
Tin tức
Giải pháp Sẵn sàng của Dell EMC cho Bộ lưu trữ HPC PixStor
Giới thiệu
Các môi trường HPC ngày nay đã tăng nhu cầu lưu trữ tốc độ rất cao, điều này cũng thường yêu cầu dung lượng cao và truy cập phân tán thông qua một số giao thức tiêu chuẩn như NFS, SMB và các giao thức khác. Các yêu cầu HPC có nhu cầu cao đó thường được bao phủ bởi Hệ thống tệp song song cung cấp quyền truy cập đồng thời vào một tệp hoặc một tập hợp tệp từ nhiều nút, phân phối dữ liệu rất hiệu quả và an toàn cho nhiều LUN trên một số máy chủ.
giải pháp xây dựng
Trong blog này, chúng tôi giới thiệu phần bổ sung mới nhất của Dell EMC cho các giải pháp Hệ thống tệp song song (PFS) cho môi trường HPC, Giải pháp sẵn sàng của Dell EMC cho Bộ lưu trữ HPC PixStor . Hình 1 trình bày kiến trúc tham chiếu, tận dụng các máy chủ Dell EMC PowerEdge R740 và mảng lưu trữ PowerVault ME4084 và ME4024, với phần mềm PixStor từ công ty đối tác Arcastream của chúng tôi .
PixStor bao gồm Hệ thống tệp song song chung phổ biến còn được gọi là Thang đo quang phổ dưới dạng thành phần PFS, ngoài các thành phần phần mềm Arcastream như phân tích nâng cao, quản trị và giám sát đơn giản hóa, tìm kiếm tệp hiệu quả, khả năng cổng nâng cao, v.v.

Hình 1: Kiến trúc tham khảo.
Thành phần giải pháp
Giải pháp này dự kiến sẽ được phát hành cùng với CPU Xeon có khả năng mở rộng thế hệ thứ 2 mới nhất của Intel Xeon, hay còn gọi là CPU Cascade Lake và một số máy chủ sẽ sử dụng RAM nhanh nhất có sẵn cho chúng (2933 MT/s). Tuy nhiên, do phần cứng có sẵn để thử nghiệm giải pháp và đặc trưng cho hiệu suất của giải pháp, các máy chủ có CPU Xeon có thể mở rộng thế hệ thứ nhất của Intel Xeon hay còn gọi là bộ xử lý Skylake và RAM chậm hơn đã được sử dụng. Do nút thắt cổ chai của giải pháp nằm ở bộ điều khiển SAS của mảng Dell EMC PowerVault ME40x4, nên dự kiến sẽ không có sự chênh lệch hiệu suất đáng kể nào sau khi CPU Skylake và RAM được thay thế bằng CPU Cascade Lake dự kiến và RAM nhanh hơn. Ngoài ra, ngay cả khi phiên bản PixStor mới nhất hỗ trợ RHEL 7.6 đã có sẵn tại thời điểm định cấu hình hệ thống, nó đã được quyết định tiếp tục quy trình QA và sử dụng Red Hat® Enterprise Linux® 7.5 và phiên bản nhỏ trước đó của PixStor để mô tả hệ thống. Sau khi hệ thống được cập nhật lên CPU Cascade Lake, phần mềm PixStor cũng sẽ được cập nhật lên phiên bản mới nhất và một số kiểm tra điểm hiệu suất sẽ được thực hiện để xác minh rằng hiệu suất vẫn ở mức gần với các con số được báo cáo trong tài liệu này.
Do tình huống được mô tả trước đó, Bảng 1 có danh sách các thành phần chính của giải pháp. Cột giữa có các thành phần được lên kế hoạch sử dụng vào thời điểm phát hành và do đó có sẵn cho khách hàng và cột cuối cùng là danh sách thành phần thực sự được sử dụng để mô tả hiệu suất của giải pháp. Ổ đĩa được liệt kê hoặc dữ liệu (12TB NLS) và siêu dữ liệu (SSD 960Gb) là những ổ đĩa được sử dụng để mô tả đặc tính hiệu suất và các ổ đĩa nhanh hơn có thể cung cấp IOP ngẫu nhiên tốt hơn và có thể cải thiện hoạt động tạo/xóa siêu dữ liệu.
Cuối cùng, để hoàn thiện, danh sách các ổ cứng HDD và SSD siêu dữ liệu có thể có đã được đưa vào, danh sách này dựa trên các ổ đĩa được hỗ trợ như được chỉ định trên ma trận hỗ trợ Dell EMC PowerVault ME4, có sẵn trực tuyến.
