
Tin tức
Triển khai Microsoft SQL Server Big Data Clusters trên nền tảng Kubernetes bằng PowerFlex
Giới thiệu
Microsoft SQL Server 2019 đã giới thiệu một nền tảng dữ liệu đột phá với SQL Server 2019 Big Data Clusters (BDC). Microsoft SQL Server Big Data Clusters được thiết kế để giải quyết thách thức về dữ liệu lớn mà hầu hết các tổ chức hiện nay đang phải đối mặt. Bạn có thể sử dụng SQL Server BDC để sắp xếp và phân tích khối lượng dữ liệu lớn, bạn cũng có thể kết hợp dữ liệu quan hệ có giá trị cao với dữ liệu lớn. Bài đăng trên blog này mô tả việc triển khai SQL Server BDC trên nền tảng Kubernetes bằng cách sử dụng bộ lưu trữ được xác định bằng phần mềm Dell EMC PowerFlex.
Điện năng linh hoạt
Dell EMC PowerFlex (trước đây là VxFlex OS) là nền tảng phần mềm của lưu trữ được xác định bằng phần mềm PowerFlex. Đây là giải pháp lưu trữ và mạng tính toán hợp nhất cung cấp dịch vụ lưu trữ khối mở rộng được thiết kế để mang lại sự linh hoạt, đàn hồi và đơn giản với hiệu suất cao có thể dự đoán và khả năng phục hồi ở quy mô lớn.
Nền tảng PowerFlex có nhiều tùy chọn tiêu thụ để giúp khách hàng đáp ứng các yêu cầu về dự án và trung tâm dữ liệu của họ. Thiết bị PowerFlex và giá đỡ PowerFlex cung cấp cho khách hàng Quản lý hoạt động CNTT (ITOM) toàn diện và quản lý vòng đời (LCM) của toàn bộ ngăn xếp cơ sở hạ tầng ngoài các dịch vụ lưu trữ hiệu suất cao, có khả năng mở rộng và phục hồi tinh vi. Thiết bị PowerFlex và giá đỡ PowerFlex là các tùy chọn tiêu thụ được ưa chuộng và tiếp thị chủ động. PowerFlex cũng có sẵn trên VxFlex Ready Nodes dành cho những khách hàng quan tâm đến phần cứng tuân thủ được xác định bằng phần mềm mà không có khả năng ITOM và LCM.
Lưu trữ được xác định bằng phần mềm PowerFlex với tính toán và mạng thống nhất cung cấp tính linh hoạt của kiến trúc triển khai để giúp đáp ứng tốt nhất các yêu cầu triển khai và kiến trúc cụ thể. PowerFlex có thể được triển khai trong hai lớp để mở rộng không đối xứng tính toán và lưu trữ cho “năng lực đúng kích cỡ, lớp đơn (HCI) hoặc trong kiến trúc hỗn hợp.
Tổng quan về cụm dữ liệu lớn của Microsoft SQL Server
Microsoft SQL Server Big Data Clusters được thiết kế để giải quyết các thách thức về dữ liệu lớn theo một cách độc đáo, BDC giải quyết nhiều thách thức truyền thống thông qua việc xây dựng môi trường dữ liệu lớn và hồ dữ liệu. Bạn có thể truy vấn các nguồn dữ liệu bên ngoài, lưu trữ dữ liệu lớn trong HDFS do SQL Server quản lý hoặc truy vấn dữ liệu từ nhiều nguồn dữ liệu bên ngoài bằng cách sử dụng cụm.
SQL Server Big Data Clusters là một tính năng bổ sung của Microsoft SQL Server 2019. Bạn có thể truy vấn các nguồn dữ liệu ngoài, lưu trữ dữ liệu lớn trong HDFS do SQL Server quản lý hoặc truy vấn dữ liệu từ nhiều nguồn dữ liệu ngoài bằng cách sử dụng cụm.
Để biết thêm thông tin, hãy xem trang Đối tác cụm dữ liệu lớn SQL Server của Microsoft .
Bạn có thể sử dụng SQL Server Big Data Clusters để triển khai các cụm có khả năng mở rộng của SQL Server và Apache Spark TM và Hadoop Distributed File System (HDFS), dưới dạng các container chạy trên Kubernetes.
