
Tin tức
Đào tạo người mẫu – Thiết kế được xác nhận của Dell
Giới thiệu
Khi nói đến các mô hình ngôn ngữ lớn (LLM), có thể có một câu hỏi cơ bản mà tất cả những người muốn tận dụng các mô hình nền tảng cần phải trả lời: Tôi nên huấn luyện mô hình của mình hay tôi nên tùy chỉnh mô hình hiện có?
Có thể có những lập luận mạnh mẽ cho một trong hai. Trong bài đăng trước , Nomuka Luehr đã đề cập đến một số phương pháp tùy chỉnh phổ biến. Trong blog này, tôi sẽ xem xét mặt khác của câu hỏi: đào tạo và trả lời các câu hỏi sau: Tại sao tôi lại đào tạo LLM? Tôi nên xem xét những yếu tố nào? Tôi cũng sẽ đề cập đến Generative AI được công bố gần đây trong Doanh nghiệp – Đào tạo mô hình Thiết kế được xác thực của Dell – Cơ sở hạ tầng sản xuất mô-đun và có thể mở rộng để đào tạo mô hình ngôn ngữ lớn AI . Đây là nỗ lực hợp tác giữa Dell Technologies và NVIDIA, nhằm tạo điều kiện cho các giải pháp mô-đun, có thể mở rộng và hiệu suất cao để đào tạo các mô hình ngôn ngữ lớn (LLM) trong môi trường doanh nghiệp (sẽ nói thêm về điều đó sau).
Quy trình đào tạo
Các đường dẫn dữ liệu để đào tạo và tùy chỉnh tương tự nhau vì cả hai quy trình đều liên quan đến việc cung cấp các bộ dữ liệu cụ thể thông qua LLM.
Trong trường hợp đào tạo, tập dữ liệu thường lớn hơn nhiều so với tùy chỉnh vì việc tùy chỉnh được nhắm mục tiêu vào một miền cụ thể. Hãy nhớ rằng, để đào tạo một mô hình, mục tiêu là đưa càng nhiều kiến thức vào mô hình càng tốt, vì vậy tập dữ liệu phải lớn.
Điều này đặt ra câu hỏi về tập dữ liệu cũng như tính chính xác và phù hợp của nó. Quản lý và chuẩn bị dữ liệu là các quy trình thiết yếu để tránh những thành kiến và thông tin sai lệch. Bước này rất quan trọng để đảm bảo chất lượng và mức độ liên quan của dữ liệu được đưa vào LLM. Nó liên quan đến việc lựa chọn và tinh chỉnh dữ liệu một cách tỉ mỉ để giảm thiểu những sai lệch và thông tin sai lệch mà nếu bị bỏ qua có thể ảnh hưởng đến độ chính xác và độ tin cậy đầu ra của mô hình. Quản lý dữ liệu không chỉ là thu thập thông tin; đó là việc đảm bảo rằng nền tảng kiến thức của mô hình là toàn diện, cân bằng và phản ánh nhiều quan điểm.
Khi tập dữ liệu được quản lý và chuẩn bị trước, quy trình đào tạo thực tế bao gồm một loạt các bước trong đó dữ liệu được cung cấp thông qua LLM. Mô hình tạo ra kết quả đầu ra dựa trên đầu vào được cung cấp, sau đó được so sánh với kết quả mong đợi. Sự khác biệt giữa kết quả đầu ra thực tế và dự kiến dẫn đến việc điều chỉnh trọng số của mô hình, dần dần cải thiện độ chính xác của mô hình thông qua quá trình tinh chỉnh lặp lại (sử dụng phương pháp học có giám sát, học không giám sát, v.v.).
Mặc dù nguyên tắc bao quát của quá trình này có vẻ đơn giản nhưng nó lại không hề đơn giản. Mỗi bước bao gồm các quyết định phức tạp, từ việc chọn dữ liệu phù hợp và xử lý trước dữ liệu một cách hiệu quả cho đến tùy chỉnh các tham số của mô hình để có hiệu suất tối ưu. Hơn nữa, bối cảnh đào tạo đang phát triển với những tiến bộ, chẳng hạn như học tập có giám sát và không giám sát, mang lại những con đường khác nhau để phát triển mô hình. Học tập có giám sát, dựa trên các tập dữ liệu được gắn nhãn, vẫn là nền tảng cho hầu hết các chế độ đào tạo LLM, bằng cách cung cấp một cách có cấu trúc để nhúng kiến thức. Tuy nhiên, học tập không giám sát, khám phá các mẫu dữ liệu mà không có nhãn được xác định trước, đang thu hút được sự chú ý nhờ khả năng khám phá những hiểu biết mới.
