
Tin tức
Cụm dữ liệu lớn của Microsoft SQL Server 2019: Giải pháp dữ liệu lớn sử dụng cơ sở hạ tầng Dell EMC (3)
Kubernetes
Các ứng dụng hiện đại ngày càng được xây dựng để tận dụng công nghệ vùng chứa—chủ yếu bằng cách xác định các dịch vụ vi mô được đóng gói cùng với các phần phụ thuộc và cấu hình của chúng trong vùng chứa. Kubernetes, còn được gọi là K8s, là một nền tảng nguồn mở để triển khai và quản lý các ứng dụng được đóng gói trên quy mô lớn. Hệ thống điều phối vùng chứa Kubernetes đã được Google cung cấp nguồn mở vào năm 2014.
Hình dưới đây cho thấy kiến trúc Kubernetes:
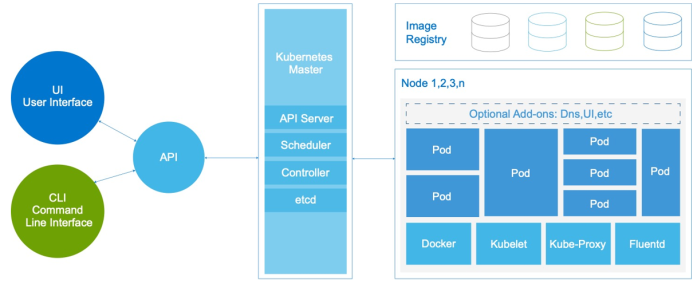
Hình 2. Kiến trúc Kubernetes
Các tính năng của Kubernetes để điều phối container trên quy mô lớn bao gồm:
- Tự động chia tỷ lệ, sao chép và phục hồi vùng chứa
- Giao tiếp nội bộ, chẳng hạn như chia sẻ IP
- Một thực thể duy nhất—một nhóm—để tạo và quản lý nhiều vùng chứa
- Tác nhân phân tích hiệu suất và sử dụng tài nguyên vùng chứa, cAdvisor
- Kiến trúc có thể cắm mạng
- Cân bằng tải
- Dịch vụ kiểm tra sức khoẻ
Trong quá trình thử nghiệm, chúng tôi đã sử dụng nhóm Kubernetes để triển khai các dịch vụ nhóm lưu trữ. Nhóm nhóm lưu trữ bao gồm một bộ chứa Spark và một bộ chứa SQL Server.
Đặc tả giao diện lưu trữ vùng chứa Kubernetes
Đặc tả Kubernetes CSI là một tiêu chuẩn để hiển thị các hệ thống lưu trữ tệp và khối tùy ý cho khối lượng công việc được chứa trong bộ chứa thông qua lớp điều phối. Kubernetes trước đây đã cung cấp một plug-in âm lượng mạnh mẽ, là một phần của mã Kubernetes cốt lõi và được cung cấp cùng với các tệp nhị phân Kubernetes cốt lõi. Tuy nhiên, trước khi áp dụng CSI, việc bổ sung hỗ trợ cho các plug-in số lượng lớn mới vào Kubernetes khi mã ở dạng “nội cây” là một thách thức. Các nhà cung cấp muốn thêm hỗ trợ cho hệ thống lưu trữ của họ vào Kubernetes hoặc thậm chí khắc phục sự cố trong plug-in ổ đĩa hiện có, buộc phải tuân thủ quy trình phát hành Kubernetes. Ngoài ra, mã lưu trữ của bên thứ ba có thể gây ra các vấn đề về độ tin cậy và bảo mật trong các tệp nhị phân Kubernetes cốt lõi. Mã này thường khó—và đôi khi không thể—đối với những người bảo trì Kubernetes để kiểm tra và bảo trì.
Việc áp dụng đặc tả CSI giúp lớp khối Kubernetes thực sự có thể mở rộng. Bằng cách sử dụng CSI, nhà cung cấp dịch vụ lưu trữ bên thứ ba có thể viết và triển khai các plug-in để hiển thị các hệ thống lưu trữ mới trong Kubernetes mà không cần phải chạm vào mã Kubernetes cốt lõi. Khả năng này mang đến cho người dùng Kubernetes nhiều tùy chọn lưu trữ hơn và giúp hệ thống an toàn và đáng tin cậy hơn. Thiết kế giải pháp của chúng tôi nêu bật những ưu điểm này bằng cách sử dụng plug-in CSI cho hệ thống PowerFlex để thể hiện lợi ích của việc tự động hóa lưu trữ Kubernetes.
