
Nếu lịch sử dạy cho chúng ta điều gì đó, thì đó là thảm họa luôn rình rập và có xu hướng xuất hiện dưới mọi hình thức khi chúng ta ít ngờ tới nhất.
Để vượt qua những hoàn cảnh này, chúng ta cần những công cụ và công nghệ phù hợp có thể đảm bảo hoạt động trở lại bình thường một cách an toàn, tự động và kịp thời.
Các quy trình phục hồi thảm họa (DR) truyền thống thường phức tạp và đòi hỏi đầu tư cơ sở hạ tầng đáng kể. Chúng cũng đòi hỏi nhiều nhân công và dễ xảy ra lỗi của con người.
Kể từ tháng 12 năm 2020, tình hình đã thay đổi. Nhờ bản phát hành mới của Microsoft Azure Stack HCI, phiên bản 20H2 , chúng ta có thể tận dụng tính năng cụm kéo dài Azure Stack HCI mới trên Hệ thống tích hợp Dell EMC cho Microsoft Azure Stack HCI (Azure Stack HCI).
Hệ thống tích hợp này dựa trên nền tảng là nhóm nút AX linh hoạt của chúng tôi và kết hợp quản lý vòng đời đầy đủ của Dell Technologies với hệ điều hành Microsoft Azure Stack HCI.
Điều quan trọng cần lưu ý là công nghệ này chỉ khả dụng cho hệ thống tích hợp được cung cấp theo danh mục Azure Stack HCI được chứng nhận.
Azure Stack HCI stretch clustering cung cấp giải pháp dễ dàng và tự động (không cần tương tác của con người nếu muốn) đảm bảo chuyển đổi dự phòng minh bạch các khối lượng công việc sản xuất bị ảnh hưởng bởi thảm họa sang một địa điểm thứ cấp an toàn.
Nó cũng có thể được sử dụng để thực hiện các hoạt động theo kế hoạch (như di chuyển toàn bộ địa điểm hoặc tránh thảm họa) mà cho đến nay vẫn đòi hỏi nhiều nhân lực và dễ xảy ra lỗi khi thực hiện.
Phân cụm kéo dài là một loại cấu hình Storage Replica . Nó cho phép khách hàng chia một cụm duy nhất giữa hai vị trí—phòng, tòa nhà, thành phố hoặc khu vực. Nó cung cấp sao chép đồng bộ hoặc không đồng bộ các ổ đĩa Storage Spaces Direct để cung cấp khả năng chuyển đổi dự phòng VM tự động nếu xảy ra thảm họa tại địa điểm.
Có hai cấu trúc khác nhau:
- Chủ động-Thụ động: Tất cả các ứng dụng và khối lượng công việc chạy trên trang web chính (ưu tiên) trong khi cơ sở hạ tầng tại trang web phụ vẫn ở trạng thái nhàn rỗi cho đến khi xảy ra sự cố chuyển đổi dự phòng.
- Hoạt động-Hoạt động: Có các ứng dụng hoạt động ở cả hai trang web tại bất kỳ thời điểm nào và sao chép diễn ra theo hai hướng từ cả hai trang web. Thiết lập này có xu hướng sử dụng hiệu quả hơn khoản đầu tư của tổ chức vào cơ sở hạ tầng vì tài nguyên ở cả hai trang web đều được sử dụng.