Những vấn đề phức tạp này nêu bật tầm quan trọng của việc tận dụng các công cụ và công nghệ tiên tiến. Các công ty như NVIDIA đang đi đầu, cung cấp các gói phần mềm tinh vi tự động hóa nhiều khía cạnh của quy trình và giảm bớt rào cản gia nhập cho những ai muốn phát triển hoặc cải tiến LLM.
Hiệu suất mạng và lưu trữ
Trong phần trước, tôi đã đề cập đến tập dữ liệu cần thiết để huấn luyện hoặc tùy chỉnh mô hình. Mặc dù việc có tập dữ liệu phù hợp là một phần quan trọng của quy trình này, nhưng việc có thể phân phối tập dữ liệu đó đủ nhanh đến các GPU chạy mô hình là một phần quan trọng khác nhưng thường bị bỏ qua. Để đạt được điều đó, bạn phải xem xét hai thành phần:
- Hiệu suất lưu trữ
- Hiệu suất mạng
Đối với bất kỳ ai muốn đào tạo một mô hình, việc có cơ sở hạ tầng mạng nút-nút (còn được gọi là Đông-Tây) dựa trên 100Gbps hoặc tốt hơn là 400Gbps là rất quan trọng vì nó đảm bảo đủ băng thông và thông lượng để duy trì loại bão hòa. GPU, chẳng hạn như NVIDIA H100, cần thiết cho việc đào tạo.
Vì các tập dữ liệu tùy chỉnh thường nhỏ hơn các tập dữ liệu huấn luyện đầy đủ nên mạng 100Gbps có thể là đủ, nhưng cũng như mọi thứ trong công nghệ, quãng đường của bạn có thể thay đổi và việc kiểm tra thích hợp là rất quan trọng để đảm bảo hiệu suất phù hợp với nhu cầu của bạn.
Các bộ dữ liệu được sử dụng để đào tạo các mô hình thường rất lớn: khoảng 100 GB. Chẳng hạn, tập dữ liệu được sử dụng để huấn luyện GPT-4 được cho là có dung lượng trên 550GB. Với sự tiến bộ của RDMA qua Ethernet hội tụ (RoCE), GPU có thể lấy dữ liệu trực tiếp từ bộ lưu trữ. Và vì mạng 100Gbps có thể hỗ trợ tải đó nên nút cổ chai đã chuyển sang bộ lưu trữ.
Do tính chất của các mô hình ngôn ngữ lớn, tập dữ liệu được sử dụng để huấn luyện chúng được tạo từ dữ liệu phi cấu trúc, chẳng hạn như các trang Sharepoint và kho tài liệu, do đó thường được lưu trữ trên bộ lưu trữ gắn liền với mạng, chẳng hạn như Dell PowerScale. Tôi sẽ không đi sâu vào chi tiết hơn về phần lưu trữ vì tôi sẽ xuất bản một blog khác về cách sử dụng PowerScale để hỗ trợ đào tạo mô hình. Nhưng bạn phải cân nhắc cẩn thận khi thiết kế bộ lưu trữ để đảm bảo rằng bộ lưu trữ có thể theo kịp GPU và mạng.
Lưu ý về việc kiểm tra điểm
Như chúng tôi đã đề cập trước đây, quá trình đào tạo được lặp đi lặp lại. Dựa trên đầu vào được cung cấp, mô hình sẽ tạo ra đầu ra , sau đó được so sánh với kết quả mong đợi. Sự khác biệt giữa kết quả đầu ra thực tế và dự kiến dẫn đến việc điều chỉnh trọng số của mô hình, dần dần cải thiện độ chính xác của mô hình thông qua quá trình tinh chỉnh lặp đi lặp lại. Quá trình này được lặp lại qua nhiều lần lặp trên toàn bộ tập dữ liệu huấn luyện.
