
Giới thiệu
Đúng như truyền thống bắt kịp xu hướng công nghệ, Giải pháp sẵn sàng của Dell EMC dành cho bộ lưu trữ hiệu suất cao BeeGFS , được ra mắt lần đầu vào tháng 11 năm 2019, hiện đã được làm mới với phần mềm và phần cứng mới nhất. Kiến trúc cơ bản của giải pháp vẫn giữ nguyên. Bảng sau liệt kê những điểm khác biệt giữa giải pháp dựa trên InfiniBand EDR được phát hành ban đầu và giải pháp dựa trên InfiniBand HDR100 hiện tại về mặt phần mềm và phần cứng được sử dụng.
Bảng 1. So sánh phần cứng và phần mềm của Giải pháp hiệu suất cao BeeGFS dựa trên EDR và HDR
| Phần mềm | Bản phát hành lần đầu (Tháng 11 năm 2019) | Làm mới hiện tại (tháng 11 năm 2020) |
| Hệ điều hành | CentOS 7.6 | CentOS 8.2. |
| Phiên bản hạt nhân | 3.10.0-957.27.2.el7.x86_64 | 4.18.0-193.14.2.el8_2.x86_64 |
| Phiên bản hệ thống tệp BeeGFS | 7.1.3 | 7.2 |
| Phiên bản Mellanox OFED | 4.5-1.0.1.0 | 5.0-2.1.8.0 |
| Phần cứng | Phát hành lần đầu | Làm mới hiện tại |
| Ổ đĩa NVMe | Intel P4600 1.6 TB Sử dụng hỗn hợp | Intel P4610 3,2 TB Sử dụng hỗn hợp |
| Bộ điều hợp InfiniBand | ConnectX-5 cổng đơn EDR | ConnectX-6 Cổng đơn HDR100 |
| Công tắc InfiniBand | SB7890 InfiniBand EDR 100 Gb/s Switch -1U (36x cổng EDR 100 Gb/s) | QM8790 Quantum HDR Edge Switch – 1U (80x cổng HDR100 100 Gb/s sử dụng cáp chia) |
Blog này trình bày kiến trúc, thông số kỹ thuật cập nhật và đặc tính hiệu suất của giải pháp hiệu suất cao được nâng cấp. Nó cũng bao gồm việc so sánh hiệu suất với giải pháp dựa trên EDR trước đó .
Kiến trúc tham khảo giải pháp
Kiến trúc cấp cao của giải pháp vẫn giữ nguyên như bản phát hành ban đầu. Các thành phần phần cứng của giải pháp bao gồm 1x PowerEdge R640 làm máy chủ quản lý và 6x máy chủ PowerEdge R740xd làm máy chủ lưu trữ/siêu dữ liệu để lưu trữ các mục tiêu lưu trữ và siêu dữ liệu. Mỗi máy chủ PowerEdge R740xd được trang bị 24 ổ đĩa Express Flash Intel P4610 3,2 TB sử dụng hỗn hợp và 2 bộ điều hợp Mellanox ConnectX-6 HDR100. Hình 1 cho thấy kiến trúc tham chiếu của giải pháp.
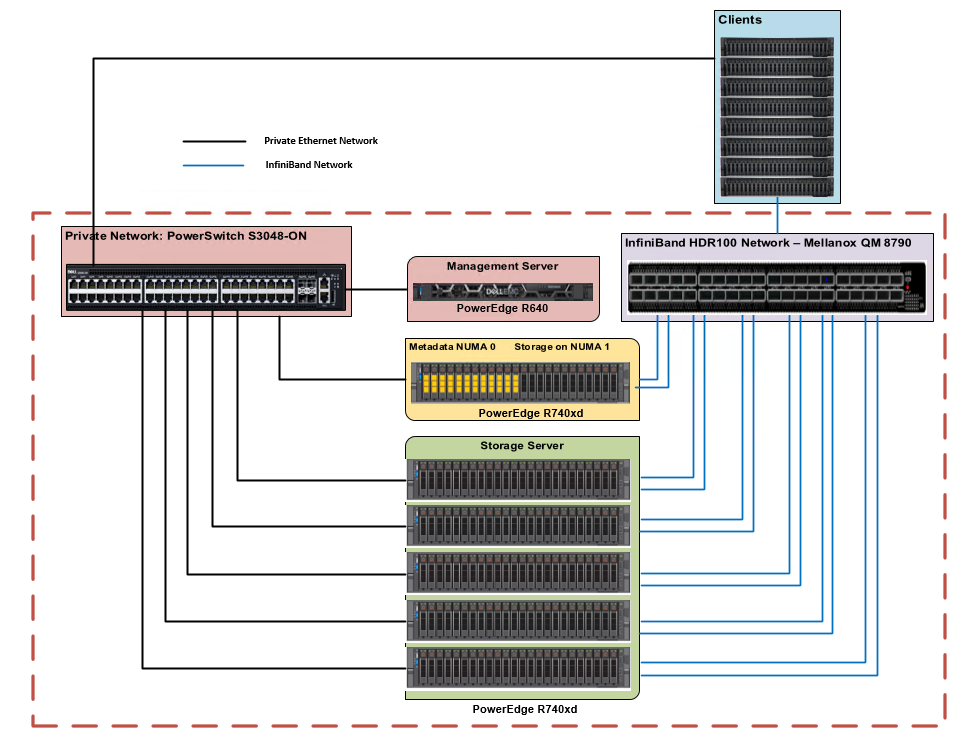
Hình 1. Giải pháp sẵn sàng của Dell EMC cho bộ lưu trữ HPC BeeGFS – Kiến trúc tham khảo