Bảng 1 Các thành phần được sử dụng tại thời điểm xuất xưởng và những thành phần được sử dụng trên giường thử nghiệm
Đặc tính hiệu suất
Để mô tả Giải pháp sẵn sàng mới này , chúng tôi đã sử dụng phần cứng được chỉ định trong cột cuối cùng của Bảng 1 , bao gồm Mô-đun siêu dữ liệu có nhu cầu cao tùy chọn. Để đánh giá hiệu suất của giải pháp, các điểm chuẩn sau đã được sử dụng:
- IOzone N đến N tuần tự
- IOR N đến 1 tuần tự
- IOzone ngẫu nhiên
- MDtest
Đối với tất cả các điểm chuẩn được liệt kê ở trên, giường thử nghiệm có khách hàng như được mô tả trong Bảng 2phía dưới. Vì số lượng nút điện toán có sẵn để thử nghiệm là 16, nên khi cần số lượng luồng cao hơn, các luồng đó sẽ được phân bổ đồng đều trên các nút điện toán (tức là 32 luồng = 2 luồng trên mỗi nút, 64 luồng = 4 luồng trên mỗi nút, 128 luồng = 8 luồng trên mỗi nút, 256 luồng = 16 luồng trên mỗi nút, 512 luồng = 32 luồng trên mỗi nút, 1024 luồng = 64 luồng trên mỗi nút). Mục đích là để mô phỏng số lượng máy khách đồng thời cao hơn với số lượng nút tính toán hạn chế. Do điểm chuẩn hỗ trợ số lượng lớn luồng nên giá trị tối đa lên tới 1024 đã được sử dụng (được chỉ định cho từng thử nghiệm), đồng thời tránh chuyển đổi ngữ cảnh quá mức và các tác dụng phụ liên quan khác ảnh hưởng đến kết quả hoạt động.
Bảng 2 Giường thử nghiệm khách hàng
Số lượng nút Máy khách 16 nút máy khách C6320 Bộ xử lý trên mỗi nút máy khách 2 x Intel(R) Xeon(R) Gold E5-2697v4 18 Nhân @ 2.30GHz Bộ nhớ trên mỗi nút máy khách 12 x 16GiB 2400 MT/s RDIMM BIOS 2.8.0 nhân hệ điều hành 3.10.0-957.10.1 Phiên bản GPFS 5.0.3
Hiệu suất IOzone tuần tự N máy khách đến N tệp
Hiệu suất của N máy khách liên tiếp đến N tệp được đo bằng IOzone phiên bản 3.487. Các thử nghiệm được thực hiện đa dạng từ một luồng đơn lẻ cho đến 1024 luồng.
Hiệu ứng bộ nhớ đệm đã được giảm thiểu bằng cách đặt nhóm trang GPFS có thể điều chỉnh thành 16GiB và sử dụng các tệp lớn hơn gấp hai lần kích thước đó. Điều quan trọng cần lưu ý là đối với GPFS, tính năng có thể điều chỉnh sẽ đặt dung lượng bộ nhớ tối đa được sử dụng để lưu vào bộ nhớ đệm dữ liệu, bất kể dung lượng RAM được cài đặt và dung lượng trống. Ngoài ra, điều quan trọng cần lưu ý là trong khi ở các giải pháp Dell EMC HPC trước đây, kích thước khối cho các lần truyền tuần tự lớn là 1 MiB, thì GPFS được định dạng bằng các khối 8 MiB và do đó, giá trị đó được sử dụng trên điểm chuẩn để có hiệu suất tối ưu. Điều đó có thể trông quá lớn và dường như lãng phí quá nhiều không gian, nhưng GPFS sử dụng phân bổ khối con để ngăn chặn tình trạng đó. Trong cấu hình hiện tại, mỗi khối được chia thành 256 khối con với 32 KiB mỗi khối.
Các lệnh sau được sử dụng để thực thi điểm chuẩn cho việc ghi và đọc, trong đó Chủ đề là biến có số lượng luồng được sử dụng (1 đến 1024 tăng dần theo lũy thừa của hai) và danh sách luồng là tệp phân bổ mỗi luồng trên một nút khác nhau, sử dụng vòng tròn để trải đều chúng trên 16 nút điện toán../iozone -i0 -c -e -w -r 8M -s 128G -t $Threads -+n -+m ./threadlist
./iozone -i1 -c -e -w -r 8M -s 128G -t $ Chủ đề -+n -+m ./threadlist
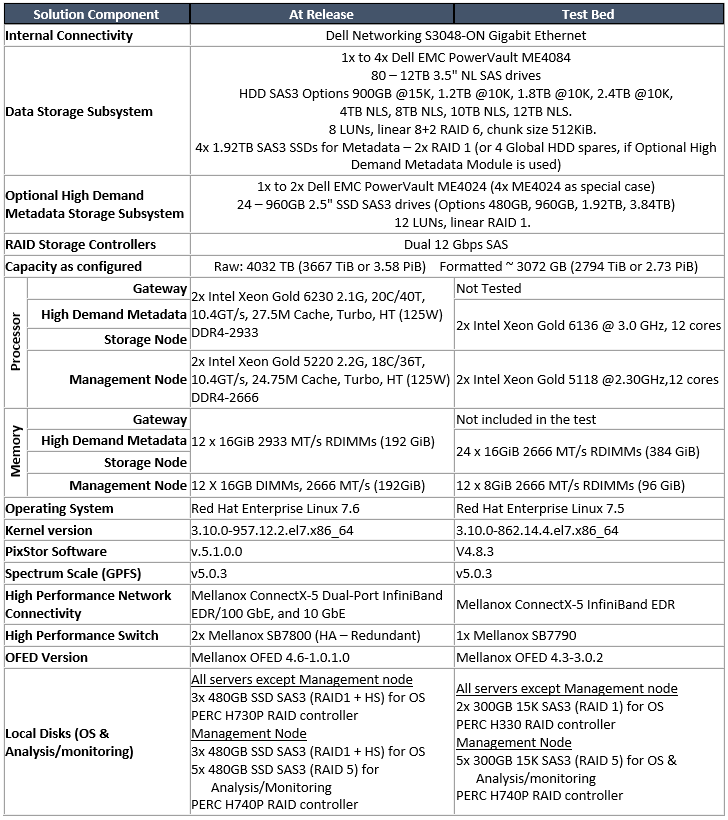
Hình 2: Hiệu suất tuần tự từ N đến NTừ kết quả, chúng tôi có thể quan sát thấy rằng hiệu suất tăng rất nhanh với số lượng máy khách được sử dụng và sau đó đạt đến mức ổn định cho đến khi đạt đến số lượng luồng tối đa mà IOzone cho phép, và do đó, tệp tuần tự có dung lượng lớn hiệu suất ổn định ngay cả đối với 1024 khách hàng đồng thời. Lưu ý rằng hiệu suất đọc tối đa là 23 GB/giây ở 32 luồng và rất có thể nút thắt cổ chai là giao diện InfiniBand EDR, trong khi mảng ME4 vẫn có sẵn một số hiệu suất bổ sung. Tương tự, lưu ý rằng hiệu suất ghi tối đa 16,7 đã đạt được hơi sớm ở 16 luồng và rõ ràng là thấp so với thông số kỹ thuật của mảng ME4.
