
Tin tức
Cụm dữ liệu lớn của Microsoft SQL Server 2019: Giải pháp dữ liệu lớn sử dụng cơ sở hạ tầng Dell EMC (5)
Xác thực trong phòng thí nghiệm Cụm dữ liệu lớn của Microsoft SQL Server 2019
Tổng quan
Phần này mô tả rộng rãi cách chúng tôi cài đặt, định cấu hình và thử nghiệm Cụm dữ liệu lớn. Thay vì bao gồm các hướng dẫn từng bước, chúng tôi tập trung vào các yếu tố chính để triển khai Cụm dữ liệu lớn thành công và cung cấp liên kết đến các tài liệu nêu chi tiết các yêu cầu cài đặt.
Dựa trên giả định hoạt động rằng ảo hóa là một phần hiện có của trung tâm dữ liệu, chúng tôi không đề cập đến việc cài đặt VMware vSphere trong phần này. Nhiều bước áp dụng cho kim loại trần và ảo hóa; do đó, nếu tổ chức đang xem xét kim loại trần thì các bước vẫn được áp dụng.
Các bước cấp cao để cài đặt, định cấu hình và thử nghiệm giải pháp này như sau. Các phần tiếp theo cung cấp thêm chi tiết.
- Cài đặt Docker, Kubernetes và plug-in CSI cho hệ thống PowerFlex:
- Cài đặt Docker Enterprise Edition trong VM trên hệ thống PowerFlex. Hệ điều hành trong VM là Red Hat Linux Enterprise.
- Cài đặt và định cấu hình sổ đăng ký Docker riêng cục bộ.
- Cài đặt Kubernetes.
- Cài đặt plug-in CSI cho hệ thống PowerFlex.
- Triển khai cụm dữ liệu lớn:
- Kéo hình ảnh vùng chứa SQL Server 2019 Big Data Cluster cho Linux mới nhất từ Microsoft Container Register.
- Đẩy Cụm dữ liệu lớn SQL Server 2019 vào hình ảnh trong sổ đăng ký riêng cục bộ.
- Định cấu hình cung cấp lưu trữ động vSphere.
- Cài đặt cụm dữ liệu lớn.
- Nhập dữ liệu TPC-H vào Cụm dữ liệu lớn.
- Thử nghiệm ảo hóa dữ liệu.
- Di chuyển dữ liệu sang nhóm dữ liệu bằng cách nhập dữ liệu từ cơ sở dữ liệu SQL Server độc lập.
- Nhập 10 TB dữ liệu TPC-H vào Cụm dữ liệu lớn.
Bước 1: Cài đặt Docker, Kubernetes và plug-in CSI cho hệ thống PowerFlex
Bước 1a: Cài đặt Docker Enterprise Edition
Bước đầu tiên trong việc tạo môi trường dành cho nhà phát triển bằng cách sử dụng bộ chứa Docker là cấp phép và cài đặt thời gian chạy Docker.
Quản trị viên Docker cài đặt Phiên bản doanh nghiệp bằng cách chạy lệnh cài đặt sau:
$ yum -y cài đặt docker-ee-18.09.9 docker-ee-cli-18.09.9 containerd.io
Trong môi trường vSphere, VM giới hạn tài nguyên CPU và bộ nhớ. Sự cộng tác giữa quản trị viên ảo hóa và Docker rất quan trọng vì hầu hết các môi trường Docker đều có nhiều vùng chứa. Các máy ảo lưu trữ bộ chứa Docker có xu hướng có kích thước lớn hơn, đòi hỏi nhiều tài nguyên CPU và bộ nhớ hơn để hỗ trợ các bộ chứa.
Bước 1b: Cài đặt sổ đăng ký Docker
Vị trí đăng ký Docker là yếu tố quan trọng cần cân nhắc khi xây dựng môi trường phát triển/thử nghiệm. Các yếu tố ảnh hưởng đến vị trí đăng ký Docker bao gồm:
- Đa dạng —Số lượng hình ảnh trong sổ đăng ký
- Vận tốc —Tần suất cung cấp ứng dụng
- Bảo mật —Bảo vệ hình ảnh ứng dụng
Để xác thực trong phòng thí nghiệm của chúng tôi, chúng tôi đã sử dụng cơ quan đăng ký tư nhân tại địa phương, cơ quan này giải quyết các yêu cầu chính về chủng loại, tốc độ và bảo mật của chúng tôi.
Để tạo sổ đăng ký cục bộ từ Docker Hub , nhà phát triển chạy các lệnh sau:
$ docker kéo sổ đăng ký
$ mkdir -p /đăng ký/riêng tư
$ docker run -d -p 5000:5000 -name register -v /var/lib/registry –restart
Quản trị viên Docker phải hợp tác chặt chẽ với các kỹ sư mạng và chuyên gia bảo mật để giải quyết vấn đề về vị trí đăng ký Docker. Tùy thuộc vào kích thước của môi trường container, tốc độ có thể đặt tải đáng kể lên mạng. Hơn nữa, hình ảnh đăng ký tùy chỉnh có thể chứa các cài đặt cấu hình nhạy cảm phải được bảo mật.
Bước 1c: Cài đặt Kubernetes
Hiện nay có nhiều giải pháp Kubernetes. Ví dụ: các dịch vụ Kubernetes được quản lý bằng chìa khóa trao tay từ các nhà cung cấp đám mây cung cấp cho các tổ chức CNTT một giải pháp không cần đến trung tâm dữ liệu mà không cần cài đặt. Việc triển khai Kubernetes trên nền tảng đám mây riêng tại chỗ mang lại khả năng kiểm soát và tính linh hoạt cao hơn nhưng đòi hỏi phải đầu tư vào cơ sở hạ tầng và đào tạo. Đối với trường hợp sử dụng này, chúng tôi hiển thị bản cài đặt Kubernetes nguồn mở để chứng minh việc hệ thống điều phối vùng chứa trên mạng LAN của chúng tôi mang lại hiệu suất và khả năng kiểm soát cao hơn cũng như khả năng tùy chỉnh cấu hình như thế nào.
