
Tin tức
Cụm dữ liệu lớn của Microsoft SQL Server 2019: Giải pháp dữ liệu lớn sử dụng cơ sở hạ tầng Dell EMC (2)
Tổng quan thiết kế
Giới thiệu
Mục tiêu của giải pháp SQL Server này là thể hiện những ưu điểm của việc sử dụng Cụm dữ liệu lớn SQL Server 2019 với PolyBase để tạo ra một phạm vi dữ liệu dễ dàng hỗ trợ hàng petabyte dữ liệu và khả năng truy cập liền mạch các nguồn dữ liệu khác để cải thiện báo cáo phân tích.
Nền tảng được xác định bằng phần mềm PowerFlex đã lưu trữ môi trường phòng thí nghiệm của chúng tôi. Chúng tôi chọn hệ thống PowerFlex vì nó hỗ trợ cả chế độ hai lớp và siêu hội tụ. Cấu hình phòng thí nghiệm đã sử dụng chế độ siêu hội tụ, mang lại khả năng tiết kiệm hợp nhất đáng kể. Với chế độ siêu hội tụ, chúng ta có thể sử dụng tài nguyên CPU, bộ nhớ và bộ nhớ cho các vùng chứa trên các nút của mình; do đó, cần ít phần cứng hơn. Một lý do quan trọng khác để sử dụng giá đỡ PowerFlex là khả năng tích hợp của nó với Kubernetes. Khi trường hợp sử dụng phát triển, chúng tôi trình bày cách trình cắm CSI cho hệ thống PowerFlex cung cấp mức độ tự động hóa lưu trữ bổ sung thông qua Kubernetes.
Trường hợp sử dụng trong sách trắng này mô tả cách quản lý và khai thác dữ liệu lớn với sự hỗ trợ của các công nghệ vùng chứa cải tiến. Nó trình bày cách bạn có thể sử dụng phạm vi dữ liệu của công ty mình để phân tích được cải thiện trên nền tảng linh hoạt được thiết kế để linh hoạt, tự động hóa và điều phối.
Tổng quan về ca sử dụng
Chúng tôi đã thiết kế trường hợp sử dụng của mình để song song với các bước mà khách hàng thực hiện để triển khai Cụm dữ liệu lớn của SQL Server. Trong suốt cuộc thảo luận về ca sử dụng, chúng tôi mô tả các bước quan trọng, những cân nhắc về thiết kế và kết quả. Cuộc thảo luận không nhằm mục đích phác thảo các hành động triển khai từng bước mà thay vào đó là cung cấp hướng dẫn để giúp giải pháp Cụm dữ liệu lớn của bạn thành công.
Thiết kế và định cấu hình giá đỡ PowerFlex linh hoạt là bước đầu tiên của chúng tôi. Vì Cụm dữ liệu lớn có vai trò quan trọng trong kinh doanh nên chúng tôi đã thiết kế giá đỡ PowerFlex với nhiều nút điều khiển và nút siêu hội tụ để không có một điểm lỗi nào. Hiệu suất không phải là yếu tố quan trọng cần cân nhắc vì PowerFlex cho phép mở rộng quy mô lớn bằng cách bổ sung các nút. Một trong nhiều ưu điểm của hệ thống PowerFlex là khách hàng có thể lựa chọn giữa việc sử dụng cơ sở hạ tầng cơ bản hoặc ảo hóa. Trong trường hợp sử dụng này, chúng tôi đã sử dụng ảo hóa VMware vSphere để tăng khả năng quản lý và bảo mật.
Chúng tôi đã tạo máy ảo vSphere để lưu trữ Red Hat Enterprise Linux. Hệ điều hành Red Hat Linux được chứng nhận cho Cụm dữ liệu lớn SQL Server 2019, Docker Enterprise Edition và Kubernetes. Trong trường hợp sử dụng này, chúng tôi trình bày khả năng tự động hóa mà chúng tôi đạt được khi sử dụng Kubernetes với trình cắm CSI cho hệ thống PowerFlex.
Triển khai Cụm dữ liệu lớn SQL Server 2019 trong vùng chứa là bước tiếp theo của chúng tôi. Để biết các bước triển khai, hãy xem Cách triển khai Cụm dữ liệu lớn của SQL Server trên Kubernetes trong Microsoft SQL Docs. Chúng tôi đã tạo một sổ đăng ký riêng cục bộ để quản lý hình ảnh Cụm dữ liệu lớn của mình, giúp nhóm cơ sở dữ liệu có khả năng cập nhật hình ảnh.
Khi Cụm dữ liệu lớn của chúng tôi đang chạy, chúng tôi đã điền vào cụm dữ liệu từ điểm chuẩn TPC-H . Điểm chuẩn TPC-H là điểm chuẩn hỗ trợ quyết định. Chúng tôi chọn nó vì nó cung cấp khả năng tạo bộ dữ liệu 1 TB và 10 TB. Chúng tôi đã sử dụng tập dữ liệu TPC-H 1 TB trong các thử nghiệm của mình và chúng tôi đã sử dụng tập dữ liệu 10 TB ở cuối trường hợp sử dụng để xác thực tập dữ liệu lớn hơn trong Cụm dữ liệu lớn.