Ở đây, điều quan trọng cần nhớ là chế độ hoạt động ưa thích của GPFS bị phân tán và giải pháp được định dạng để sử dụng nó. Trong chế độ này, các khối được phân bổ ngay từ đầu theo kiểu giả ngẫu nhiên, trải rộng dữ liệu trên toàn bộ bề mặt của mỗi ổ cứng. Mặc dù nhược điểm rõ ràng là hiệu suất tối đa ban đầu nhỏ hơn, nhưng hiệu suất đó được duy trì khá ổn định bất kể có bao nhiêu dung lượng được sử dụng trên hệ thống tệp. Điều đó trái ngược với các hệ thống tệp song song khác ban đầu sử dụng các rãnh bên ngoài có thể chứa nhiều dữ liệu (khu vực) hơn trên mỗi vòng quay của đĩa và do đó có hiệu suất cao nhất có thể mà ổ cứng có thể cung cấp, nhưng khi hệ thống sử dụng nhiều không gian hơn, các rãnh bên trong sẽ ít hơn. dữ liệu trên mỗi vòng quay được sử dụng, do đó làm giảm hiệu suất.
Hiệu suất IOR tuần tự N máy khách thành 1 tệp
Hiệu suất của các ứng dụng khách N tuần tự cho một tệp được chia sẻ duy nhất được đo bằng IOR phiên bản 3.3.0, được hỗ trợ bởi OpenMPI v4.0.1 để chạy điểm chuẩn trên 16 nút điện toán. Các thử nghiệm được thực hiện đa dạng từ một luồng cho đến 1024 luồng.
Hiệu ứng bộ nhớ đệm đã được giảm thiểu bằng cách đặt nhóm trang GPFS có thể điều chỉnh thành 16GiB và sử dụng các tệp lớn hơn gấp hai lần kích thước đó. Bài kiểm tra điểm chuẩn này đã sử dụng 8 khối MiB để có hiệu suất tối ưu. Phần kiểm tra hiệu suất trước đó có giải thích đầy đủ hơn cho những vấn đề đó.
Các lệnh sau đây được sử dụng để thực thi điểm chuẩn cho việc ghi và đọc, trong đó Chủ đề là biến có số lượng chủ đề được sử dụng (1 đến 1024 tăng dần theo lũy thừa của hai) và my_hosts.$Threads là tệp tương ứng phân bổ mỗi chủ đề trên một nút khác, sử dụng vòng tròn để trải chúng đồng nhất trên 16 nút điện toán.mpirun –allow-run-as-root -np $Threads –hostfile my_hosts.$Threads –mca btl_openib_allow_ib 1 –mca pml ^ucx –oversubscribe –prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior /bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -w -s 1 -t 8m -b 128G
mpirun –allow-run-as-root -np $Threads –hostfile my_hosts.$Threads –mca btl_openib_allow_ib 1 –mca pml ^ucx –oversubscribe –prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior /bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -r -s 1 -t 8m -b 128G
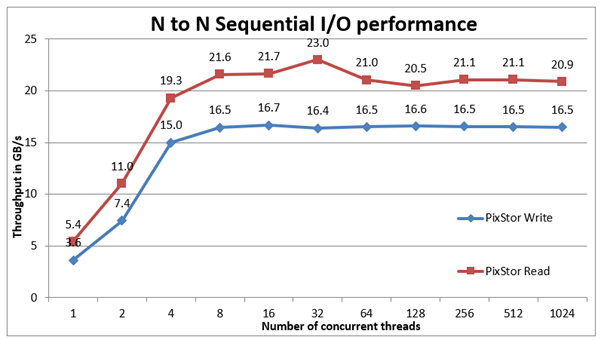
Hình 3: Hiệu suất tuần tự N đến 1
Từ kết quả, chúng tôi có thể quan sát thấy rằng hiệu suất tăng trở lại rất nhanh với số lượng máy khách được sử dụng và sau đó đạt đến mức ổn định bán ổn định đối với số lần đọc và rất ổn định đối với số lần ghi đối với số lượng luồng tối đa được sử dụng trong thử nghiệm này. Do đó, hiệu suất tuần tự của tệp được chia sẻ đơn lớn ổn định ngay cả đối với 1024 máy khách đồng thời. Lưu ý rằng hiệu suất đọc tối đa là 23,7 GB/giây ở 16 luồng và rất có thể nút thắt cổ chai là giao diện InfiniBand EDR, trong khi mảng ME4 vẫn có sẵn một số hiệu suất bổ sung. Hơn nữa, hiệu suất đọc giảm từ giá trị đó cho đến khi đạt mức ổn định khoảng 20,5 GB/giây, với mức giảm tạm thời xuống 18,5 GB/giây ở 128 luồng. Tương tự, lưu ý rằng hiệu suất ghi tối đa là 16,5 đã đạt được ở 16 luồng và rõ ràng là thấp so với thông số mảng ME4.