Để biết tổng quan về Microsoft SQL Server 2019 Big Data Clusters, hãy xem Giới thiệu về SQL Server Big Data Clusters của Microsoft và trên GitHub, hãy xem Workshop: SQL Server Big Data Clusters – Architecture .
Triển khai nền tảng Kubernetes trên PowerFlex
Đối với thử nghiệm này, PowerFlex 3.6.0 được xây dựng theo cấu hình hai lớp với sáu nút Compute Only (CO) và tám nút Storage Only (SO). Chúng tôi đã sử dụng PowerFlex Manager để tự động cung cấp cụm PowerFlex với các nút CO trên VMware vSphere 7.0 U2 và các nút SO với Red Hat Enterprise Linux 8.2.
Hình sau đây cho thấy kiến trúc logic của SQL Server BDC trên nền tảng Kubernetes với PowerFlex.
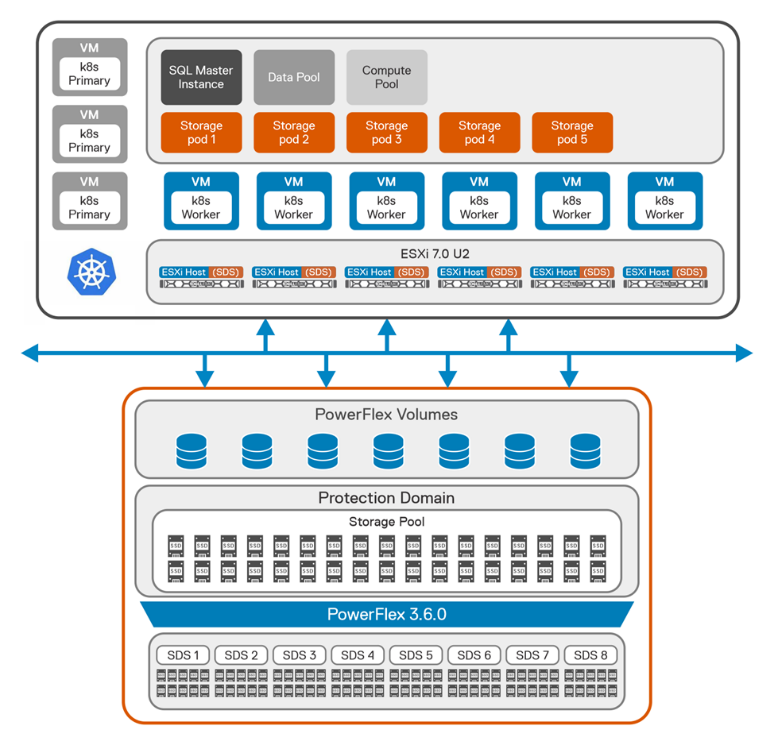
Hình 1: Kiến trúc logic của SQL BDC trên PowerFlex
Về mặt lưu trữ, chúng tôi đã tạo một miền bảo vệ duy nhất từ tám nút PowerFlex cho SQL BDC. Sau đó, chúng tôi đã tạo một nhóm lưu trữ duy nhất bằng cách sử dụng tất cả các ổ SSD được cài đặt trong mỗi nút là thành viên của miền bảo vệ.
Sau khi triển khai cụm PowerFlex, chúng tôi đã tạo mười một máy ảo trên sáu nút CO giống hệt nhau với Ubuntu 20.04 trên đó, như thể hiện trong bảng sau.