Bước tiếp theo là sử dụng PolyBase để kết nối ba tài nguyên khác nhau. Chúng tôi đã nhập hầu hết dữ liệu TPC-H vào Cụm dữ liệu lớn và nhập các bảng nhỏ hơn từ cùng một tập dữ liệu vào cơ sở dữ liệu SQL Server 2019 và cơ sở dữ liệu Oracle 19 c . Sau đó, chúng tôi có thể sử dụng các truy vấn TPC-H để chỉ ra rằng PolyBase cho phép ảo hóa dữ liệu—nghĩa là PolyBase cho phép chúng tôi truy vấn ba nguồn dữ liệu khác nhau bằng T ‑ SQL.
Kết quả của việc thiết lập Cụm dữ liệu lớn của Microsoft này là khả năng báo cáo dữ liệu trên ba cơ sở dữ liệu của chúng tôi. Chúng tôi đã thử nghiệm khả năng báo cáo của mình theo hai cách. Trước tiên, chúng tôi sử dụng các truy vấn TPC-H mà không cần tăng tốc. Sau đó, chúng tôi đã tạo nhóm dữ liệu Cụm dữ liệu lớn và lưu trữ dữ liệu từ cơ sở dữ liệu Oracle vào bộ nhớ đệm.
Công nghệ phần mềm
Các phần sau đây tóm tắt các thành phần công nghệ phần mềm chính của giải pháp này.
Ảo hóa dựa trên container
Hai tùy chọn chính để cho phép các ứng dụng phần mềm chạy trên phần cứng ảo là sử dụng máy ảo và bộ ảo hóa hoặc sử dụng ảo hóa dựa trên bộ chứa—còn được gọi là ảo hóa hoặc bộ chứa hệ điều hành.
Phương pháp ảo hóa cũ hơn và phổ biến hơn sử dụng máy ảo và bộ ảo hóa được phát triển lần đầu tiên bởi Burroughs Corporation vào những năm 1950 và được nhân rộng với việc thương mại hóa các máy tính lớn của IBM vào đầu những năm 1960. Phương pháp ảo hóa chính được các nền tảng như IBM VM/CMS, VMware ESXi và Microsoft Hyper-V sử dụng bắt đầu bằng lớp ảo hóa giúp trừu tượng hóa các thành phần vật lý của máy tính. Sự trừu tượng hóa cho phép chia sẻ các thành phần bởi nhiều máy ảo, mỗi máy chạy một hệ điều hành khách. Một sự phát triển gần đây hơn là ảo hóa dựa trên container, trong đó một hệ điều hành máy chủ duy nhất hỗ trợ nhiều quy trình đang chạy dưới dạng ứng dụng ảo.
Hình dưới đây so sánh ảo hóa dựa trên VM với ảo hóa dựa trên vùng chứa. Trong ảo hóa dựa trên vùng chứa, sự kết hợp của các thành phần hệ điều hành khách và mọi ứng dụng phần mềm bị cô lập sẽ tạo thành một vùng chứa chạy trên máy chủ lưu trữ, như được biểu thị bằng các hộp Ứng dụng 1, Ứng dụng 2 và Ứng dụng 3.
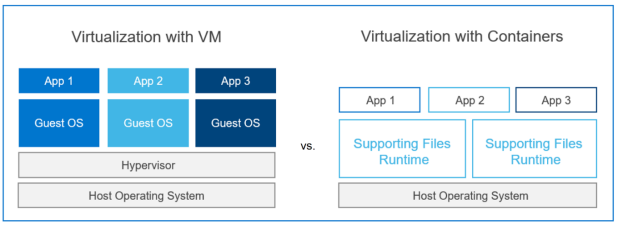
Hình 1. Các phương pháp ảo hóa chính
Cả hai loại ảo hóa đều được phát triển để tăng hiệu quả đầu tư phần cứng máy tính bằng cách hỗ trợ song song nhiều người dùng và ứng dụng. Việc container hóa cải thiện hơn nữa năng suất hoạt động CNTT bằng cách đơn giản hóa tính di động của ứng dụng. Các nhà phát triển ứng dụng thường làm việc bên ngoài môi trường máy chủ nơi chương trình của họ sẽ chạy. Để giảm thiểu xung đột trong các phiên bản thư viện, phần phụ thuộc và cài đặt cấu hình, môi trường sản xuất phải được tạo lại nhiều lần để phát triển, thử nghiệm và tích hợp tiền sản xuất. Các chuyên gia CNTT nhận thấy các bộ chứa dễ dàng triển khai nhất quán hơn trên nhiều môi trường vì hệ điều hành cốt lõi có thể được cấu hình độc lập với bộ chứa ứng dụng.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...