Các khối nhỏ ngẫu nhiên Hiệu suất IOzone N máy khách thành N tệp
Hiệu suất N máy khách ngẫu nhiên đến N tệp được đo bằng IOzone phiên bản 3.487. Các thử nghiệm được thực hiện đa dạng từ một luồng cho đến 1024 luồng. Bài kiểm tra điểm chuẩn này đã sử dụng 4 khối KiB để mô phỏng lưu lượng khối nhỏ.
Hiệu ứng bộ nhớ đệm đã được giảm thiểu bằng cách đặt nhóm trang GPFS có thể điều chỉnh thành 16GiB và sử dụng các tệp có kích thước gấp hai lần kích thước đó. Phần kiểm tra hiệu suất đầu tiên có giải thích đầy đủ hơn về lý do tại sao điều này lại hiệu quả trên GPFS.
Lệnh sau được sử dụng để thực thi điểm chuẩn ở chế độ IO ngẫu nhiên cho cả ghi và đọc, trong đó Chủ đề là biến có số lượng luồng được sử dụng (1 đến 1024 tăng dần theo lũy thừa của hai) và danh sách luồng là tệp phân bổ từng luồng trên một nút khác, sử dụng vòng tròn để phân bổ chúng đồng nhất trên 16 nút điện toán../iozone -i2 -c -O -w -r 4K -s 32G -t $Threads -+n -+m ./threadlist
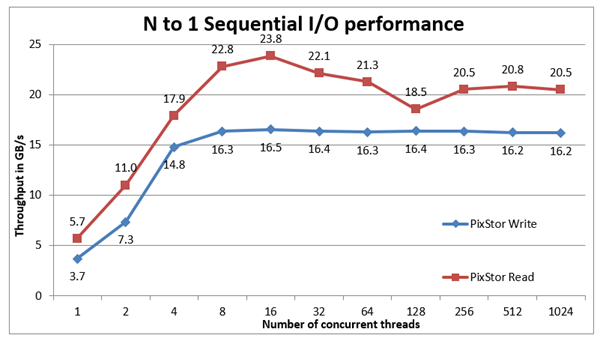
Hình 4: Hiệu suất ngẫu nhiên từ N đến NTừ kết quả, chúng tôi có thể quan sát thấy rằng hiệu suất ghi bắt đầu ở giá trị cao gần 8,2 nghìn IOPS và tăng dần lên 128 luồng khi đạt đến mức ổn định và duy trì gần với giá trị tối đa là 16,2 nghìn IOP. Mặt khác, hiệu suất đọc bắt đầu rất nhỏ ở mức hơn 200 IOPS và tăng hiệu suất gần như tuyến tính với số lượng máy khách được sử dụng (hãy nhớ rằng số lượng luồng được nhân đôi cho mỗi điểm dữ liệu) và đạt hiệu suất tối đa là 20,4K IOPS ở 512 đề không có dấu hiệu đạt cực đại. Tuy nhiên, việc sử dụng nhiều luồng hơn trên 16 nút điện toán hiện tại với hai CPU mỗi nút và trong đó mỗi CPU có 18 lõi, sẽ có hạn chế là không có đủ lõi để chạy số lượng luồng IOzone tối đa (1024) mà không phát sinh chuyển ngữ cảnh (16 x 2 x 18 = 576 lõi), làm hạn chế đáng kể hiệu năng.
Hiệu suất siêu dữ liệu với MDtest bằng các tệp trống
Hiệu suất siêu dữ liệu được đo bằng MDtest phiên bản 3.3.0, được hỗ trợ bởi OpenMPI v4.0.1 để chạy điểm chuẩn trên 16 nút tính toán. Các thử nghiệm được thực hiện đa dạng từ một luồng cho đến 512 luồng. Điểm chuẩn chỉ được sử dụng cho các tệp (không có siêu dữ liệu thư mục), nhận số lần tạo, thống kê, đọc và xóa mà giải pháp có thể xử lý.
Để đánh giá đúng giải pháp so với các giải pháp lưu trữ Dell EMC HPC khác, Mô-đun siêu dữ liệu nhu cầu cao tùy chọn đã được sử dụng, nhưng với một mảng ME4024 duy nhất, ngay cả khi cấu hình lớn và thử nghiệm trong công việc này được chỉ định có hai ME4024.
Mô-đun siêu dữ liệu có nhu cầu cao này có thể hỗ trợ tối đa bốn mảng ME4024 và nên tăng số lượng mảng ME4024 lên 4 trước khi thêm một mô-đun siêu dữ liệu khác. Các mảng ME4024 bổ sung dự kiến sẽ tăng hiệu suất Siêu dữ liệu một cách tuyến tính với mỗi mảng bổ sung, ngoại trừ có thể đối với các hoạt động Stat (và Đọc đối với các tệp trống), vì các con số này rất cao, tại một số điểm, CPU sẽ trở thành nút cổ chai và hiệu suất sẽ không tiếp tục để tăng tuyến tính.
