
Giới thiệu
Mô hình ngôn ngữ lớn (LLM) đã thu hút được sự quan tâm lớn về mặt công nghiệp và học thuật trong những năm gần đây. Các LLM khác nhau đã được áp dụng trong các ứng dụng khác nhau, chẳng hạn như tạo nội dung, tóm tắt văn bản, phân tích tình cảm và chăm sóc sức khỏe. Danh sách cứ kéo dài.
Khi chúng tôi nghĩ về LLM và những phương pháp nào chúng tôi có thể sử dụng để suy luận và tinh chỉnh, câu hỏi luôn đặt ra là chúng tôi nên sử dụng thiết bị điện toán nào. Để suy luận, chúng tôi muốn khám phá các chỉ số hiệu suất khi chạy trên CPU Intel thế hệ thứ 4 và một số biến chúng tôi nên khám phá là gì?
Blog này tập trung vào kết quả suy luận LLM trên Máy chủ Dell PowerEdge với phiên bản thứ 4Bộ xử lý có khả năng mở rộng Intel ® Xeon ® thế hệ . Cụ thể, chúng tôi đã chứng minh hiệu suất và sức mạnh của chúng khi chạy mô hình trò chuyện Llama2 và khuếch tán ổn định trên máy chủ R760 và HS5610. Chúng tôi cũng đã khám phá tác động đến hiệu suất và công suất với các bit lượng tử hóa và số lượng CPU/socket khác nhau thông qua các thử nghiệm và sẽ trình bày kết quả suy luận của mô hình Llama2 và khuếch tán ổn định thu được trên Dell PowerEdge R760 và HS5610 với Bộ xử lý có khả năng mở rộng Intel ® Xeon ® thế hệ thứ 4 .
Chúng tôi đã chọn các nền tảng Dell nói trên vì chúng tôi muốn khám phá cách các nền tảng tập trung vào CSP như HS5610 hoạt động khi nói đến suy luận và liệu chúng có thể đáp ứng các yêu cầu đối với mô hình LLM hay không. Các bộ xử lý Intel ® Xeon ® mới này sử dụng công cụ nhân ma trận Intel AMX ® trong mỗi lõi để tăng hiệu suất suy luận tổng thể. Bằng cách kết hợp với các kỹ thuật lượng tử hóa, chúng tôi đã cải thiện hơn nữa hiệu suất suy luận với hệ thống chỉ dùng CPU. Hơn nữa, chúng tôi cũng cho thấy số lượng lõi và ổ cắm CPU ảnh hưởng đến kết quả hiệu suất như thế nào.
Lý lịch
Transformer được coi là mô hình cơ bản thứ 4 sau Multilayer Perceptron (MLP), Mạng thần kinh tái phát (RNN) và Mạng thần kinh chuyển đổi (CNN). Được biết đến với khả năng song song hóa và khả năng mở rộng, máy biến áp đã tăng cường đáng kể hiệu suất và khả năng của LLM kể từ khi được giới thiệu vào năm 2017 [1].
Ngày nay, LLM đã nhanh chóng được áp dụng trong các ứng dụng khác nhau như tạo nội dung, tóm tắt văn bản, phân tích tình cảm, tạo mã, chăm sóc sức khỏe, v.v., như trong Hình 1 [2]. Xu hướng này đang tiếp tục. Nhiều LLM nguồn mở hơn đang xuất hiện gần như hàng tháng. Hơn nữa, các kỹ thuật dựa trên máy biến áp đang được sử dụng cùng với các phương pháp khác, cải thiện đáng kể độ chính xác và hiệu suất của các tác vụ ban đầu. Ví dụ: mô hình khuếch tán ổn định sử dụng LLM ở đầu vào làm công cụ hiểu ngôn ngữ thần kinh. Kết hợp với mô hình khuếch tán, nó đã cải thiện đáng kể chất lượng và thông lượng của tác vụ tạo văn bản thành hình ảnh [3]. Lưu ý rằng để đơn giản trong blog này, chúng tôi sử dụng thuật ngữ “LLM” để biểu thị cả các mô hình dựa trên máy biến áp được hiển thị trong Hình 1 và các mô hình phái sinh như mô hình khuếch tán ổn định.