Triển khai Kubernetes
Kubernetes là một hệ thống điều phối container nguồn mở. Dell Technologies là thành viên bạch kim của Tổ chức Điện toán Đám mây (CNCF), tổ chức hỗ trợ quá trình phát triển Kubernetes đang diễn ra. Các công ty như VMware, Red Hat và Canonical đã tạo các phiên bản Kubernetes được hỗ trợ của riêng họ dựa trên phiên bản nguồn mở phổ biến. Đối với trường hợp sử dụng mà chúng tôi mô tả trong sách trắng này, chúng tôi đã sử dụng Kubernetes nguồn mở vì khả năng chạy ở mọi nơi, để đáp ứng số lượng thiết kế rộng nhất. Ví dụ: các nền tảng được hỗ trợ chính bao gồm hầu hết các phiên bản Linux và các đám mây như Google GCP, Amazon AWS và Microsoft Azure. Không có chi phí hỗ trợ cho Kubernetes nguồn mở được cộng đồng Kubernetes hỗ trợ; tuy nhiên, khách hàng cần hỗ trợ doanh nghiệp nên khám phá các phiên bản khác. Red Hat OpenShift là một nền tảng để quản lý các vùng chứa trên các trung tâm dữ liệu tại chỗ và các đám mây như Azure Red Hat OpenShift. Red Hat OpenShift là một phần của chương trình Kubernetes được chứng nhận CNCF, đảm bảo khả năng tương thích cho khối lượng công việc trong vùng chứa của bạn. Dễ cài đặt, tập trung vào bảo mật và hỗ trợ doanh nghiệp khiến OpenShift trở thành lựa chọn phổ biến. Trung tâm thông tin giải pháp Dell Technologies dành cho Nền tảng vùng chứa OpenShift của Red Hat có một thư viện gồm các tài liệu và hướng dẫn kỹ thuật liên quan.
Canonical cung cấp nền tảng Kubernetes ngược dòng thuần túy để quản lý các vùng chứa trên nhiều loại đám mây, bao gồm tất cả các đám mây công cộng lớn và trong các trung tâm dữ liệu riêng tư cho cả cơ sở hạ tầng ảo hóa và kim loại trần. Canonical cũng cung cấp hỗ trợ doanh nghiệp cho Kubernetes trên Ubuntu dành cho đám mây công cộng, VMware, OpenStack và bare metal.
Tự động hóa Kubernetes với plug-in Dell EMC CSI cho hệ thống PowerFlex
Với plug-in CSI cho hệ thống PowerFlex, khách hàng có thể tự động hóa các hoạt động lưu trữ trong khi sử dụng Kubernetes và tận dụng các khả năng như:
- Hành động khối lượng liên tục (PV) —Tạo, liệt kê, xóa và tạo từ ảnh chụp nhanh
- Cung cấp khối lượng động —Tạo khối lượng liên tục theo yêu cầu mà không cần bất kỳ bước thủ công nào
- Khả năng chụp nhanh —Tạo, xóa và liệt kê
Tiền tố âm lượng cho phép nhận dạng LUN dễ dàng. Đối với các ổ đĩa ổn định, trình cắm CSI hỗ trợ cả hệ thống tệp ext4 và xfs trên các nút công nhân. Để biết chi tiết cài đặt và liên kết tải xuống plug-in CSI mới nhất cho hệ thống PowerFlex, hãy xem GitHub . Bạn cũng có thể tải xuống hướng dẫn sản phẩm trình điều khiển từ GitHub.
Bộ chứa SQL Server và Docker trên Linux
Trong những năm gần đây, Microsoft đã mở rộng danh mục các dịch vụ tương thích hoặc được chuyển riêng sang hệ điều hành Linux. Với bản phát hành SQL Server 2017, Microsoft đã cung cấp SQL Server trên các bộ chứa Linux và Docker. Trong sách trắng này, chúng tôi xem xét SQL Server 2019 mới được phát hành với Cụm dữ liệu lớn trên vùng chứa Docker.
