
Tin tức
Các giải pháp sẵn sàng của Dell EMC cho Bộ lưu trữ hiệu suất cao HPC BeeGFS
Giới thiệu
Nhóm Dell EMC HPC tự hào công bố việc phát hành “Dell EMC Ready Solutions for HPC BeeGFS Storage”, đây là phần bổ sung mới nhất cho danh mục lưu trữ HPC. Giải pháp này sử dụng các máy chủ R740xd, mỗi máy chủ có 24x Intel P4600 1.6TB NVMe, ổ đĩa Flash Tốc hành Sử dụng Hỗn hợp và hai bộ điều hợp Mellanox ConnectX-5 InfiniBand EDR. Trong cấu hình ổ 24 NVMe này, 12 ổ SSD NVMe kết nối với bộ chuyển mạch PCIe và mỗi bộ chuyển mạch được kết nối với một CPU thông qua thẻ mở rộng x16 PCIe. Hơn nữa, mỗi giao diện IB được kết nối với một CPU. Một cấu hình cân bằng như vậy với mỗi CPU được kết nối với một bộ điều hợp InfiniBand và xử lý 12 ổ SSD NVMe mang lại hiệu suất tối đa bằng cách đảm bảo rằng các bộ xử lý được phân bổ như nhau trong việc xử lý các yêu cầu I/O đến và từ các ổ NVMe.
Trọng tâm của giải pháp là I/O hiệu suất cao và nó đã được thiết kế như một giải pháp cào tốc độ cao. Điểm cốt lõi của giải pháp là việc sử dụng SSD NVMe tốc độ cao cung cấp băng thông rất cao và độ trễ thấp bằng cách loại bỏ nút cổ chai của bộ lập lịch và hàng đợi khỏi lớp khối. Hệ thống tệp BeeGFS cũng hỗ trợ thông lượng I/O tổng hợp cao
Kiến trúc tham khảo giải pháp
Hình 1 cho thấy cấu trúc tham chiếu của giải pháp. Máy chủ quản lý chỉ được kết nối qua Ethernet với máy chủ lưu trữ và siêu dữ liệu. Mỗi siêu dữ liệu và máy chủ lưu trữ có hai liên kết InfiniBand và được kết nối với mạng riêng qua Ethernet. Các máy khách có một liên kết InfiniBand và được kết nối với giao diện riêng qua Ethernet.

Hình 1: Các giải pháp sẵn sàng của Dell EMC cho Bộ lưu trữ HPC BeeGFS – Kiến trúc tham khảo
Cấu hình phần cứng và phần mềm
Bảng 1 và 2 lần lượt mô tả các thông số kỹ thuật phần cứng của máy chủ quản lý và máy chủ lưu trữ/siêu dữ liệu. Bảng 3 mô tả các phiên bản phần mềm được sử dụng cho giải pháp.
| Bảng 1 Cấu hình PowerEdge R640 (Máy chủ quản lý) | |
|---|---|
| Người phục vụ | Dell EMC PowerEdge R640 |
| bộ vi xử lý | 2x Intel Xeon Gold 5218 2,3 GHz, 16 lõi |
| Trí nhớ | 12 x 8GB DIMM DDR4 2666MT/s – 96GB |
| đĩa cục bộ | 6 ổ cứng 300GB 15K RPM SAS 2.5in |
| Bộ điều khiển RAID | Bộ điều khiển RAID tích hợp PERC H740P |
| Quản lý ngoài băng tần | iDRAC9 Enterprise với Bộ điều khiển vòng đời |
| nguồn điện | Bộ cấp nguồn kép 1100W |
| Phiên bản sinh học | 2.2.11 |
| Hệ điều hành | CentOS™ 7.6 |
| Phiên bản hạt nhân | 3.10.0-957.27.2.el7.x86_64 |
| Bảng 2 Cấu hình PowerEdge R740xd (Siêu dữ liệu và Máy chủ lưu trữ) | |
|---|---|
| Người phục vụ | Dell EMC PowerEdge R740xd |
| bộ vi xử lý | 2x CPU Intel Xeon Platinum 8268 @ 2.90GHz, 24 lõi |
| Trí nhớ | 12 x 32GB DIMM DDR4 2933MT/s – 384GB |
| Thẻ BOSS | 2 ổ SSD M.2 240GB M.2 trong RAID 1 cho hệ điều hành |
| Ổ đĩa cục bộ | 24x Dell Express Flash NVMe P4600 1.6TB 2.5″ U.2 |
| Thẻ Mellanox EDR | 2x thẻ Mellanox ConnectX-5 EDR (Khe 1 & 8) |
| Quản lý ngoài băng tần | iDRAC9 Enterprise với Bộ điều khiển vòng đời |
| nguồn điện | Bộ cấp nguồn kép 2000W |