Bảng 1: Máy ảo cho các nút CO
| Mục | Nút 1 | Nút 2 | Nút 3 | Nút 4 | Nút 5 | Nút 6 |
| Nút vật lý | esxi70-1 | esxi70-2 | esxi70-3 | esxi70-4 | esxi70-5 | esxi70-6 |
| Thông số kỹ thuật H/W | 2 x Intel Gold 6242 R, 20 lõi, RAM 768 GB |
2 x Intel Gold 6242R, 20 lõi 768 768 GB RAM |
2 x Intel Gold 6242R, 20 lõi 768 768 GB RAM |
2 x Intel Gold 6242R, 20 lõi 768 768 GB RAM |
2 x Intel Gold 6242R, 20 lõi 768 768 GB RAM |
2 x Intel Gold 6242R, 20 lõi 768 768 GB RAM |
| Máy ảo | k8w1 72 vCPU/512 GB Đĩa khởi động: 250 250 GB |
lb01 8 vCPU/16 Đĩa khởi động GB : 16 16 GB |
lb02 8 vCPU/16 Đĩa khởi động GB : 16 16 GB |
k8m1 8 vCPU/16 Đĩa khởi động GB : 40 40 GB |
k8m2 8 vCPU/16 Đĩa khởi động GB : 40 40 GB |
k8m3 8 vCPU/16 Đĩa khởi động GB : 40 40 GB |
| k8w2 56 vCPU/512 Đĩa khởi động GB : 250 GB |
k8w3 56v CPU/512 Đĩa khởi động GB : 250 GB |
k8w4 56 vCPU/512 Đĩa khởi động GB : 250 GB |
k8w5 56 vCPU/512 Đĩa khởi động GB : 250 GB |
k8w6 56 vCPU/512 Đĩa khởi động GB : 250 GB |
Chúng tôi đã cài đặt thủ công thành phần SDC của PowerFlex trên các nút worker của Kubernetes. Sau đó, chúng tôi đã cấu hình một cụm Kubernetes (v 1.20) trên các máy ảo với ba nút master và tám nút worker:
$ kubectl lấy các nút
TÊN TRẠNG THÁI CHỨC VỤ TUỔI PHIÊN BẢN
k8m1 Sẵn sàng điều khiển mặt phẳng,master 10d v1.20.10
k8m2 Sẵn sàng điều khiển mặt phẳng,master 10d v1.20.10
k8m3 Sẵn sàng điều khiển mặt phẳng,master 10d v1.20.10
k8w1 Sẵn sàng <không có> 10d v1.20.10
k8w2 Sẵn sàng <không có> 10d v1.20.10
k8w3 Sẵn sàng <không có> 10d v1.20.10
k8w4 Sẵn sàng <không có> 10d v1.20.10
k8w5 Sẵn sàng <không có> 10d v1.20.10
k8w6 Sẵn sàng <không có> 10d v1.20.10
Giải pháp lưu trữ Dell EMC cung cấp các plugin CSI cho phép khách hàng cung cấp lưu trữ liên tục cho các ứng dụng dựa trên container ở quy mô lớn. Sự kết hợp của hệ thống điều phối Kubernetes và plugin Dell EMC PowerFlex CSI cho phép cung cấp dễ dàng các container và lưu trữ liên tục.
Trong giải pháp, sau khi chúng tôi cài đặt cụm Kubernetes, CSI 2.0 đã được cung cấp để kích hoạt các ổ đĩa liên tục cho khối lượng công việc SQL BDC.
Để biết thêm thông tin về các tính năng được PowerFlex CSI hỗ trợ,xem Tài liệu trình điều khiển Dell CSI .
Để biết thêm thông tin về cài đặt PowerFlex CSI bằng biểu đồ Helm, hãy xem Tài liệu PowerFlex CSI .
Triển khai Microsoft SQL Server BDC trên nền tảng Kubernetes
Khi cụm Kubernetes với CSI đã sẵn sàng, Azure data CLI được cài đặt trên máy khách. Để tạo tệp cấu hình cơ sở cho việc triển khai, hãy xem triển khai Cụm dữ liệu lớn trên Kubernetes . Đối với giải pháp này, chúng tôi đã sử dụng kubeadm-dev-test làm nguồn cho mẫu cấu hình.
Ban đầu, khi sử dụng kubectl , mỗi nút được gắn nhãn để đảm bảo các pod bắt đầu ở đúng nút:
$ kubectl nhãn nút k8w1 mssql-cluster=bdc mssql-resource=bdc-master –overwrite=true
$ kubectl nhãn nút k8w2 mssql-cluster=bdc mssql-resource=bdc-compute-pool –overwrite=true
$ kubectl nhãn nút k8w3 mssql-cluster=bdc mssql-resource=bdc-compute-pool –overwrite=true
$ kubectl nhãn nút k8w4 mssql-cluster=bdc mssql-resource=bdc-compute-pool –overwrite=true
$ kubectl nhãn nút k8w5 mssql-cluster=bdc mssql-resource=bdc-compute-pool –overwrite=true
$ kubectl nhãn nút k8w6 mssql-cluster=bdc mssql-resource=bdc-compute-pool –overwrite=true
Để đẩy nhanh quá trình triển khai BDC, chúng tôi khuyên bạn nên sử dụng phương pháp cài đặt ngoại tuyến từ sổ đăng ký riêng cục bộ. Mặc dù điều này có nghĩa là phải làm thêm một số công việc trong việc tạo và cấu hình sổ đăng ký, nhưng nó sẽ loại bỏ tải mạng của mọi máy chủ BDC kéo hình ảnh container từ kho lưu trữ Microsoft. Thay vào đó, chúng được kéo một lần. Trên máy chủ hoạt động như sổ đăng ký riêng, hãy cài đặt Docker và bật kho lưu trữ Docker.
