
Tin tức
Một tấm áp phích đơn giản tại NVIDIA GTC – Chạy NVIDIA Riva trên Red Hat OpenShift với Dell PowerFlex
Dell và NVIDIA đã phát hành một thiết kế đã được xác thực để chạy NVIDIA Riva trên Red Hat OpenShift với Dell PowerFlex . Một tấm áp phích đơn giản—không hơn, không kém—nhưng nó có thể mở khóa nhiều hơn nữa cho tổ chức của bạn. Thiết kế này cho thấy sức mạnh của NVIDIA Riva và Dell PowerFlex trong việc xử lý khối lượng công việc xử lý âm thanh.
Hơn nữa, nó sẽ được trưng bày như một phần của phòng trưng bày áp phích tại NVIDIA GTC tuần này ở San Jose California. Nếu bạn ở GTC, chúng tôi thực sự khuyến khích bạn tham gia cùng chúng tôi trong Lễ đón tiếp áp phích từ 4:00 đến 6:00 chiều. Nếu bạn không thể tham gia cùng chúng tôi, bạn có thể xem áp phích trực tuyến từ trang web GTC.
Đối với những người quen thuộc với các ứng dụng ASR, TTS và NMT, bạn có thể tò mò về cách chúng tôi có thể tổng hợp các khái niệm này thành một áp phích đơn giản. Đọc tiếp để tìm hiểu thêm.
NVIDIA Riva
Đối với những ai chưa quen với NVIDIA Riva , chúng ta hãy bắt đầu từ đó.
NVIDIA Riva là một bộ công cụ phát triển phần mềm AI (SDK) để xây dựng các đường ống AI đàm thoại, cho phép các tổ chức lập trình AI vào hệ thống giọng nói và âm thanh của họ. Nó có thể được sử dụng như một trợ lý thông minh hoặc thậm chí là một người ghi chú trong cuộc họp tiếp theo của bạn. Thật tuyệt phải không?
Nâng cấp hơn nữa, NVIDIA Riva cho phép bạn xây dựng các đường ống AI đàm thoại thời gian thực, có thể tùy chỉnh hoàn toàn, đây là cách nói hoa mỹ để cho phép bạn xử lý giọng nói theo nhiều cách khác nhau, bao gồm nhận dạng giọng nói tự động (ASR), chuyển văn bản thành giọng nói (TTS) và các ứng dụng dịch máy thần kinh (NMT):
- Nhận dạng giọng nói tự động ( ASR) – về cơ bản là đọc chính tả. Cung cấp cho AI bản ghi âm và nhận bản ghi chép—một công cụ lưu trữ ghi chú gần như hoàn hảo cho cuộc họp tiếp theo của bạn.
- Chuyển văn bản thành giọng nói (TTS) – máy tính đọc những gì bạn nhập. Trước đây, điều này thường diễn ra bằng giọng đều đều. Nó đã tồn tại trong hơn một vài thập kỷ và đã phát triển nhanh chóng với giọng nói và cảm xúc trôi chảy hơn.
- Dịch máy thần kinh (NMT) – đây là bản dịch ngôn ngữ nói gần như theo thời gian thực sang một ngôn ngữ khác. Đây là một công cụ tuyệt vời để cải thiện giao tiếp, có thể giúp các tổ chức mở rộng kinh doanh.
Mỗi ứng dụng đều mạnh mẽ theo cách riêng của nó, vì vậy hãy nghĩ về những gì có thể khi chúng ta kết hợp ASR, TTS và NMT lại với nhau, đặc biệt là với hệ thống được AI hỗ trợ. Hãy tưởng tượng có một hệ thống hỗ trợ kỹ thuật có thể phân loại các cuộc gọi hỗ trợ, nghe như bạn đang nói chuyện với một kỹ sư hỗ trợ thực sự và có thể cung cấp hỗ trợ đó bằng nhiều ngôn ngữ. Nói một cách ngắn gọn: đột phá.
