
Tin tức
Đào tạo bác sĩ X quang AI bằng phương pháp học sâu phân tán
Tiềm năng của mạng lưới thần kinh trong việc chuyển đổi hoạt động chăm sóc sức khỏe là điều hiển nhiên. Từ phân loại hình ảnh đến đọc chính tả và dịch thuật, mạng lưới thần kinh đang đạt hoặc vượt quá khả năng của con người. Và họ chỉ thực hiện tốt hơn những nhiệm vụ này khi số lượng dữ liệu tăng lên.
Nhưng có một cách khác mà mạng lưới thần kinh có thể biến đổi ngành chăm sóc sức khỏe: Kiến thức có thể được nhân rộng mà hầu như không mất phí. Lấy X quang làm ví dụ: Để đào tạo 100 bác sĩ X quang, bạn phải dạy cho mỗi cá nhân những kỹ năng cần thiết để xác định bệnh qua hình ảnh chụp X quang cơ thể bệnh nhân. Để tạo ra 100 trợ lý bác sĩ X quang hỗ trợ AI, bạn lấy mô hình mạng thần kinh mà bạn đã đào tạo để đọc hình ảnh X-quang và tải nó vào 100 thiết bị khác nhau.
Rào cản là đào tạo mô hình. Cần một lượng lớn dữ liệu được làm sạch, sắp xếp và dán nhãn để huấn luyện một mô hình phân loại hình ảnh. Khi bạn đã chuẩn bị xong dữ liệu huấn luyện, có thể mất vài ngày, vài tuần hoặc thậm chí vài tháng để huấn luyện mạng lưới thần kinh. Ngay cả khi bạn đã huấn luyện một mô hình mạng nơ-ron, nó có thể không đủ thông minh để thực hiện nhiệm vụ mong muốn. Vì vậy, bạn thử lại. Và một lần nữa. Cuối cùng, bạn sẽ đào tạo một mô hình vượt qua bài kiểm tra và có thể được sử dụng trên thế giới.
 Quy trình phát triển mô hình mạng lưới thần kinhTrong bài đăng này, tôi sẽ nói về cách giảm thời gian dành cho chu trình Đào tạo/Kiểm tra/Điều chỉnh bằng cách tăng tốc phần đào tạo với học sâu phân tán, sử dụng trường hợp thử nghiệm mà chúng tôi đã phát triển trong Phòng thí nghiệm đổi mới HPC & AI của Dell EMC để phân loại các bệnh lý trên hình ảnh X quang ngực. Thông qua sự kết hợp giữa học sâu phân tán, lựa chọn trình tối ưu hóa và lựa chọn cấu trúc liên kết mạng thần kinh, chúng tôi không chỉ có thể tăng tốc quá trình đào tạo mô hình từ vài ngày đến vài phút mà còn có thể cải thiện đáng kể độ chính xác phân loại.
Quy trình phát triển mô hình mạng lưới thần kinhTrong bài đăng này, tôi sẽ nói về cách giảm thời gian dành cho chu trình Đào tạo/Kiểm tra/Điều chỉnh bằng cách tăng tốc phần đào tạo với học sâu phân tán, sử dụng trường hợp thử nghiệm mà chúng tôi đã phát triển trong Phòng thí nghiệm đổi mới HPC & AI của Dell EMC để phân loại các bệnh lý trên hình ảnh X quang ngực. Thông qua sự kết hợp giữa học sâu phân tán, lựa chọn trình tối ưu hóa và lựa chọn cấu trúc liên kết mạng thần kinh, chúng tôi không chỉ có thể tăng tốc quá trình đào tạo mô hình từ vài ngày đến vài phút mà còn có thể cải thiện đáng kể độ chính xác phân loại.
Điểm khởi đầu: CheXNet của Đại học Stanford
Chúng tôi bắt đầu bằng việc khảo sát bối cảnh các dự án AI trong lĩnh vực chăm sóc sức khỏe và nhóm của Andrew Ng tại Đại học Stanford đã cung cấp điểm khởi đầu cho chúng tôi. CheXNet là một dự án chứng minh khả năng của mạng lưới thần kinh trong việc phân loại chính xác các trường hợp viêm phổi trong hình ảnh chụp X-quang ngực.