Có hai mạng – mạng InfiniBand và mạng Ethernet riêng. Máy chủ quản lý chỉ được kết nối qua Ethernet với máy chủ lưu trữ và siêu dữ liệu. Mỗi máy chủ lưu trữ và siêu dữ liệu có 2x liên kết đến mạng InfiniBand và được kết nối với mạng riêng qua Ethernet. Các máy khách có một liên kết InfiniBand và cũng được kết nối với mạng Ethernet riêng. Để biết thêm chi tiết về cấu hình giải pháp, vui lòng tham khảo blog và báo cáo nghiên cứu chuyên sâu về Giải pháp hiệu suất cao BeeGFS được xuất bản tại hpcatdell.com .
Cấu hình phần cứng và phần mềm
Bảng 2 và 3 lần lượt mô tả thông số phần cứng của máy chủ quản lý và máy chủ siêu dữ liệu/lưu trữ. Bảng 4 mô tả các phiên bản phần mềm được sử dụng cho giải pháp.
Bảng 2. Cấu hình PowerEdge R640 (Máy chủ quản lý)
| Thành phần | Sự miêu tả |
| Bộ xử lý | 2 x Intel Xeon Gold 5218 2.3GHz, 16 lõi |
| Ký ức | DIMM 12 x 8GB DDR4 2666MT/s – 96GB |
| Đĩa cục bộ | 6 ổ cứng 300GB 15K RPM SAS 2,5 inch |
| Bộ điều khiển RAID | Bộ điều khiển RAID tích hợp PERC H740P |
| Quản lý ngoài ban nhạc | iDRAC9 Enterprise với Bộ điều khiển vòng đời |
Bảng 3. Cấu hình PowerEdge R740xd (Máy chủ siêu dữ liệu và lưu trữ)
| Thành phần | Sự miêu tả |
| Bộ xử lý | 2x CPU Intel Xeon Platinum 8268 @ 2.90GHz, 24 lõi |
| Ký ức | 12 x 32GB DDR4 2933MT/s DIMM – 384GB |
| Thẻ BOSS | 2x SSD M.2 240GB trong RAID 1 cho hệ điều hành |
| Ổ đĩa cục bộ | 24x Dell Express Flash NVMe P4610 3.2 TB 2.5” U.2 |
| Bộ chuyển đổi InfiniBand | 2x Bộ chuyển đổi HDR100 cổng đơn Mellanox ConnectX-6 |
| Phần mềm điều khiển bộ điều hợp InfiniBand | 20.26.4300 |
| Quản lý ngoài ban nhạc | iDRAC9 Enterprise với Bộ điều khiển vòng đời |
Bảng 4. Cấu hình phần mềm (Máy chủ siêu dữ liệu và lưu trữ)
| Thành phần | Sự miêu tả |
| Hệ điều hành | CentOS Linux phát hành 8.2.2004 (Lõi) |
| Phiên bản hạt nhân | 4 4.18.0-193.14.2.el8_2. |
| Mellanox OFED | 5.0-2.1.8.0 |
| SSD NVMe | VDV1DP23 |
| OpenMPI | 4.0.3rc4 |
| Công cụ trung tâm dữ liệu Intel | v 3.0.26 |
| BeeGFS | 7.2 |
| Grafana | 7.1.5-1 |
| FluxDB | 1.8.2-1 |
| IOzone | 3.490 |
| kiểm tra MD | 3.3.0+nhà phát triển |
Đánh giá hiệu suất
Hiệu suất hệ thống được đánh giá bằng cách sử dụng các điểm chuẩn sau:
Các thử nghiệm hiệu năng đã được chạy trên một khung thử nghiệm với các máy khách như được mô tả trong Bảng 5. Đối với các trường hợp thử nghiệm trong đó số lượng luồng IO lớn hơn số lượng máy khách IO vật lý, các luồng được phân bổ đều trên các máy khách (tức là 32 luồng = 2 luồng trên mỗi máy khách). client…,1024 luồng = 64 luồng trên mỗi nút).