| Bảng 3 Cấu hình phần mềm (Siêu dữ liệu và Máy chủ lưu trữ) | |
|---|---|
| BIOS | 2.2.11 |
| CPLD | 1.1.3 |
| Hệ điều hành | CentOS™ 7.6 |
| Phiên bản hạt nhân | 3.10.0-957.el7.x86_64 |
| iDRAC | 3.34.34.34 |
| Công cụ quản lý hệ thống | Quản trị viên máy chủ OpenManage 9.3.0-3407_A00 |
| Mellanox OFED | 4.5-1.0.1.0 |
| SSD NVMe | QDV1DP13 |
| *Công cụ Trung tâm Dữ liệu Intel ® | 3.0.19 |
| BeeGFS | 7.1.3 |
| Grafana | 6.3.2 |
| InfluxDB | 1.7.7 |
| Điểm chuẩn IOzone | 3.487 |
*Đối với cập nhật Quản lý và Chương trình cơ sở của SSD Intel P4600NVMe
Chi tiết cấu hình giải pháp
Kiến trúc BeeGFS bao gồm bốn dịch vụ chính:
- Dịch vụ quản lý
- Dịch vụ siêu dữ liệu
- Dịch vụ lưu trữ
- Dịch vụ khách hàng
Ngoại trừ dịch vụ máy khách là mô-đun hạt nhân, các dịch vụ quản lý, siêu dữ liệu và lưu trữ là các quy trình không gian người dùng. Hình 2 minh họa cách kiến trúc tham chiếu của Giải pháp Dell EMC Ready cho Bộ lưu trữ HPC BeeGFS ánh xạ tới kiến trúc chung của hệ thống tệp BeeGFS.

Hình 2 : Hệ thống tệp BeeGFS trên PowerEdge R740xd với SSD NVMe
Dịch vụ quản lý
Mỗi hệ thống tệp hoặc không gian tên BeeGFS chỉ có một dịch vụ quản lý. Dịch vụ quản lý là dịch vụ đầu tiên cần được thiết lập vì khi chúng ta cấu hình tất cả các dịch vụ khác, chúng cần phải đăng ký với dịch vụ quản lý. PowerEdge R640 được sử dụng làm máy chủ quản lý. Ngoài việc lưu trữ dịch vụ quản lý ( beegfs-mgmtd.ser vice ), nó còn lưu trữ dịch vụ giám sát ( beegfs-mon.service ) thu thập số liệu thống kê từ hệ thống và cung cấp chúng cho người dùng, sử dụng cơ sở dữ liệu chuỗi thời gian InfluxDB . Để trực quan hóa dữ liệu, beegfs-mon cung cấp Grafana được xác định trướctấm có thể được sử dụng ra khỏi hộp. Máy chủ quản lý có 6 ổ cứng 300 GB được định cấu hình trong RAID 10 cho Hệ điều hành và InfluxDB.
Dịch vụ siêu dữ liệu
Dịch vụ siêu dữ liệu là dịch vụ mở rộng quy mô, có nghĩa là có thể có nhiều dịch vụ siêu dữ liệu trong hệ thống tệp BeeGFS. Tuy nhiên, mỗi dịch vụ siêu dữ liệu có chính xác một mục tiêu siêu dữ liệu để lưu trữ siêu dữ liệu. Trên mục tiêu siêu dữ liệu, BeeGFS tạo một tệp siêu dữ liệu cho mỗi tệp do người dùng tạo. Siêu dữ liệu BeeGFS được phân phối trên cơ sở từng thư mục. Dịch vụ siêu dữ liệu cung cấp thông tin tách dữ liệu cho khách hàng và không liên quan đến việc truy cập dữ liệu giữa mở/đóng tệp.
PowerEdge R740xd với 24x Intel P4600 1.6TB NVMe, ổ đĩa được sử dụng để lưu trữ siêu dữ liệu. Do các yêu cầu về dung lượng lưu trữ cho siêu dữ liệu BeeGFS là rất nhỏ nên thay vì sử dụng máy chủ siêu dữ liệu chuyên dụng, chỉ có 12 ổ đĩa trên NUMA vùng 0 được sử dụng để lưu trữ M eta D ata Target (MDT), trong khi 12 ổ đĩa còn lại trên máy chủ lưu trữ vùng NUMA lưu trữ T arget ( ST). Hình 3 cho thấy máy chủ siêu dữ liệu. 12 ổ nằm trong hình chữ nhật màu vàng là các MDT trong vùng NUMA 0 trong khi 12 ổ nằm trong hình chữ nhật màu xanh lá cây là các ST trong vùng NUMA 1. Cấu hình này không chỉ tránh các sự cố NUMA mà còn cung cấp đủ dung lượng lưu trữ siêu dữ liệu để tạo điều kiện mở rộng quy mô năng lực và hiệu suất theo yêu cầu.