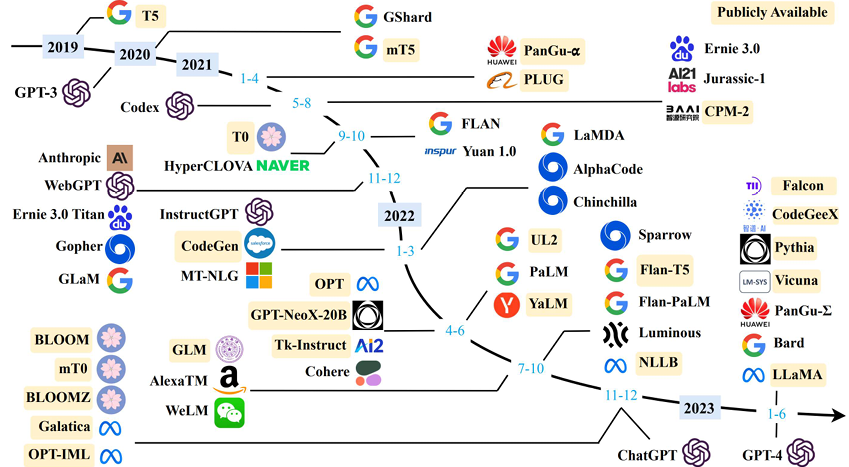
Hình 1. Dòng thời gian LLM [2] Nguồn hình ảnh: Wayne Xin Zhao, et.al, “Khảo sát về các mô hình ngôn ngữ lớn”]
Mặc dù việc đào tạo và tinh chỉnh các LLM đó thường tốn thời gian và chi phí, nhưng việc triển khai LLM ở vùng biên cũng có những thách thức riêng. Xem xét cả hiệu suất và sức mạnh, theo một nghĩa nào đó, việc triển khai LLM có thể nhạy cảm hơn về mặt chi phí do khối lượng hệ thống cần thiết để đáp ứng các ứng dụng khác nhau. GPU được sử dụng rộng rãi để triển khai LLM. Trong blog này, chúng tôi chứng minh tính khả thi của việc triển khai các LLM đó với CPU Intel ® Xeon ® thế hệ thứ 4 của Intel với máy chủ Dell PowerEdge và minh họa rằng có thể đạt được hiệu suất tốt với cấu hình phần cứng phù hợp – như số lõi CPU và phương pháp lượng tử hóa cho các LLM phổ biến .
Thiết lập thử nghiệm
Phần cứngnền tảng mà chúng tôi sử dụng cho thử nghiệm là PowerEdge R760 và HS5610, lần lượt là các máy chủ phổ thông và được tối ưu hóa cho đám mây mới nhất từ danh mục sản phẩm của Dell. Hình 2 hiển thị giao diện mức giá cho máy chủ HS5610. Là một giải pháp được tối ưu hóa cho đám mây, máy chủ HS5610 đã được thiết kế với các tính năng CSP mang lại lợi ích tương tự với đầy đủ các tính năng và quản lý PowerEdge như máy chủ chính thống R760, cũng như quản lý mở (OpenBMC), dịch vụ lối đi lạnh, chương trình cơ sở kênh và dịch vụ. Cả hai máy chủ đều có hai ổ cắm với CPU Xeon thế hệ thứ 4 của Intel trên mỗi ổ cắm. R760 có CPU 56 lõi – Intel ® Xeon ® Platinum 8480+ (TDP: 350W) trong mỗi ổ cắm và HS5610 có CPU 32 lõi – Intel ® Xeon ® Gold 6430 (TDP: 250W) trong mỗi ổ cắm. Bảng 1-4 hiển thị chi tiết về cấu hình máy chủ và thông số kỹ thuật CPU. Trong quá trình thử nghiệm, chúng tôi sử dụng lệnh numactl để đặt số lượng ổ cắm hoặc lõi CPU nhằm thực thi các tác vụ suy luận LLM.
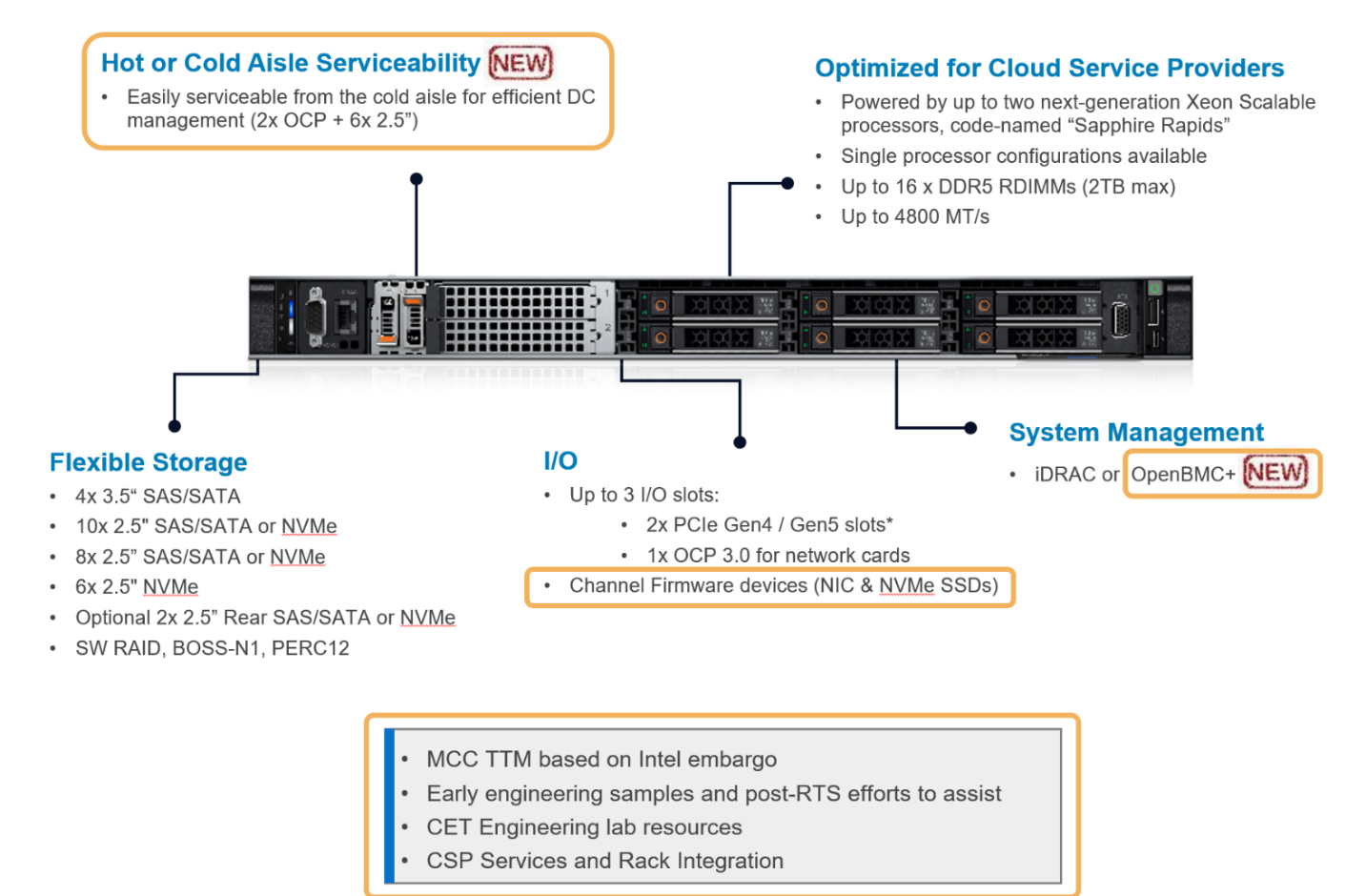
Hình 2. PowerEdge HS5610 [4]
| Tên hệ thống | PowerEdge R760 |
| Trạng thái | Có sẵn |
| Loại hệ thống | Trung tâm dữ liệu |
| Số nút | 1 |