Quá trình đào tạo (nghĩa là chạy toàn bộ tập dữ liệu thông qua một mô hình và cập nhật trọng số của nó) cực kỳ tốn thời gian và tốn nhiều tài nguyên. Theo bài đăng trên blog này , một lần huấn luyện ChatGPT-4 có giá khoảng 4,6 triệu USD. Hãy tưởng tượng chạy một vài trong số chúng liên tiếp, rồi gặp sự cố và phải bắt đầu lại. Do chi phí liên quan đến các lần chạy huấn luyện nên việc tiết kiệm trọng lượng của mô hình ở giai đoạn trung gian trong quá trình chạy thường là một ý tưởng hay. Nếu sau này có lỗi xảy ra, bạn có thể tải trọng lượng đã lưu và khởi động lại từ thời điểm đó. Việc chụp nhanh trọng số của mô hình theo cách này được gọi là điểm kiểm tra. Thách thức với việc kiểm tra điểm là hiệu suất.
Điểm kiểm tra thường được lưu trữ trên hệ thống lưu trữ bên ngoài, do đó, một lần nữa, hiệu suất lưu trữ và hiệu suất mạng là những cân nhắc quan trọng để cung cấp băng thông và thông lượng thích hợp cho điểm kiểm tra. Chẳng hạn, Llama-2 70B tiêu tốn khoảng 129GB dung lượng lưu trữ. Vì mỗi điểm kiểm tra của nó có cùng kích thước có thể dự đoán được nên chúng có thể được lưu nhanh chóng (vào đĩa) để đảm bảo quá trình đào tạo diễn ra đúng cách.
Ngăn xếp phần mềm NVIDIA
Việc lựa chọn sử dụng khung nào tùy thuộc vào việc bạn thường thiên về việc tự mình thực hiện hay mua các kết quả cụ thể. Lợi ích của việc tự mình thực hiện là tính linh hoạt cao nhất, đôi khi phải tốn thời gian tiếp thị, trong khi việc mua một kết quả có thể mang lại thời gian tiếp thị tốt hơn với chi phí phải lựa chọn trong một tập hợp các thành phần được xác định trước. Trong trường hợp của tôi, tôi luôn có xu hướng ưu tiên kết quả mua hàng, đó là lý do tại sao tôi muốn đề cập đến nhóm phần mềm NVIDIA AI Enterprise (NVAIE) ở mức cao.
Hình dưới đây là một chiếc bánh nhiều lớp đơn giản thể hiện các thành phần khác nhau của NVAIE, có màu xanh lục nhạt.
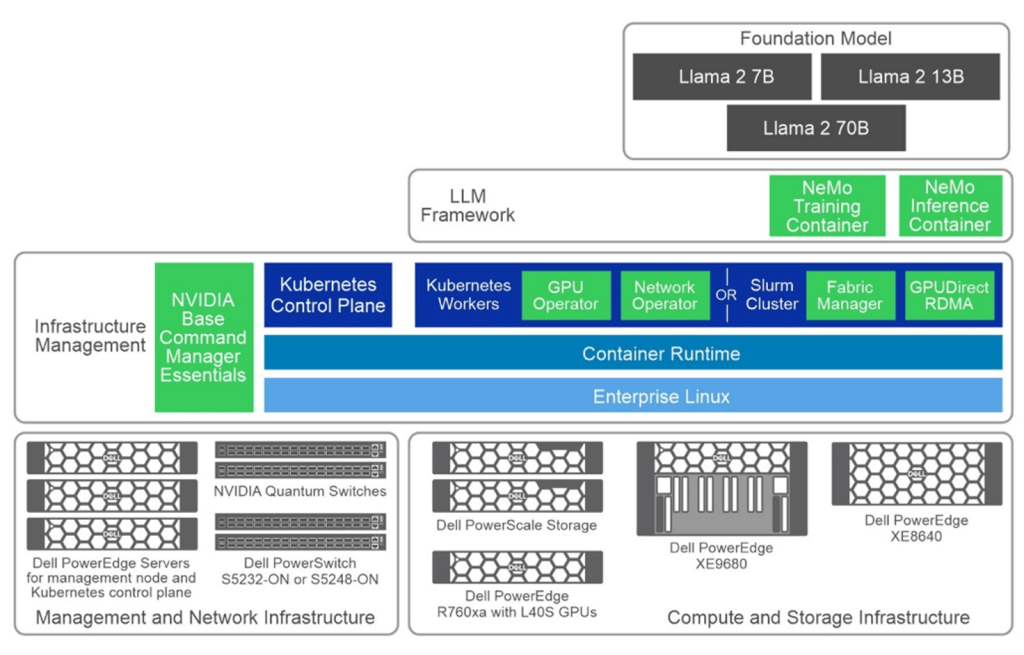
Sách trắng Generative AI trong doanh nghiệp – Đào tạo mô hình Thiết kế được xác thực của Dell cung cấp thông tin khám phá chuyên sâu về thiết kế tham chiếu do Dell Technologies hợp tác với NVIDIA phát triển. Nó cung cấp cho doanh nghiệp một khuôn khổ mạnh mẽ và có thể mở rộng để đào tạo các mô hình ngôn ngữ lớn một cách hiệu quả. Cho dù bạn là CTO, kỹ sư AI hay giám đốc điều hành CNTT, hướng dẫn này đều đề cập đến các khía cạnh quan trọng của cơ sở hạ tầng đào tạo mô hình, bao gồm thông số kỹ thuật phần cứng, thiết kế phần mềm và kết quả xác thực thực tế.