Cài đặt Kubernetes như sau.
Lưu ý : Để biết hướng dẫn cài đặt Kubernetes đầy đủ, hãy xem tài liệu Kubernetes .
mèo <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
tên=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
đã bật=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
loại trừ=kube*
EOF
# Đặt SELinux ở chế độ cho phép (vô hiệu hóa nó một cách hiệu quả)
thiết lập lực lượng 0
sed -i ‘s/^SELINUX=enforcing$/SELINUX=permissive/’ /etc/selinux/config
yum cài đặt -y kubelet kubeadm kubectl –disableexcludes=kubernetes
kích hoạt systemctl –now kubelet
Bước 1d: Cài đặt plug-in CSI cho hệ thống PowerFlex
Ngoài môi trường Kubernetes, chúng tôi cũng cần một plug-in CSI để hoàn thành hành trình tự động hóa của mình. Các plug-in CSI là một tiêu chuẩn do Kubernetes xác định mà Dell Technologies và các hãng khác sử dụng để hiển thị khối và lưu trữ tệp cho các hệ thống điều phối vùng chứa. Các plug-in CSI thống nhất việc quản lý lưu trữ trên nhiều hệ thống điều phối vùng chứa khác nhau bao gồm Mesos, Docker Swarm và Kubernetes.
Plug-in CSI cho hệ thống PowerFlex dành cho Kubernetes cung cấp các khả năng điều phối sau:
- Cung cấp động và ngừng hoạt động của khối lượng
- Đính kèm và tách khối lượng khỏi nút máy chủ
- Gắn và ngắt kết nối ổ đĩa từ nút máy chủ
- Khả năng chụp nhanh: tạo, xóa và liệt kê
Quản trị viên Kubernetes làm việc với quản trị viên lưu trữ để tải xuống, sửa đổi và cài đặt plug-in CSI như sau.
Lưu ý : Thông tin tổng quan có sẵn trên YouTube và trong hướng dẫn sản phẩm .
- Trên nút chính của Kubernetes, hãy chỉnh sửa tệp YAML và CONF.
- Cài đặt trình quản lý gói Helm.
- Cài đặt PowerFlex SDC.
- Tải xuống plugin từ GitHub:
$ git bản sao https://github.com/dell/csi-vxflexos
- Sửa đổi tệp CSI.ini để kết nối với mảng PowerFlex.
- Cài đặt trình cắm CSI trên nút đầu tiên:
$ sh cài đặt.vxflexos
Bộ lưu trữ PowerFlex sau đó có sẵn trong Kubernetes. Hình dưới đây cho thấy đầu ra kubectl get pod –n -vxflexos khi plug-in CSI đang chạy trên tất cả các nút công nhân Kubernetes:
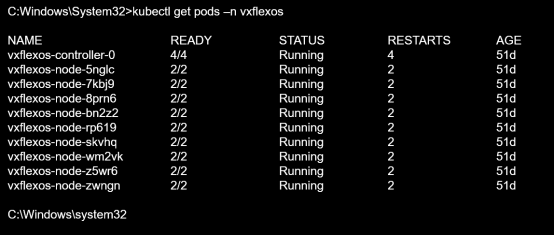
Hình 12. Plug-in CSI cho hệ thống PowerFlex, chạy trên nút công nhân Kubernetes
Hình dưới đây cho thấy cấu hình PowerFlex. Bằng cách sử dụng Tổng quan hệ thống, quản trị viên lưu trữ có thể dễ dàng hiểu được mức sử dụng dung lượng vật lý, số lượng ổ đĩa cũng như số lượng nút SDS và SDC.
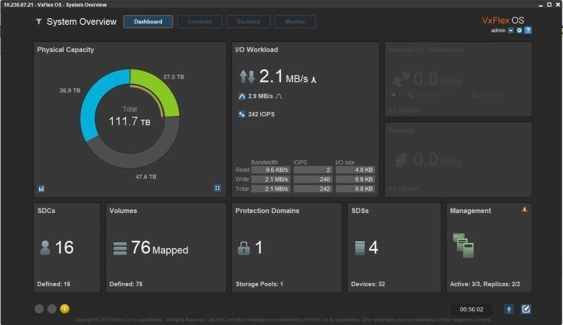
Hình 13. Cấu hình cụm PowerFlex
Bước 2: Triển khai cụm dữ liệu lớn
Quản trị viên Docker tải hình ảnh Cụm dữ liệu lớn mới nhất từ Sổ đăng ký vùng chứa của Microsoft xuống sổ đăng ký riêng cục bộ. Quản trị viên Docker cộng tác với quản trị viên SQL Server để đảm bảo rằng tất cả các yêu cầu đã nêu đối với hình ảnh Cụm dữ liệu lớn này đều được đáp ứng.
Lưu ý : Việc truy cập vào hình ảnh vùng chứa chất lượng cao từ một nguồn đáng tin cậy có thể tiết kiệm nhiều giờ lao động thường được yêu cầu để tạo và quản lý hình ảnh được xây dựng cục bộ từ các tệp Docker. Luôn kiểm tra các yêu cầu trước khi thử triển khai hình ảnh vùng chứa.
Để tải xuống image, quản trị viên Docker chạy lệnh Docker pull sau :
$ docker kéo mcr.start.com/mssql/bdc/ <SOURCE_IMAGE_NAME>;<SOURCE_DOCKER_TAG>
Lệnh kéo Docker này cho biết cách kéo hình ảnh theo cách thủ công từ các cơ quan đăng ký công cộng đáng tin cậy. Vì chúng tôi đang thực hiện cài đặt ngoại tuyến từ sổ đăng ký riêng cục bộ nên chúng tôi đã sử dụng tập lệnh Python để tự động kéo tất cả các hình ảnh được yêu cầu.