Tập dữ liệu mà Stanford sử dụng là ChestXray14 , được phát triển và cung cấp bởi Viện Y tế Quốc gia Hoa Kỳ (NIH). Bộ dữ liệu chứa hơn 120.000 hình ảnh chụp X-quang ngực trước, mỗi hình ảnh có khả năng được gắn nhãn với một hoặc nhiều trong số mười bốn bệnh lý lồng ngực khác nhau. Tập dữ liệu rất mất cân bằng, với hơn một nửa số hình ảnh trong tập dữ liệu không có bệnh lý nào được liệt kê.
Stanford đã quyết định sử dụng DenseNet , một cấu trúc liên kết mạng thần kinh vừa được công bố là Bài báo hay nhất tại Hội nghị về Thị giác máy tính và Nhận dạng mẫu (CVPR) năm 2017, để giải quyết vấn đề. Cấu trúc liên kết DenseNet là một mạng sâu gồm các khối lặp lại trên các cấu trúc phức tạp được liên kết với các kết nối còn lại. Các khối kết thúc bằng việc chuẩn hóa hàng loạt, theo sau là một số phép chập và gộp bổ sung để liên kết các khối. Ở cuối mạng, một lớp được kết nối đầy đủ sẽ được sử dụng để thực hiện phân loại.
 Hình minh họa cấu trúc liên kết DenseNet (nguồn: Kaggle)
Hình minh họa cấu trúc liên kết DenseNet (nguồn: Kaggle)
Nhóm của Stanford đã sử dụng cấu trúc liên kết DenseNet với các trọng số lớp được huấn luyện trước trên ImageNet và thay thế lớp phân loại ImageNet ban đầu bằng một lớp mới gồm 14 nơ-ron được kết nối đầy đủ, mỗi lớp cho mỗi bệnh lý trong bộ dữ liệu ChestXray14.
Xây dựng CheXNet ở Keras
Có vẻ như việc thiết lập sẽ khó khăn. Rất may, Keras (được cung cấp cùng với TensorFlow) cung cấp một cách đơn giản, dễ hiểu để sử dụng các cấu trúc liên kết mạng thần kinh tiêu chuẩn và cài đặt các lớp phân loại mới.
từ máy ảnh nhập khẩu tensorflow từ keras.applications nhập DenseNet121 orig_net = DenseNet121(include_top=False,weights='imagenet', input_shape=(256,256,3))
Trong đoạn mã này, chúng tôi đang nhập mạng thần kinh DenseNet ban đầu (DenseNet121) và xóa lớp phân loại bằng đối số include_top=False . Chúng tôi cũng tự động nhập trọng số ImageNet đã được huấn luyện trước và đặt kích thước hình ảnh thành 256×256, với 3 kênh (đỏ, lục, lam).
Với mạng ban đầu được nhập, chúng ta có thể bắt đầu xây dựng lớp phân loại. Nếu bạn nhìn vào hình minh họa của DenseNet ở trên, bạn sẽ nhận thấy rằng lớp phân loại được đặt trước một lớp gộp. Chúng ta có thể thêm lớp tổng hợp này trở lại mạng mới bằng một lệnh gọi hàm Keras và chúng ta có thể gọi cấu trúc liên kết kết quả là bộ lọc của mạng thần kinh hoặc một phần của mạng thần kinh trích xuất tất cả các tính năng chính được sử dụng để phân loại.
từ keras.layers nhập GlobalAveragePooling2D bộ lọc = GlobalAveragePooling2D()(orig_net.output)
Nhiệm vụ tiếp theo là xác định lớp phân loại. Bộ dữ liệu ChestXray14 có 14 bệnh lý được gắn nhãn, vì vậy chúng tôi có một nơ-ron cho mỗi nhãn. Chúng tôi cũng kích hoạt từng nơ-ron bằng chức năng kích hoạt sigmoid và sử dụng đầu ra của phần bộ lọc tính năng trong mạng của chúng tôi làm đầu vào cho các bộ phân loại.
