi sửa độ dài chuỗi đầu vào và độ dài chuỗi đầu ra lần lượt là 512 và 200.
| Tên hệ thống | PowerEdge R760xa |
| Trạng thái | Có sẵn |
| Loại hệ thống | Trung tâm dữ liệu |
| Số nút | 1 |
| Mô hình bộ xử lý máy chủ | Bộ xử lý có khả năng mở rộng Intel® Xeon® thế hệ thứ 4 |
| Tên quy trình máy chủ | Intel® Xeon® Vàng 6430 |
| Bộ xử lý máy chủ trên mỗi nút | 2 |
| Số lượng lõi của bộ xử lý máy chủ | 32 |
| Tần số bộ xử lý máy chủ | Tăng tốc Turbo 2,0 GHz, 3,8 GHz |
| Dung lượng và loại bộ nhớ máy chủ | DIMM 512GB, 16 x 32GB, DDR5 4800 MT/s |
| Dung lượng lưu trữ máy chủ | 1,8 TB, NVME |
Bảng 1: Cấu hình máy chủ R760xa
| Kiến trúc GPU | Kiến trúc NVIDIA Ada Lovelace L40 |
| Băng thông bộ nhớ GPU | 48 GB GDDR6 có ECC |
| Tiêu thụ điện tối đa | 300W |
| Yếu tố hình thức | Khe kép 4,4″ (H) x 10,5″ (L) |
| nhiệt | Thụ động |
Bảng 2: Thông số kỹ thuật cấp cao L40
Khung suy luận bao gồm các công cụ lượng tử hóa khác nhau là phiên bản phát hành ban đầu NVIDIA TensorRT-LLM 0.5. Hệ điều hành cho thử nghiệm là Ubuntu 22.04 LTS.
Kết quả
Trước tiên, chúng tôi hiển thị kết quả về độ chính xác của mô hình dựa trên các thử nghiệm tập dữ liệu MMLU trong Hình 2 và Hình 3, cũng như kết quả hiệu suất thông lượng khi chạy các mô hình đó trên PowerEdge R760xa trong Hình 4. Cuối cùng, chúng tôi hiển thị mức sử dụng bộ nhớ cao nhất thực tế cho các tình huống khác nhau. Các cuộc thảo luận ngắn gọn được đưa ra cho mỗi kết quả. Các kết luận được tóm tắt trong phần tiếp theo.
Sự chính xác
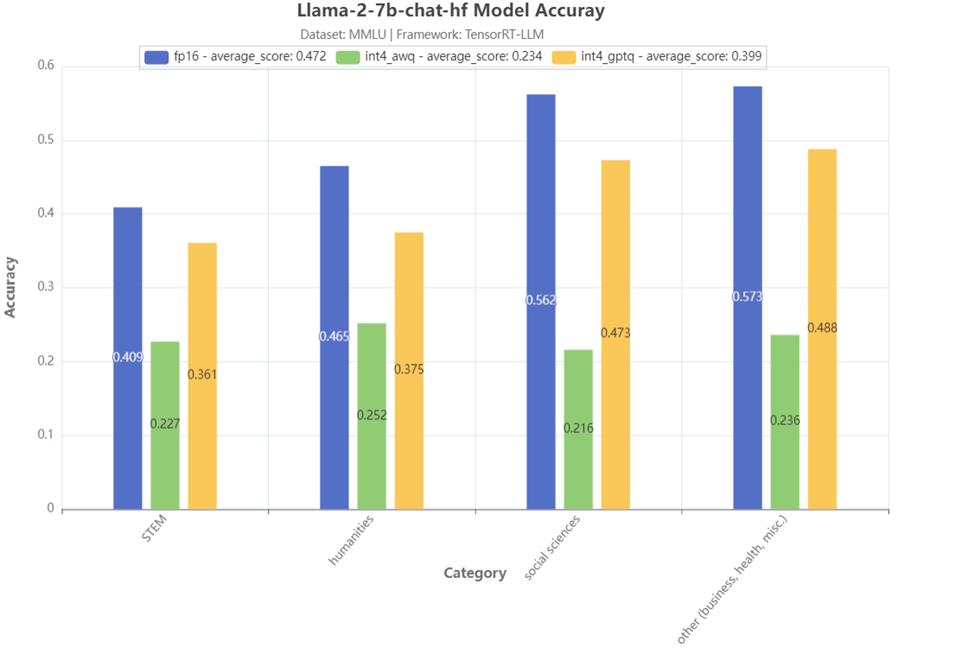
Hình 2: Kết quả kiểm tra độ chính xác 4 loại MMLU
Hình 2 thể hiện kết quả kiểm tra độ chính xác của 4 loại MMLU chính cho mô hình Llama-2-7b-chat-hf. So với mô hình fp16 cơ bản, chúng ta có thể thấy rằng mô hình có AWQ 4 bit có độ chính xác giảm đáng kể. Mặt khác, mô hình có GPTQ 4 bit có mức giảm độ chính xác nhỏ hơn nhiều, đặc biệt đối với danh mục STEM, mức giảm độ chính xác nhỏ hơn 5%.