Lệnh sau được sử dụng để thực thi điểm chuẩn, trong đó Chủ đề là biến có số lượng chủ đề được sử dụng (1 đến 512 tăng dần theo lũy thừa của hai) và my_hosts.$Threads là tệp tương ứng phân bổ từng luồng trên một nút khác nhau, sử dụng vòng tròn để trải đều chúng trên 16 nút điện toán. Tương tự như điểm chuẩn IO ngẫu nhiên, số lượng luồng tối đa được giới hạn ở 512, do không có đủ lõi cho 1024 luồng và việc chuyển ngữ cảnh sẽ ảnh hưởng đến kết quả, báo cáo một con số thấp hơn hiệu suất thực của giải pháp.mpirun –allow-run-as-root -np $Threads –hostfile my_hosts.$Threads –prefix /mmfs1/perftest/ompi –mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d / mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F
Vì kết quả hiệu suất có thể bị ảnh hưởng bởi tổng số IOP, số lượng tệp trên mỗi thư mục và số lượng luồng, nên chúng tôi đã quyết định giữ cố định tổng số tệp thành 2 tệp MiB (2^21 = 2097152), số số tệp trên mỗi thư mục được cố định ở mức 1024 và số lượng thư mục thay đổi khi số lượng luồng thay đổi như trong Bảng 3.
Bảng 3: Phân phối tệp MDtest trên các thư mục
Số của chủ đề Số lượng thư mục trên mỗi chủ đề Tổng số tệp 1 2048 2.097.152 2 1024 2.097.152 4 512 2.097.152 số 8 256 2.097.152 16 128 2.097.152 32 64 2.097.152 64 32 2.097.152 128 16 2.097.152 256 số 8 2.097.152 512 4 2.097.152 1024 2 2.097.152
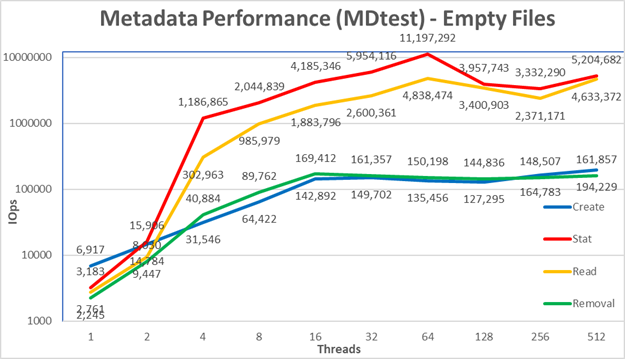
Hình 5: Hiệu suất siêu dữ liệu – Các tập tin trốngĐầu tiên, lưu ý rằng thang đo được chọn là logarit với cơ số 10, để cho phép so sánh các hoạt động có sự khác biệt vài bậc về độ lớn; nếu không, một số thao tác sẽ trông giống như một đường phẳng gần bằng 0 trên biểu đồ bình thường. Biểu đồ nhật ký với cơ số 2 có thể phù hợp hơn, vì số luồng được tăng theo lũy thừa 2, nhưng biểu đồ trông khá giống nhau và mọi người có xu hướng xử lý và ghi nhớ các số tốt hơn dựa trên lũy thừa 10.
Hệ thống nhận được kết quả rất tốt với các thao tác Stat và Read đạt giá trị cao nhất ở 64 luồng với lần lượt là 11,2M thao tác/giây và 4,8M thao tác/giây. Hoạt động loại bỏ đạt mức tối đa 169,4K op/s ở 16 luồng và hoạt động Tạo đạt mức cao nhất ở 512 luồng với 194,2K op/s. Hoạt động Thống kê và Đọc có nhiều biến đổi hơn, nhưng khi chúng đạt đến giá trị cao nhất, hiệu suất sẽ không giảm xuống dưới 3 triệu thao tác/giây đối với Thống kê và 2 triệu thao tác/giây đối với Đọc. Tạo và Xóa sẽ ổn định hơn khi chúng đạt đến mức ổn định và duy trì trên 140K thao tác/giây đối với Xóa và 120K thao tác/giây đối với Tạo.
Hiệu suất siêu dữ liệu với MDtest bằng 4 tệp KiB
Thử nghiệm này gần giống với thử nghiệm trước, ngoại trừ việc thay vì các tệp trống, các tệp nhỏ 4KiB đã được sử dụng.