Hình 3: Máy chủ siêu dữ liệu
Hình 4 cho thấy cấu hình đột kích của máy chủ siêu dữ liệu. Nó làm nổi bật cách thức trong máy chủ siêu dữ liệu, các ổ đĩa trong vùng NUMA 0 lưu trữ các MDT và những ổ đĩa trong vùng NUMA 1 lưu trữ dữ liệu lưu trữ, trong khi các máy chủ lưu trữ lưu trữ các ST trong cả hai vùng NUMA.
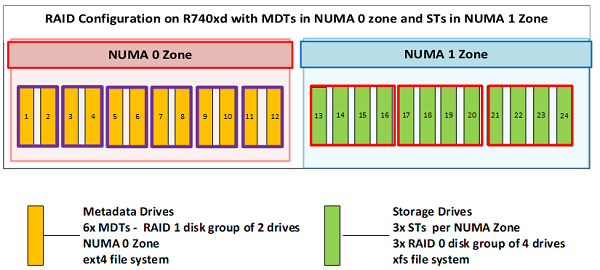
Hình 4: Cấu hình các ổ đĩa trong Máy chủ siêu dữ liệu
12 ổ đĩa được sử dụng cho siêu dữ liệu được cấu hình thành 6x RAID 1 nhóm đĩa gồm 2 ổ đĩa, mỗi ổ đóng vai trò là một MDT. Có 6 dịch vụ siêu dữ liệu đang chạy, mỗi dịch vụ xử lý một MDT. 12 ổ lưu trữ còn lại được cấu hình trong nhóm đĩa 3x RAID 0, mỗi nhóm 4 ổ. Có ba dịch vụ lưu trữ chạy trên vùng NUMA 1, một dịch vụ cho mỗi ST. Vì vậy, máy chủ đồng lưu trữ siêu dữ liệu và Mục tiêu lưu trữ có 6 MDT và 3 ST. Nó cũng chạy 6 dịch vụ siêu dữ liệu và ba dịch vụ lưu trữ. Mỗi MDT là một hệ thống tệp ext4 dựa trên cấu hình RAID 1. Các ST dựa trên hệ thống tệp XFS được định cấu hình trong RAID 0.
Dịch vụ lưu trữ
Giống như dịch vụ siêu dữ liệu, dịch vụ lưu trữ cũng là dịch vụ mở rộng quy mô. Có thể có nhiều phiên bản của dịch vụ lưu trữ trong hệ thống tệp BeeGFS. Tuy nhiên, không giống như dịch vụ siêu dữ liệu, có thể có một số mục tiêu lưu trữ cho mỗi dịch vụ lưu trữ. Dịch vụ lưu trữ lưu trữ nội dung tệp người dùng sọc, còn được gọi là tệp khối dữ liệu
Hình 5 cho thấy máy chủ 5x PowerEdge R740xd được sử dụng làm máy chủ lưu trữ.

Hình 5: Các máy chủ lưu trữ chuyên dụng
Mỗi máy chủ lưu trữ được cấu hình với 6 nhóm RAID 0, mỗi nhóm 4 ổ đĩa, do đó lưu trữ 6 ST trên mỗi máy chủ (3 ST trên mỗi vùng NUMA), như minh họa trong Hình 6 dưới đây:
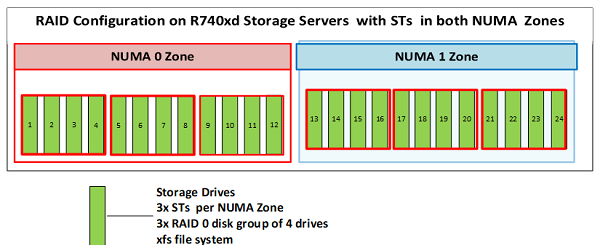
Hình 6: Cấu hình các ổ đĩa trong máy chủ lưu trữ
Tổng cộng, cấu hình kiến trúc tham chiếu cơ sở lưu trữ 6 MDT và 33 ST. Có năm máy chủ lưu trữ chuyên dụng cung cấp dung lượng thô là 211 TB và dung lượng khả dụng là 190TiB. Dung lượng có thể sử dụng ước tính tính bằng TiB = Số ổ x dung lượng mỗi ổ tính bằng TB x 0,99 (chi phí hệ thống tệp) x (10^12/2^40). Đây sẽ là một giải pháp lý tưởng với tư cách là một giải pháp sơ bộ tầm trung với đủ dung lượng lưu trữ siêu dữ liệu để tạo điều kiện bổ sung thêm nhiều máy chủ lưu trữ khi yêu cầu về dung lượng tăng lên.