từ keras.layers nhập dày đặc bộ phân loại = Dense(14, activate='sigmoid',bias_initializer='ones')(filters)
Việc lựa chọn sigmoid làm hàm kích hoạt là do tính chất đa nhãn của tập dữ liệu. Đối với các vấn đề trong đó chỉ có một nhãn áp dụng cho một hình ảnh nhất định (ví dụ: chó, mèo, bánh sandwich), kích hoạt softmax sẽ thích hợp hơn. Trong trường hợp của ChestXray14, hình ảnh có thể hiển thị dấu hiệu của nhiều bệnh lý và mô hình phải xác định chính xác xác suất cao cho nhiều phân loại khi thích hợp.
Cuối cùng, chúng ta có thể kết hợp các bộ lọc đặc trưng và bộ phân loại để tạo ra một mô hình duy nhất có thể huấn luyện được.
từ mô hình nhập keras.models chexnet = Model(inputs=orig_net.inputs, results=classifiers)
Với cấu hình mô hình cuối cùng đã có, mô hình sau đó có thể được biên dịch và huấn luyện.
Tăng tốc chu trình đào tạo/kiểm tra/điều chỉnh bằng phương pháp học sâu phân tán
Để sớm tạo ra các mô hình tốt hơn, chúng ta cần đẩy nhanh chu trình Đào tạo/Thử nghiệm/Điều chỉnh. Bởi vì việc kiểm tra và điều chỉnh chủ yếu diễn ra tuần tự nên đào tạo là nơi tốt nhất để tìm kiếm khả năng tối ưu hóa tiềm năng.
Chính xác thì làm thế nào để chúng ta tăng tốc quá trình đào tạo? Trong Tăng tốc hiểu biết sâu sắc với Học sâu phân tán , Michael Bennett và tôi thảo luận về ba cách mà học sâu có thể được tăng tốc bằng cách phân phối công việc và song song hóa quy trình:
- Các mô hình máy chủ tham số như trong Caffe hay TensorFlow phân tán,
- Các phương pháp tiếp cận Ring-AllReduce như Horovod của Uber và
- Các phương pháp kết hợp cho môi trường Hadoop/Spark như Intel BigDL.
Cách tiếp cận bạn chọn tùy thuộc vào khung học tập sâu mà bạn lựa chọn và môi trường điện toán mà bạn sẽ sử dụng. Đối với các thử nghiệm được mô tả ở đây, chúng tôi đã thực hiện chương trình đào tạo nội bộ trên siêu máy tính Zenith trong Phòng thí nghiệm Đổi mới AI & HPC của Dell EMC . Cách tiếp cận giảm toàn bộ vòng được kích hoạt bởi khung Horovod của Uber có ý nghĩa nhất khi tận dụng hệ thống được điều chỉnh cho khối lượng công việc HPC và tận dụng mạng Intel Omni-Path (OPA) để liên lạc nhanh giữa các nút. Cách tiếp cận giảm toàn bộ vòng cũng sẽ phù hợp với các giải pháp như Giải pháp sẵn sàng của Dell EMC cho AI, Học sâu với NVIDIA .
 Cách tiếp cận MPI-RingAllreduce để học sâu phân tán
Cách tiếp cận MPI-RingAllreduce để học sâu phân tán
Horovod là một khung dựa trên MPI để thực hiện các hoạt động rút gọn giữa các bản sao giống hệt nhau của tập lệnh huấn luyện tuần tự. Vì nó dựa trên MPI nên bạn cần chắc chắn rằng trình biên dịch MPI (mpicc) có sẵn trong môi trường làm việc trước khi cài đặt horovod.
Thêm Horovod vào Mô hình do Keras xác định
Việc thêm Horovod vào bất kỳ mô hình mạng thần kinh nào do Keras xác định chỉ yêu cầu một số sửa đổi mã:
- Đang khởi tạo môi trường MPI,
- Truyền phát trọng lượng ngẫu nhiên ban đầu hoặc trọng lượng điểm kiểm tra cho tất cả công nhân,
- Bao bọc chức năng tối ưu hóa để kích hoạt tính tổng gradient nhiều nút,
- Số liệu trung bình giữa các công nhân, và
- Giới hạn việc ghi điểm kiểm tra cho một nhân viên.