Thực hiện triển khai ngoại tuyến Cụm dữ liệu lớn SQL Server trong Microsoft SQL Docs nêu chi tiết các bước để tự động kéo các hình ảnh được yêu cầu. Các bước chính là:
- Tải xuống tập lệnh Python tự động đẩy hình ảnh Cụm dữ liệu lớn vào sổ đăng ký riêng cục bộ.
- Sử dụng bash shell, tải xuống tập lệnh có Curl :
cuộn tròn -o push-bdc-images-to-custom-private-repo.py “https://raw.githubusercontent.com/Microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster /triển khai/ngoại tuyến/push-bdc-images-to-custom-private-repo.py”
Bước 2b: Đẩy hình ảnh Cụm dữ liệu lớn vào sổ đăng ký riêng cục bộ
Để điền thủ công sổ đăng ký Docker riêng cục bộ với Cụm dữ liệu lớn, quản trị viên Docker chạy lệnh đẩy Docker sau :
$ docker đẩy localhost:5000/ <SOURCE_IMAGE_NAME>;<SOURCE_DOCKER_TAG>
Để tự động điền sổ đăng ký cục bộ, hãy chạy tập lệnh Microsoft Python bằng lệnh Linux:
sudo python push-bdc-images-to-custom-private-repo.py
Lưu ý : Nếu bạn tùy chỉnh hình ảnh vùng chứa Cụm dữ liệu lớn (chúng tôi không làm như vậy), hãy lưu các hình ảnh cơ sở và bất kỳ tùy chỉnh nào vào sổ đăng ký riêng tư cục bộ với các chú thích thích hợp, nếu được yêu cầu, cho trường hợp sử dụng của bạn.
Bước 2c: Định cấu hình cung cấp lưu trữ động vSphere
Một câu hỏi quan trọng liên quan đến việc triển khai môi trường Cụm dữ liệu lớn này liên quan đến việc cung cấp lưu trữ. Trong cơ sở hạ tầng kim loại trần, mặt phẳng điều khiển là Kubernetes. Nhưng khi vSphere là một phần của ngăn xếp ứng dụng, mặt phẳng điều khiển vẫn thuộc về Kubernetes hay vSphere?
Quản lý dựa trên chính sách lưu trữ vSphere (SPBM) cung cấp một mặt phẳng điều khiển thống nhất duy nhất cho các dịch vụ lưu trữ như Kubernetes. SPBM là một lớp trừu tượng cho phép thống nhất các dịch vụ lưu trữ khác nhau trong một khuôn khổ chung cho vSphere. Việc sử dụng SPBM cho phép quản trị viên vSphere quản lý bộ nhớ trong môi trường vùng chứa, như được mô tả trong hình sau:
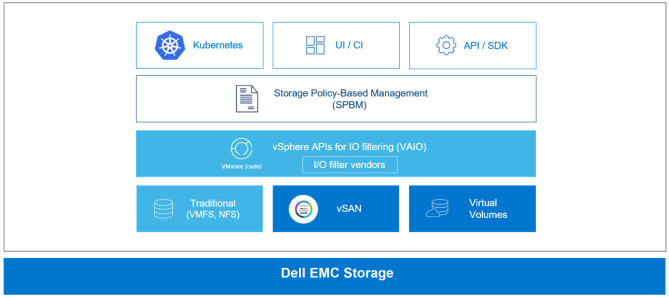
Hình 14. vSphere SPBM
Quá trình quản lý bao gồm việc tạo các định nghĩa StorageClass để cung cấp bộ nhớ động. Các tham số StorageClass được chứa trong tệp YAML. Các tham số trong file YAML cho VMFS và NFS bao gồm:
- định dạng đĩa : mỏng, không dày, háo hức
- storagePolicyName : <do người dùng xác định, ví dụ: gold>
Việc sử dụng các tham số StorageClass cho phép kiểm soát chi tiết việc cung cấp bộ nhớ liên tục. Sau khi xác định các lớp lưu trữ, Kubernetes có thể tạo PersistentVolumes cho Cụm dữ liệu lớn.
Lưu ý : Để tìm hiểu thêm về cách sử dụng vSphere để cung cấp động bộ lưu trữ trong môi trường Kubernetes, hãy xem Quản lý dựa trên chính sách lưu trữ trong VMware Docs.
Bước 2d: Cài đặt cụm dữ liệu lớn
Các điều kiện tiên quyết để cài đặt Cụm dữ liệu lớn bao gồm các công cụ cài đặt như Python, azdata và kubectl. Để biết các bước cài đặt chi tiết, hãy xem Thực hiện triển khai ngoại tuyến Cụm dữ liệu lớn của SQL Server trong Microsoft SQL Docs.
- Chạy lệnh sau để tạo bản sao của hồ sơ triển khai cơ sở trong thư mục tùy chỉnh từ nguồn bdc-test-profile01:
azdata bdc config init ––source bdc-test-profile –target custom
- Tùy chỉnh bản sao hồ sơ triển khai cơ sở cho cơ sở hạ tầng của bạn bằng cách sử dụng Visual Studio Code hoặc công cụ chỉnh sửa JSON tương tự.
- Chạy lệnh sau để cài đặt Cụm dữ liệu lớn:
azdata bdc tạo –-config-profile tùy chỉnh –accept-eula vâng
Trong khoảng 15 đến 30 phút, thông báo sau sẽ hiển thị trong cửa sổ nơi quá trình cài đặt bắt đầu, cho biết nhóm bộ điều khiển đã hoạt động và đang chạy:
Điểm cuối của bộ điều khiển cụm có sẵn tại <IP_address> : <port_number>
Mặt phẳng điều khiển cụm đã sẵn sàng.
