
Tin tức
Dịch thuật máy thần kinh có thể mở rộng bằng bộ xử lý có khả năng mở rộng Intel Xeon
Lĩnh vực dịch ngôn ngữ máy đang chuyển đổi nhanh chóng từ các mô hình học máy thống kê sang các thiết kế kiến trúc mạng thần kinh hiệu quả có thể cải thiện đáng kể chất lượng dịch thuật. Tuy nhiên, việc đào tạo một mô hình Dịch máy thần kinh (NMT) hoạt động tốt hơn vẫn mất vài ngày đến vài tuần tùy thuộc vào phần cứng, kích thước của kho dữ liệu đào tạo và kiến trúc mô hình. Việc cải thiện thời gian thực hiện giải pháp cho đào tạo NMT sẽ rất quan trọng nếu những phương pháp này muốn được áp dụng rộng rãi.
Bộ xử lý có khả năng mở rộng Intel® Xeon® là đặc trưng của trung tâm dữ liệu hiện đại và hơn 90% siêu máy tính Top500 chạy trên Intel . Chúng tôi có thể áp dụng phương pháp siêu máy tính để mở rộng quy mô ra nhiều máy chủ để đào tạo các mô hình NMT ở bất kỳ trung tâm dữ liệu nào. Trong bài viết này, chúng tôi trình bày một số tính hiệu quả và nêu bật những cân nhắc quan trọng khi mở rộng mô hình NMT bằng bộ xử lý có khả năng mở rộng Intel® Xeon®.
Kiến trúc bộ mã hóa – giải mã
Mô hình NMT đọc một câu bằng ngôn ngữ nguồn và chuyển nó tới bộ mã hóa để xây dựng biểu diễn trung gian. Sau đó, bộ giải mã xử lý biểu diễn trung gian để tạo ra câu được dịch sang ngôn ngữ đích.
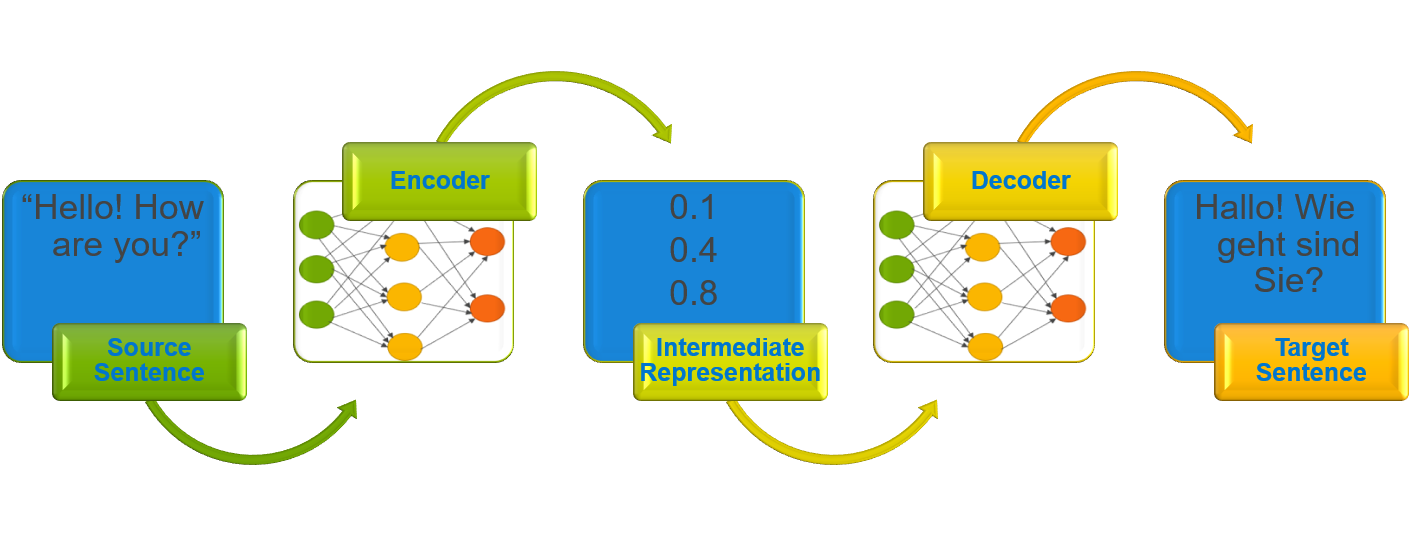
Hình 1: Kiến trúc bộ mã hóa-giải mã
Hình trên minh họa kiến trúc bộ mã hóa-giải mã. Câu nguồn tiếng Anh, “Xin chào! Bạn có khỏe không?” được kiến trúc đọc và xử lý để tạo ra câu tiếng Đức được dịch “Xin chào! Bạn có thích Sie không?”. Theo truyền thống, Mạng thần kinh tái phát (RNN) được sử dụng trong bộ mã hóa và bộ giải mã, nhưng các kiến trúc mạng thần kinh khác như Mạng thần kinh chuyển đổi (CNN) và kiến trúc dựa trên cơ chế chú ý cũng được sử dụng.