Bảng 5. Cấu hình máy khách
| Thành phần | Sự miêu tả |
| Mô hình máy chủ | 8x PowerEdge R840
8x PowerEdge C6420 |
| Bộ xử lý | 4x CPU Intel(R) Xeon(R) Platinum 8260 @ 2.40GHz, 24 lõi (R840)
2x CPU Intel(R) Xeon(R) Gold 6248 @ 2.50GHz, 20 lõi (C6420) |
| Ký ức | DIMM 24 x 16GB DDR4 2933MT/s – 384GB (R840)
DIMM 12 x 16GB DDR4 2933MT/s – 192 GB (C6420) |
| Hệ điều hành | 4.18.0-193.el8.x86_64 |
| Phiên bản hạt nhân | Red Hat Enterprise Linux phát hành 8.2 (Ootpa) |
| Bộ chuyển đổi InfiniBand | 1x Bộ chuyển đổi HDR100 cổng đơn ConnectX-6 |
| Phiên bản OFED | 5.0-2.1.8.0 |
Đọc và ghi tuần tự NN
Điểm chuẩn IOzone được sử dụng ở chế độ đọc và ghi tuần tự để đánh giá việc đọc và ghi tuần tự. Các thử nghiệm này được tiến hành bằng cách sử dụng số lượng luồng bắt đầu từ 1 luồng và lên tới 1024 luồng. Ở mỗi lần đếm luồng, một số lượng tệp bằng nhau đã được tạo do thử nghiệm này hoạt động trên một tệp trên mỗi luồng hoặc trường hợp NN. Thuật toán quay vòng được sử dụng để chọn mục tiêu tạo tệp theo kiểu xác định.
Đối với tất cả các thử nghiệm, kích thước tệp tổng hợp là 8 TB và được chia đều cho số lượng luồng cho bất kỳ thử nghiệm nhất định nào. Kích thước tệp tổng hợp được chọn đủ lớn để giảm thiểu tác động của bộ nhớ đệm từ máy chủ cũng như từ máy khách BeeGFS.
IOzone được chạy ở chế độ kết hợp ghi rồi đọc (-i 0, -i 1) để cho phép nó phối hợp ranh giới giữa các hoạt động. Đối với thử nghiệm này, chúng tôi đã sử dụng kích thước bản ghi 1MiB cho mỗi lần chạy. Các lệnh được sử dụng cho các bài kiểm tra NN tuần tự được đưa ra dưới đây:
Viết và đọc tuần tự : iozone -i 0 -i 1 -c -e -w -r 1m -I -s $Size -t $Thread -+n -+m /path/to/threadlist
Bộ đệm của hệ điều hành cũng bị loại bỏ hoặc làm sạch trên các nút máy khách giữa các lần lặp cũng như giữa các lần kiểm tra ghi và đọc bằng cách chạy lệnh:
# đồng bộ && echo 3 > /proc/sys/vm/drop_caches
Số sọc mặc định cho BeeGFS là 4. Tuy nhiên, kích thước khối và số lượng mục tiêu trên mỗi tệp có thể được định cấu hình trên cơ sở từng thư mục. Đối với tất cả các thử nghiệm này, kích thước sọc BeeGFS được chọn là 2MB và số lượng sọc được chọn là 3 vì chúng tôi có ba mục tiêu trên mỗi vùng NUMA như hiển thị bên dưới:
# beegfs-ctl –getentryinfo –mount=/mnt/beegfs /mnt/beegfs/benchmark –verbose
Loại mục: thư mục
ID mục: 0-5F6417B3-1
ID cha mẹ: gốc
Nút siêu dữ liệu: storage1-numa0-2 [ID: 2]
Chi tiết mẫu sọc:
+ Loại: RAID0
+ Kích thước chunk: 2M
+ Số lượng mục tiêu lưu trữ: mong muốn: 3
+ Kho lưu trữ: 1 (Mặc định)
Đường dẫn băm inode: 33/57/0-5F6417B3-1
Phương pháp thử nghiệm và các tham số điều chỉnh được sử dụng tương tự như các phương pháp được mô tả trước đây trong giải pháp dựa trên EDR . Để biết thêm chi tiết về vấn đề này, vui lòng tham khảo báo cáo nghiên cứu chuyên sâu về Giải pháp hiệu suất cao BeeGFS.