Cấu hình BDC được sửa đổi từ các thiết lập mặc định để sử dụng tài nguyên cụm và giải quyết các yêu cầu về khối lượng công việc. Để biết hướng dẫn đầy đủ về việc sửa đổi các thiết lập này, hãy xem phần Tùy chỉnh triển khai trong trang web Microsoft BDC. Để mở rộng nhóm tài nguyên BDC, số lượng bản sao được điều chỉnh để sử dụng tài nguyên của cụm.
Các giá trị hiển thị trong bảng sau được điều chỉnh trong tệp bdc.json.
Bảng 2: Tài nguyên cụm
| Nguồn | Bản sao | Sự miêu tả |
| nmnode-0 | 2 | Cổng Apache Knox |
| đầu tia lửa | 2 | Cấu hình tài nguyên dịch vụ Spark |
| người trông coi sở thú | 3 | Theo dõi các nút trong cụm |
| tính toán-0 | 1 | Nhóm tính toán |
| dữ liệu-0 | 1 | Nhóm dữ liệu |
| lưu trữ-0 | 5 | Bể chứa |
Các giá trị cấu hình để chạy Spark và Apache Hadoop YARN cũng được điều chỉnh theo tài nguyên tính toán khả dụng cho mỗi nút. Trong cấu hình này, kích thước dựa trên 768 GB RAM và 72 lõi CPU ảo khả dụng cho mỗi nút PowerFlex CO. Hầu hết cấu hình này được ước tính và điều chỉnh dựa trên khối lượng công việc. Trong trường hợp này, chúng tôi giả định rằng các nút công nhân được dành riêng để chạy khối lượng công việc Spark . Nếu các nút công nhân đang thực hiện các hoạt động hoặc khối lượng công việc khác, bạn có thể cần điều chỉnh các giá trị này. Bạn cũng có thể ghi đè các giá trị Spark làm tham số công việc.
Để biết thêm hướng dẫn về cài đặt cấu hình cho Apache Spark và Apache Hadoop trong Big Data Clusters, hãy xem phần Cấu hình Apache Spark & Apache Hadoop trong phần tài liệu SQL Server BDC.
Bảng sau đây nêu bật các thiết lập spark được sử dụng trên cụm SQL Server BDC.
Bảng 3: Cài đặt Spark
| Cài đặt | Giá trị |
| spark-defaults-conf.spark.executor.memoryChi phí chung | 484 |
| trang web sợi.yarn.nodemanager.resource.memory-mb | 440000 |
| trang web yarn.yarn.nodemanager.resource.cpu-vcores | 50 |
| yarn-site.yarn.scheduler.phân bổ tối đa-mb | 54614 |
| yarn-site.yarn.scheduler.maximum-allocation-vcores | 6 |
| yarn-site.yarn.scheduler.capacity.maximum-am-tài nguyên-phần trăm | 0,34 |