Theo quan điểm của các yếu tố sau, cấu hình RAID 0 đã được chọn cho mục tiêu lưu trữ thay vì cấu hình RAID 10.
- Hiệu suất ghi được đo bằng lệnh dd bằng cách tạo tệp 10GiB có kích thước khối 1MiB và I/O trực tiếp cho dữ liệu, đối với thiết bị RAID 0, tốc độ trung bình là khoảng 5,1 GB/giây cho mỗi thiết bị trong khi đối với thiết bị RAID 10, tốc độ ghi trung bình là 3,4 GB/giây s cho từng thiết bị.
- Các bài kiểm tra điểm chuẩn của StorageBench cho thấy thông lượng tối đa là 5,5 GB/giây đối với cấu hình RAID 0 trong khi đó là 3,4 GB/giây đối với cấu hình RAID 10. Những kết quả này giống như kết quả thu được khi sử dụng lệnh dd.
- RAID 10 cung cấp khả năng sử dụng 50% dung lượng đĩa và giảm 50% hiệu suất ghi tương tự. Sử dụng RAID 10 là một cách tốn kém để có được dự phòng lưu trữ.
- Ổ đĩa NVMe đắt tiền và cung cấp khả năng tăng tốc được sử dụng tốt nhất trong cấu hình RAID 0
- Ổ đĩa thể rắn Intel P4600 được sử dụng trong cấu hình này rất đáng tin cậy với D aily W rites P er D ay (DWPD) là 3, nghĩa là một người có thể ghi 4,8 TB dữ liệu vào đó mỗi ngày trong 5 năm tới.
Dịch vụ khách hàng
Mô-đun máy khách BeeGFS cần được tải lên tất cả các máy chủ cần truy cập hệ thống tệp BeeGFS. Khi beegfs-client được tải, nó sẽ gắn các hệ thống tệp được xác định trong tệp /etc/beegfs/beegfs-mounts.conf thay vì cách tiếp cận thông thường dựa trên /etc/fstab . Việc áp dụng phương pháp này sẽ khởi động beegfs-client giống như bất kỳ dịch vụ Linux nào khác thông qua tập lệnh khởi động dịch vụ. Nó cũng cho phép tự động biên dịch lại mô-đun máy khách BeeGFS sau khi cập nhật hệ thống. Khi mô-đun máy khách được tải, nó sẽ gắn các hệ thống tệp được xác định trong beegfs-mounts.conf . Có thể gắn nhiều phiên bản beegfs trên cùng một máy khách như hình bên dưới:
$ cat /etc/beegfs/beegfs-mounts.conf
/mnt/beegfs-medium /etc/beegfs/beegfs-client-medium.conf
/mnt/beegfs-small /etc/beegfs/beegfs-client-small.conf
Ví dụ trên cho thấy hai hệ thống tệp khác nhau được gắn trên cùng một máy khách. Với mục đích của thử nghiệm này, 32 nút C6420 đã được sử dụng làm máy khách.
R740xd, Ổ đĩa NVMe 24x, Chi tiết về ánh xạ CPU
Trong cấu hình 24xNVMe của máy chủ PowerEdge R740xd, có hai thẻ cầu nối x16 NVMe cấp nguồn cho công tắc PCIe trên bảng nối đa năng để quạt ra và cấp nguồn cho các ổ đĩa (ổ đĩa là x4) ở phía trước như trong Hình 7 bên dưới:
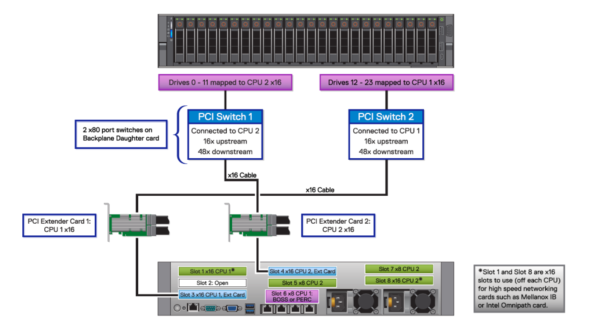
Hình 7: R740xd, Chi tiết NVMe 24x trên ánh xạ CPU
Trong Truy cập bộ nhớ không đồng nhất (NUMA), bộ nhớ hệ thống được chia thành các vùng được gọi là nút, được phân bổ cho CPU hoặc ổ cắm. Truy cập vào bộ nhớ cục bộ của CPU nhanh hơn bộ nhớ được kết nối với các CPU từ xa trên hệ thống. Một ứng dụng theo luồng thường hoạt động tốt nhất khi các luồng đang truy cập bộ nhớ trên cùng một nút NUMA. Tác động hiệu suất của các lần bỏ lỡ NUMA là đáng kể, thường bắt đầu từ mức hiệu suất 10% trở lên. Để cải thiện hiệu suất, các dịch vụ được định cấu hình để sử dụng các vùng NUMA cụ thể nhằm tránh việc sử dụng không cần thiết các liên kết ổ cắm chéo UPI, do đó giảm độ trễ. Mỗi vùng NUMA xử lý 12 ổ đĩa và sử dụng một trong hai giao diện InfiniBand EDR trên máy chủ. Việc tách NUMA này đạt được bằng cách định cấu hình cân bằng NUMA theo cách thủ công bằng cách tạo các tệp đơn vị systemd tùy chỉnh và bằng cách định cấu hìnhnhiều nhà . Do đó, tính năng cân bằng NUMA tự động bị tắt, như minh họa bên dưới:
# mèo /proc/sys/kernel/numa_balancing
0
Hình 8 hiển thị nền thử nghiệm nơi kết nối InfiniBand với vùng NUMA được làm nổi bật. Mỗi máy chủ có hai liên kết IP và lưu lượng truy cập qua vùng NUMA 0 được truyền bởi giao diện IB0 trong khi lưu lượng truy cập qua vùng NUMA 1 được xử lý bởi giao diện IB1.