Khi toàn bộ quá trình cài đặt hoàn tất, thông báo sau sẽ hiển thị:
Cụm được triển khai thành công.
Việc sử dụng sổ đăng ký riêng cục bộ đòi hỏi nhiều công việc nâng cao hơn nhưng sẽ tăng tốc đáng kể việc triển khai Cụm dữ liệu lớn. Ngược lại, quá trình cài đặt bằng Microsoft Container Register yêu cầu kéo tất cả các tệp hình ảnh qua Internet, việc này có thể mất hàng giờ cho mỗi lần cài đặt Cụm dữ liệu lớn.
Các lệnh hữu ích để kiểm tra tình trạng cài đặt bài cụm là:
- danh sách điểm cuối azdata bdc -o table —Cung cấp mô tả về từng dịch vụ với điểm cuối tương ứng
- hiển thị trạng thái azdata bdc —Hiển thị danh sách chi tiết về tên dịch vụ, trạng thái, tình trạng sức khỏe và thông tin chi tiết của chúng
Lợi ích chính của việc cài đặt Cụm dữ liệu lớn tự động
Sự đơn giản của các bước này làm lu mờ giá trị quan trọng đạt được thông qua việc cài đặt tự động các Cụm dữ liệu lớn. Kiến trúc ứng dụng rất phức tạp, bao gồm nhiều công cụ và ngăn xếp phần mềm có thể mất vài ngày hoặc vài tuần để hoàn thành thủ công. Trong bước này, azdata, Kubernetes và Docker phối hợp và tự động hóa quá trình cài đặt Cụm dữ liệu lớn trong vài phút hoặc vài giờ. Quá trình tự động hóa này phản ánh một trong những lợi ích cốt lõi của bộ chứa, đó là khả năng cung cấp Cụm dữ liệu lớn và các ứng dụng khác một cách nhanh chóng mà không cần phải thực hiện các bước tốn thời gian như phải cài đặt phần mềm theo cách thủ công.
Kubernetes và azdata kết hợp là công cụ tự động hóa và điều phối. Khi quá trình cài đặt Cụm dữ liệu lớn hoàn tất, các thùng chứa, cấu hình và bộ lưu trữ sẽ được cung cấp và cụm ở trạng thái sẵn sàng. Sự tự động hóa và điều phối này chuyển các Cụm dữ liệu lớn thành một nền tảng tự phục vụ, theo yêu cầu. Sau đó, tổ chức CNTT có thể dễ dàng thiết lập nhiều Cụm dữ liệu lớn cho các nhóm khác nhau trong tổ chức.
Một số Cụm dữ liệu lớn, bao gồm Cụm dữ liệu lớn dành cho nhà phát triển/thử nghiệm được làm mới thường xuyên, có thể chỉ cần dùng trong vài tháng. Các vùng chứa Docker được thiết kế để phù hợp—nghĩa là chúng có thể bị dừng và phá hủy một cách dễ dàng, đồng thời các vùng chứa mới có thể được tạo từ cùng một hình ảnh và được đưa vào vị trí với thiết lập và cấu hình tối thiểu. Bản chất phù du của vùng chứa Docker lý tưởng cho các kịch bản phát triển/thử nghiệm, trong đó hầu hết các nhà phát triển và thành viên khác trong nhóm chỉ sử dụng vùng chứa trong một thời gian ngắn.
Bước 2e: Nhập dữ liệu TPC-H vào Cụm dữ liệu lớn
Bạn có thể nhập dữ liệu vào Cụm dữ liệu lớn thông qua bất kỳ phương pháp nào sau đây:
- Tải dữ liệu vào vùng lưu trữ bằng cách sử dụng tiện ích cuộn tròn. Xem Sử dụng cuộn tròn để nhập dữ liệu .
- Tải dữ liệu vào nhóm dữ liệu bằng cách sử dụng SQL Server và T-SQL. Xem Sử dụng SQL Server và T-SQL để nhập dữ liệu .
- Tải dữ liệu vào nhóm dữ liệu bằng cách sử dụng công việc Spark. Xem Sử dụng công việc Spark để nhập dữ liệu .
Phương pháp tối ưu để nhập dữ liệu phụ thuộc vào lượng dữ liệu, loại dữ liệu và vị trí mục tiêu của dữ liệu. Ví dụ: nếu mục tiêu là nhập tệp vào nhóm lưu trữ (nút dữ liệu HDFS), thì việc sử dụng dòng lệnh Curl sẽ hoạt động tốt. Ngược lại, việc sử dụng các công việc SQL Server và Spark hoạt động tốt nếu mục tiêu là nhập dữ liệu vào nhóm dữ liệu. Trong trường hợp sử dụng này, mục tiêu là nhập khoảng 1 TB dữ liệu TPC-H vào nhóm lưu trữ Cụm dữ liệu lớn, với các bảng nhỏ hơn sẽ đưa vào cơ sở dữ liệu Oracle độc lập và cơ sở dữ liệu SQL Server độc lập.