| Mô hình bộ xử lý máy chủ | Bộ xử lý có khả năng mở rộng Intel ® Xeon ® thế hệ thứ 4 |
| Bộ xử lý máy chủ trên mỗi nút | 2 |
| Số lượng lõi của bộ xử lý máy chủ | 56 |
| Tần số bộ xử lý máy chủ | Tăng tốc Turbo 2,0 GHz, 3,8 GHz |
| Dung lượng bộ nhớ máy chủ | DIMM 1TB, 16 x 64GB 4800 MHz |
| Dung lượng lưu trữ máy chủ | 4,8 TB, NVME |
Bảng 1. Cấu hình máy chủ R760
| Bộ sưu tập sản phẩm | Bộ xử lý có khả năng mở rộng Intel ® Xeon ® thế hệ thứ 4 |
| Tên bộ xử lý | Bạch kim 8480+ |
| Trạng thái | Đã ra mắt |
| Số lõi CPU | 56 |
| số chủ đề | 112 |
| Tần số cơ sở | 2,0 GHz |
| Tốc độ Turbo tối đa | 3,8 GHz |
| Bộ đệm L3 | 108MB |
| Loại bộ nhớ | DDR5 4800 tấn/giây |
| Hỗ trợ bộ nhớ ECC | Đúng |
Bảng 2. Thông số kỹ thuật của bộ xử lý có khả năng mở rộng Intel ® Xeon ® 56 nhân thế hệ thứ 4
| Tên hệ thống | PowerEdge HS5610 |
| Trạng thái | Có sẵn |
| Loại hệ thống | Trung tâm dữ liệu |
| Số nút | 1 |
| Mô hình bộ xử lý máy chủ | Bộ xử lý có khả năng mở rộng Intel ® Xeon ® thế hệ thứ 4 |
| Bộ xử lý máy chủ trên mỗi nút | 2 |
| Số lượng lõi của bộ xử lý máy chủ | 32 |
| Tần số bộ xử lý máy chủ | Tăng tốc Turbo 2,0 GHz, 3,8 GHz |
| Dung lượng bộ nhớ máy chủ | DIMM 1TB, 16 x 64GB 4800 MHz |
| Dung lượng lưu trữ máy chủ | 4,8 TB, NVME |
Bảng 3. Cấu hình máy chủ HS5610
| Bộ sưu tập sản phẩm | Bộ xử lý có khả năng mở rộng Intel ® Xeon ® thế hệ thứ 4 |
| Tên bộ xử lý | Vàng 6430 |
| Trạng thái | Đã ra mắt |
| Số lõi CPU | 32 |
| số chủ đề | 64 |
| Tần số cơ sở | 2,0 GHz |
| Tốc độ Turbo tối đa | 3,8 GHz |
| Bộ đệm L3 | 64MB |
| Loại bộ nhớ | DDR5 4800 tấn/giây |
| Hỗ trợ bộ nhớ ECC | Đúng |
Bảng 4. Thông số kỹ thuật của bộ xử lý có khả năng mở rộng Intel ® Xeon ® 32 nhân thế hệ thứ 4
Ngăn xếp phần mềm và cấu hình hệ thống
Cấu hình hệ thống và ngăn xếp phần mềm được sử dụng cho lần gửi này được tóm tắt trong Bảng 5. Các tối ưu hóa đã được thực hiện đối với khung PyTorch và thư viện Transformers để giải phóng khả năng học máy của CPU Xeon. Hơn nữa, một công cụ cấp thấp — Intel® Neural Compressor — đã được sử dụng để lượng tử hóa với độ chính xác cao.