Horovod cũng cung cấp các chức năng trợ giúp và lệnh gọi lại cho các khả năng tùy chọn hữu ích khi thực hiện học sâu phân tán, chẳng hạn như khởi động/phân rã tốc độ học tập và tính trung bình số liệu.
Khởi tạo môi trường MPI
Khởi tạo môi trường MPI trong Horovod chỉ yêu cầu gọi phương thức init:
nhập horovod.keras dưới dạng hvd hvd.init()
Điều này sẽ đảm bảo rằng hàm MPI_Init được gọi, thiết lập cấu trúc liên lạc và phân cấp cấp bậc cho tất cả công nhân.
Trọng lượng phát sóng
Việc phát các trọng số nơ-ron được thực hiện bằng cách sử dụng lệnh gọi lại phương thức Model.fit Keras. Trên thực tế, nhiều tính năng của Horovod được triển khai dưới dạng lệnh gọi lại cho Model.fit, do đó, bạn nên xác định một đối tượng danh sách gọi lại để lưu giữ tất cả các lệnh gọi lại.
cuộc gọi lại = [ hvd.callbacks.BroadcastGlobalVariablesCallback(0) ]
Bạn sẽ nhận thấy rằng BroadcastGlobalVariablesCallback nhận một đối số duy nhất được đặt thành 0. Đây là nhân viên gốc, sẽ chịu trách nhiệm đọc các tệp điểm kiểm tra hoặc tạo các trọng số ban đầu mới, phát các trọng số khi bắt đầu quá trình đào tạo và viết điểm kiểm tra tập tin định kỳ để công việc không bị mất nếu công việc đào tạo không thành công hoặc chấm dứt.
Gói chức năng tối ưu hóa
Hàm tối ưu hóa phải được gói để có thể tổng hợp thông tin lỗi từ tất cả các trình chạy trước khi thực thi. Chức năng DistributedOptimizer của Horovod có thể bao bọc bất kỳ trình tối ưu hóa nào kế thừa lớp Trình tối ưu hóa cơ sở của Keras, bao gồm SGD, Adam, Adadelta, Adagrad và các trình tối ưu hóa khác.
nhập keras.optimizers opt = hvd.DistributedOptimizer(keras.optimizers.Adadelta(lr=1.0))
Trình tối ưu hóa phân tán hiện sẽ sử dụng tập hợp MPI_Allgather để tổng hợp thông tin lỗi từ các đợt đào tạo cho tất cả các trình chạy, thay vì chỉ thu thập chúng cho trình chạy gốc. Điều này cho phép các công nhân cập nhật mô hình của họ một cách độc lập thay vì chờ gốc phát lại các trọng số đã cập nhật trước khi bắt đầu đợt đào tạo tiếp theo.
Số liệu trung bình
Số liệu lỗi giữa các bước cần được tính trung bình để tính toán tổn thất tổng thể. Horovod cung cấp một chức năng gọi lại khác để thực hiện việc này được gọi là MetricAverageCallback.
cuộc gọi lại = [ hvd.callbacks.BroadcastGlobalVariablesCallback(0), hvd.callbacks.MetricAverageCallback() ]
Điều này sẽ đảm bảo rằng việc tối ưu hóa được thực hiện trên các số liệu chung chứ không phải các số liệu cục bộ cho từng nhân viên.
Viết điểm kiểm tra từ một công nhân
Khi sử dụng deep learning phân tán, điều quan trọng là chỉ một nhân viên ghi các tệp điểm kiểm tra để đảm bảo rằng nhiều nhân viên ghi vào cùng một tệp không tạo ra tình trạng chạy đua, điều này có thể dẫn đến lỗi điểm kiểm tra.