Ghi chú :
Số lượng khách hàng được sử dụng để mô tả đặc tính hiệu suất của giải pháp dựa trên EDR là 32 trong khi số lượng khách hàng được sử dụng để mô tả đặc tính hiệu suất của giải pháp dựa trên HDR100 chỉ là 16. Trong biểu đồ hiệu suất đưa ra bên dưới, điều này được biểu thị bằng cách bao gồm 16c biểu thị 16 khách hàng và 32c biểu thị 32 khách hàng. Các đường chấm chấm thể hiện hiệu suất của giải pháp dựa trên EDR và các đường liền nét thể hiện hiệu suất của giải pháp dựa trên HDR100.
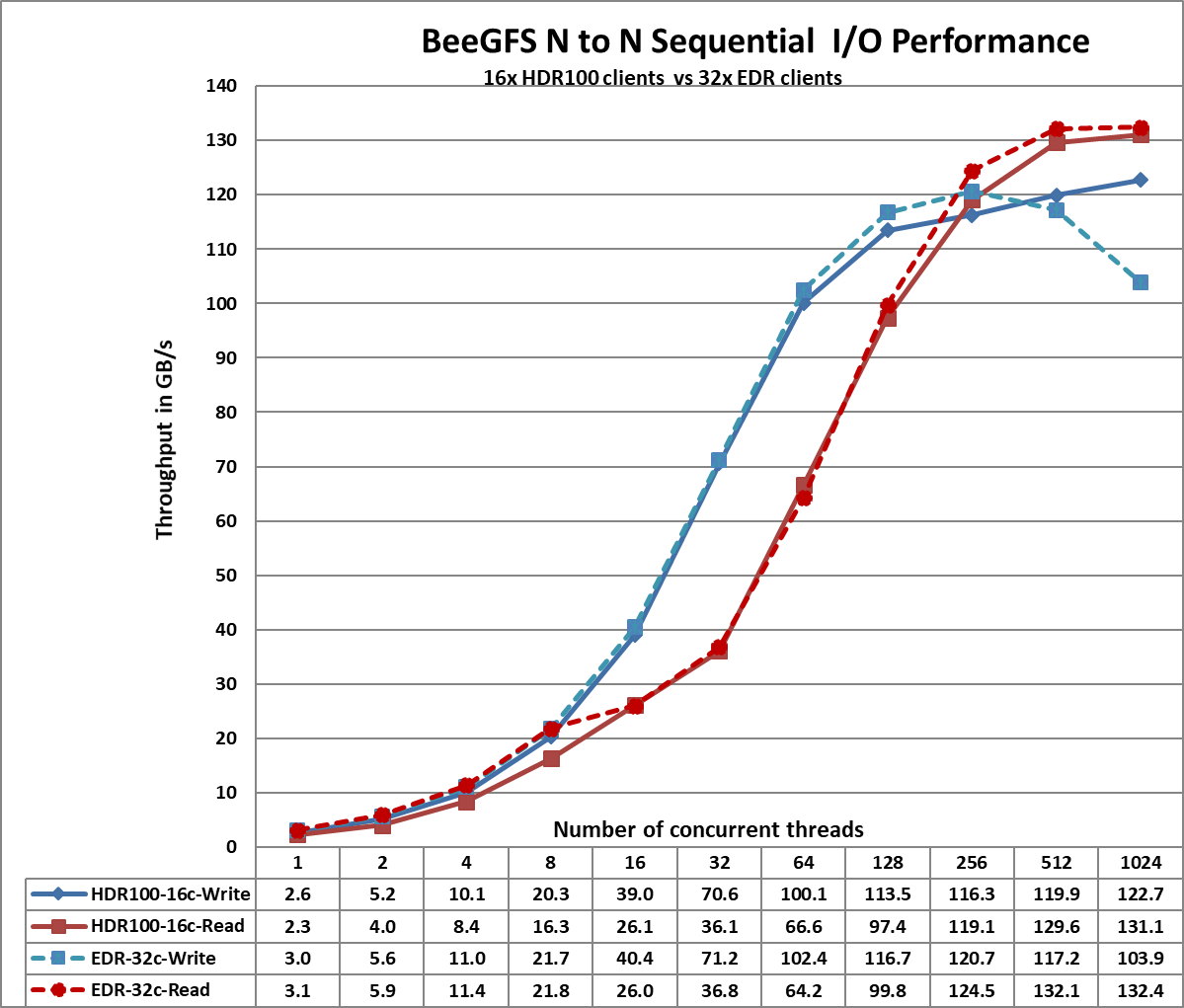
Hình 2. Kích thước tệp tổng hợp IOzone 8 TB tuần tự
Từ Hình 2, chúng tôi quan sát thấy hiệu suất đọc cao nhất của HDR100 là ~131 GB/s và ghi cao nhất là ~123 GB/s ở 1024 luồng. Mỗi ổ đĩa có thể cung cấp hiệu suất đọc cao nhất là 3,2 GB/giây và hiệu suất ghi cao nhất là 3,0 GB/giây, cho phép mức cao nhất theo lý thuyết là 460,8 GB/giây khi đọc và 432 GB/giây cho giải pháp. Tuy nhiên, trong giải pháp này, mạng là yếu tố hạn chế. Trong quá trình thiết lập, chúng tôi có tổng cộng 11 liên kết InfiniBand HDR100 cho các máy chủ lưu trữ. Mỗi liên kết có thể cung cấp hiệu suất cao nhất về mặt lý thuyết là 12,4 GB/s, cho phép hiệu suất cao nhất về mặt lý thuyết tổng hợp là 136,4 GB/s. Hiệu suất đọc và ghi cao nhất đạt được lần lượt là 96% và 90% hiệu suất cao nhất theo lý thuyết.
Chúng tôi nhận thấy rằng hiệu suất đọc cao nhất của giải pháp dựa trên HDR100 thấp hơn một chút so với hiệu suất đọc của giải pháp dựa trên EDR. Điều này có thể là do các bài kiểm tra điểm chuẩn được thực hiện bằng cách sử dụng 16 máy khách cho thiết lập dựa trên HDR100 trong khi giải pháp dựa trên EDR sử dụng 32 máy khách. Hiệu suất ghi được cải thiện với HDR100 là do SSD P4600 NVMe được sử dụng trong giải pháp dựa trên EDR chỉ có thể cung cấp 1,3 GB/giây để ghi tuần tự trong khi SSD P4610 NVMe cung cấp hiệu suất ghi cao nhất là 3,0 GB/giây.