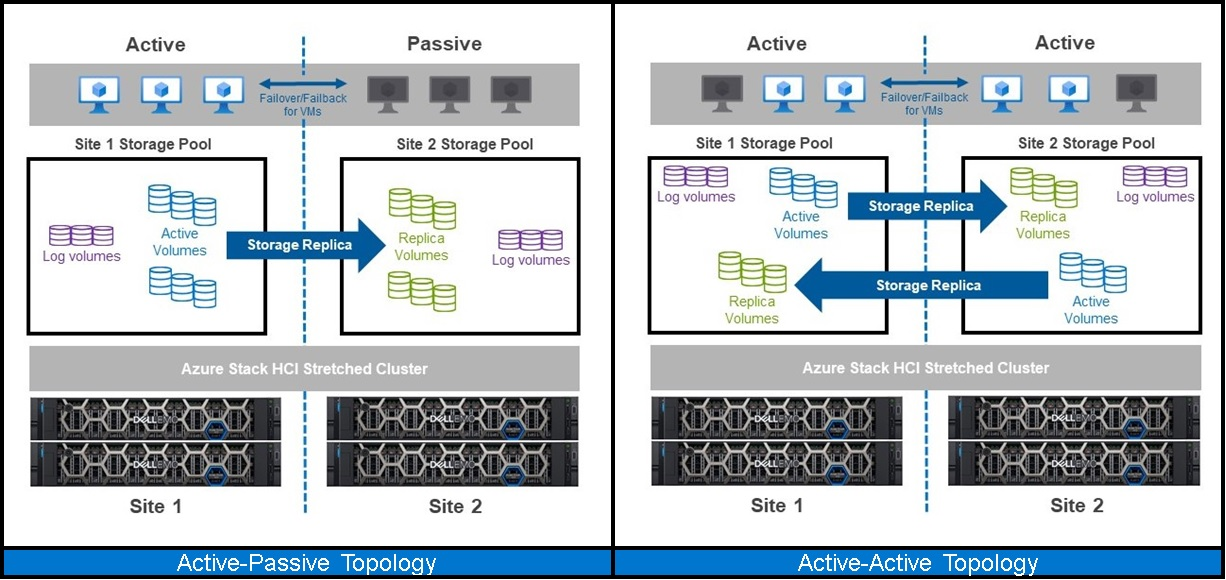
Các cấu trúc cụm phân cụm kéo dài Azure Stack HCI: Chủ động-Thụ động và Chủ động-Chủ động
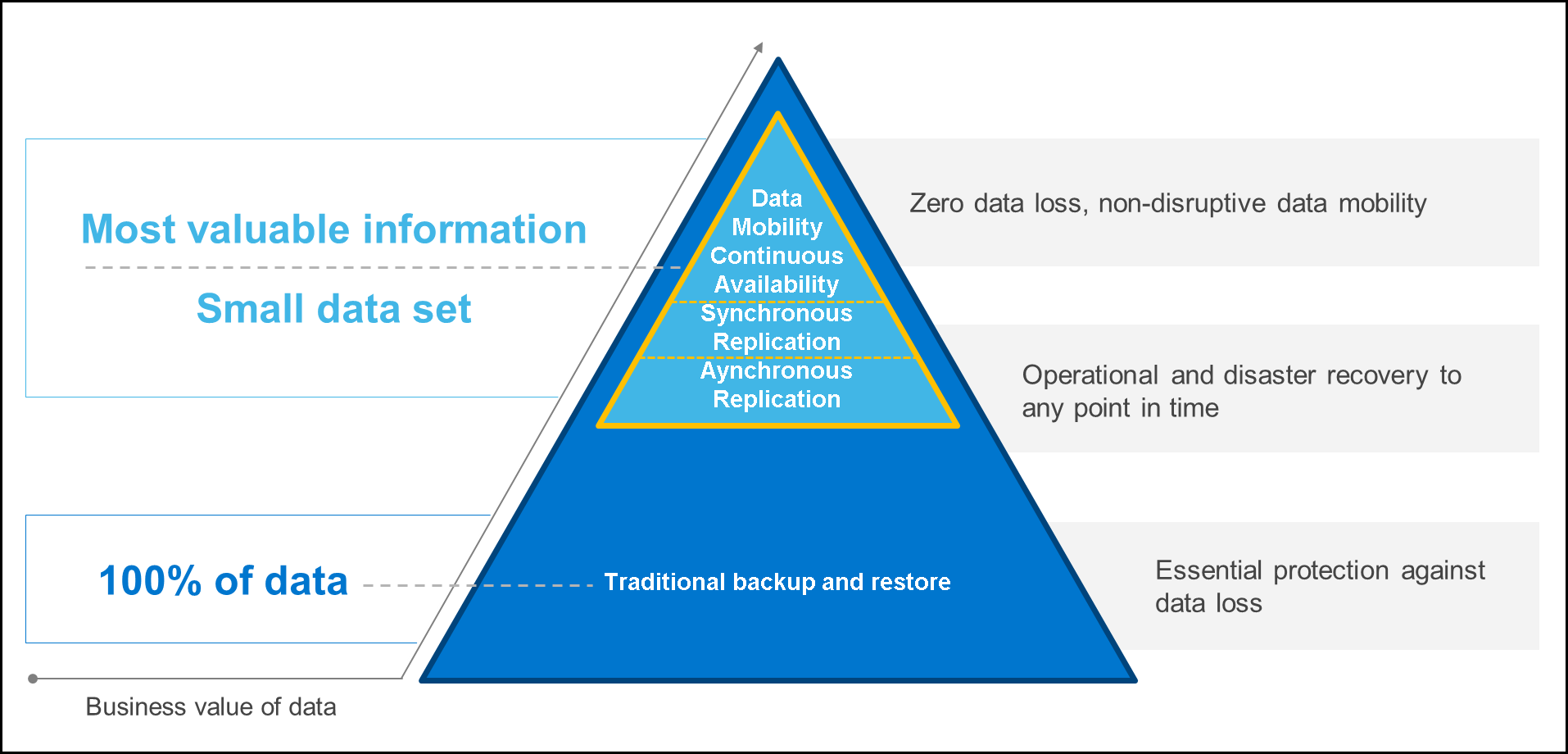
Để thực sự tiết kiệm chi phí, các chiến lược bảo vệ dữ liệu tốt nhất phải kết hợp nhiều công nghệ khác nhau (sao lưu loại bỏ trùng lặp, lưu trữ, sao chép dữ liệu, tính liên tục của hoạt động kinh doanh và tính di động của khối lượng công việc) để mang lại mức độ bảo vệ dữ liệu phù hợp cho từng ứng dụng kinh doanh.
Sơ đồ sau đây làm nổi bật thực tế rằng chỉ một tập dữ liệu thu gọn mới chứa thông tin có giá trị nhất. Đây là điểm lý tưởng cho phân cụm kéo dài.
Để có trải nghiệm thực tế, các chuyên gia Dell Technologies của chúng tôi đã thử nghiệm cụm mở rộng Azure Stack HCI trong thiết lập phòng thí nghiệm sau:
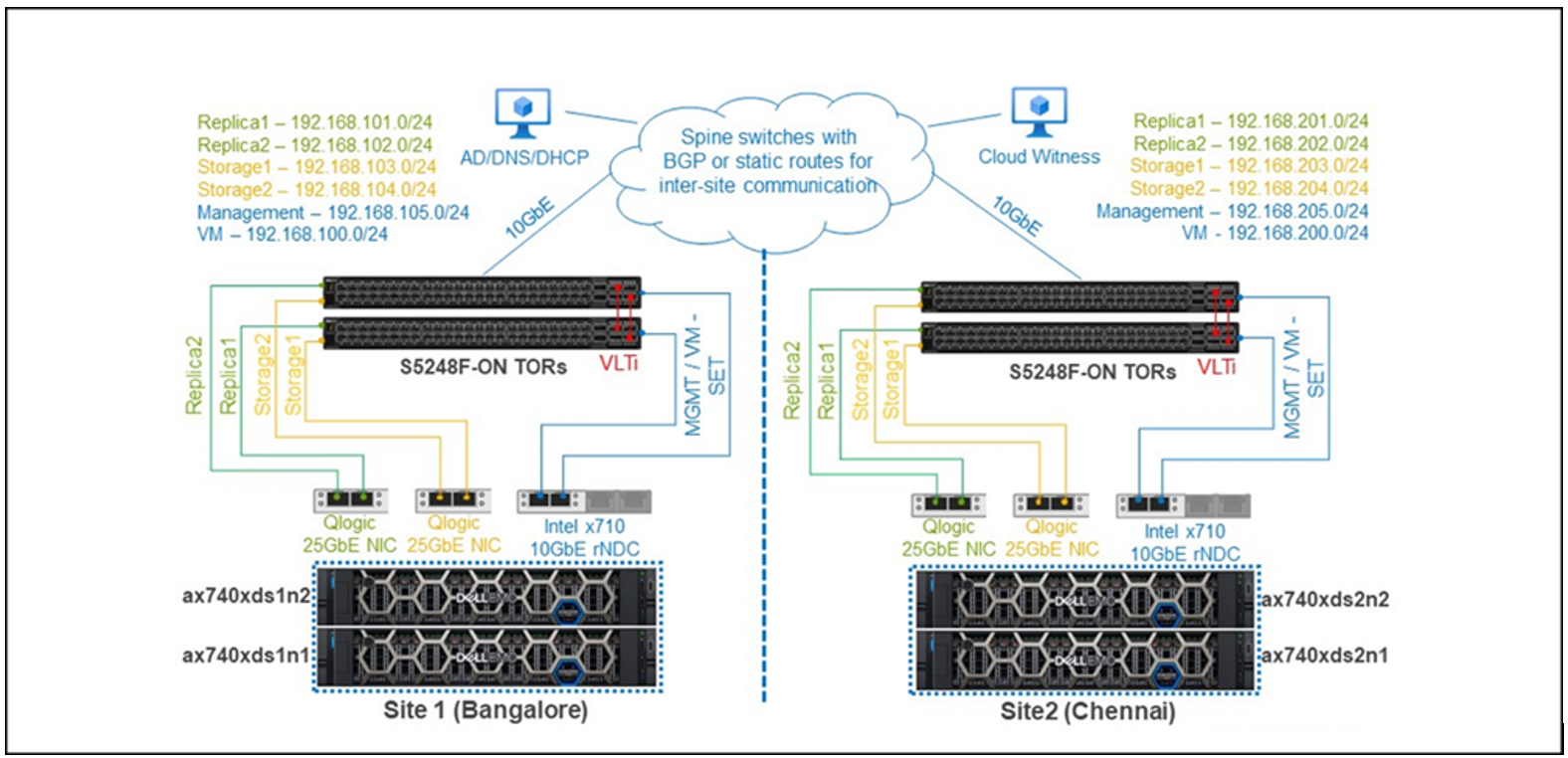