Microsoft đang phát triển triển khai SQL Server của các bộ chứa Linux cho cả máy chủ Linux và Windows cũng như các bộ chứa Windows cho Windows. Các tính năng được hỗ trợ và lộ trình triển khai này khác nhau, vì vậy hãy xác minh cẩn thận xem sản phẩm có đáp ứng yêu cầu của bạn hay không. Đối với sách trắng này, chúng tôi đã làm việc độc quyền với các bộ chứa SQL Server dành cho Linux.
Microsoft lần đầu tiên giới thiệu hỗ trợ cho hệ điều hành Linux và hình ảnh Linux được đóng gói trong SQL Server 2017. Theo Microsoft, một trong những trường hợp sử dụng chính dành cho khách hàng đang sử dụng bộ chứa SQL Server là dành cho nhà phát triển/thử nghiệm cục bộ trong quy trình DevOps, với việc triển khai được xử lý bởi Kubernetes. SQL Server trong các vùng chứa mang lại nhiều lợi thế cho DevOps nhờ hoạt động nhất quán, tách biệt và đáng tin cậy trên các môi trường, dễ sử dụng cũng như dễ dàng khởi động và dừng. Các ứng dụng có thể được xây dựng trên các vùng chứa SQL Server và chạy mà không bị ảnh hưởng bởi phần còn lại của môi trường. Sự cô lập này làm cho SQL Server trong các vùng chứa trở nên lý tưởng cho các tình huống triển khai thử nghiệm cũng như các quy trình DevOps.
Cụm dữ liệu lớn của SQL Server
SQL Server và các cơ sở dữ liệu tương tự được thiết kế chủ yếu để xử lý giao dịch trực tuyến (OLTP) và là các hệ thống mở rộng quy mô. Trong hệ thống mở rộng quy mô, lợi ích về hiệu suất đến từ việc bổ sung thêm tài nguyên bộ nhớ và điện toán trong máy chủ lưu trữ hoặc di chuyển sang máy chủ lớn hơn. Ngược lại, hệ thống cơ sở dữ liệu mở rộng quy mô được thiết kế để sử dụng nhiều máy chủ nối mạng có bộ lưu trữ để phân phối dữ liệu và xử lý dữ liệu trên một cụm. Hệ thống mở rộng quy mô được thiết kế để quản lý những thách thức về dữ liệu lớn không hoạt động tốt thông qua cách tiếp cận hệ thống mở rộng quy mô truyền thống.
Với SQL Server 2019, Microsoft hiện cung cấp tùy chọn lưu trữ các dịch vụ cơ sở dữ liệu mở rộng. Cụm dữ liệu lớn SQL Server 2019 là một giải pháp dữ liệu lớn có quy mô lớn mới kết hợp SQL Server, Spark và HDFS trên một cụm máy chủ. Phiên bản chính của SQL Server điều phối khả năng kết nối, quản lý truy vấn mở rộng, siêu dữ liệu và học máy. Phiên bản chính là phiên bản SQL Server đầy đủ chức năng và điểm cuối Luồng dữ liệu dạng bảng (TDS) cung cấp giao thức cấp ứng dụng được sử dụng bởi các công cụ như Azure Data Studio và SQL Server Management Studio.
Phiên bản chính chứa công cụ truy vấn mở rộng quy mô để đẩy các tính toán vào nhóm điện toán. Trong Cụm dữ liệu lớn, nhóm điện toán xử lý truy vấn trên các phiên bản SQL Server. Sự song song hóa này cho phép đọc các tập dữ liệu lớn nhanh hơn, do đó tiết kiệm thời gian trả về kết quả. Việc quản lý các truy vấn mở rộng quy mô và siêu dữ liệu khác được duy trì trong phiên bản chính.