Kiến trúc và môi trường
Mô hình Transformer là một trong những kiến trúc hiện đang được quan tâm trong lĩnh vực NMT và được xây dựng với các biến thể của cơ chế chú ý thay thế các thành phần RNN truyền thống trong kiến trúc. Kiến trúc này có thể tạo ra một mô hình đạt được kết quả hiện đại trong các nhiệm vụ dịch thuật Anh-Đức và Anh-Pháp .
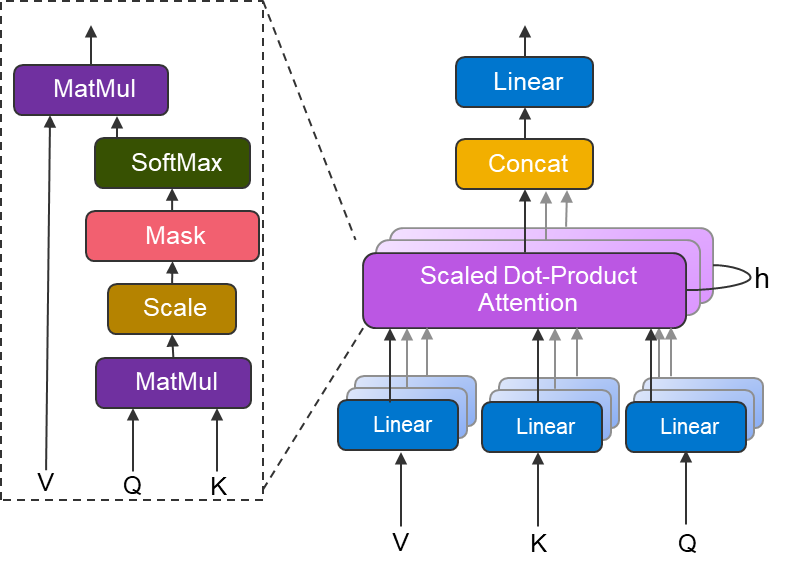
Hình 2: Khối chú ý nhiều đầu
Hình trên cho thấy khối chú ý nhiều đầu được sử dụng trong kiến trúc máy biến áp. Ở cấp độ cao, sự chú ý của sản phẩm chấm được chia tỷ lệ có thể được coi là tìm kiếm thông tin liên quan, dưới dạng giá trị (V) dựa trên Truy vấn (Q) và Khóa (K). Sự chú ý của nhiều đầu có thể được coi là một số lớp chú ý song song, cùng nhau có thể xác định các khía cạnh riêng biệt của đầu vào.
Chúng tôi sử dụng triển khai mô hình chính thức của Tensorflow cho kiến trúc máy biến áp, đã được tăng cường bằng khung đào tạo phân tán Horovod của Uber. Tập dữ liệu huấn luyện được sử dụng là kho ngữ liệu song song Anh-Đức WMT , chứa 4,5 triệu cặp câu Anh-Đức.