Cấu trúc mạng cụm phòng thí nghiệm thử nghiệm
Lưu ý những cân nhắc quan trọng sau đây liên quan đến kiến trúc mạng phòng thí nghiệm:
- Bản sao lưu trữ, quản lý và mạng VM trong mỗi site là các mạng con Lớp 3 duy nhất. Trong Active Directory, chúng tôi đã cấu hình hai site—Bangalore (Site 1) và Chennai (Site 2)—dựa trên các mạng con IP này để các site chính xác xuất hiện trong Failover Cluster Manager khi cấu hình cụm kéo dài. Không cần cấu hình thủ công bổ sung nào cho các miền lỗi cụm.
- Độ trễ trung bình giữa hai vị trí này nhỏ hơn 5 mili giây, độ trễ cần thiết cho quá trình sao chép đồng bộ.
- Các nút cụm có thể đạt được chứng kiến chia sẻ tệp trong yêu cầu độ trễ khứ hồi tối đa 200 mili giây.
- Các mạng con ở cả hai trang web đều có thể truy cập tới máy chủ Active Directory, DNS và DHCP.
- Mạng được xác định bằng phần mềm (SDN) trên cụm đa địa điểm hiện không được hỗ trợ và không được sử dụng cho thử nghiệm này.
Để biết thêm chi tiết, hãy xem sách trắng này: Thêm tính linh hoạt cho các kế hoạch DR với Stretch Clustering cho Azure Stack HCI.
Tuy nhiên, trong bài viết này, tôi chỉ muốn tập trung vào việc tóm tắt các kết quả chúng tôi thu được trong phòng thí nghiệm cho bốn tình huống sau:
- Tình huống 1: Lỗi nút không được lên kế hoạch
- Tình huống 2: Sự cố trang web không mong muốn
- Kịch bản 3: Chuyển đổi dự phòng
- Kịch bản 4: Quản lý vòng đời
| Kịch bản | Sự kiện | Sự kiện bảo trì hoặc lỗi mô phỏng | Cụm kéo dài
phản ứng mong đợi |
Cụm kéo dài
phản ứng thực tế |
| 1 | Lỗi nút không mong muốn | Nút 1 trong Site 1 bị tắt nguồn | Các máy ảo bị ảnh hưởng phải chuyển sang một nút cục bộ khác | Trong khoảng 5 phút, tất cả 10 VM ở Node 1 Site 1 đều khởi động lại hoàn toàn ở Node 2 Site 1.