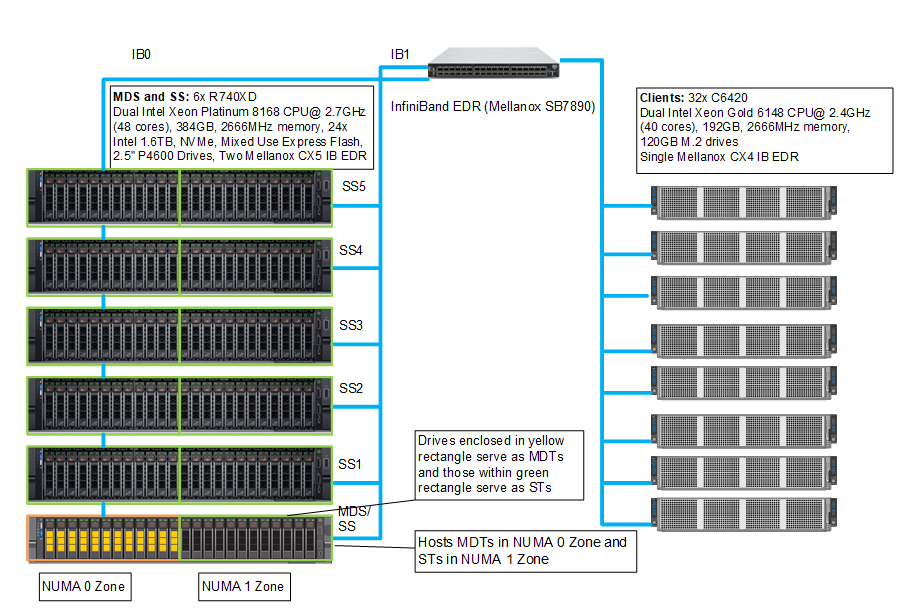
Hình 8: Cấu hình thử nghiệm
Đặc tính hiệu suất
Phần này trình bày đánh giá hiệu suất giúp mô tả Giải pháp Dell EMC Ready cho Giải pháp lưu trữ hiệu suất cao HPC BeeGFS. Để biết thêm chi tiết và cập nhật, vui lòng tìm sách trắng sẽ được xuất bản sau. Hiệu suất hệ thống được đánh giá bằng cách sử dụng điểm chuẩn IOzone . Giải pháp được kiểm tra về thông lượng đọc và ghi tuần tự cũng như IOPS đọc và ghi ngẫu nhiên. Bảng 4 mô tả cấu hình của các máy chủ C6420 được sử dụng làm ứng dụng khách BeeGFS cho các nghiên cứu về hiệu suất được trình bày trong blog này.