Các thử nghiệm của chúng tôi đã được thực hiện ngay trên siêu máy tính Zenith trong phòng thí nghiệm Dell EMC HPC và AI Innovation . Zenith là cụm dựa trên Dell EMC PowerEdge C6420 , bao gồm 388 nút ổ cắm kép được hỗ trợ bởi bộ xử lý Intel® Xeon® Scalable Gold 6148 và được kết nối với nhau bằng cấu trúc Intel® Omni-path.
Thông tin hệ thống
| Mẫu CPU | CPU Intel(R) Xeon(R) Gold 6148 @ 2.40GHz |
| Hệ điều hành | Red Hat Enterprise Linux Server phát hành 7.4 (Maipo) |
| Phiên bản Tensorflow | 1.10.1 với Intel® MKL |
| Phiên bản Horovod | 0,15,0 |
| MPI | Mở MPI 3.1.2 |
Lưu ý: Chúng tôi đã sử dụng một nhánh Horovod cụ thể để xử lý độ dốc thưa thớt. Hiện là một phần của nhánh chính trong kho GitHub của họ.
Tỷ lệ yếu, biến môi trường và cấu hình TF
Khi đào tạo bằng CPU, cài đặt biến môi trường và giá trị cấu hình thời gian chạy TensorFlow đóng vai trò quan trọng trong việc cải thiện thông lượng và giảm thời gian giải quyết.
Dưới đây là các cài đặt được đề xuất dựa trên các thử nghiệm thực nghiệm của chúng tôi khi chạy 4 quy trình trên mỗi nút cho mô hình máy biến áp (lớn) trên 50 nút thiên đỉnh.
Biến môi trường
| xuất OMP_NUM_THREADS=10
xuất KMP_BLOCKTIME=0 xuất KMP_AFFINITY=độ chi tiết=tốt,dài dòng,nhỏ gọn,1,0 |
Cấu hình TF:
| nội_op_parallelism_threads=$OMP_NUM_THREADS
inter_op_parallelism_threads=1 |
Thử nghiệm với các tùy chọn chia tỷ lệ yếu cho phép tìm ra số lượng quy trình tối ưu chạy trên mỗi nút sao cho mô hình phù hợp với bộ nhớ và hiệu suất không bị suy giảm. Vì lý do nào đó, TensorFlow tạo thêm một luồng. Do đó, để tránh đăng ký quá mức, tốt hơn hết bạn nên đặt OMP_NUM_THREADS thành 9, 19 hoặc 39 khi đào tạo với quy trình 4,2,1 trên mỗi nút tương ứng. Mặc dù chúng tôi không thấy nó ảnh hưởng đến hiệu suất thông lượng trong các thử nghiệm của chúng tôi nhưng có thể ảnh hưởng đến hiệu suất trong thiết lập quy mô rất lớn.
Tận dụng đa luồng có thể cải thiện đáng kể hiệu suất. Điều này có thể được thực hiện bằng cách đặt OMP_NUM_THREADS sao cho tích của giá trị của nó và số thứ hạng MPI trên mỗi nút bằng với số lõi CPU có sẵn trên mỗi nút. Trong trường hợp của Zenith, đây là 40 lõi, vì mỗi nút PowerEdge C6420 chứa 2 bộ xử lý Intel® Xeon® Gold 6148 20 lõi.
Biến môi trường KMP_AFFINITY cung cấp cách điều khiển giao diện liên kết các luồng OpenMP với các đơn vị xử lý vật lý, trong khi KMP_BLOCKTIME, đặt thời gian tính bằng mili giây mà một luồng sẽ đợi sau khi hoàn thành thực thi song song trước khi ngủ. Cài đặt cấu hình TF, inter_op_parallelism_threads và inter_op_parallelism_threads được sử dụng để điều chỉnh nhóm luồng từ đó tối ưu hóa hiệu suất CPU.