Lệnh sau được sử dụng để thực thi điểm chuẩn, trong đó Chủ đề là biến có số lượng chủ đề được sử dụng (1 đến 512 tăng dần theo lũy thừa của hai) và my_hosts.$Threads là tệp tương ứng phân bổ từng luồng trên một nút khác nhau, sử dụng vòng tròn để trải đều chúng trên 16 nút điện toán.mpirun –allow-run-as-root -np $Threads –hostfile my_hosts.$Threads –prefix /mmfs1/perftest/ompi –mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d / mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 4K -e 4K
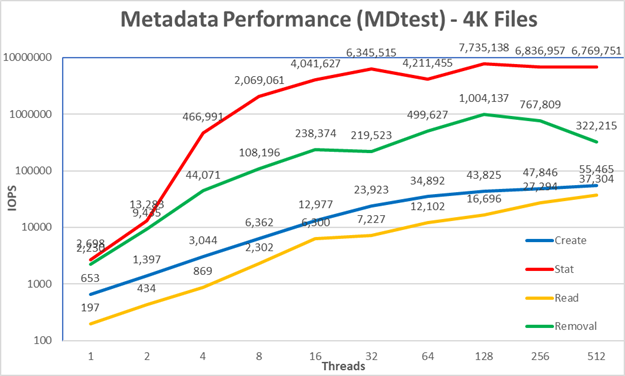
Hình 6: Hiệu suất siêu dữ liệu – Tệp nhỏ (4K)Hệ thống nhận được kết quả rất tốt cho các thao tác Thống kê và Loại bỏ đạt giá trị cao nhất ở 128 luồng với 7,7 triệu thao tác/giây và 1 triệu thao tác/giây tương ứng. Hoạt động loại bỏ đạt mức tối đa là 37,3K op/s và hoạt động Tạo đạt mức cao nhất là 55,5K op/s, cả hai đều ở 512 luồng. Các thao tác Thống kê và Loại bỏ có nhiều biến đổi hơn, nhưng khi chúng đạt đến giá trị cao nhất, hiệu suất không giảm xuống dưới 4 triệu thao tác/giây đối với Chỉ số và 200 nghìn thao tác/giây đối với Loại bỏ. Tạo và Đọc ít biến đổi hơn và tiếp tục tăng khi số lượng chuỗi tăng lên.
Vì những con số này dành cho một mô-đun siêu dữ liệu với một ME4024 duy nhất, nên hiệu suất sẽ tăng đối với mỗi mảng ME4024 bổ sung, tuy nhiên, chúng tôi không thể chỉ giả định mức tăng tuyến tính cho mỗi thao tác. Trừ khi toàn bộ tệp vừa với inode của tệp đó, các mục tiêu dữ liệu trên ME4084 sẽ được sử dụng để lưu trữ tệp 4K, hạn chế hiệu suất ở một mức độ nào đó. Vì kích thước inode là 4KiB và nó vẫn cần lưu trữ siêu dữ liệu nên chỉ những tệp khoảng 3 KiB mới phù hợp bên trong và bất kỳ tệp nào lớn hơn sẽ sử dụng mục tiêu dữ liệu.
Hiệu suất siêu dữ liệu bằng MDtest với các tệp 3K
Thử nghiệm này gần như giống hoàn toàn với các thử nghiệm trước, ngoại trừ các tệp nhỏ 3KiB đã được sử dụng. Sự khác biệt chính là các tệp này nằm hoàn toàn bên trong inode. Do đó, các nút lưu trữ và ME4084 của chúng không được sử dụng, giúp cải thiện tốc độ tổng thể bằng cách chỉ sử dụng phương tiện SSD để lưu trữ và ít truy cập mạng hơn.
Lệnh sau được sử dụng để thực thi điểm chuẩn, trong đó Chủ đề là biến có số lượng chủ đề được sử dụng (1 đến 512 tăng dần theo lũy thừa của hai) và my_hosts.$Threads là tệp tương ứng phân bổ từng luồng trên một nút khác nhau, sử dụng vòng tròn để trải đều chúng trên 16 nút điện toán.mpirun –allow-run-as-root -np $Threads –hostfile my_hosts.$Threads –prefix /mmfs1/perftest/ompi –mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d / mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 3K -e 3K
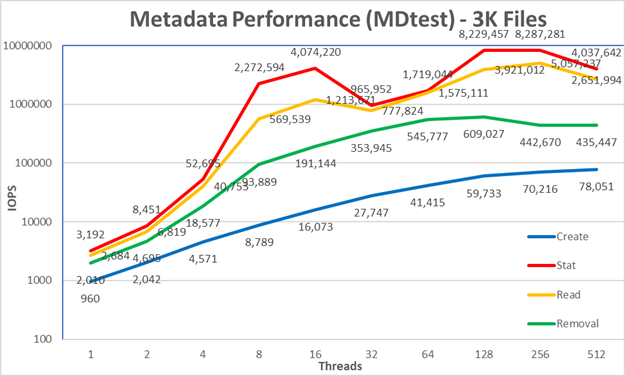
Hình 7: Hiệu suất siêu dữ liệu – Tệp nhỏ (3K)Hệ thống nhận được kết quả rất tốt cho các thao tác Stat và Read đạt giá trị cao nhất ở 256 luồng với lần lượt là 8,29 triệu thao tác/giây và 5,06 triệu thao tác/giây. Hoạt động xóa đạt tối đa 609K thao tác/giây ở 128 luồng và Thao tác tạo đạt tối đa 78K thao tác/giây ở 512 luồng. Các thao tác Thống kê và Đọc có nhiều biến đổi hơn so với Tạo và Loại bỏ. Việc loại bỏ có hiệu suất giảm nhẹ đối với hai điểm luồng cao hơn cho thấy hiệu suất duy trì sau 128 luồng sẽ hơn 400 nghìn thao tác/giây một chút. Số lần tạo tiếp tục tăng lên tới 512 luồng, nhưng có vẻ như đang đạt đến mức ổn định nên hiệu suất tối đa có thể vẫn dưới 100K thao tác/giây.