Ghi chú phát hành SQL Server BDC 2019 CU12 nêu rằng Kubernetes API 1.20 được hỗ trợ. Do đó, đối với thử nghiệm này, hình ảnh được triển khai trên SQL master pod là 2019-CU12-ubuntu-16.04. Dung lượng lưu trữ 20 TB đã được cung cấp cho SQL master pod, với 10 TB làm không gian nhật ký:
“nodeLabel”: “bdc-master”,
“kho”: {
“dữ liệu”: {
“className”: “vxflexos-xfs”,
“accessMode”: “Đọc-Ghi-Một-Lần”,
“kích thước”: “20Ti”
},
“nhật ký”: {
“className”: “vxflexos-xfs”,
“accessMode”: “Đọc-Ghi-Một-Lần”,
“kích thước”: “10Ti”
}
}
Vì thử nghiệm liên quan đến việc chạy khối lượng công việc TPC-DS nên chúng tôi đã cung cấp tổng cộng 60 TB dung lượng cho năm nhóm lưu trữ:
“lưu trữ-0”: {
“metadata”: {
“loại”: “Bể bơi”,
“tên”: “mặc định”
},
“đặc tả”: {
“loại”: “Lưu trữ”,
“bản sao”: 5,
“cài đặt”: {
“tia lửa”: {
“includeSpark”: “đúng”
}
},
“nodeLabel”: “bdc-compute-pool”,
“kho”: {
“dữ liệu”: {
“className”: “vxflexos-xfs”,
“accessMode”: “Đọc-Ghi-Một-Lần”,
“kích thước”: “12Ti”
},
“nhật ký”: {
“className”: “vxflexos-xfs”,
“accessMode”: “Đọc-Ghi-Một-Lần”,
“kích thước”: “4Ti”
}
}
}
}
Xác thực SQL Server BDC trên PowerFlex
Để xác thực cấu hình của Big Data Cluster đang chạy trên PowerFlex và để kiểm tra khả năng mở rộng của nó, chúng tôi đã chạy khối lượng công việc TPC-DS trên cụm bằng bộ công cụ Databricks ® TPC-DS Spark SQL. Bộ công cụ này cho phép bạn gửi toàn bộ khối lượng công việc TPC-DS dưới dạng tác vụ Spark tạo ra tập dữ liệu thử nghiệm và chạy một loạt các truy vấn phân tích trên đó. Vì khối lượng công việc này chạy hoàn toàn bên trong nhóm lưu trữ của SQL Server Big Data Cluster, nên môi trường đã được mở rộng để chạy tối đa năm nhóm lưu trữ được khuyến nghị.
Chúng tôi đã chỉ định một pod lưu trữ cho mỗi nút công nhân trong môi trường Kubernetes như thể hiện trong hình sau.
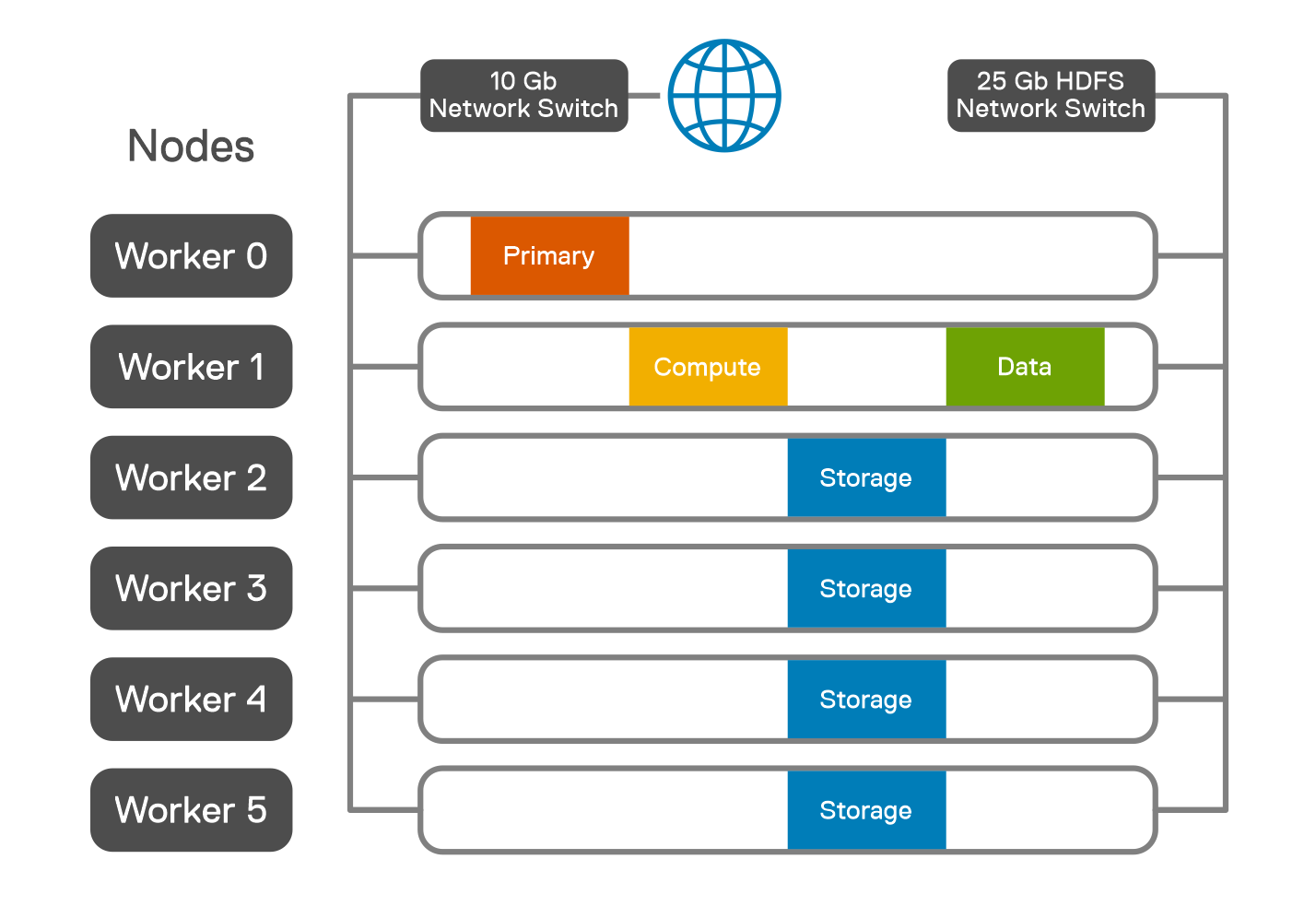
Hình 2: Vị trí pod trên các nút công nhân