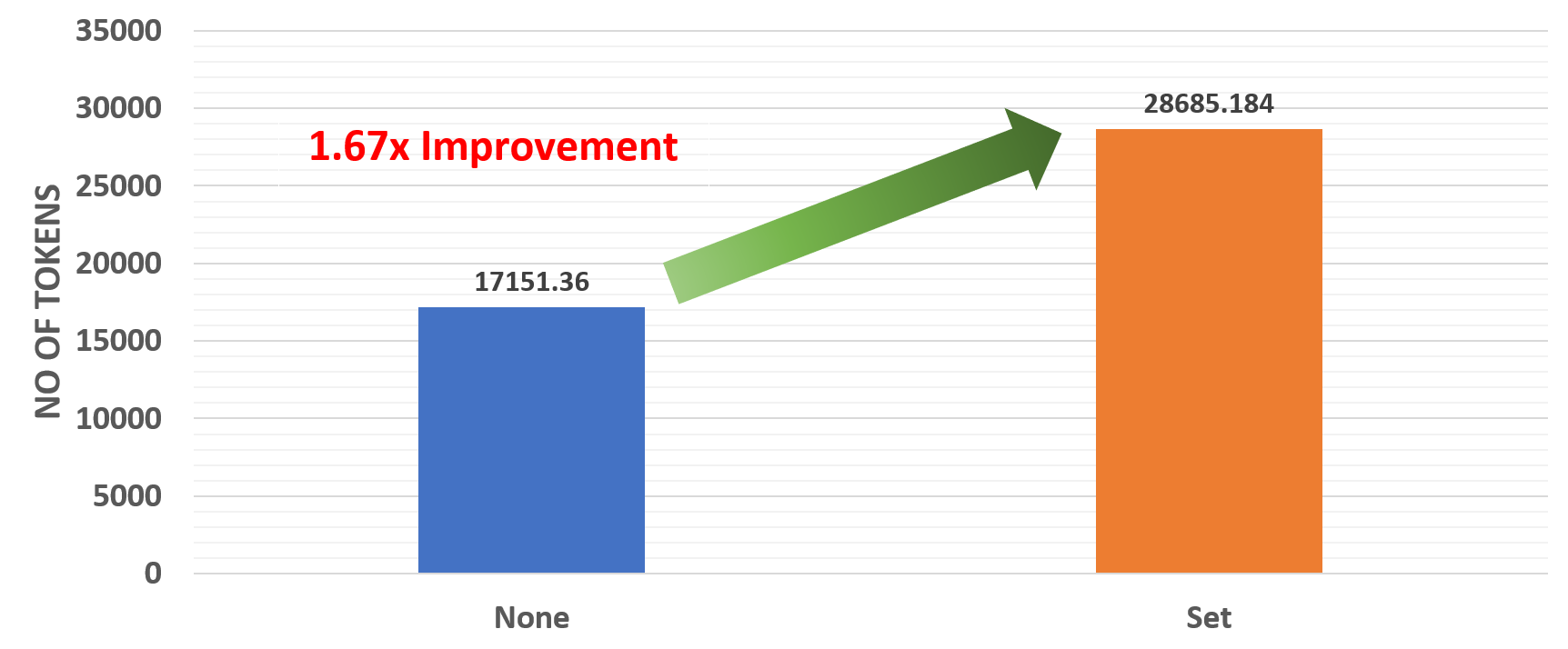
Hình 3: Ảnh hưởng của các biến môi trường
Các kết quả trên cho thấy có sự cải thiện gấp 1,67 lần khi các biến môi trường được đặt chính xác.