Dữ liệu TPC-H sử dụng tám bảng riêng biệt và riêng biệt. Các bảng lớn hơn với nhiều hàng hơn đã được đưa vào nhóm dữ liệu Cụm dữ liệu lớn. Các bảng kích thước trung bình đã được đưa vào cơ sở dữ liệu SQL Server độc lập không liên quan đến cấu hình Cụm dữ liệu lớn. Cuối cùng, các bảng nhỏ nhất đã được đưa vào cơ sở dữ liệu Oracle. Mục tiêu là đặt các bảng lớn nhất trong Cụm dữ liệu lớn. Bảng sau đây tóm tắt nơi dữ liệu TPC – H được nhập:
Bảng 2. Vị trí dữ liệu TPC-H sau khi nhập
| Vị trí dữ liệu | Bàn | Hệ số tỷ lệ (SF) | Kích thước bàn |
| Nhóm lưu trữ cụm dữ liệu lớn | BỘ PHẬN | SF * 800.000 | Lớn |
| Nhóm lưu trữ cụm dữ liệu lớn | MỤC HÀNG | SF * 6.000.000 | Lớn |
| Nhóm lưu trữ cụm dữ liệu lớn | ĐƠN HÀNG | SF * 1.500.000 | Lớn |
| Nhóm lưu trữ cụm dữ liệu lớn | KHÁCH HÀNG | SF * 150.000 | Trung bình |
| Máy chủ SQL | PHẦN | SF * 200.000 | Trung bình |
| Máy chủ SQL | CÁC NHÀ CUNG CẤP | SF * 10.000 | Trung bình |
| Lời tiên tri | QUỐC GIA | 25 | Bé nhỏ |
| Lời tiên tri | VÙNG ĐẤT | 5 | Bé nhỏ |
Cột hệ số tỷ lệ trong bảng đề cập đến kích thước của cơ sở dữ liệu TPC-H tính bằng gigabyte. Trong trường hợp sử dụng của chúng tôi, kích thước cơ sở dữ liệu là 1.000 GB (1 TB); do đó, hệ số tỷ lệ là 1.000. Để tính số hàng trong một bảng, hãy nhân SF với số hàng cơ sở. Ví dụ: đối với bảng đầu tiên, PARTSUPP:
1.000 (SF) * 800.000 = 8.000.000.000 hàng.
Để biết thêm thông tin, hãy xem TPC Benchmark H.
Lợi ích chính của việc nhập dữ liệu Cụm dữ liệu lớn
Một trong những giá trị cốt lõi của Cụm dữ liệu lớn là khả năng dễ dàng tiếp nhận dữ liệu lớn. Trong trường hợp sử dụng của chúng tôi, chúng tôi đã sử dụng tính năng cuộn tròn để nhập khoảng 1 TB dữ liệu hỗ trợ quyết định. Các hướng dẫn trong Microsoft SQL Docs đã cho phép các chuyên gia SQL Server của chúng tôi bắt đầu nhập dữ liệu một cách nhanh chóng. Trong quá trình thử nghiệm, chúng tôi đã thực hiện thêm một bước để tối ưu hóa hiệu suất bằng cách chuyển từ tệp giá trị được phân tách bằng dấu phẩy (CSV) trong tệp HDFS sang tệp Parquet, như được mô tả trong Sử dụng cuộn tròn để nhập dữ liệu .
Bằng cách đặt các bảng trung bình trong cơ sở dữ liệu SQL Server độc lập và các bảng nhỏ hơn trong cơ sở dữ liệu Oracle, các thử nghiệm ảo hóa dữ liệu của chúng tôi sẽ xác thực:
- Truy cập vào dữ liệu khác nhau ở dạng gốc —Khả năng truy cập dữ liệu mà không cần bất kỳ chuyển đổi nào.
- Truy cập dữ liệu bên ngoài Cụm dữ liệu lớn —Khả năng truy cập dữ liệu ở hầu hết mọi nơi và không cần sửa đổi, nghĩa là không cần phải sửa đổi hoặc cài đặt tác nhân trên nguồn dữ liệu để hỗ trợ truy cập dữ liệu.
Sử dụng Curl để nhập dữ liệu
Curl là một công cụ dòng lệnh được thiết kế để truyền dữ liệu qua một loạt giao thức. Lợi ích của việc sử dụng Curl là khả năng đưa các tệp cục bộ vào HDFS, đây là phương pháp mà chúng tôi đã sử dụng trong quá trình thử nghiệm trong phòng thí nghiệm của mình.
Chúng tôi đã xóa dữ liệu TPC-H và lưu nó vào tệp CSV. Sau đó, chúng tôi đã sử dụng tập lệnh PowerShell để tự động tạo và chạy cuộn tròn nhằm nhập tệp CSV vào HDFS. Một phần của tập lệnh tạo thư mục HDFS:
cuộn tròn -L -k -u root:%KNOX_PASSWORD% -X PUT “https://%KNOX_ENDPOINT%/gateway/webhdfs/v1/%DIR_NAME%/csv/PART?OP=MKDIRS”
Ở đâu:
- %KNOX_PASSWORD% là mật khẩu của người dùng root cho cổng Apache KNOX.
- %KNOX_ENDPOINT% là IP và cổng KNOX ở định dạng <KNOX_IP> : <KNOX_PORT> .
- %DIR_NAME% là tên thư mục sẽ được tạo tại HDFS (nếu chưa tồn tại); các tệp CSV sẽ được tải lên vị trí này.
Sau đó, chúng tôi đặt các tệp CSV vào thư mục HDFS:
Curl -L -k -u root:%KNOX_PASSWORD% -X PUT https://%KNOX_ENDPOINT%/gateway/webhdfs/v1/%DIR_NAME%/csv/part/final_F00001_part.csv?op=create&overwrite=true -H “Nội dung -type:application/octet-stream” -T “C:\stage\ps\v5\final\part\final_F00001_part.csv”
Trong lệnh cuộn tròn cuối cùng, tên tệp là Final_F00001_part.csv vì tệp CSV được chia thành tám phần và được đặt trong nhóm lưu trữ HDFS. Đối với mỗi tệp trong số tám tệp, số trong tên tệp được tăng lên (00001–00008). Việc chia tệp thành tám phần cho phép phân phối dữ liệu trên các nút trong nhóm lưu trữ, giúp tối ưu hóa hiệu suất.