Chúng tôi cũng nhận thấy rằng hiệu suất đọc thấp hơn so với ghi đối với số luồng từ 16 đến 128. Điều này là do thao tác đọc PCIe là Thao tác không được đăng, yêu cầu cả yêu cầu và hoàn thành, trong khi thao tác ghi PCIe là Thao tác đã đăng chỉ bao gồm một yêu cầu. Thao tác ghi PCIe là thao tác ghi và quên, trong đó khi Gói lớp giao dịch được chuyển giao cho Lớp liên kết dữ liệu, thao tác sẽ hoàn tất.
Thông lượng đọc thường thấp hơn thông lượng ghi vì việc đọc yêu cầu hai giao dịch thay vì một lần ghi cho cùng một lượng dữ liệu. PCI Express sử dụng mô hình giao dịch phân chia để đọc. Giao dịch đọc bao gồm các bước sau:
- Người yêu cầu gửi Yêu cầu đọc bộ nhớ (MRR).
- Người hoàn thiện sẽ gửi xác nhận đến MRR.
- Trình hoàn thành trả về Sự hoàn thành có dữ liệu.
Thông lượng đọc phụ thuộc vào độ trễ giữa thời điểm yêu cầu đọc được đưa ra và thời gian bộ hoàn thiện cần để trả lại dữ liệu. Tuy nhiên, khi ứng dụng đưa ra đủ số lượng yêu cầu đọc để bù đắp độ trễ này thì thông lượng sẽ được tối đa hóa. Thông lượng thấp hơn được đo khi người yêu cầu đợi hoàn thành trước khi đưa ra các yêu cầu tiếp theo. Thông lượng cao hơn được đăng ký khi có nhiều yêu cầu được đưa ra để giảm bớt độ trễ sau khi dữ liệu đầu tiên được trả về. Điều này giải thích tại sao hiệu suất đọc thấp hơn so với hiệu suất ghi từ 16 luồng đến 128 luồng và sau đó thông lượng tăng lên được quan sát thấy đối với số lượng luồng cao hơn là 256, 512 và 1024.