Trong giải pháp này, khối lượng công việc Spark SQL TPC-DS được áp dụng để mô phỏng môi trường cơ sở dữ liệu mô phỏng một số khía cạnh áp dụng của hệ thống hỗ trợ quyết định, bao gồm các truy vấn và bảo trì dữ liệu. Được đặc trưng bởi tải CPU và I/O cao, khối lượng công việc hỗ trợ quyết định đặt tải lên cấu hình cụm SQL Server BDC để khai thác hiệu quả hoạt động tối đa trong các lĩnh vực sử dụng CPU, bộ nhớ và I/O. Kết quả chuẩn được đo bằng thời gian phản hồi truy vấn và thông lượng truy vấn.
Tệp Spark JAR được tải lên thư mục được chỉ định trong HDFS, ví dụ: /tpcds. Spark-submit được thực hiện bởi CURL, sử dụng máy chủ Livy là một phần của Microsoft SQL Server Big Data Cluster.
Sử dụng bộ Databricks TPC-DS Spark SQL, khối lượng công việc được chạy dưới dạng các tác vụ Spark cho khối lượng công việc 1 TB, 5 TB, 10 TB và 30 TB. Đối với mỗi khối lượng công việc, chỉ có kích thước của tập dữ liệu được thay đổi.
Các thông số được sử dụng cho từng công việc được nêu trong bảng sau.
Bảng 4: Các tham số công việc
| Tham số | Giá trị |
| spark-defaults-conf.spark.driver.cores | 4 |
| spark-defaults-conf.spark.driver.memory | 8G |
| spark-defaults-conf.spark.driver.memoryChi phí chung | 484 |
| spark-defaults-conf.spark.driver.maxResultSize | 16g |
| spark-defaults-conf.spark.executor.instances | 12 |
| spark-defaults-conf.spark.executor.cores | 4 |
| spark-defaults-conf.spark.executor.memory | 36768 mét |
| spark-defaults-conf.spark.executor.memoryChi phí chung | 384 |
| spark.sql.sortMergeJoinExec.buffer.in.memory.threshold | 10000000 |
| spark.sql.sortMergeJoinExec.buffer.spill.threshold | 60000000 |
| spark.shuffle.spill.numElementsForceSpillThreshold | 59000000 |
| spark.sql.autoBroadcastJoinThreshold | 20971520 |
| spark-defaults-conf.spark.sql.cbo.enabled | ĐÚNG VẬY |
| spark-defaults-conf.spark.sql.cbo.joinReorder.enabled | ĐÚNG VẬY |
| trang web sợi.yarn.nodemanager.resource.memory-mb | 440000 |
| trang web yarn.yarn.nodemanager.resource.cpu-vcores | 50 |
| yarn-site.yarn.scheduler.phân bổ tối đa-mb | 54614 |
| yarn-site.yarn.scheduler.maximum-allocation-vcores | 6 |
Chúng tôi thiết lập tập dữ liệu TPC-DS với các hệ số tỷ lệ khác nhau trong lệnh CURL. Dữ liệu được đưa trực tiếp vào nhóm lưu trữ HDFS của SQL Server Big Data Cluster.