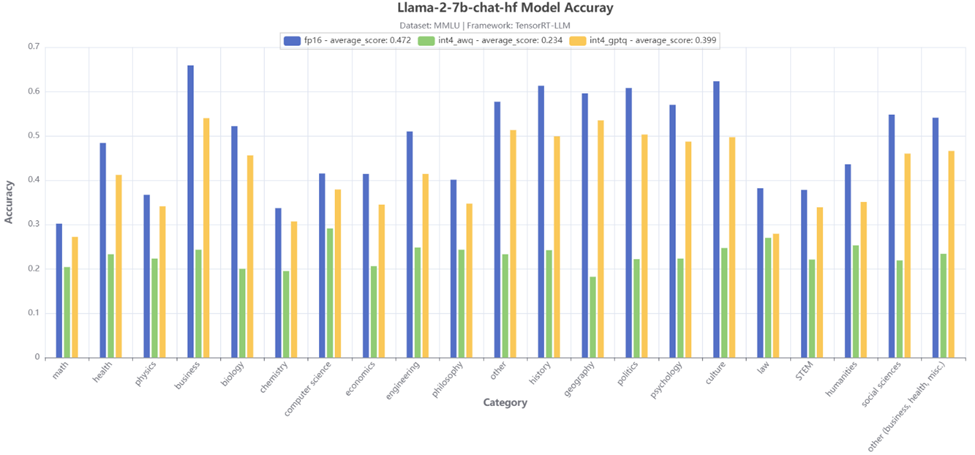
Hình 3: Kết quả kiểm tra độ chính xác loại MMLU 21
Hình 3 tiếp tục hiển thị kết quả kiểm tra độ chính xác của 21 danh mục phụ MMLU cho mô hình Llama-2-7b-chat-hf. Có thể đưa ra kết luận tương tự là lượng tử hóa GPTQ 4 bit cho độ chính xác cao hơn nhiều, ngoại trừ phạm trù luật, hai kỹ thuật lượng tử hóa đều đạt được độ chính xác gần nhau.
Hiệu suất
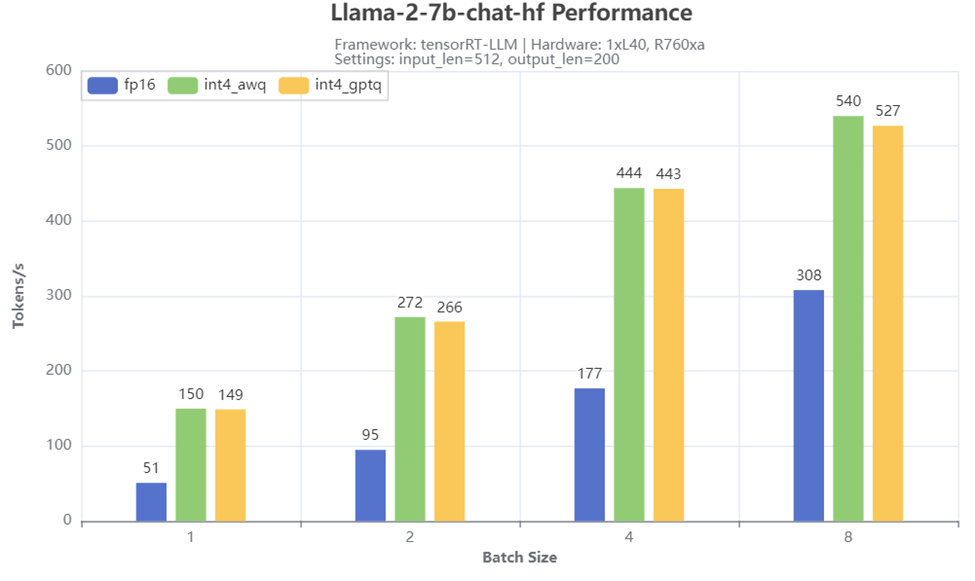
Hình 4: Kết quả kiểm tra thông lượng
Hình 4 hiển thị số lượng thông lượng khi chạy Llama-2-7b-chat-hf với các phương pháp lượng tử hóa và kích thước lô khác nhau trên máy chủ R760xa. Chúng tôi quan sát thấy thông lượng tăng đáng kể nhờ lượng tử hóa 4 bit, đặc biệt khi kích thước lô nhỏ. Ví dụ: đạt được số lượng mã thông báo gấp 3 lần/giây khi kích thước lô là 1 khi so sánh các kịch bản với lượng tử hóa AWQ hoặc GPTQ 4 bit với kịch bản cơ sở 16 bit. Cả lượng tử hóa AWQ và GPTQ đều cho hiệu suất tương tự trên các kích cỡ lô khác nhau.