NVIDIA Riva cho phép các tổ chức trở nên hiệu quả hơn trong việc xử lý giao tiếp dựa trên giọng nói. Khi các tổ chức trở nên hiệu quả hơn trong một lĩnh vực, họ có thể cải thiện ở các lĩnh vực khác. Đây là lý do tại sao NVIDIA Riva là một phần của nền tảng phần mềm NVIDIA AI Enterprise , tập trung vào việc hợp lý hóa quá trình phát triển và triển khai AI sản xuất.
Tôi làm cho mọi thứ nghe có vẻ đơn giản, tuy nhiên những người tạo ra các mô hình ngôn ngữ lớn (LLM) xung quanh phần mềm dịch và lời nói đa ngôn ngữ đều biết rằng không phải vậy. Đó là lý do tại sao NVIDIA phát triển Riva SDK.
Nền tảng vận hành cũng đóng vai trò to lớn trong những gì có thể thực hiện được với khối lượng công việc. Red Hat OpenShift cho phép nhận dạng giọng nói và suy luận AI với khả năng điều phối container mạnh mẽ, kiến trúc microservices và các tính năng bảo mật mạnh mẽ. Điều này cho phép khối lượng công việc mở rộng để đáp ứng nhu cầu của một tổ chức. Khi sự thành công của một dự án tăng lên, dự án cũng phải tăng theo.
Tại sao lưu trữ lại quan trọng
Bạn có thể đang tự hỏi làm thế nào để lưu trữ phù hợp với tất cả những điều này. Đó là một câu hỏi tuyệt vời. Bạn sẽ cần lưu trữ hiệu suất cao cho NVIDIA Riva. Rốt cuộc, nó được thiết kế để xử lý và/hoặc tạo tệp âm thanh và có thể thực hiện điều đó gần như theo thời gian thực đòi hỏi một lưu trữ hiệu suất cao, cấp doanh nghiệphệ thống như Dell PowerFlex.
Ngoài ra, khối lượng công việc AI đang trở thành ứng dụng chính thống trong trung tâm dữ liệu và có thể chạy song song với các khối lượng công việc quan trọng khác sử dụng cùng một bộ lưu trữ. Tôi đã viết về điều này trong blog Dell PowerFlex – For Business-Critical Workloads and AI của mình.
Lúc này bạn có thể tò mò NVIDIA Riva chạy tốt như thế nào trên Dell PowerFlex.Đó chính là nội dung chính của phần lớn tấm áp phích.
Hiệu suất ASR và TTS
Nhóm Kỹ thuật Giải pháp Dell PowerFlex đã tiến hành thử nghiệm mở rộng bằng cách sử dụng bộ dữ liệu dev-clean LibriSpeech có sẵn từ Open SLR . Với bộ dữ liệu này, họ đã thực hiện thử nghiệm nhận dạng giọng nói tự động (ASR) bằng NVIDIA Riva. Đối với mỗi thử nghiệm, luồng được tăng từ 1 lên 64, 128, 256, 384 và cuối cùng là 512, như thể hiện trong biểu đồ sau.