Hình sau đây cho thấy thời gian tiêu tốn để tạo dữ liệu của các thiết lập hệ số tỷ lệ khác nhau. Thời gian tạo dữ liệu cũng bao gồm quá trình phân tích dữ liệu sau khi tính toán số liệu thống kê bảng.
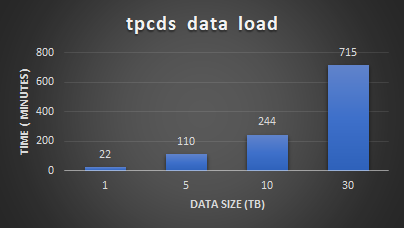
Hình 3: Tạo dữ liệu TPC-DS
Sau khi tải, chúng tôi chạy khối lượng công việc TPC-DS để xác thực hiệu suất và khả năng mở rộng của Spark SQL với 99 truy vấn người dùng được xác định trước. Các truy vấn được mô tả bằng các mẫu người dùng khác nhau.
Hình sau đây cho thấy kết quả kiểm tra hiệu suất và khả năng mở rộng. Kết quả chứng minh rằng chạy Microsoft SQL Server Big Data Cluster trên PowerFlex có khả năng mở rộng tuyến tính cho các tập dữ liệu khác nhau. Điều này cho thấy khả năng của PowerFlex trong việc cung cấp hiệu suất nhất quán và có thể dự đoán được cho các loại khối lượng công việc Spark SQL khác nhau.
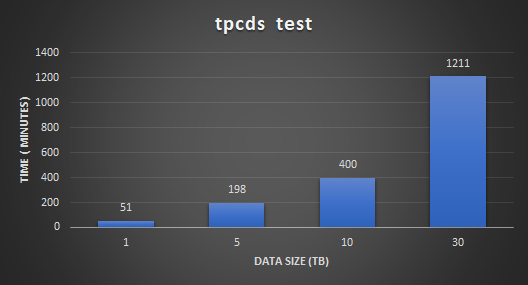
Hình 4: Kết quả thử nghiệm TPC-DS
Một trường hợp bảng điều khiển Grafana được chụp trong quá trình chạy 30 TB của thử nghiệm TPC-DS được hiển thị trong hình sau. Hình cho thấy băng thông đọc đạt được là 15 GB/giây trong quá trình thử nghiệm.
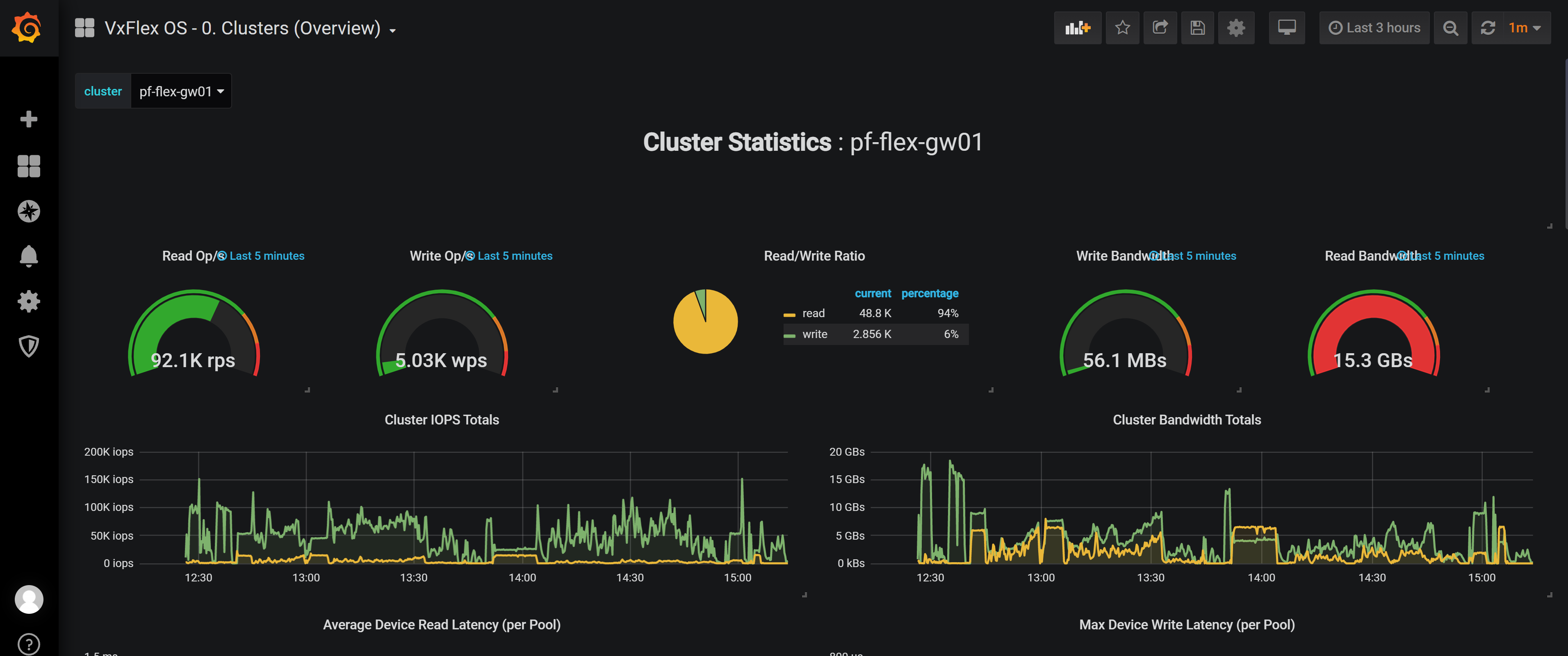
Hình 5: Bảng điều khiển Grafana
Trong phần cứng phòng thí nghiệm tối thiểu này, không có tình trạng tắc nghẽn lưu trữ đối với tải dữ liệu TPC-DS và thực hiện truy vấn. CPU trên các nút công nhân đạt gần 90 phần trăm, cho thấy các nút mạnh hơn có thể nâng cao hiệu suất.
Phần kết luận