| hệ điều hành | CentOS Stream 8 (GNU/Linux x86_64) |
| SW suy luận tối ưu hóa Intel® | OneDNN™ Deep Learning, ONNX, Intel ® Extension cho PyTorch (IPEX), Intel ® Extension cho Transformers (ITREX), Intel ® Neural Compressor |
| Chế độ bộ nhớ ECC | TRÊN |
| Cấu hình bộ nhớ máy chủ | 1TiB |
| Chế độ tăng tốc | TRÊN |
| Bộ điều chỉnh tần số CPU | Hiệu suất |
Bảng 5. Cấu hình hệ thống và ngăn xếp phần mềm
Các mô hình đang được thử nghiệm là mô hình khuếch tán ổn định phiên bản 1.4 (~1 tỷ tham số) và mô hình Llama2-chat-HF với 7 tỷ, 13 tỷ và 70 tỷ tham số. Chúng tôi cố tình chọn những mô hình đó vì chúng có nguồn mở, mang tính đại diện và bao gồm phạm vi tham số rộng. Các bit lượng tử hóa khác nhau được kiểm tra để mô tả hiệu suất và mức tiêu thụ điện năng tương ứng.
Tất cả các thử nghiệm đều dựa trên quy mô lô bằng 1. Hiệu suất được đặc trưng bởi độ trễ hoặc thông lượng. Để giảm sai số đo, phép suy luận được thực hiện 10 lần để lấy giá trị trung bình. Quá trình khởi động được thực hiện bằng cách tải tham số và chạy thử nghiệm mẫu trước khi chạy suy luận đã xác định.
Kết quả
Chúng tôi trình bày một số kết quả điển hình trong phần này cùng với các thảo luận ngắn gọn về từng kết quả. Các kết luận được tóm tắt trong phần tiếp theo.
Kết quả HS5610
Độ trễ so với lượng tử hóa so với lõi – Mô hình khuếch tán ổn định:
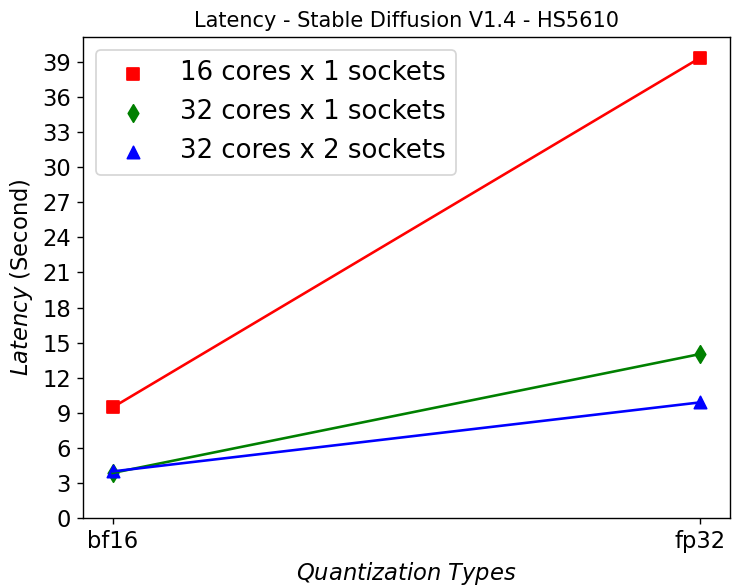
Hình 3. Độ trễ trong máy chủ HS5610 chạy Stable Diffusion
Hình 3 cho thấy HS5610 có thể tạo ra một hình ảnh mới trong khoảng 3 giây khi chạy ở model bf16 Stable Diffusion V1.4. Lượng tử hóa thành 16 bit giúp giảm đáng kể độ trễ so với sử dụng mô hình fp32. Việc mở rộng số lượng lõi từ 16 lên 32 lõi giúp giảm đáng kể độ trễ, tuy nhiên việc mở rộng quy mô trên các ổ cắm không giúp ích được gì. Điều này chủ yếu là do tắc nghẽn bộ nhớ từ xa NUMA.