Do các tệp nhỏ như thế này được lưu trữ hoàn toàn trên mô-đun siêu dữ liệu dựa trên SSD, các ứng dụng yêu cầu hiệu suất tệp nhỏ vượt trội có thể sử dụng một hoặc nhiều mô-đun siêu dữ liệu có nhu cầu cao tùy chọn để tăng hiệu suất tệp nhỏ. Tuy nhiên, các tệp phù hợp với inode rất nhỏ theo tiêu chuẩn hiện tại. Ngoài ra, do các mục tiêu siêu dữ liệu sử dụng RAID1 với ổ SSD tương đối nhỏ (kích thước tối đa là 19,2TB), dung lượng sẽ bị hạn chế khi so sánh với các nút lưu trữ. Do đó, cần phải cẩn thận để tránh làm đầy các mục tiêu Siêu dữ liệu, điều này có thể gây ra các lỗi không cần thiết và các vấn đề khác.
Phân tích nâng cao
Trong số các khả năng của PixStor, việc giám sát hệ thống tệp thông qua phân tích nâng cao có thể là điều cần thiết để đơn giản hóa rất nhiều việc quản trị, giúp chủ động hoặc chủ động tìm ra các sự cố hoặc sự cố tiềm ẩn. Tiếp theo, chúng tôi sẽ xem xét ngắn gọn một số khả năng này.
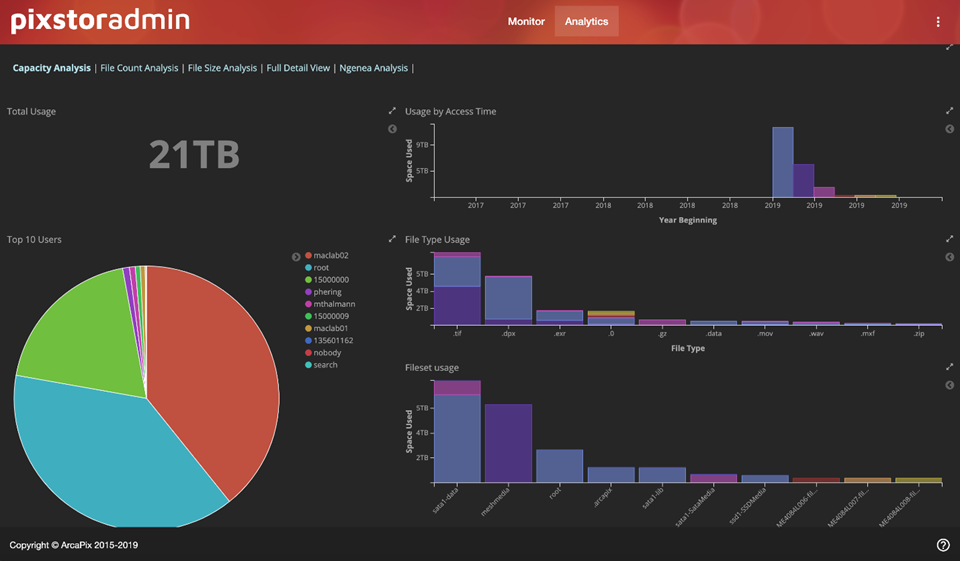
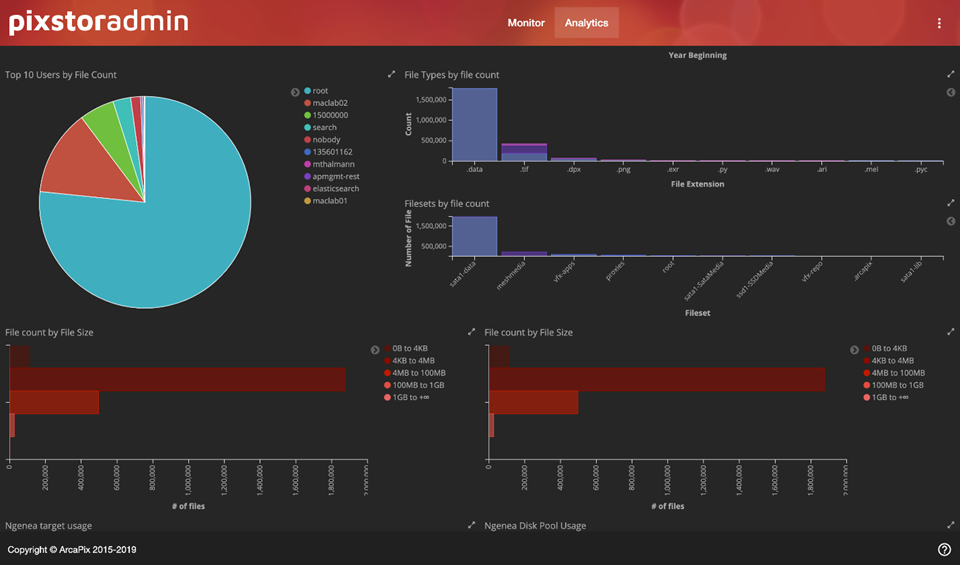
Hình 8 hiển thị thông tin hữu ích dựa trên dung lượng hệ thống tệp. Ở phía bên trái, tổng dung lượng hệ thống tệp được sử dụng và mười người dùng hàng đầu dựa trên dung lượng hệ thống tệp được sử dụng. Ở phía bên phải, chế độ xem lịch sử với dung lượng được sử dụng trong nhiều năm, sau đó là mười loại tệp hàng đầu được sử dụng và mười bộ tệp hàng đầu, cả hai đều dựa trên dung lượng được sử dụng, ở định dạng tương tự như biểu đồ pareto (không có dòng cho tổng số tích lũy). Với thông tin này, có thể dễ dàng tìm thấy người dùng sử dụng nhiều hơn phần chia sẻ công bằng của họ đối với hệ thống tệp, xu hướng sử dụng dung lượng để hỗ trợ các quyết định về tăng trưởng dung lượng trong tương lai, tệp nào đang sử dụng nhiều dung lượng nhất hoặc dự án nào đang chiếm nhiều dung lượng nhất năng lực.