Siêu dữ liệu trong phiên bản chính bao gồm:
- Cơ sở dữ liệu siêu dữ liệu với siêu dữ liệu bảng HDFS
- Bản đồ phân đoạn gói dữ liệu
- Chi tiết về các bảng bên ngoài cung cấp quyền truy cập vào mặt phẳng dữ liệu cụm
- Nguồn dữ liệu ngoài PolyBase và các bảng bên ngoài được xác định trong cơ sở dữ liệu người dùng
Ngoài công cụ SQL và quản lý Cụm dữ liệu lớn, SQL Server 2019 còn tích hợp các dịch vụ bổ sung như học máy. Học máy là khả năng sử dụng dữ liệu trong việc phát triển các mô hình. Ví dụ: bằng cách sử dụng máy học, một mô hình có thể được tạo để xác định sự khác biệt giữa email hợp pháp và thư rác. Mô hình như vậy sau đó có thể được sử dụng để cải thiện dịch vụ email bằng cách loại bỏ hầu hết thư rác khỏi hộp thư đến của người dùng.
Dịch vụ học máy là một tính năng bổ sung cho phiên bản chính. Tính năng này được cài đặt theo mặc định và cho phép các nhà phát triển sử dụng mã Java, R và Python trong SQL Server. Khả năng này cung cấp lộ trình cho các nhà khoa học dữ liệu sử dụng các công cụ Spark và HDFS với phiên bản chính của SQL Server, như minh họa trong hình sau:
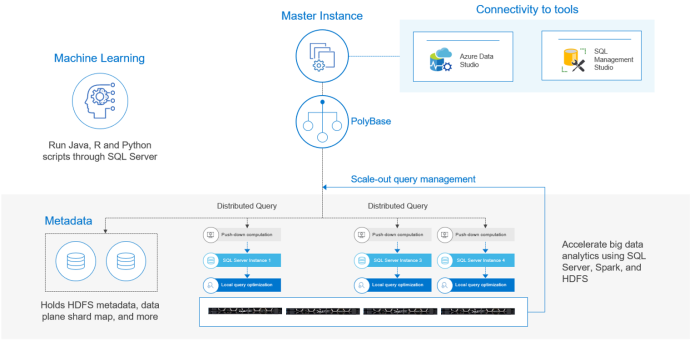
Hình 3. Dịch vụ Machine Learning được cài đặt trên phiên bản chính của SQL Server
Các dịch vụ Apache Spark cũng có sẵn trong SQL Server 2019. Spark là một hệ thống điện toán cụm đa năng được thiết kế để đạt được hiệu suất. Thông qua API, Spark hỗ trợ nhiều ngôn ngữ lập trình như Java, Scala, Python và R. Spark sử dụng thư viện máy khách của Hadoop để truy cập các nút dữ liệu HDFS, nghĩa là Spark được thiết kế để sử dụng bộ lưu trữ HDFS. Spark cung cấp khả năng trong Cụm dữ liệu lớn để thực hiện học máy (MLib), xử lý đồ thị (GraphX) và Spark Streaming. Theo tùy chọn, khách hàng có thể tách các dịch vụ Spark để tạo nhóm Spark chuyên dụng. Nhóm Spark chuyên dụng có thể mang lại lợi ích nếu khách hàng có kế hoạch sử dụng rộng rãi các dịch vụ Spark.
Ngoài phiên bản chính, Cụm dữ liệu lớn SQL Server 2019 còn bao gồm một số dịch vụ mở rộng quy mô. Ví dụ: nhóm điện toán cho phép giảm tải quá trình xử lý truy vấn phân tán sang dịch vụ mở rộng quy mô chuyên dụng. Trong quá trình thiết lập phòng thí nghiệm của chúng tôi, nhóm điện toán Cụm dữ liệu lớn có một hoặc nhiều phiên bản điện toán SQL Server chạy trong các vùng chứa trên mỗi nút giá PowerFlex. Các ví dụ khác về cách nhóm điện toán tăng tốc xử lý dữ liệu bao gồm:
- Các kết nối truy vấn kết hợp dữ liệu từ hai đối tượng trong cơ sở dữ liệu hoặc từ các nguồn dữ liệu bên ngoài. Với kết nối truy vấn, bạn có thể:
- Tham gia các thư mục HDFS với hàng nghìn tệp.
- Tham gia các bảng trong các tài nguyên dữ liệu khác nhau.