Tiêu thụ điện năng – Mô hình khuếch tán ổn định:
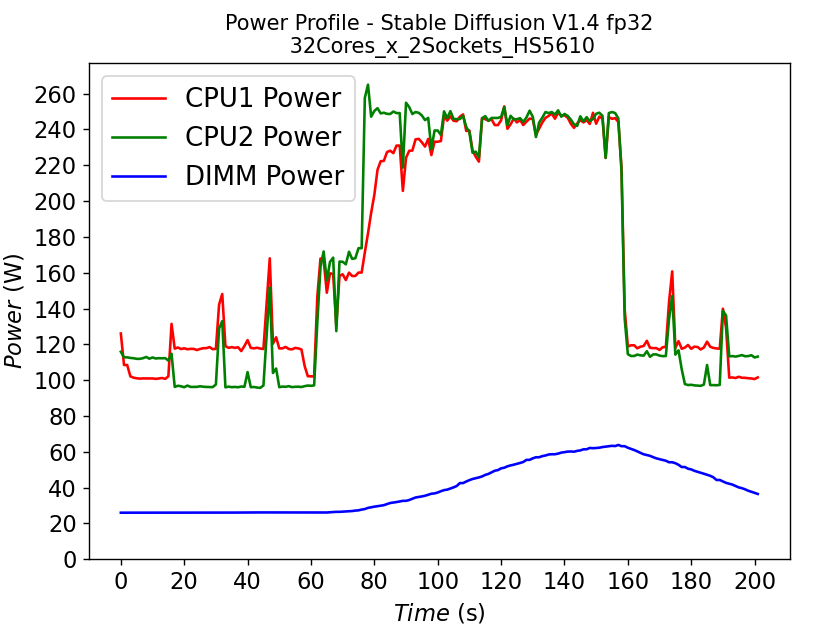 (Một)
(Một) 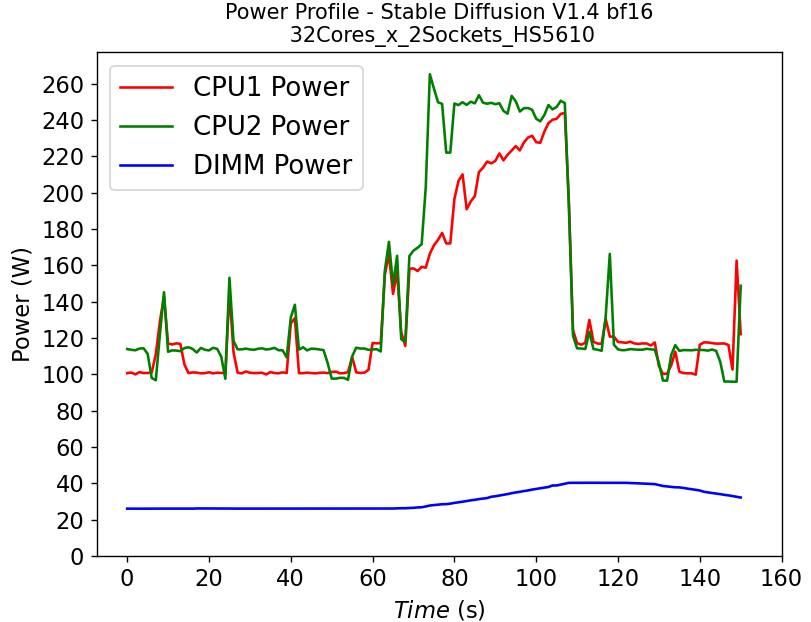 (b)
(b)
Hình 4. Điện năng tiêu thụ của CPU và DIMM trong máy chủ HS5610 chạy khuếch tán ổn định: (a) model fp32 (b) model bf16
Hình 4 cho thấy so sánh cấu hình công suất của HS5610 khi chạy mô hình khuếch tán ổn định với (a) trọng lượng fp32 và (b) trọng lượng bf16. Để hoàn thành các nhiệm vụ tương tự (khởi động và suy luận), mô hình bf16 mất ít thời gian hơn đáng kể (thời lượng cấu hình nguồn ngắn hơn) so với kịch bản fp32. Biểu đồ cũng cho thấy cần có công suất DIMM lớn hơn nhiều để chạy fp32 so với bf16. Việc thực thi tác vụ sẽ đẩy CPU hoạt động gần đến giới hạn TDP, ngoại trừ CPU1 trong Hình 4b, cho thấy rằng có thể cải thiện thêm để giảm độ trễ hơn nữa cho mô hình bf16.