| Bảng 4 Cấu hình máy khách | |
|---|---|
| khách hàng | 32 nút tính toán Dell EMC PowerEdge C6420 |
| BIOS | 2.2.9 |
| bộ vi xử lý | 2x CPU Intel Xeon Gold 6148 @ 2.40GHz với 20 lõi trên mỗi bộ xử lý |
| Trí nhớ | 12 x 16GB DIMM DDR4 2666 MT/s – 192GB |
| Thẻ BOSS | 2x ổ đĩa khởi động M.2 120GB trong RAID 1 cho HĐH |
| Hệ điều hành | Red Hat Enterprise Linux Server phát hành 7.6 |
| Phiên bản hạt nhân | 3.10.0-957.el7.x86_64 |
| kết nối | 1x thẻ Mellanox ConnectX-4 EDR |
| Phiên bản OFED | 4.5-1.0.1.0 |
Đọc và ghi tuần tự NN
Để đánh giá các lần đọc và ghi tuần tự, điểm chuẩn IOzone đã được sử dụng ở chế độ đọc và ghi tuần tự. Các thử nghiệm này được tiến hành trên nhiều số lượng luồng bắt đầu từ 1 luồng và tăng dần theo lũy thừa của 2, tối đa 1024 luồng. Tại mỗi lần đếm luồng, số lượng tệp bằng nhau được tạo do thử nghiệm này hoạt động trên một tệp trên mỗi luồng hoặc trường hợp N máy khách tới N tệp (NN). Các quy trình được phân phối trên 32 nút máy khách vật lý theo kiểu vòng tròn hoặc theo chu kỳ để các yêu cầu được phân bổ đồng đều và có cân bằng tải. Kích thước tệp tổng hợp là 8TB đã được chọn, được chia đều cho số lượng chuỗi trong bất kỳ thử nghiệm cụ thể nào. Kích thước tệp tổng hợp được chọn đủ lớn để giảm thiểu ảnh hưởng của bộ nhớ đệm từ máy chủ cũng như từ máy khách BeeGFS. IOzone được chạy ở chế độ ghi rồi đọc kết hợp (-i 0, -i 1) để cho phép nó phối hợp ranh giới giữa các hoạt động. Đối với thử nghiệm và kết quả này, chúng tôi đã sử dụng kích thước bản ghi 1MiB cho mỗi lần chạy. Các lệnh được sử dụng cho các bài kiểm tra NN tuần tự được đưa ra dưới đây:
Đọc và ghi tuần tự: iozone -i 0 -i 1 -c -e -w -r 1m -I -s $Size -t $Thread -+n -+m /path/to/threadlist
Bộ đệm của hệ điều hành cũng bị loại bỏ hoặc làm sạch trên các nút máy khách giữa các lần lặp lại cũng như giữa các lần kiểm tra ghi và đọc bằng cách chạy lệnh:
# sync && echo 3 > /proc/sys/vm/drop_caches
Số lượng sọc mặc định cho Beegfs là 4. Tuy nhiên, kích thước khối và số lượng mục tiêu trên mỗi tệp có thể được định cấu hình trên cơ sở từng thư mục. Đối với tất cả các thử nghiệm này, kích thước sọc BeeGFS được chọn là 2 MB và số sọc được chọn là 3 vì chúng tôi có ba mục tiêu trên mỗi vùng NUMA như hình bên dưới:
$ beegfs-ctl –getentryinfo –mount=/mnt/beegfs /mnt/beegfs/benchmark –verbose
EntryID: 0-5D9BA1BC-1
ParentID: gốc
Nút siêu dữ liệu: nút001-numa0-4 [ID: 4]
Chi tiết mẫu sọc :
+ Loại: RAID0
+ Kích thước khối: 2M
+ Số mục tiêu lưu trữ: mong muốn: 3
+ Nhóm lưu trữ: 1 (Mặc định)
Đường dẫn hàm băm inode: 7/5E/0-5D9BA1BC-1
Các trang lớn trong suốt đã bị vô hiệu hóa và các tùy chọn điều chỉnh sau được áp dụng trên siêu dữ liệu và máy chủ lưu trữ:
- vm.dirty_background_ratio = 5
- vm.dirty_ratio = 20
- vm.min_free_kbytes = 262144
- vm.vfs_cache_pressure = 50
- vm.zone_reclaim_mode = 2
- kernel.numa_balancing = 0
Ngoài những điều trên, các tùy chọn điều chỉnh BeeGFS sau đây đã được sử dụng:
- thông số tuneTargetChooser được đặt thành ” roundrobin ” trong tệp cấu hình siêu dữ liệu
- tham số tuneNumWorkers được đặt thành 24 cho siêu dữ liệu và 32 cho bộ nhớ