Đào tạo kiến trúc Thiết kế được xác thực của Dell
Kiến trúc được xác thực nhằm mục đích cung cấp cho người đọc một kết quả đầu ra rộng rãi về kết quả đào tạo mô hình. Chúng tôi đã sử dụng hai loại cấu hình riêng biệt trên ngăn xếp điện toán, mạng và GPU.
Có hai cấu hình PowerEdge XE9680 8x, cả hai đều có GPU NVIDIA H100 SXM 8x. Sự khác biệt giữa các cấu hình (một lần nữa) là mạng. Cấu hình đầu tiên được trang bị 8x ConnectX-7; cấu hình thứ hai được trang bị bốn bộ điều hợp ConnectX-7. Cả hai đều được cấu hình cho NDR.
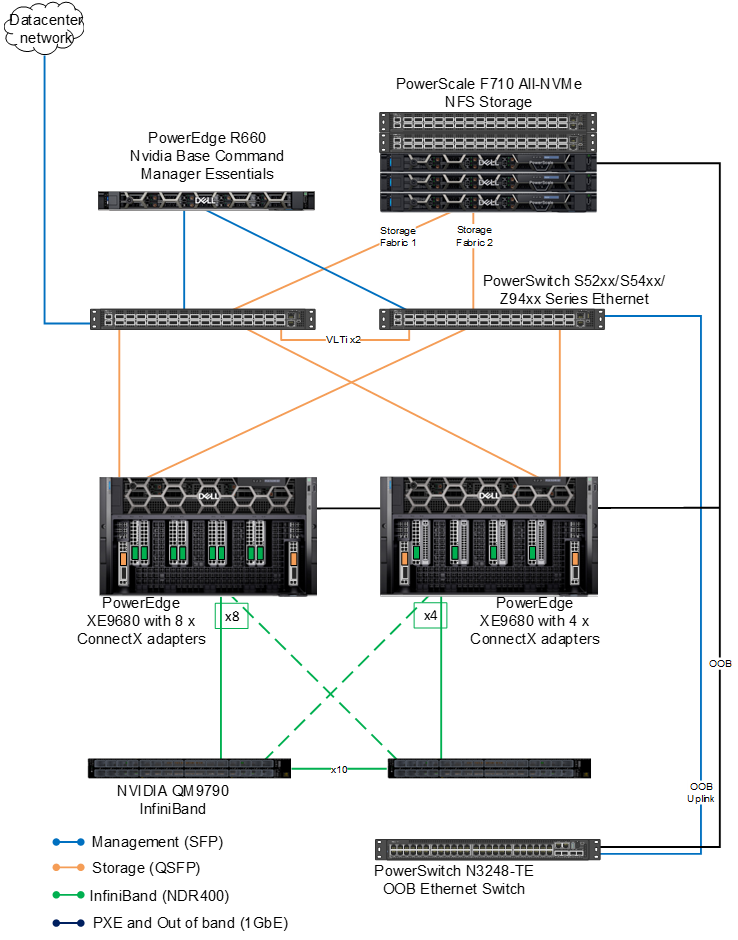
Về mặt lưu trữ, sự phát triển của PowerScale tiếp tục phát triển mạnh trong lĩnh vực AI với việc ra mắt dòng sản phẩm mới nhất, bao gồm cả PowerScale F710 đáng chú ý. Sự bổ sung này bao gồm các máy chủ Dell PowerEdge 16G, báo trước một kỷ nguyên mới về khả năng hoạt động cho các nút flash toàn bộ của PowerScale. Về mặt phần mềm, F710 được hưởng lợi từ các tính năng hiệu suất nâng cao có trong bản cập nhật PowerScale OneFS 9.7.