Ngoài ra, để cải thiện hiệu suất và tiết kiệm dung lượng, chúng tôi đã chuyển đổi tệp CSV trong HDFS sang tệp Parquet. Parquet là một công cụ Apache Software Foundation được sử dụng để chuyển đổi tệp thành dữ liệu cột. Khi dữ liệu ở dạng cột, Parquet có thể nén và mã hóa nó một cách hiệu quả.
Sử dụng SQL Server và T-SQL để nhập dữ liệu
Cách thứ hai để nhập dữ liệu là đưa dữ liệu vào nhóm dữ liệu bằng cách sử dụng SQL Server và T ‑ SQL. Bước đầu tiên trong quy trình này là tạo một bảng bên ngoài trong vùng dữ liệu. Bảng bên ngoài là một đối tượng cho phép PolyBase truy cập dữ liệu được lưu trữ bên ngoài cơ sở dữ liệu. Bằng cách sử dụng bảng bên ngoài, như được mô tả trong các bước sau, PolyBase có thể truy cập dữ liệu trong cơ sở dữ liệu Oracle, cụm Hadoop, bộ lưu trữ blob Azure và, như trong các thử nghiệm trong phòng thí nghiệm của chúng tôi, tệp văn bản có dữ liệu TPC-H:
- Kết nối với phiên bản chính của SQL Server và tạo nguồn dữ liệu ngoài cho cơ sở dữ liệu từ xa:
NẾU KHÔNG Tồn tại( CHỌN * TỪ sys.external_data_sources
Tên WHERE = ‘SqlDataPool’)
TẠO NGUỒN DỮ LIỆU BÊN NGOÀI SqlDataPool
VỚI ( VỊ TRÍ = ‘sqldatapool://controller-svc/default’);
ĐI
- Tạo lược đồ tại nhóm lưu trữ (HDFS) đóng vai trò là bảng nguồn ( EXT_HDFS_PARTSUPP ) trên nhóm lưu trữ và trỏ đến các tệp sàn gỗ trên thư mục /TPCH1TB/parquet/partsupp trên HDFS:
SỬ DỤNG [TPCH1TB]
ĐI
NẾU KHÔNG Tồn tại (CHỌN * TỪ sys.external_tables Tên WHERE = ‘EXT_HDFS_PARTSUPP’)
TẠO BẢNG NGOÀI EXT_HDFS_PARTSUPP (
“PS_PARTKEY” BIGINT KHÔNG NULL,
“PS_SUPPKEY” lớn,
INT “PS_AVAILQTY”,
nổi “PS_SUPPLYCOST”,
“PS_COMMENT” VARCHAR(199)
)
VỚI
(
DATA_SOURCE = SqlStoragePool,
VỊ TRÍ = ‘/TPCH1GB/sàn gỗ/bộ phận’,
FILE_FORMAT = tập tin sàn gỗ
);
ĐI
- Tạo một bảng bên ngoài có tên EXT_DP_PARTSUPP trong nhóm dữ liệu với phân phối dữ liệu theo vòng tròn:
NẾU KHÔNG Tồn tại (CHỌN * TỪ sys.external_tables Tên WHERE = ‘EXT_DP_PARTSUPP’)
TẠO BẢNG BÊN NGOÀI [ EXT_DP_PARTSUPP ] (
“PS_PARTKEY” BIGINT KHÔNG NULL,
“PS_SUPPKEY” lớn,
INT “PS_AVAILQTY”,
nổi “PS_SUPPLYCOST”,
“PS_COMMENT” VARCHAR(199)
)
VỚI (
DATA_SOURCE = SqlDataPool,
PHÂN PHỐI = ROUND_ROBIN
);
ĐI
- Nhập dữ liệu vào nhóm dữ liệu:
CHÈN VÀO EXT_DP_PARTSUPP(
“PS_PARTKEY”,
“PS_SUPPKEY”,
“PS_AVAILQTY”,
“PS_SUPPLYCOST”,
“PS_COMMENT”
)
LỰA CHỌN
“PS_PARTKEY”,
“PS_SUPPKEY”,
“PS_AVAILQTY”,
“PS_SUPPLYCOST”,
“PS_COMMENT”
TỪ EXT_HDFS_PARTSUPP
ĐI
- Để kiểm tra xem quá trình nhập có thành công hay không, hãy chọn số đếm từ bảng bên ngoài để hiển thị số hàng:
Chọn số lượng(1) từ [owner_name].[tên bảng bên ngoài]
Ví dụ:
Chọn số lượng (1) từ [dbo].[EXT_DP_PARTSUPP]
Sử dụng công việc Spark để nhập dữ liệu
Cách thứ ba để nhập dữ liệu là sử dụng công việc Spark. Các bước sau đây cung cấp thông tin khái quát về cách nhập dữ liệu bằng công việc Spark.
Lưu ý : Để biết các bước chi tiết, hãy xem Hướng dẫn: Nhập dữ liệu vào nhóm dữ liệu SQL Server với các công việc Spark trong Microsoft SQL Docs.
- Tạo nguồn dữ liệu ngoài.
- Tạo một bảng bên ngoài.
Xem ví dụ trong Sử dụng SQL Server và T-SQL để nhập dữ liệu .
- Định cấu hình các tham số của trình kết nối Spark-SQL và chạy công việc Spark.
Bước 2f: Kiểm tra ảo hóa dữ liệu
Sau khi dữ liệu hỗ trợ quyết định được đưa vào Cụm dữ liệu lớn , SQL Server và Oracle, hãy kiểm tra ảo hóa dữ liệu:
- Tạo nguồn dữ liệu cho Cụm dữ liệu lớn và Oracle.
Nguồn dữ liệu là một hàng trong bảng sys.external_data_sources trong cơ sở dữ liệu SQL Server chính của Cụm dữ liệu lớn . Hàng chứa tên, nguồn và vị trí của nguồn dữ liệu. Việc tạo nguồn dữ liệu cho phép PolyBase trong Cụm dữ liệu lớn truy cập vào các hệ thống cơ sở dữ liệu khác.