Việc ghi điểm kiểm tra trong Keras được kích hoạt bằng một lệnh gọi lại khác tới Model.fit. Tuy nhiên, chúng tôi chỉ muốn gọi lại cuộc gọi này từ một công nhân thay vì tất cả công nhân. Theo quy ước, chúng tôi sử dụng nhân viên 0 cho nhiệm vụ này, nhưng về mặt kỹ thuật, chúng tôi có thể sử dụng bất kỳ nhân viên nào cho nhiệm vụ này. Một điều tốt về công nhân 0 là ngay cả khi bạn quyết định thực hiện công việc học sâu phân tán của mình chỉ với 1 công nhân thì công nhân đó sẽ là công nhân 0.
cuộc gọi lại = [ ... ] nếu hvd.rank() == 0: callbacks.append(keras.callbacks.ModelCheckpoint('./checkpoint-{epoch].h5'))
Kết quả: Một mô hình thông minh hơn, nhanh hơn!
Khi mạng lưới thần kinh có thể được đào tạo theo kiểu phân tán trên nhiều công nhân, chu trình Đào tạo/Kiểm tra/Điều chỉnh có thể được tăng tốc đáng kể.
Hình dưới đây cho thấy chính xác đáng kể như thế nào. Ba bài kiểm tra được hiển thị là tốc độ đào tạo của mô hình Keras DenseNet trên một nút Zenith duy nhất không có deep learning phân tán (ngoài cùng bên trái), mô hình Keras DenseNet với deep learning phân tán trên 32 nút Zenith (64 quy trình MPI, 2 quy trình MPI trên mỗi nút, trung tâm) và phiên bản Keras VGG16 sử dụng học sâu phân tán trên 64 nút Zenith (128 quy trình MPI, 2 quy trình MPI trên mỗi nút, ngoài cùng bên phải). Bằng cách sử dụng 32 nút thay vì một nút duy nhất, học sâu phân tán có thể cải thiện tốc độ đào tạo gấp 47 lần , rút thời gian đào tạo trong 10 kỷ nguyên trên bộ dữ liệu ChestXray14 từ 2 ngày (50 giờ) xuống dưới 2 giờ!
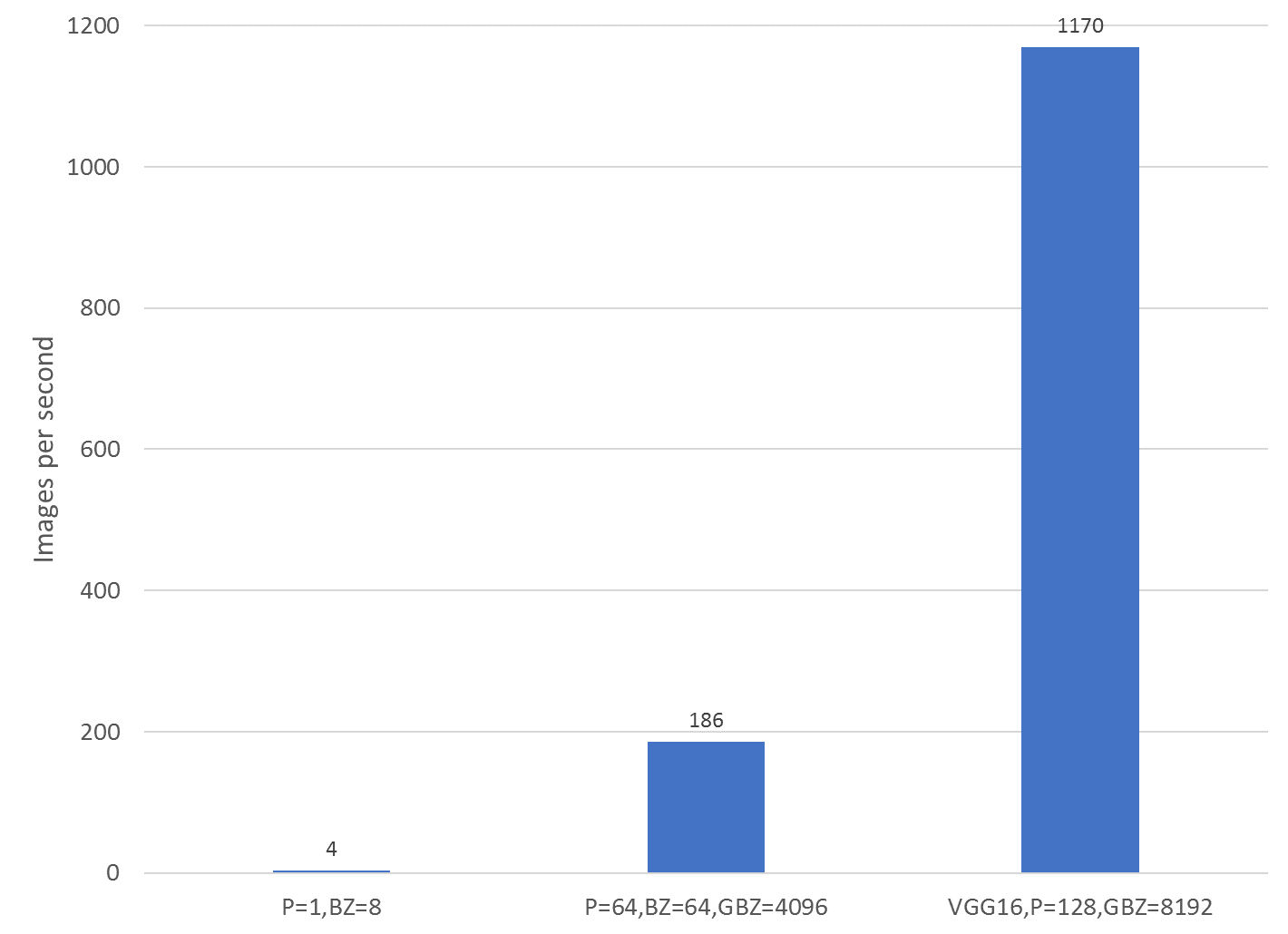 So sánh hiệu suất của các mô hình Keras với deep learning phân tán bằng Horovod