Bài học chính
Hướng dẫn cung cấp thời gian đào tạo cho các mẫu Llama 2 7B và Llama 2 70B trên 500 bước, với các biến thể dựa trên số lượng nút và cấu hình được sử dụng.
Tại sao chỉ có 500 bước? Quyết định đào tạo mô hình cho một số bước nhất định (500), thay vì đào tạo mô hình để hội tụ, là thực tế cho mục đích xác nhận. Nó cho phép đo điểm chuẩn nhất quán giữa các kịch bản và mô hình khác nhau, để tạo ra sự so sánh rõ ràng hơn về hiệu quả cơ sở hạ tầng và hiệu suất mô hình trong giai đoạn đầu.
Hiệu quả của việc định cỡ mô hình: Việc lựa chọn kiến trúc mô hình 7B và 70B Llama 2 cho thấy một cách tiếp cận chiến lược nhằm cân bằng hiệu quả tính toán với hiệu suất mô hình tiềm năng. Các mô hình nhỏ hơn như 7B được đào tạo nhanh hơn và yêu cầu ít tài nguyên hơn, khiến chúng phù hợp cho các thử nghiệm sơ bộ và ứng dụng ở quy mô nhỏ hơn. Mặt khác, mô hình 70B, mặc dù tiêu tốn nhiều tài nguyên hơn đáng kể, nhưng lại được chọn vì có tiềm năng nắm bắt các mẫu phức tạp hơn và cung cấp kết quả đầu ra chính xác hơn.
Tối ưu hóa cấu hình và tài nguyên : So sánh hai cấu hình phần cứng cung cấp những hiểu biết sâu sắc có giá trị về việc tối ưu hóa việc phân bổ tài nguyên. Mặc dù các cấu hình cao cấp hơn (Cấu hình 1 với 8 bộ điều hợp) mang lại hiệu suất tốt hơn một chút nhưng bạn phải cân nhắc lợi ích cận biên với chi phí tăng lên. Điều này nhấn mạnh tầm quan trọng của việc điều chỉnh thiết lập phần cứng theo nhu cầu và quy mô cụ thể của dự án, trong đó đôi khi, cách tiếp cận ít tối đa hơn (Cấu hình 2 với 4 bộ điều hợp) có thể mang lại tỷ lệ chi phí trên lợi ích cân bằng hơn, đặc biệt là trong các thiết lập nhỏ hơn. Chắc chắn có điều gì đó để suy nghĩ!
Cài đặt song song: Các cài đặt cụ thể cho tính song song tensor và đường ống (như được đề cập trong hướng dẫn), cùng với kích thước lô và độ dài chuỗi, rất quan trọng đối với hiệu quả đào tạo. Các cài đặt này tác động đến tốc độ đào tạo và hiệu suất mô hình, cho thấy cần phải điều chỉnh cẩn thận để cân bằng việc sử dụng tài nguyên với hiệu quả đào tạo. Việc lựa chọn các tham số này phản ánh cách tiếp cận chiến lược để quản lý tải tính toán và thời gian đào tạo.
Đóng
Với cơ sở hạ tầng mô-đun và có thể mở rộng được thiết kế bởi Dell Technologies và NVIDIA, bạn được trang bị đầy đủ để bắt tay vào hoặc nâng cao các sáng kiến AI của mình. Tận dụng kế hoạch chi tiết này để thúc đẩy đổi mới, cải tiến khả năng hoạt động của bạn và duy trì lợi thế cạnh tranh trong việc khai thác sức mạnh của các mô hình ngôn ngữ lớn.
Bài viết mới cập nhật
Đẩy nhanh đổi mới AI: Máy chủ mới và giải pháp giá đỡ tích hợp cho tương lai
Sau những thông báo thú vị tại Ngày AI tiên tiến ...
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...