Đào tạo phân tán nhanh hơn
Việc đào tạo một kiến trúc mạng lưới thần kinh lớn có thể tốn thời gian, gây khó khăn cho việc thực hiện tạo nguyên mẫu nhanh hoặc điều chỉnh siêu tham số. Nhờ các khung đào tạo phân tán và nguồn mở như Horovod , cho phép đào tạo một mô hình sử dụng nhiều nhân viên, thời gian đào tạo có thể giảm đáng kể. Trong blog trước đây, chúng tôi đã cho thấy tính hiệu quả của việc đào tạo bác sĩ X quang AI bằng phương pháp học sâu phân tán và sử dụng bộ xử lý Intel® Xeon® có thể mở rộng. Ở đây, chúng tôi chỉ ra cách học sâu phân tán cải thiện thời gian đào tạo cho các mô hình dịch máy.
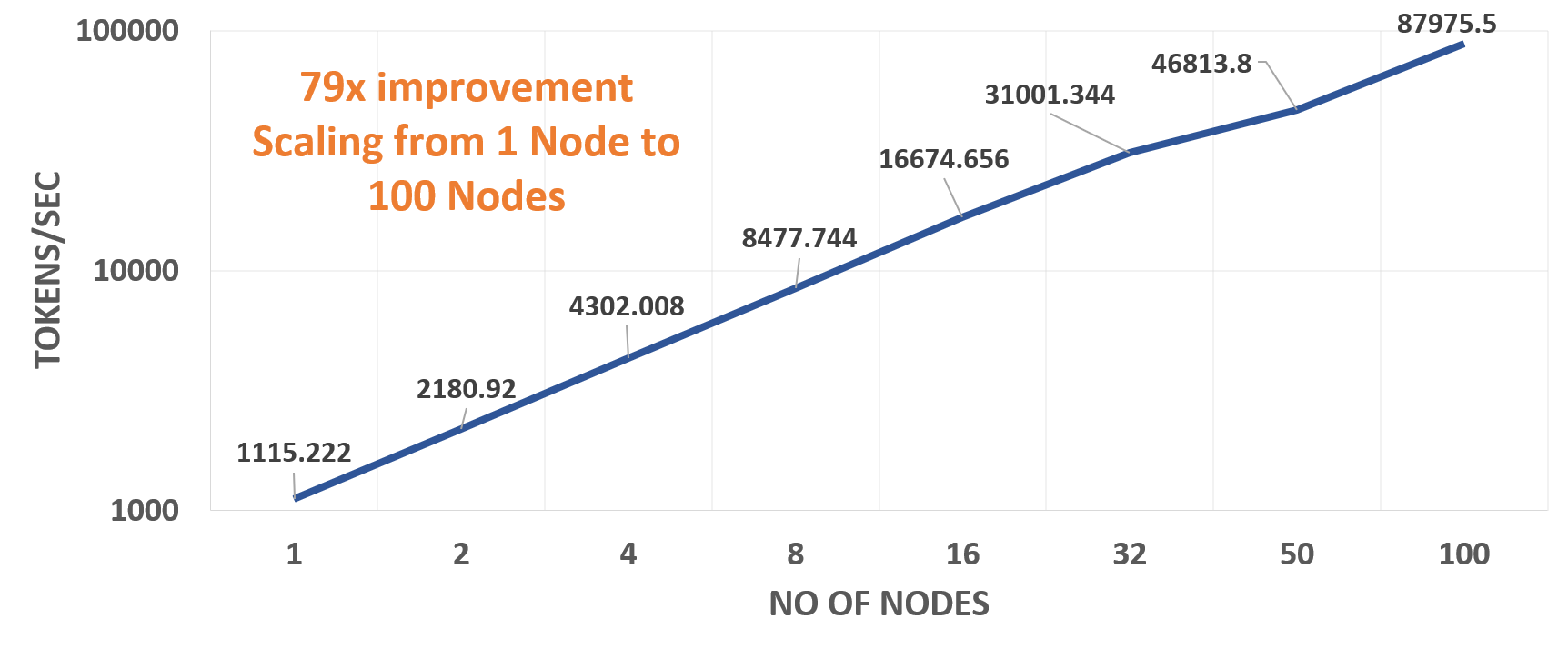
Hình 4: Hiệu suất mở rộng quy mô
Biểu đồ trên cho thấy thông lượng của mô hình máy biến áp (lớn) khi được đào tạo bằng cách sử dụng tối đa 100 nút Zenith. Thử nghiệm của chúng tôi cho thấy hiệu suất tuyến tính khi tăng số lượng nút. Dựa trên các thử nghiệm của chúng tôi, bao gồm việc đặt các biến môi trường chính xác và số lượng quy trình MPI tối ưu trên mỗi nút, chúng tôi nhận thấy sự cải thiện gấp 79 lần trên 100 nút Zenith với 2 quy trình trên mỗi nút so với thông lượng trên một nút duy nhất có 4 quy trình.