Chạy SQL Server Big Data Clusters trên PowerFlex là một cách đơn giản để bắt đầu với khối lượng công việc dữ liệu lớn hiện đại chạy trên Kubernetes. Giải pháp này cho phép bạn chạy khối lượng công việc container hiện đại bằng cách sử dụng cơ sở hạ tầng và quy trình CNTT hiện có. Big Data Clusters cho phép các nhà khoa học dữ liệu lớn đổi mới và xây dựng với sự nhanh nhẹn của Kubernetes, trong khi quản trị viên CNTT quản lý khối lượng công việc an toàn trong môi trường vSphere quen thuộc của họ.
Trong giải pháp này, Microsoft SQL Server Big Data Clusters được triển khai trên PowerFlex, cung cấp hoạt động đơn giản hóa để phục vụ khối lượng công việc gốc trên nền tảng đám mây và có thể mở rộng mà không cần thỏa hiệp. Quản trị viên CNTT có thể triển khai các chính sách cho không gian tên và quản lý quyền truy cập và phân bổ hạn ngạch cho quản lý tập trung vào ứng dụng. Quản lý tập trung vào ứng dụng giúp bạn xây dựng cơ sở hạ tầng sẵn sàng cho nhà phát triển với Kubernetes cấp doanh nghiệp, cung cấp khả năng quản trị, độ tin cậy và bảo mật tiên tiến.
Microsoft SQL Server Big Data Clusters cũng được sử dụng với khối lượng công việc Spark SQL TPC-DS với các tham số được tối ưu hóa. Kết quả thử nghiệm cho thấy Microsoft SQL Server Big Data Clusters được triển khai trong môi trường PowerFlex có thể cung cấp nền tảng phân tích mạnh mẽ cho các giải pháp Big Data ngoài các hoạt động kiểu kho dữ liệu.
Bài viết mới cập nhật
Đẩy nhanh đổi mới AI: Máy chủ mới và giải pháp giá đỡ tích hợp cho tương lai
Sau những thông báo thú vị tại Ngày AI tiên tiến ...
Thuần hóa sự hỗn loạn của công nghệ: Giải pháp phục hồi sáng tạo của Dell
Sự cố CNTT nghiêm trọng ảnh hưởng đến 8,5 triệu hệ ...
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...