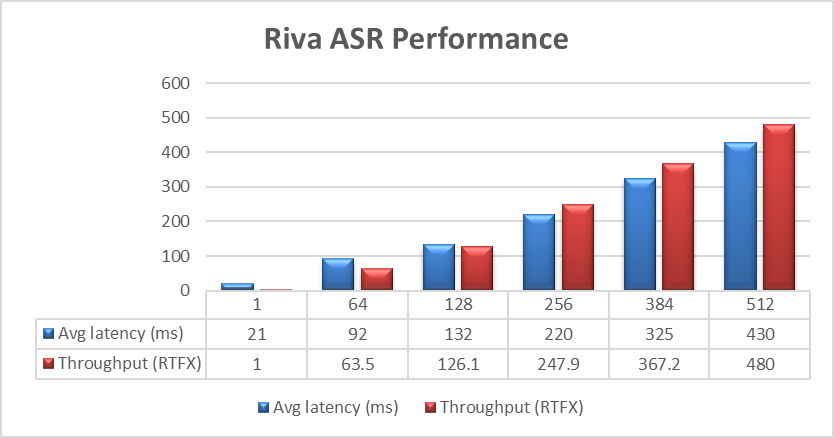 Hình 1. Hiệu suất NVIDIA Riva ASR
Hình 1. Hiệu suất NVIDIA Riva ASR
Mục tiêu của các thử nghiệm này là có độ trễ thấp nhất với thông lượng cao nhất. Thông lượng được đo bằng RTFX hoặc thời lượng âm thanh được phiên âm chia cho thời gian tính toán. Trong các thử nghiệm này, mức sử dụng GPU đạt khoảng 48% mà không có bất kỳ tắc nghẽn lưu trữ PowerFlex nào. Những kết quả này tương đương với những phát hiện của riêng NVIDIA trong Hướng dẫn sử dụng NVIDIA Riva .
Nhóm Kỹ thuật Giải pháp Dell PowerFlex đã không chỉ xem xét tốc độ NVIDIA Riva có thể phiên âm văn bản mà còn khám phá tốc độ chuyển đổi văn bản thành giọng nói (TTS) của nó. Họ cũng đã xác thực điều này. Bắt đầu với một luồng duy nhất, đối với mỗi lần chạy, luồng được thay đổi thành 4, 6, 8 và 10, như thể hiện trong biểu đồ sau.
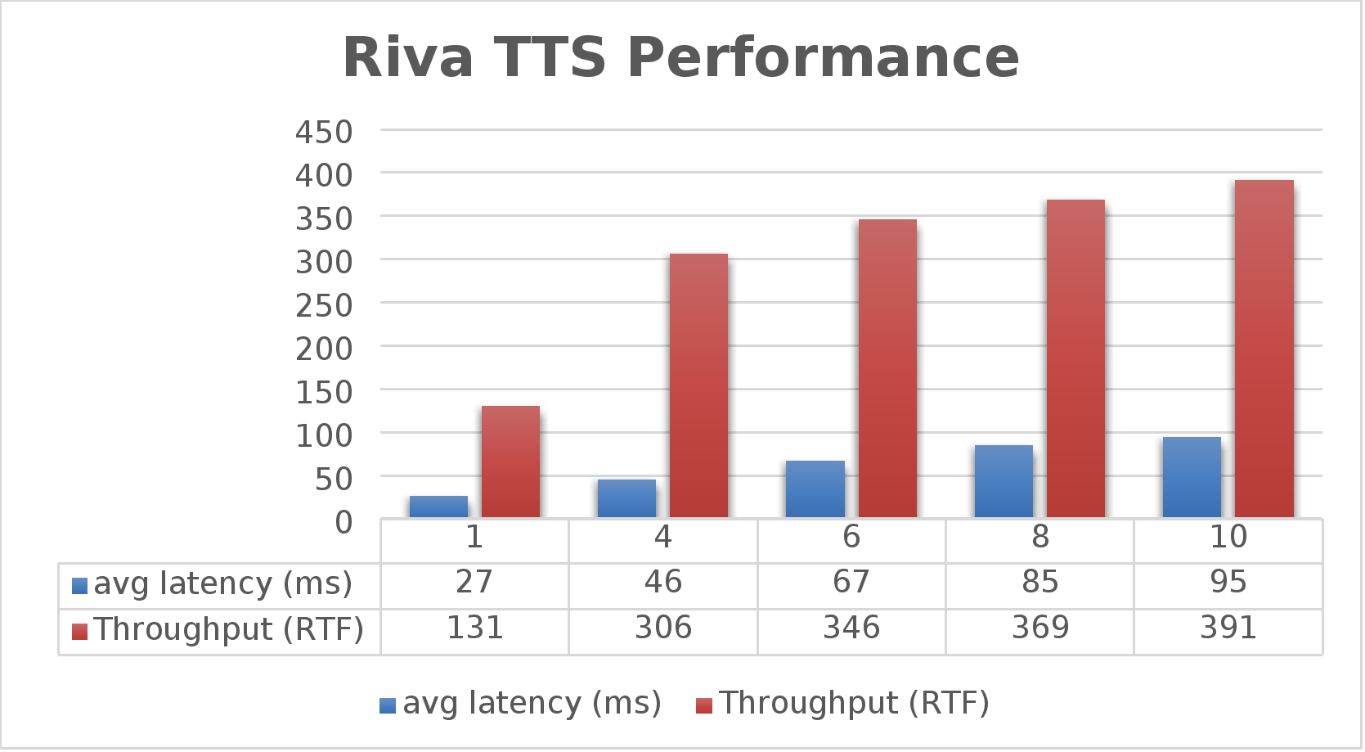 Hình 2. Hiệu suất NVIDIA Riva TTS
Hình 2. Hiệu suất NVIDIA Riva TTS
Một lần nữa, mục tiêu là có độ trễ trung bình thấp với thông lượng cao. Thông lượng (RTFX) trong trường hợp này là thời lượng âm thanh được tạo ra chia cho thời gian tính toán. Như chúng ta có thể thấy, điều này dẫn đến thông lượng RTFX là 391 với độ trễ là 91ms với mười luồng. Cũng đáng lưu ý rằng trong quá trình thử nghiệm, mức sử dụng GPU là khoảng 82% mà không có tình trạng tắc nghẽn lưu trữ.
Đây là rất nhiều dữ liệu để đưa vào một áp phích. May mắn thay, nhóm Kỹ thuật Giải pháp Dell PowerFlex đã tạo ra một kiến trúc được xác thực, nêu chi tiết cách thức đạt được tất cả các kết quả này và cách một tổ chức có thể sao chép chúng nếu cần.