Chất lượng dịch thuật
Chất lượng dịch thuật của mô hình NMT được đo bằng điểm BLEU (Nghiên cứu đánh giá song ngữ). Đó là thước đo để tính toán sự khác biệt giữa kết quả do con người dịch và kết quả do máy dịch.
Trong một bài đăng trên blog trước đây , chúng tôi đã giải thích một số thách thức trong việc đào tạo hàng loạt mô hình học sâu. Tại đây, chúng tôi đã thử nghiệm sử dụng quy mô lô toàn cầu lớn gồm 402 nghìn mã thông báo để xác định độ chính xác của mô hình đối với tác vụ dịch từ tiếng Anh sang tiếng Đức. Các siêu tham số được đặt để khớp với các siêu tham số được sử dụng cho mô hình máy biến áp (lớn) và mô hình được đào tạo bằng cách sử dụng 50 nút Zenith với 4 quy trình trên mỗi nút. Tốc độ học tăng tuyến tính trong 4000 bước đến 0,001 và sau đó tuân theo phân rã căn bậc hai nghịch đảo.
| BLEU không phân biệt chữ hoa chữ thường | BLEU phân biệt chữ hoa chữ thường | |
| Kết quả điểm chuẩn chính thức của TensorFlow | 28,9 | – |
| Ket qua cua chung toi | 29,15 | 28,56 |
Lưu ý: Điểm phân biệt chữ hoa chữ thường không được báo cáo trong Điểm chuẩn chính thức của Tensorflow.
Bảng trên cho thấy kết quả của chúng tôi trên bộ thử nghiệm (newstest2014) sau khi đào tạo mô hình trong khoảng 2,7 ngày (26000 bước). Chúng ta có thể thấy sự cải thiện rõ rệt về chất lượng dịch thuật so với kết quả được đăng trên trang Tensorflow Official Benchmarks. Điều này cho thấy rằng việc đào tạo với các lô lớn không ảnh hưởng xấu đến chất lượng của các mô hình dịch thu được, đây là một kết quả đáng khích lệ cho các nghiên cứu trong tương lai với quy mô lô lớn hơn nữa.
Phần kết luận
Trong bài đăng này, chúng tôi đã trình bày cách đào tạo hiệu quả hệ thống Dịch máy thần kinh (NMT) bằng cách sử dụng bộ xử lý Intel® Xeon® có thể mở rộng bằng cách sử dụng phương pháp học sâu phân tán. Chúng tôi đã nêu bật một số phương pháp hay nhất để đặt biến môi trường và hiệu suất mở rộng quy mô tương ứng. Dựa trên các thử nghiệm của chúng tôi và theo dõi công việc nghiên cứu khác về NMT để hiểu một số khía cạnh quan trọng của việc mở rộng hệ thống NMT, chúng tôi đã có thể chứng minh chất lượng dịch tốt hơn và đẩy nhanh quá trình đào tạo. Với mối quan tâm nghiên cứu trong lĩnh vực dịch máy thần kinh tiếp tục phát triển, chúng tôi hy vọng sẽ thấy nhiều kiến trúc NMT thú vị và sáng tạo hơn trong tương lai.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...