Thông tin chi tiết khác về Truy cập bộ nhớ trực tiếp PCI Express hiện có tại https://www.intel.com/content/www/us/en/programmable/documentation/nik1412547570040.html#nik1412547565760
Đọc và ghi ngẫu nhiên NN
IOzone được sử dụng ở chế độ ngẫu nhiên để đánh giá hiệu suất IO ngẫu nhiên. Các thử nghiệm được tiến hành với số lượng luồng bắt đầu từ 8 luồng đến tối đa 1024 luồng. Tùy chọn IO trực tiếp (-I) được sử dụng để chạy IOzone để tất cả các hoạt động bỏ qua bộ đệm đệm và đi thẳng vào đĩa. Số lượng sọc BeeGFS là 3 và kích thước khối 2 MB đã được sử dụng. Kích thước yêu cầu 4KiB đã được sử dụng trên IOzone và hiệu suất được đo bằng hoạt động I/O mỗi giây (IOPS). Kích thước tệp tổng hợp là 8 TB đã được chọn để giảm thiểu tác động của bộ nhớ đệm. Kích thước tệp tổng hợp được chia đều cho số lượng chuỗi trong bất kỳ thử nghiệm nhất định nào. Bộ nhớ đệm của hệ điều hành đã bị loại bỏ giữa các lần chạy trên máy chủ BeeGFS cũng như máy khách BeeGFS.
Lệnh được sử dụng để đọc và ghi ngẫu nhiên được đưa ra dưới đây:
iozone -i 2 -w -c -O -I -r 4K -s $Size -t $Thread -+n -+m /path/to/threadlist
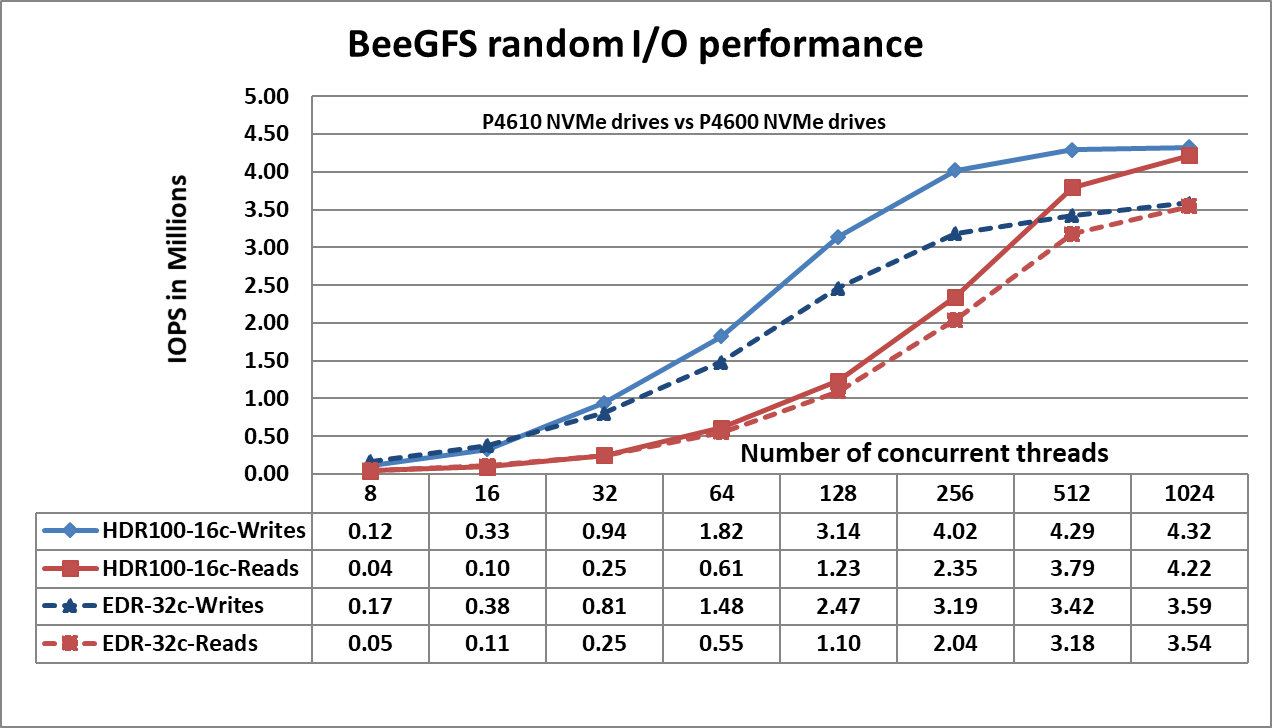
Hình 3. Hiệu suất ngẫu nhiên NN
Hình 3 cho thấy đỉnh ghi ngẫu nhiên ở mức ~4,3 triệu IOPS ở 1024 luồng và đỉnh đọc ngẫu nhiên ở mức ~4,2 triệu IOPS ở 1024 luồng. Cả hiệu suất ghi và đọc đều thể hiện hiệu suất cao hơn khi có số lượng yêu cầu IO lớn hơn. Điều này là do tiêu chuẩn NVMe hỗ trợ hàng đợi I/O lên tới 64K và tối đa 64K lệnh trên mỗi hàng đợi. Nhóm hàng đợi NVMe lớn này cung cấp mức độ song song I/O cao hơn và do đó chúng tôi quan sát thấy IOPS vượt quá 3 triệu. Bảng sau đây cung cấp sự so sánh về hiệu suất IO ngẫu nhiên của SSD NVMe P4610 và P4600 để hiểu rõ hơn về kết quả quan sát được.