- Tham số connMaxInternodeNum được đặt thành 32 cho siêu dữ liệu và 12 cho bộ nhớ và 24 cho máy khách
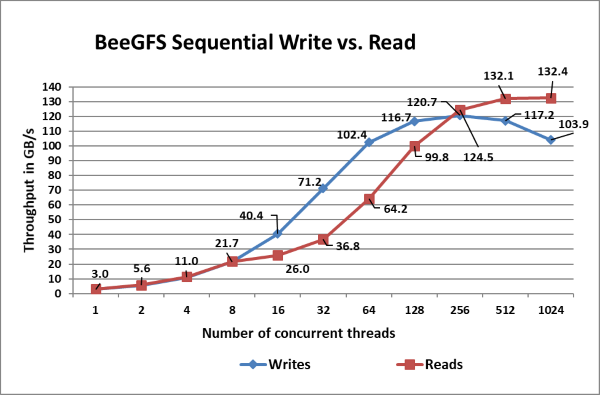
Hình 9: Kích thước tập tin tổng hợp IOzone 8TB tuần tự
Trong Hình 9, chúng ta thấy rằng hiệu suất đọc cao nhất là 132 GB/giây ở 1024 luồng và tốc độ ghi cao nhất là 121 GB/giây ở 256 luồng. Theo thông số kỹ thuật của SSD Intel P4600 1,6 TB NVMe , mỗi ổ có thể cung cấp hiệu suất đọc cao nhất là 3,2 GB/giây và hiệu suất ghi cao nhất là 1,3 GB/giây, cho phép tốc độ đọc cao nhất theo lý thuyết là 422 GB/giây và 172 GB/giây s cho viết. Tuy nhiên, ở đây mạng là yếu tố hạn chế. Chúng tôi có tổng cộng 11 liên kết InfiniBand EDR cho các máy chủ lưu trữ trong quá trình thiết lập. Mỗi liên kết có thể cung cấp hiệu suất cao nhất theo lý thuyết là 12,4 GB/giây, cho phép hiệu suất cao nhất theo lý thuyết là 136,4 GB/giây. Hiệu suất đọc và ghi cao nhất đạt được lần lượt là 97% và 89% so với hiệu suất cao nhất theo lý thuyết.
Hiệu suất ghi một luồng được quan sát là ~3 GB/giây và đọc với tốc độ ~3 GB/giây. Chúng tôi quan sát thấy rằng hiệu suất ghi tăng theo tỷ lệ tuyến tính, đạt cực đại ở 256 luồng rồi bắt đầu giảm dần. Ở số lượng luồng thấp hơn, hiệu suất đọc và ghi là như nhau. Bởi vì cho đến 8 luồng, chúng tôi có 8 ứng dụng khách ghi 8 tệp trên 24 mục tiêu, điều đó có nghĩa là không phải tất cả các mục tiêu lưu trữ đều được sử dụng đầy đủ. Chúng tôi có 33 mục tiêu lưu trữ trong hệ thống và do đó cần ít nhất 11 luồng để sử dụng đầy đủ tất cả các máy chủ. Hiệu suất đọc ghi nhận mức tăng tuyến tính ổn định với sự gia tăng số lượng luồng đồng thời và chúng tôi quan sát thấy hiệu suất gần như tương tự ở 512 và 1024 luồng.
Chúng tôi cũng quan sát thấy rằng hiệu suất đọc thấp hơn ghi đối với số lượng chuỗi từ 16 đến 128 và sau đó hiệu suất đọc bắt đầu mở rộng. Điều này là do trong khi thao tác đọc PCIe là Thao tác không được đăng, yêu cầu cả yêu cầu và hoàn thành, thì thao tác ghi PCIe là thao tác cháy và quên. Sau khi Gói lớp giao dịch được chuyển giao cho Lớp liên kết dữ liệu, thao tác sẽ hoàn tất. Thao tác ghi là thao tác “Đã đăng” chỉ bao gồm một yêu cầu.
Thông lượng đọc thường thấp hơn thông lượng ghi vì các lần đọc yêu cầu hai giao dịch thay vì một lần ghi cho cùng một lượng dữ liệu. PCI Express sử dụng mô hình giao dịch phân tách để đọc. Giao dịch đọc bao gồm các bước sau:
- Người yêu cầu gửi Yêu cầu đọc bộ nhớ (MRR).
- Trình hoàn thành gửi xác nhận tới MRR.
- Trình hoàn thành trả về một Hoàn thành có Dữ liệu.
Thông lượng đọc phụ thuộc vào độ trễ giữa thời gian yêu cầu đọc được đưa ra và thời gian trình hoàn thành trả lại dữ liệu. Tuy nhiên, khi ứng dụng đưa ra đủ số lượng yêu cầu đọc để bù đắp cho độ trễ này, thì thông lượng sẽ được tối đa hóa. Đó là lý do tại sao trong khi hiệu suất đọc thấp hơn hiệu suất ghi từ 16 luồng đến 128 luồng, chúng tôi đo lường thông lượng tăng lên khi số lượng yêu cầu tăng lên. Thông lượng thấp hơn được đo khi người yêu cầu đợi hoàn thành trước khi đưa ra các yêu cầu tiếp theo. Thông lượng cao hơn được đăng ký khi nhiều yêu cầu được đưa ra để phân bổ độ trễ sau khi dữ liệu đầu tiên trả về.