Hình 8: PixStor Analytics – Chế độ xem dung lượngHình 9 cung cấp chế độ xem đếm tệp với hai cách rất hữu ích để tìm ra sự cố. Nửa đầu của màn hình có mười người dùng hàng đầu trong biểu đồ hình tròn và mười loại tệp hàng đầu và mười bộ tệp hàng đầu (nghĩ về các dự án) ở định dạng tương tự như biểu đồ pareto (không có các dòng cho tổng số tích lũy), tất cả đều dựa trên số lượng tệp . Thông tin này có thể được sử dụng để trả lời một số câu hỏi quan trọng. Ví dụ: người dùng nào đang độc quyền hệ thống tệp bằng cách tạo quá nhiều tệp, loại tệp nào đang tạo ra cơn ác mộng siêu dữ liệu hoặc dự án nào đang sử dụng hầu hết các tài nguyên.
Nửa dưới có một biểu đồ với số lượng tệp (tần suất) cho kích thước tệp sử dụng 5 danh mục cho các kích thước tệp khác nhau. Điều này có thể được sử dụng để có ý tưởng về kích thước tệp được sử dụng trên hệ thống tệp, được phối hợp với các loại tệp có thể được sử dụng để quyết định xem việc nén có mang lại lợi ích hay không.
Hình 9: PixStor Analytics – Chế độ xem đếm tệp
Kết luận và công việc tương lai
Giải pháp hiện tại có thể mang lại hiệu suất khá tốt, được kỳ vọng là ổn định bất kể không gian sử dụng (vì hệ thống được định dạng ở chế độ phân tán), như có thể thấy trong Bảng 4 . Hơn nữa, giải pháp mở rộng tuyến tính về dung lượng và hiệu suất khi thêm nhiều mô-đun nút lưu trữ và có thể mong đợi mức tăng hiệu suất tương tự từ mô-đun siêu dữ liệu có nhu cầu cao tùy chọn. Giải pháp này cung cấp cho khách hàng HPC một hệ thống tệp song song rất đáng tin cậy được sử dụng bởi nhiều cụm 500 HPC hàng đầu. Ngoài ra, nó cung cấp khả năng tìm kiếm đặc biệt, giám sát và quản lý nâng cao, đồng thời bổ sung các cổng tùy chọn cho phép chia sẻ tệp qua các giao thức tiêu chuẩn phổ biến như NFS, SMB và các giao thức khác tới nhiều máy khách nếu cần.
Bảng 4 Hiệu suất cao nhất và duy trì
Hiệu suất cao điểm Hiệu suất bền vững Viết Đọc Viết Đọc Máy khách N tuần tự lớn đến N tệp 16,7 GB/giây 23GB/giây 16,5 GB/giây 20,5 GB/giây Máy khách N tuần tự lớn cho một tệp được chia sẻ 16,5 GB/giây 23,8 GB/giây 16,2 GB/giây 20,5 GB/giây Khối nhỏ ngẫu nhiên N máy khách thành N tệp 15,8KIOps 20,4KIOps 15,7KIOps 20,4KIOps Siêu dữ liệu Tạo tệp trống 169,4K IOps 127,2K IOps Siêu dữ liệu Thống kê các tệp trống 11,2M IOps 3,3M IOps Siêu dữ liệu Đọc các tệp trống 4,8M IOps 2,4M IOp Siêu dữ liệu Xóa các tệp trống 194,2K IOps 144,8K IOps Siêu dữ liệu Tạo tệp 4KiB 55,4K IOps 55,4K IOps Tệp siêu dữ liệu Stat 4KiB 6,4M IOps 4M IOp Siêu dữ liệu Đọc tệp 4KiB 37,3K IOps 37,3K IOps Siêu dữ liệu Xóa các tệp 4KiB 1M IOp 219,5K IOps Vì giải pháp dự kiến sẽ được phát hành với CPU Cascade Lake và RAM nhanh hơn nên sau khi hệ thống có cấu hình cuối cùng, một số kiểm tra điểm hiệu suất sẽ được thực hiện. Và kiểm tra Mô-đun siêu dữ liệu nhu cầu cao tùy chọn với ít nhất 2 tệp ME4024 và tệp 4KiB là cần thiết để ghi lại chính xác hơn cách hiệu suất siêu dữ liệu thay đổi khi có liên quan đến các mục tiêu dữ liệu. Ngoài ra, hiệu suất của các nút cổng sẽ được đo lường và báo cáo cùng với bất kỳ kết quả liên quan nào từ việc kiểm tra tại chỗ trong blog mới hoặc sách trắng. Cuối cùng, nhiều thành phần giải pháp hơn đã được lên kế hoạch thử nghiệm và phát hành để cung cấp nhiều khả năng hơn nữa.
Bài viết mới cập nhật
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...
Cơ sở hạ tầng CNTT: Mua hay đăng ký?
Nghiên cứu theo số liệu của IDC về giải pháp đăng ...