Bảng 6. Thông số hiệu năng của SSD Intel NVMe
| Sản phẩm | SSD NVMe P4610 3.2 TB | SSD NVMe P4600 1.6 TB |
| Đọc ngẫu nhiên (Khoảng 100%) | 638000 IOPS | 559550 IOPS |
| Viết ngẫu nhiên (100% Span) | 222000 IOPS | 176500 IOPS |
Kiểm tra siêu dữ liệu
Hiệu suất siêu dữ liệu được đo bằng MDtest và OpenMPI để chạy điểm chuẩn trên 16 máy khách. Điểm chuẩn được sử dụng để đo lường hiệu suất tạo, thống kê và xóa tệp của giải pháp. Vì kết quả hiệu suất có thể bị ảnh hưởng bởi tổng số IOP, số lượng tệp trên mỗi thư mục và
số lượng chủ đề, số lượng tệp nhất quán trong các thử nghiệm đã được chọn để cho phép so sánh. Tổng số tệp được chọn là ~ 2M với lũy thừa hai (2^21 = 2097152). Số lượng tập tin trên mỗi
thư mục đã được sửa ở mức 1024 và số lượng thư mục thay đổi khi số lượng chủ đề thay đổi. Phương pháp thử nghiệm và các thư mục được tạo tương tự như phương pháp được mô tả trong blog trước.
Lệnh sau được sử dụng để thực thi điểm chuẩn:
mpirun -machinefile $hostlist –map-by node -np $threads ~/bin/mdtest -i 3 -b
$Thư mục -z 1 -L -I 1024 -y -u -t -F
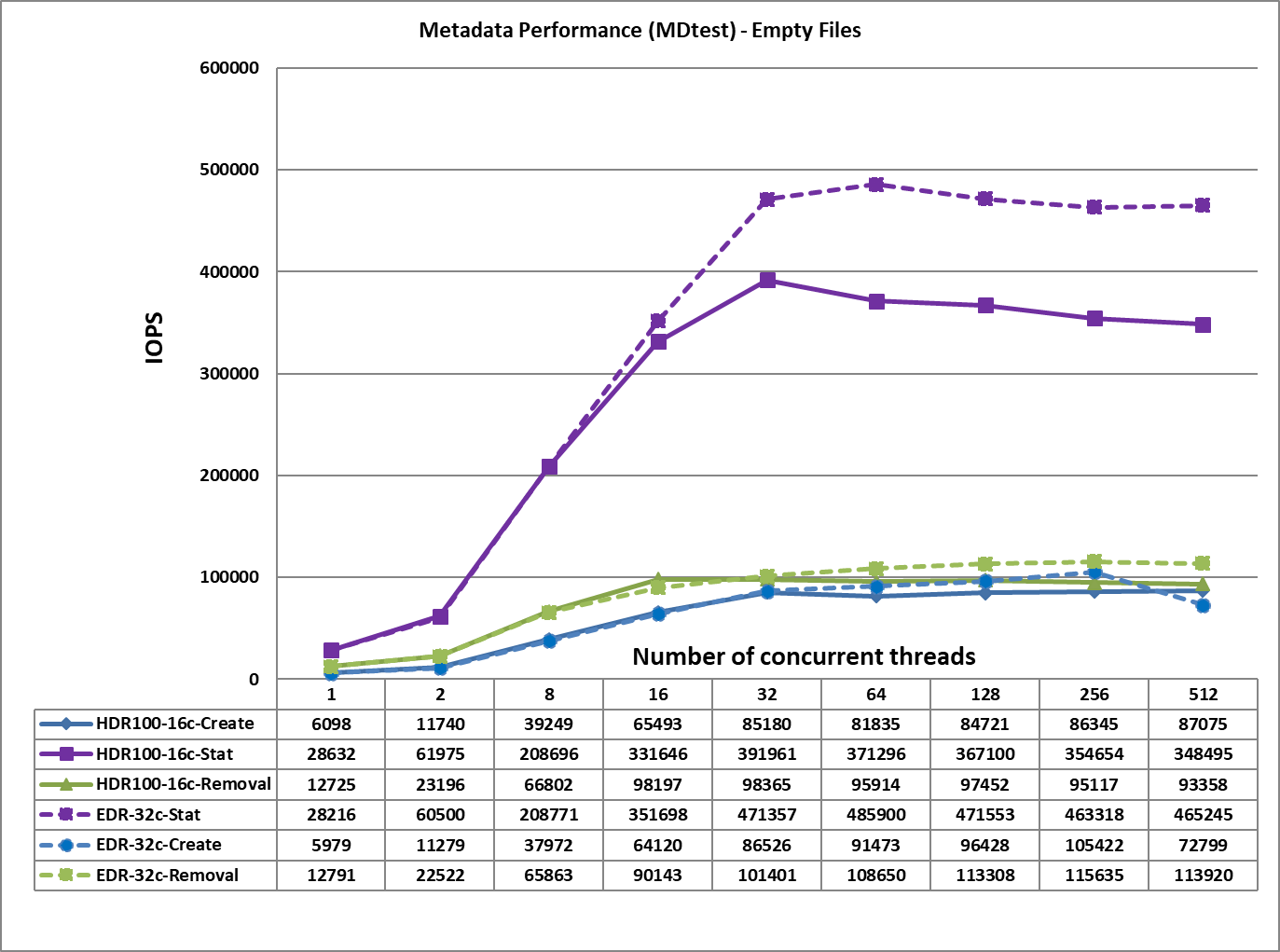
Hình 4. Hiệu suất siêu dữ liệu – Tệp trống
Từ Hình 4, chúng tôi nhận thấy rằng hiệu suất tạo, xóa và đọc tương đương với hiệu suất nhận được cho giải pháp dựa trên EDR trong khi hiệu suất Stat thấp hơn ~100K IOPS. Điều này có thể là do giải pháp dựa trên HDR100 chỉ sử dụng 16 máy khách