Sử dụng bộ nhớ GPU
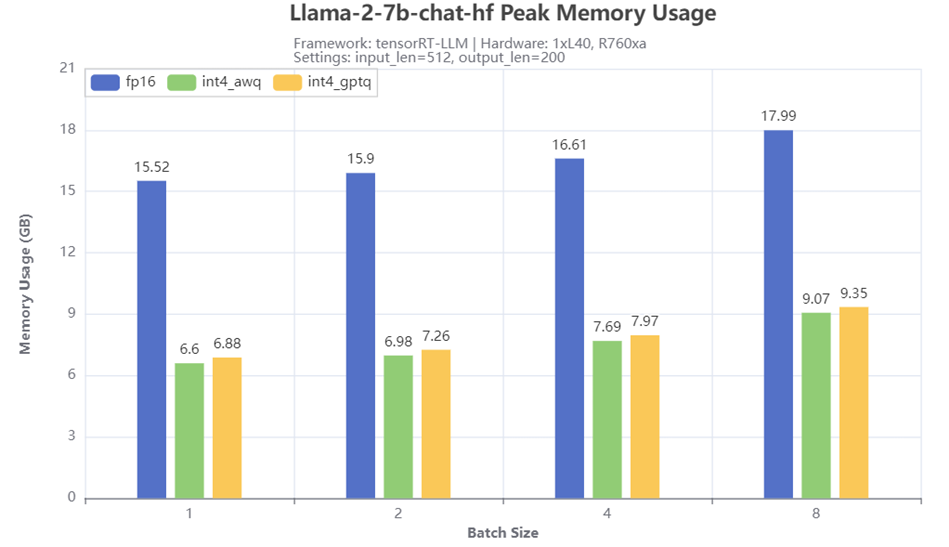
Hình 5: Mức sử dụng bộ nhớ GPU cao nhất
Hình 5 cho thấy mức sử dụng bộ nhớ GPU cao nhất khi chạy Llama-2-7b-chat-hf với các phương pháp lượng tử hóa và kích thước lô khác nhau trên máy chủ R760xa. Từ kết quả, kỹ thuật lượng tử hóa 4 bit giúp giảm đáng kể bộ nhớ cần thiết để chạy mô hình. So với kích thước bộ nhớ cần thiết cho mô hình fp16 cơ bản, các mô hình lượng tử hóa có AWQ hoặc GPTQ chỉ yêu cầu một nửa hoặc thậm chí ít hơn bộ nhớ, tùy thuộc vào kích thước lô. Mức sử dụng bộ nhớ tối đa lớn hơn một chút cũng được quan sát thấy đối với mô hình lượng tử hóa GPTQ so với mô hình lượng tử hóa AWQ.
Phần kết luận
- Chúng tôi đã chỉ ra những tác động về độ chính xác, hiệu suất và mức sử dụng bộ nhớ GPU bằng cách áp dụng các kỹ thuật lượng tử hóa 4 bit nâng cao trên máy chủ Dell PowerEdge khi chạy model Llama 7B.
- Chúng tôi đã chứng minh những lợi ích to lớn của kỹ thuật lượng tử hóa 4 bit này về mặt cải thiện thông lượng và tiết kiệm bộ nhớ GPU.
- Chúng tôi đã so sánh định lượng các mô hình lượng tử hóa với mô hình cơ sở về độ chính xác giữa các đối tượng khác nhau dựa trên bộ dữ liệu MMLU.
- Các thử nghiệm cho thấy rằng với mức độ giảm độ chính xác có thể chấp nhận được, GPTQ 4 bit là một phương pháp lượng tử hóa hấp dẫn để triển khai LLM khi tài nguyên phần cứng bị hạn chế. Mặt khác, độ chính xác giảm mạnh ở nhiều đối tượng MMLU đã được quan sát thấy đối với AWQ 4 bit. Điều này cho thấy mô hình nên được giới hạn ở các ứng dụng gắn liền với một số đối tượng cụ thể. Mặt khác, có thể cần phải có các kỹ thuật khác như kỹ thuật huấn luyện lại hoặc kỹ thuật tiện tinh để cải thiện độ chính xác.
Bài viết mới cập nhật
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...