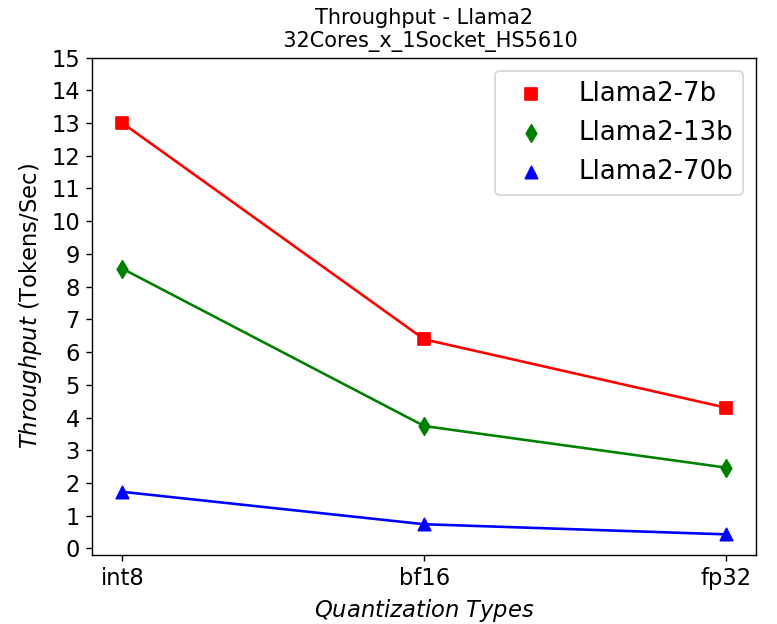
Thông lượng, Lượng tử hóa và Lõi – Mô hình trò chuyện Llama2:
 (Một)
(Một)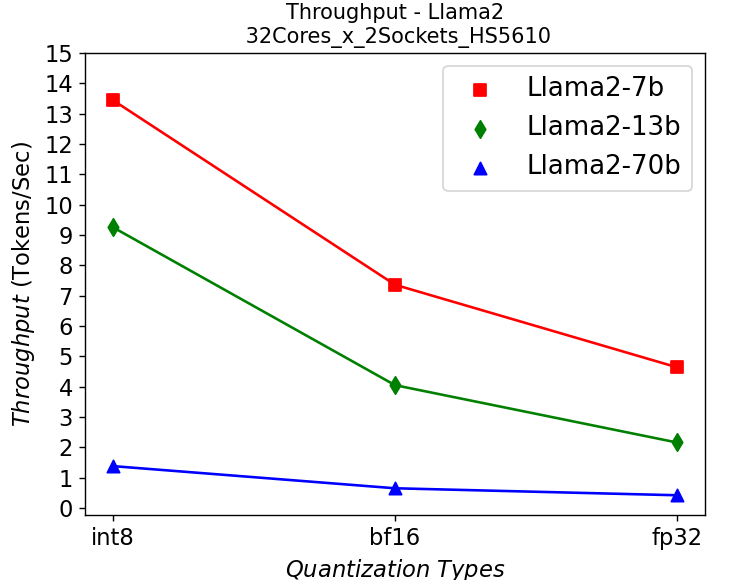 (b)
(b)
Hình 5. Thông lượng trong máy chủ HS5610 chạy Llama2: (a) 1-socket (b) 2-socket
Hình 5 hiển thị số lượng thông lượng khi chạy mô hình trò chuyện Llama2 với các kích thước tham số và bit lượng tử hóa khác nhau trong máy chủ HS5610. Hình 5a hiển thị kịch bản ổ cắm đơn và 5b hiển thị kịch bản ổ cắm kép. Các mô hình nhỏ hơn với số bit lượng tử hóa thấp hơn sẽ mang lại thông lượng cao hơn như mong đợi. Giống như mô hình khuếch tán ổn định, lượng tử hóa cải thiện đáng kể thông lượng. Tuy nhiên, việc mở rộng quy mô với nhiều lõi CPU hơn trên ổ cắm có kết quả không đáng kể trong việc tăng hiệu suất.