để mô tả đặc tính hiệu suất trong khi giải pháp dựa trên EDR sử dụng 32 máy khách. Các hoạt động tạo tệp đạt giá trị cao nhất ở 512 luồng với tốc độ ~ 87K op/s. Các hoạt động loại bỏ và chỉ số đạt được giá trị tối đa ở 32 luồng với ~ 98K op/s và 392 op/s tương ứng.
Phần kết luận
Blog này trình bày các đặc tính hiệu suất của Giải pháp lưu trữ BeeGFS hiệu suất cao Dell EMC với phần mềm và phần cứng mới nhất. Ở cấp độ phần mềm, giải pháp hiệu suất cao hiện đã được cập nhật với
- CentOS 8.2.2004 làm hệ điều hành cơ sở
- BeeGFS v7.2
- Mellanox OFED phiên bản 5.0-2.1.8.0.
Ở cấp độ phần cứng, giải pháp sử dụng
- Bộ điều hợp HDR100 một cổng ConnectX-6
- Intel P4610 3,2 TB Sử dụng hỗn hợp, ổ NVMe và
- Công tắc lượng tử QM8790 với cổng 80x HDR100 100 Gb/s.
Phân tích hiệu suất cho phép chúng tôi kết luận rằng:
- Hiệu suất đọc và ghi tuần tự của IOzone tương tự như giải pháp dựa trên EDR vì mạng là điểm nghẽn ở đây.
- Hiệu suất đọc và ghi ngẫu nhiên của IOzone lớn hơn giải pháp dựa trên EDR trước đó khoảng ~ 1 triệu IOPS do sử dụng ổ P4610 NVMe mang lại hiệu suất đọc và ghi ngẫu nhiên được cải thiện.
- Hiệu suất tạo và xóa tệp tương tự như giải pháp dựa trên EDR.
- Hiệu suất thống kê tệp giảm 19% do chỉ sử dụng 16 máy khách trong giải pháp hiện tại so với 32 máy khách được sử dụng trong giải pháp dựa trên EDR trước đó.
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...