So sánh hiệu suất của các mô hình Keras với deep learning phân tán bằng Horovod
Biến thể VGG, được huấn luyện trên 128 nút Zenith, có thể hoàn thành cùng số lượng kỷ nguyên được yêu cầu để phiên bản DenseNet một nút huấn luyện trong vòng chưa đầy một giờ, mặc dù cần nhiều kỷ nguyên hơn để huấn luyện. Tuy nhiên, nó cũng có thể hội tụ đến một giải pháp chất lượng cao hơn. Mô hình dựa trên VGG này hoạt động tốt hơn mô hình cơ sở, một nút ở 4 trong số 14 điều kiện và có thể đạt được độ chính xác gần 90% trong việc phân loại bệnh khí thũng.
 So sánh độ chính xác của mô hình DenseNet nút đơn cơ bản với biến thể VGG với Horovod
So sánh độ chính xác của mô hình DenseNet nút đơn cơ bản với biến thể VGG với Horovod
Phần kết luận
Trong bài đăng này, chúng tôi đã chỉ cho bạn cách tăng tốc chu trình Đào tạo/Kiểm tra/Điều chỉnh khi phát triển các mô hình dựa trên mạng thần kinh bằng cách tăng tốc giai đoạn đào tạo với học sâu phân tán. Chúng tôi đã hướng dẫn quy trình chuyển đổi mô hình dựa trên Keras để tận dụng nhiều nút bằng khung Horovod và cách thay đổi một số mã đơn giản này, cùng với một số cơ sở hạ tầng điện toán bổ sung, có thể giảm thời gian cần thiết để đào tạo mô hình từ vài ngày xuống còn phút , cho phép có nhiều thời gian hơn cho việc kiểm tra và điều chỉnh các phần của chu trình. Nhiều thời gian hơn để điều chỉnh có nghĩa là các mô hình có chất lượng cao hơn, nghĩa là mang lại kết quả tốt hơn cho bệnh nhân, khách hàng hoặc bất kỳ ai sẽ được hưởng lợi từ việc triển khai mô hình của bạn.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...