Đây là hành vi dự kiến vì Site 1 đã được cấu hình là site ưu tiên; nếu không, ổ đĩa đang hoạt động có thể đã được chuyển đến Site 2 và các VM sẽ được khởi động lại trên một nút cụm trong Site 2. |
| 2 | Sự cố tại Site 1 | Tắt nguồn đồng thời các nút 1 và 2 tại vị trí 1 | Các VM bị ảnh hưởng phải chuyển sang các nút trên trang web thứ cấp | Trong vòng 25 phút, tất cả các máy ảo đã được khởi động lại và ứng dụng web đi kèm đã phản hồi hoàn toàn.
Các ổ đĩa do các nút ở Site 2 sở hữu vẫn trực tuyến trong suốt tình huống lỗi này.
Các khối bản sao vẫn ngoại tuyến cho đến khi Site 1 được khôi phục hoàn toàn. Khi Site 1 hoạt động trở lại, quá trình sao chép đồng bộ lại bắt đầu từ các ổ đĩa nguồn ở Site 2 đến các đối tác bản sao đích ở Site 1. |
| 3 | Kế hoạch chuyển đổi dự phòng | Thao tác chuyển hướng trên ổ đĩa từ Trung tâm quản trị Windows | Các VM và khối lượng công việc được chọn phải được di chuyển một cách minh bạch đến trang web thứ cấp | Trong vòng từ 0 đến 3 phút, ứng dụng do các VM bị ảnh hưởng lưu trữ có thể truy cập được mà không bị gián đoạn dịch vụ (thời gian tùy thuộc vào việc có yêu cầu chỉ định lại IP hay không).
Đầu tiên, nút chủ sở hữu cho các ổ đĩa được thay đổi thành Nút 2 trong Site 2 và nút chủ sở hữu cho các ổ đĩa bản sao được thay đổi thành Nút 2 trong Site 1. Không có gián đoạn dịch vụ. Vào thời điểm này, VM thử nghiệm đang chạy ở Site 1, nhưng đĩa ảo của nó nằm trên ổ đĩa đang chạy ở Site 2. Các vấn đề về hiệu suất có thể xảy ra do I/O đang đi qua các liên kết sao chép giữa các site. Sau khoảng 10 phút, Live Migration của VM thử nghiệm sẽ tự động diễn ra (nếu không được khởi tạo thủ công trước đó) để VM sẽ ở cùng một nút với đĩa ảo của nó. |
| 4 | Quản lý vòng đời | Cập nhật tất cả các nút trong cụm bằng cách sử dụng Cập nhật nhận biết cụm toàn bộ ngăn xếp một lần nhấp (CAU) trong Trung tâm quản trị Windows | Cụm kéo dài và CAU phải hoạt động liền mạch với nhau để cung cấp bản cập nhật cụm ngăn xếp đầy đủ mà không làm gián đoạn dịch vụ và tính di động khối lượng công việc chỉ cục bộ cho các VM được Di chuyển Trực tiếp | Toàn bộ quá trình áp dụng hệ điều hành và bản cập nhật chương trình cơ sở cho cụm mở rộng mất khoảng 3 giờ và không ảnh hưởng đến ứng dụng.
Mỗi nút đã được rút hết tài nguyên và các VM của nó được di chuyển trực tiếp đến nút khác trong cùng một trang web. Các liên kết liên trang web giữa Site 1 và Site 2 không bao giờ được sử dụng trong quá trình cập nhật. Ngoài ra, quy trình chỉ yêu cầu khởi động lại một lần cho mỗi nút. Hành vi này luôn nhất quán trong suốt quá trình cập nhật tất cả các nút trong cụm kéo dài. |
Tóm lại, Azure Stack HCI Stretch Clustering đã được chứng minh là hoạt động như mong đợi trong những trường hợp khó khăn. Nó có thể dễ dàng được tận dụng để bao phủ nhiều tình huống bảo vệ dữ liệu, chẳng hạn như:
- khôi phục CNTT của tổ chức bạn trong vòng vài phút sau một sự kiện không mong muốn
- di chuyển khối lượng công việc đang chạy giữa các địa điểm một cách minh bạch để tránh thảm họa sắp xảy ra hoặc các hoạt động đã lên kế hoạch khác
- tự động chuyển sang chế độ lỗi VM và khối lượng công việc của từng nút bị lỗi
Công nghệ này có thể tạo ra sự khác biệt giúp các doanh nghiệp tự động phục hồi sau thảm họa, một bước ngoặt hoàn toàn trong lĩnh vực phục hồi thảm họa tự động.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...