Bây giờ, để đưa tất cả những điều này vào đúng bối cảnh, với PowerFlex, bạn có thể đạt được kết quả tuyệt vời về cả ngôn ngữ nói khi đưa vào tổ chức của mình và chuyển đổi văn bản thành giọng nói. Kết hợp khả năng này với một số công cụ AI tạo sinh khác (genAI), như NVIDIA NeMo , và bạn có thể tạo ra một số hệ thống khéo léo cho tổ chức của mình.
Ví dụ, nếu một mô hình ASR được ghép nối với một mô hình ngôn ngữ lớn (LLM) cho một bộ phận trợ giúp, người dùng có thể đặt câu hỏi bằng lời nói và—khi tìm thấy câu trả lời—nó có thể sử dụng TTS để hỗ trợ họ. Hãy nghĩ xem điều đó có thể có ý nghĩa gì đối với các tổ chức.
Thật ngạc nhiên khi một tấm áp phích đơn giản có thể chứa đựng nhiều thông tin và khả năng đến vậy. Nếu bạn quan tâm đến việc tìm hiểu thêm về nghiên cứu mà Dell PowerFlex đã thực hiện với NVIDIA Riva, hãy đến tham dự Tiệc chiêu đãi Poster tại NVIDIA GTC vào Thứ Hai, ngày 18 tháng 3 từ 4:00 đến 6:00 chiều. Nếu bạn không thể tham gia tiệc chiêu đãi poster, poster sẽ được trưng bày trên khắp NVIDIA GTC. Nếu bạn không thể tham dự GTC, hãy xem sách trắng ,và liên hệ với đại diện Dell của bạn để biết thêm thông tin.
Bài viết mới cập nhật
Đẩy nhanh đổi mới AI: Máy chủ mới và giải pháp giá đỡ tích hợp cho tương lai
Sau những thông báo thú vị tại Ngày AI tiên tiến ...
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...