Kết quả R760
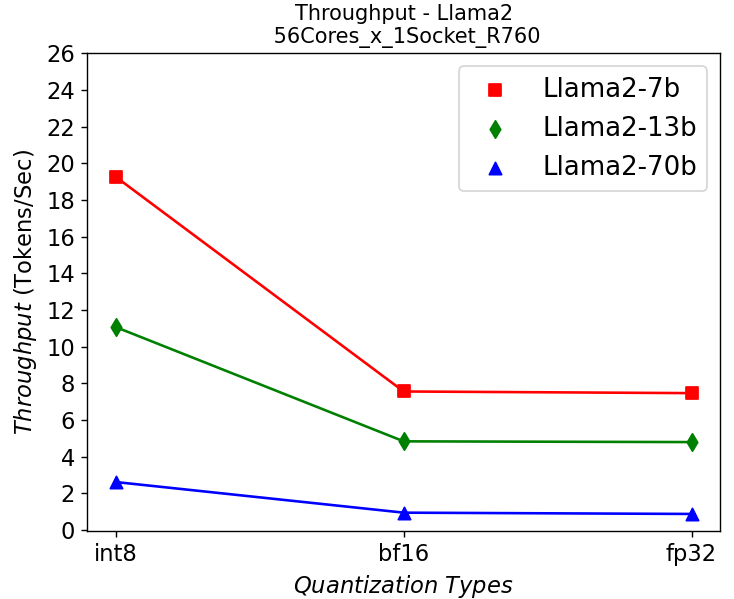
Thông lượng, Lượng tử hóa và Lõi – Mô hình trò chuyện Llama2:
 (Một)
(Một)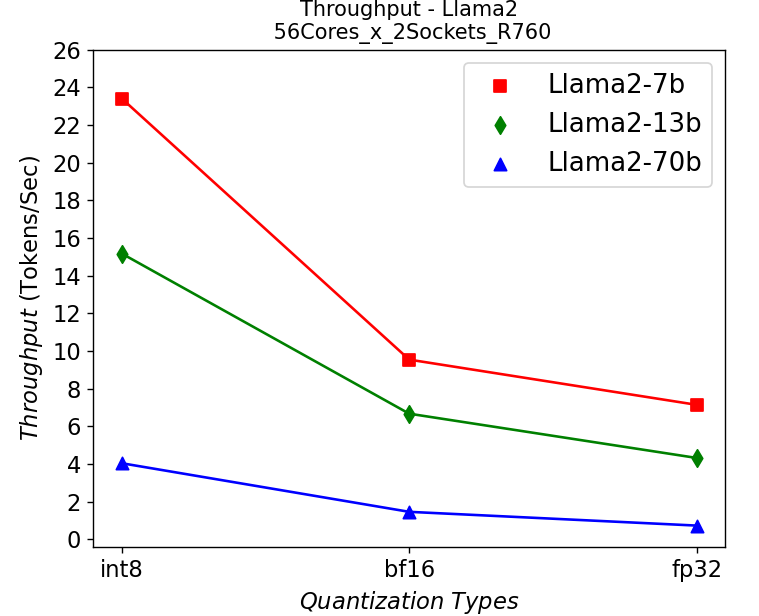 (b)
(b)
Hình 6. Thông lượng trong máy chủ R760 chạy Llama2: (a) 1-socket (b) 2-socket
Hình 6 hiển thị số lượng thông lượng khi chạy mô hình trò chuyện Llama2 với các kích thước tham số và bit lượng tử hóa khác nhau trong máy chủ R760. Chúng tôi nhận được những quan sát tương tự như kết quả được hiển thị trên máy chủ HS5610. Một mô hình nhỏ hơn cho thông lượng cao hơn và lượng tử hóa sẽ cải thiện đáng kể thông lượng. Một điểm khác biệt là chúng tôi nhận được cải thiện hiệu suất 10-30% tùy thuộc vào kiểu máy khi mở rộng quy mô trên các ổ cắm, cho thấy lợi ích từ số lượng lõi lớn hơn. Hiệu suất trên các mô hình đủ tốt cho hầu hết các ứng dụng chatbot thời gian thực.
Hiệu suất trên mỗi watt – Mô hình trò chuyện Llama2:
 (Một)
(Một)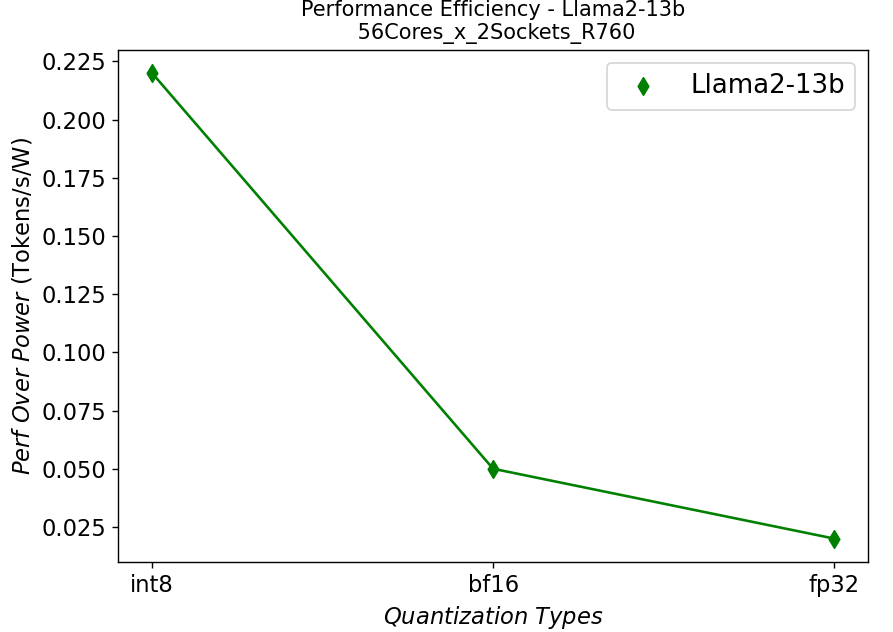 (b)
(b)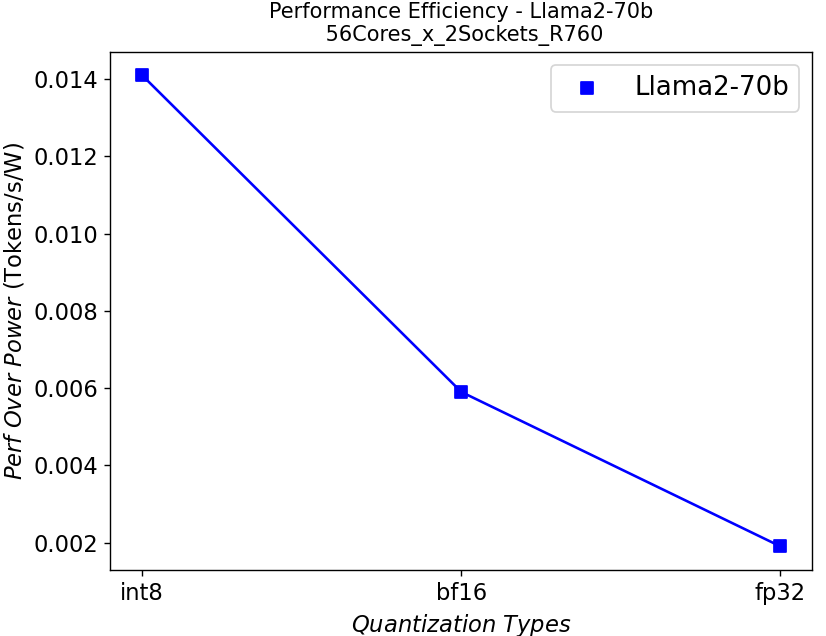 (c)
(c)
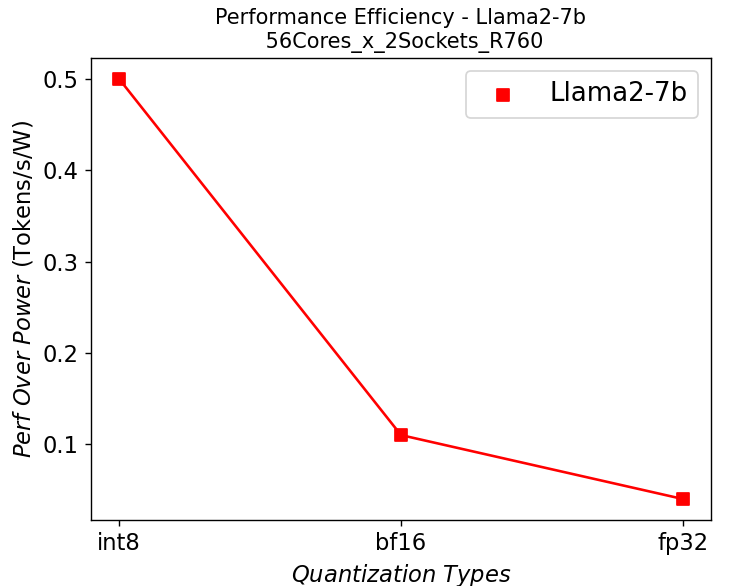