Lưu ý : Cơ sở dữ liệu SQL Server độc lập không yêu cầu nguồn dữ liệu vì Cụm dữ liệu lớn có thể truy cập dữ liệu một cách tự nhiên.
- Chạy tập lệnh sau để tạo nguồn dữ liệu cho nhóm lưu trữ Cụm dữ liệu lớn:
NẾU KHÔNG Tồn tại( CHỌN * TỪ sys.external_data_sources WHERE name = ‘SqlStoragePool’)
TẠO NGUỒN DỮ LIỆU BÊN NGOÀI SqlStoragePool
VỚI (VỊ TRÍ = ‘sqlhdfs://controller-svc/default’);
- Tạo nguồn dữ liệu cho cơ sở dữ liệu Oracle như sau:
i Tạo khóa chính để mã hóa mật khẩu cơ sở dữ liệu:
TẠO MÃ HÓA CHÍNH BẰNG MẬT KHẨU = ‘@StrongPasword!!!’;
ii Tạo thông tin xác thực để kết nối với cơ sở dữ liệu Oracle trong phiên bản SQL Server chính.
Lệnh T-SQL sau đây gán tên (oracle_cred) và lưu tài khoản người dùng (oracle_user) bằng mật khẩu đã được tạo ở bước trước:
TẠO CƠ SỞ CƠ SỞ DỮ LIỆU CÓ QUYỀN XÁC NHẬN oracle_cred
VỚI IDENTITY = ‘oracle_user’, SECRET = ‘StrongOraclePassword!!!!’;
iii Chạy lệnh T-SQL sau để hoàn tất việc tạo nguồn dữ liệu cho cơ sở dữ liệu Oracle:
TẠO NGUỒN DỮ LIỆU BÊN NGOÀI Oracle_Data_Source
VỚI
( VỊ TRÍ = ‘oracle:// <Oracle_instance_IP> : <Oracle_Instance_Port> ‘
, CREDENTIAL = oracle_cred
);
- Tạo các bảng bên ngoài xác định DDL của các bảng từ xa.
Đối với Cụm dữ liệu lớn:
Đối với các bảng được nhập vào nhóm lưu trữ Cụm dữ liệu lớn , tập lệnh bảng bên ngoài như sau:
NẾU KHÔNG Tồn tại (CHỌN * TỪ sys.external_tables Tên WHERE = ‘EXT_HDFS_ORDERS’)
TẠO BẢNG NGOÀI EXT_HDFS_ORDERS (
“O_ORDERKEY” bigint KHÔNG NULL, “O_CUSTKEY” bigint KHÔNG NULL,
Ký tự “O_ORDERSTATUS” (1) KHÔNG NULL,
Số thập phân “O_TOTALPRICE”(12, 2) KHÔNG NULL,
Ngày “O_ORDERDATE” KHÔNG NULL,
Ký tự “O_ORDERPRIORITY”(15) KHÔNG NULL,
Ký tự “O_CLERK” (15) KHÔNG NULL,
“O_SHIPPRIORITY” int KHÔNG NULL,
“O_COMMENT” varchar(79) KHÔNG NULL
)
VỚI
(
DATA_SOURCE = SqlStoragePool,
VỊ TRÍ = ‘/TPCH1GB/sàn gỗ/đơn hàng’,
FILE_FORMAT = tập tin sàn gỗ
);
ĐI
Kịch bản này:
- Sử dụng tên bảng để dễ dàng xác định loại bảng (EXT), vị trí (HDFS) và tên (PHẦN); do đó, tên bảng đầy đủ là: EXT_HDFS_PART
- Sử dụng DDL để xác định bảng
- Tham chiếu nguồn dữ liệu và vị trí
- Tham chiếu định dạng tệp—trong trường hợp này là tệp Parquet trong vùng lưu trữ HDFS
Đối với cơ sở dữ liệu Oracle:
Tập lệnh tạo bảng bên ngoài cho cơ sở dữ liệu Oracle tương tự như tập lệnh cho nhóm lưu trữ Cụm dữ liệu lớn:
TẠO BẢNG NGOÀI EXT_ORA_REGION (
“R_REGIONKEY” int,
“R_NAME” Varchar(25) THU THẬP Latin1_General_100_BIN2_UTF8,
“R_COMMENT” VARCHAR(152) THU THẬP Latin1_General_100_BIN2_UTF8)
VỚI (DATA_SOURCE=bdcOracleDataSource,
VỊ TRÍ=’ <cơ sở dữ liệu oracle> . <lược đồ oracle> .REGION’);
ĐI
Đối với trường hợp sử dụng này, chúng tôi đã tạo các bảng bên ngoài bổ sung cho các bảng có liên quan trong HDFS và Oracle.
- Thực hiện tự động hóa container.
Khi quá trình thiết lập kết nối và xác định nguồn dữ liệu ngoài hoàn tất, quá trình chuyển đổi sang ảo hóa dữ liệu sẽ diễn ra liền mạch. Hiện tại, có hai phương pháp tự động hóa vùng chứa cần xem xét—sử dụng hình ảnh hoặc tập lệnh tùy chỉnh.
Nếu tổ chức cần làm mới môi trường Cụm dữ liệu lớn thì việc lưu trạng thái của các vùng chứa hiện có dưới dạng hình ảnh tùy chỉnh trong sổ đăng ký sẽ cho phép tổ chức triển khai môi trường Cụm dữ liệu lớn với cấu hình ảo hóa dữ liệu đã hoàn tất. Với hình ảnh Cụm dữ liệu lớn tùy chỉnh , nhà phát triển và nhà khoa học dữ liệu có thể bắt đầu làm việc mà không cần phải chờ thiết lập bổ sung.