- Tham gia các bảng với các sơ đồ phân vùng hoặc phân phối dữ liệu khác nhau.
- Xuất dữ liệu di chuyển dữ liệu ra khỏi ứng dụng song song với bộ lưu trữ HDFS hoặc Azure Blob.
Hình sau đây minh họa cấu hình nhóm điện toán:
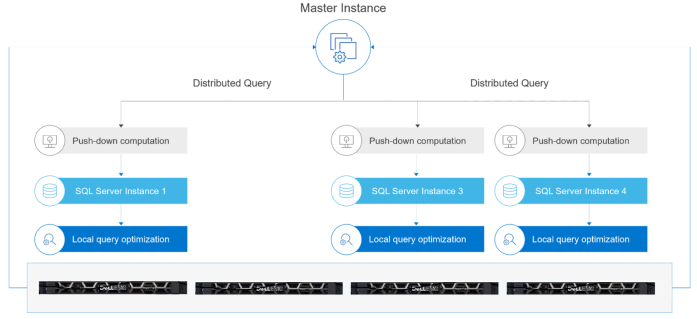
Hình 4. Cấu hình nhóm tính toán
Nhóm lưu trữ Cụm dữ liệu lớn SQL 2019 là một nhóm các nhóm lưu trữ các dịch vụ sau: công cụ SQL Server, nút dữ liệu HDFS và Spark. Nút dữ liệu HDFS lưu trữ và sao chép dữ liệu trên tất cả các nút trong vùng lưu trữ. Vì HDFS sao chép dữ liệu trong hầu hết các kiến trúc nên không cần RAID. Nút lưu trữ HDFS quản lý tất cả các hoạt động đọc và ghi vào nút.
Công cụ SQL Server có thể truy cập nguyên bản vào các nút dữ liệu HDFS, cung cấp khả năng sử dụng T-SQL với Cụm dữ liệu lớn. Do đó, tổ chức có thể sử dụng các báo cáo T – SQL hiện có và hoàn toàn được hưởng lợi từ trải nghiệm của nhà phát triển với T-SQL; các nhà phát triển không phải học một ngôn ngữ lập trình mới. Hình dưới đây hiển thị kiến trúc nhóm lưu trữ được Kubernetes cung cấp theo nhóm:
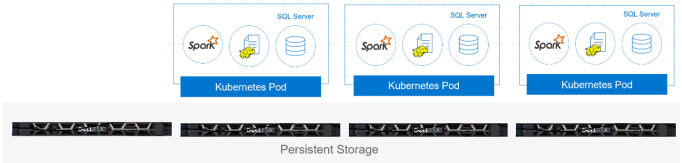
Hình 5. Kiến trúc vùng lưu trữ
Nhóm dữ liệu Cụm dữ liệu lớn SQL Server 2019 có một hoặc nhiều phiên bản SQL Server và được dùng để nhập dữ liệu từ các nguồn bên ngoài. Nhóm dữ liệu được quản lý từ phiên bản chính của SQL Server bằng cách sử dụng Ngôn ngữ định nghĩa dữ liệu (DDL) để quản lý cơ sở dữ liệu và các đối tượng của nó cũng như Ngôn ngữ thao tác dữ liệu (DML) để quản lý dữ liệu. Công dụng chính của nhóm dữ liệu là giảm tải các hoạt động xử lý dữ liệu từ phiên bản chính của SQL Server. Nhóm dữ liệu có thể tăng tốc xử lý dữ liệu vì nó sử dụng phân đoạn dữ liệu (phân vùng) trên các phiên bản SQL Server trong nhóm. Phân đoạn cơ sở dữ liệu là dữ liệu được phân phối trong các vùng chứa riêng biệt trên nhiều phiên bản cơ sở dữ liệu nằm trên các máy chủ riêng biệt. Hầu hết dữ liệu không bị trùng lặp hoặc sao chép, nghĩa là mỗi phân đoạn chứa một nguồn dữ liệu duy nhất. Sharding cải thiện hiệu suất bằng cách cho phép đọc nhiều dữ liệu song song trên nhiều phiên bản cơ sở dữ liệu, nhờ đó giảm thời gian cần thiết để hoàn thành một truy vấn.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...