Thông tin chi tiết khác về Truy cập bộ nhớ trực tiếp PCI Express hiện có tại https://www.intel.com/content/www/us/en/programmable/documentation/nik1412547570040.html#nik1412547565760
Viết và đọc ngẫu nhiên NN
Để đánh giá hiệu suất IO ngẫu nhiên, IOzone được sử dụng ở chế độ ngẫu nhiên. Các thử nghiệm được tiến hành trên số lượng luồng bắt đầu từ 4 luồng đến tối đa 1024 luồng. Tùy chọn IO trực tiếp (-I) đã được sử dụng để chạy IOzone để tất cả các hoạt động bỏ qua bộ nhớ cache của bộ đệm và đi trực tiếp vào đĩa. Số lượng sọc BeeGFS là 3 và kích thước khối là 2 MB đã được sử dụng. Kích thước yêu cầu 4KiB được sử dụng trên IOzone. Hiệu suất được đo bằng hoạt động I/O mỗi giây (IOPS). Bộ đệm hệ điều hành đã bị loại bỏ giữa các lần chạy trên máy chủ BeeGFS cũng như máy khách BeeGFS. Lệnh được sử dụng để thực hiện ghi và đọc ngẫu nhiên được đưa ra dưới đây:
Đọc và ghi ngẫu nhiên: iozone -i 2 -w -c -O -I -r 4K -s $Size -t $Thread -+n -+m /path/to/threadlist
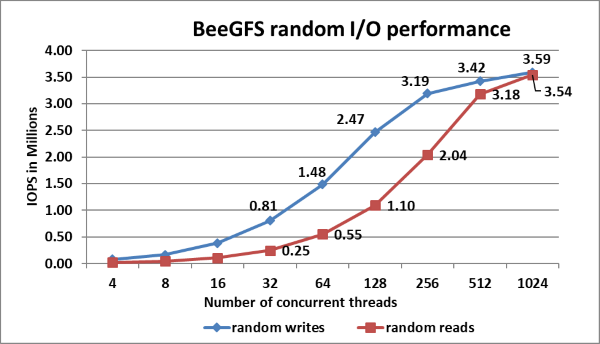
Hình 10: Hiệu suất đọc và ghi ngẫu nhiên khi sử dụng IOzone với kích thước tệp tổng hợp 8TB
Đỉnh ghi ngẫu nhiên ở mức ~3,6 triệu IOPS ở 512 luồng và đỉnh đọc ngẫu nhiên ở ~3,5 triệu IOPS ở 1024 luồng như trong Hình 10. Cả ghi và ghi hiệu suất đọc cho thấy hiệu suất cao hơn khi có số lượng yêu cầu IO cao hơn. Điều này là do tiêu chuẩn NVMe hỗ trợ tối đa 64K hàng đợi I/O và tối đa 64K lệnh trên mỗi hàng đợi. Nhóm hàng đợi NVMe lớn này cung cấp mức độ song song I/O cao hơn và do đó chúng tôi quan sát thấy IOPS vượt quá 3 triệu.
Kết luận và công việc trong tương lai
Blog này thông báo về việc phát hành Giải pháp Lưu trữ BeeGFS Hiệu suất Cao của Dell EMC và nêu bật các đặc tính hiệu suất của nó. Giải pháp này có hiệu suất đọc và ghi tuần tự cao nhất lần lượt là ~132 GB/giây và ~121 GB/giây, đồng thời hiệu suất ghi ngẫu nhiên cao nhất là ~3,6 triệu IOPS và tốc độ đọc ngẫu nhiên là ~3,5 triệu IOPS.
Blog này là một phần của “Giải pháp lưu trữ BeeGFS” được thiết kế tập trung vào không gian đầu với hiệu suất cao. Hãy theo dõi Phần 2 của loạt blog sẽ mô tả cách giải pháp có thể được mở rộng quy mô bằng cách tăng số lượng máy chủ để tăng hiệu suất và dung lượng. Phần 3 của loạt blog sẽ thảo luận về các tính năng bổ sung của BeeGFS và sẽ làm nổi bật việc sử dụng “StorageBench”, điểm chuẩn nhắm mục tiêu lưu trữ tích hợp của BeeGFS.
Là một phần của các bước tiếp theo, chúng tôi sẽ xuất bản sách trắng sau với hiệu suất siêu dữ liệu và hiệu suất N luồng cho 1 tệp IOR và với các chi tiết bổ sung về cân nhắc thiết kế, điều chỉnh và cấu hình.
Bài viết mới cập nhật
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...
Cơ sở hạ tầng CNTT: Mua hay đăng ký?
Nghiên cứu theo số liệu của IDC về giải pháp đăng ...