Một cách tiếp cận khác là tự động hóa thông qua kịch bản. Khi thử nghiệm Cụm dữ liệu lớn, các chuyên gia của chúng tôi đã tạo các tập lệnh để tự động hóa các bước thủ công như tạo kết nối với tài nguyên dữ liệu bên ngoài. Là một phần của công việc xác thực, Cụm dữ liệu lớn đã được làm mới để đảm bảo rằng các bước có thể lặp lại. Việc triển khai container ban đầu mất khoảng 3 giờ. Mọi hoạt động làm mới hệ thống Cụm dữ liệu lớn đều mất khoảng 30 phút. Việc viết kịch bản cho các bước sau cài đặt đã hoạt động tốt và cho phép các nhóm bắt đầu sử dụng Cụm dữ liệu lớn một cách nhanh chóng.
- Chạy truy vấn T-SQL sử dụng tất cả các bảng hỗ trợ quyết định.
Khả năng truy cập cả ba nguồn dữ liệu mà không cần bất kỳ chuyển đổi dữ liệu nào chứng tỏ giá trị của ảo hóa dữ liệu. Điểm chuẩn TPC-H có một số truy vấn chạy dựa trên dữ liệu hỗ trợ quyết định. Chúng tôi đã chọn truy vấn TPC-H 8, được gọi là Thị phần Quốc gia, để kiểm tra cấu hình ảo hóa dữ liệu của chúng tôi:
/* TPC_H Truy vấn 8 – Thị phần quốc gia */
LỰA CHỌN O_YEAR,
TỔNG (TRƯỜNG HỢP KHI QUỐC GIA = ‘TRUNG QUỐC’
SAU ĐÓ ÂM LƯỢNG
KHÁC 0
KẾT THÚC) / TỔNG (ÂM LƯỢNG) NHƯ MKT_SHARE
TỪ ( LỰA CHỌN ngày tháng (yy,O_ORDERDATE) NHƯ O_NĂM,
L_EXTENDEDPRICE * (1-L_DISCOUNT) NHƯ KHỐI LƯỢNG,
N2.N_NAME NHƯ QUỐC GIA
TỪ EXT_HDFS_PART, — Trỏ tới HDFS
NHÀ CUNG CẤP, — Trỏ tới SQL Server
EXT_HDFS_LINEITEM, — Trỏ tới HDFS
EXT_HDFS_ORDERS, — Trỏ tới HDFS
EXT_HDFS_CUSTOMER, — Trỏ tới HDFS
EXT_ORA_NATION N1, — Trỏ tới Oracle
EXT_ORA_NATION N2, — Trỏ tới Oracle
EXT_ORA_REGION — Trỏ tới Oracle
Ở ĐÂU P_PARTKEY = L_PARTKEY VÀ
S_SUPPKEY = L_SUPPKEY VÀ
L_ORDERKEY = O_ORDERKEY VÀ
O_CUSTKEY = C_CUSTKEY VÀ
C_NATIONKEY = N1.N_NATIONKEY VÀ
N1.N_REGIONKEY = R_REGIONKEY VÀ
R_NAME = ‘CHÂU Á’ VÀ
S_NATIONKEY = N2.N_NATIONKEY VÀ
O_ORDERDATE GIỮA ‘1995-01-01’ VÀ ‘1996-12-31’ VÀ
P_TYPE = ‘ĐỒNG CHẢI NHỎ’
) BẰNG TẤT CẢ_NATIONS
NHÓM QUA O_YEAR
ĐẶT HÀNG QUA O_YEAR
Phần nội dung của truy vấn (giữa FROM và WHERE) hiển thị tất cả các bảng đã chọn. Truy vấn này sử dụng bảy trong số tám bảng trong tiêu chuẩn hỗ trợ quyết định. (PARTSUPP không được chọn.) Trong số bảy bảng được chọn, mỗi nguồn trong số ba nguồn dữ liệu đã được sử dụng:
- Cụm BDC: EXT_HDFS_PART, EXT_HDFS_LINEITEM, EXT_HDFS_ORDERS, EXT_HDFS_CUSTOMER
- Máy chủ SQL: NHÀ CUNG CẤP
- Cơ sở dữ liệu Oracle: EXT_ORA_SUPPIER, EXT_ORA_NATION
Truy vấn hoàn thành nhanh chóng mà không có lỗi. PolyBase với Big Data Clusters cho phép ảo hóa dữ liệu.
Lợi ích chính của việc triển khai Cụm dữ liệu lớn với ảo hóa dữ liệu
Các nhà khoa học và nhà phát triển dữ liệu hiện có thể truy cập cơ sở dữ liệu bên ngoài mà không cần phải chuyển đổi dữ liệu hoặc di chuyển dữ liệu vào kho dữ liệu hoặc hồ dữ liệu. Trong trường hợp sử dụng này, ảo hóa dữ liệu đã đơn giản hóa việc truy cập dữ liệu và loại bỏ sự phức tạp liên quan đến các quy trình ETL. Ít phức tạp hơn có thể giúp tiết kiệm thời gian. Hơn nữa, trong quá trình thử nghiệm Cụm dữ liệu lớn với ảo hóa dữ liệu PolyBase, chúng tôi đã trải nghiệm kết nối nhanh chóng ấn tượng với các nguồn dữ liệu bên ngoài.
Cụm dữ liệu lớn thống nhất và tập trung dữ liệu lớn và kết nối với các nguồn dữ liệu bên ngoài. Việc kết hợp dữ liệu lớn và ảo hóa dữ liệu mang lại cho các nhà khoa học dữ liệu một nơi để truy cập thông tin. Truy cập dữ liệu tập trung, một bộ công cụ chung và khả năng truy cập thông tin ít phức tạp hơn mang lại nền tảng để tăng năng suất.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...