Hình 7. Hiệu suất trên mỗi watt trong máy chủ R760 chạy Llama2: (a) 7b (b)13b (c) 70b
Chúng tôi tiếp tục vẽ đường cong hiệu suất trên mỗi watt có liên quan chặt chẽ đến tổng chi phí sở hữu (TCO) của hệ thống trong Hình 7. Từ các sơ đồ, việc lượng tử hóa có thể giúp ích rất nhiều cho hiệu quả hiệu suất, đặc biệt đối với các mô hình có tham số lớn.
Phần kết luận
- Chúng tôi đã chỉ ra rằng CPU Intel® Xeon® thế hệ thứ 4 trên nền tảng Dell PowerEdge phổ thông và lớp HS có thể dễ dàng đáp ứng các yêu cầu về hiệu suất khi sử dụng các mô hình Suy luận với Llama2.
- Chúng tôi cũng chứng minh những lợi ích của việc lượng tử hóa hoặc sử dụng độ chính xác thấp hơn để suy luận định lượng, điều này có thể mang lại TCO tốt hơn về hiệu suất trên mỗi watt và dung lượng bộ nhớ cũng như mang lại trải nghiệm người dùng tốt hơn bằng cách cải thiện thông lượng.
- Những nghiên cứu này cũng cho thấy rằng chúng ta cần điều chỉnh kích thước cơ sở hạ tầng phù hợp dựa trên kích thước ứng dụng và mô hình.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...