
Tin tức
GPU NVIDIA H100 SXM của Dell Technologies được gửi tới MLPerf™ Inference 3.0
Dell Technologies gần đây đã gửi kết quả tới MLPerf Inference v3.0 ở bộ phận đóng. Blog này nêu bật nội dung gửi phân chia khép kín của Dell Technologies được thực hiện bằng GPU NVIDIA H100 Tensor Core sử dụng hệ thống HGX dựa trên SXM.
Giới thiệu
Việc gửi MLPerf Inference v3.0 nằm trong trụ cột đo điểm chuẩn của tập đoàn MLCommons TM với mục tiêu đưa ra những so sánh công bằng giữa các cấu hình máy chủ. Các đệ trình được gửi tới bộ phận khép kín đảm bảo sự so sánh công bằng của các hệ thống.
Blog này nêu bật các đề xuất phân chia khép kín mà Dell Technologies đã thực hiện với GPU NVIDIA H100 sử dụng hệ thống HGX 100. Hệ thống HGX sử dụng giải pháp ổ cắm băng thông cao được thiết kế để hoạt động song song với công nghệ kết nối NVIDIA NVSwitch .
Ngoài NVIDIA, Dell Technologies là công ty duy nhất công bố kết quả về card GPU NVIDIA H100 SXM. Kết quả GPU NVIDIA H100 tỏa sáng trong vòng Suy luận MLPerf này. GPU này có hiệu suất tăng từ 300% đến 800% so với GPU NVIDIA A100 Tensor Core. Nó đạt được kết quả cao nhất khi xem xét hiệu suất trên mỗi hệ thống và hiệu suất trên mỗi GPU.
Bài gửi được thực hiện bằng GPU NVIDIA H100
Trong vòng này, Dell Technologies đã sử dụng máy chủ Dell PowerEdge XE9680 và Dell PowerEdge XE8545 để gửi bài cho thẻ NVIDIA H100 SXM. Vì máy chủ PowerEdge XE9680 là máy chủ GPU tám chiều nên nó cho phép khách hàng trải nghiệm khả năng tăng tốc vượt trội cho trí tuệ nhân tạo (AI), học máy (ML) và đào tạo và suy luận học sâu (DL).
| Nền tảng | PowerEdge XE9680 (8x H100-SXM-80GB, TensorRT) | PowerEdge XE8545 (4x A100-SXM-80GB, TensorRT) | PowerEdge XE9680 (8x A100-SXM-80GB, TensorRT) |
| ID hệ thống MLPerf | XE9680_H100_SXM_80GBx8_TRT | XE8545_A100_SXM4_80GBx4_TRT | XE9680_A100_SXM4_80GBx8_TRT |
| Hệ điều hành | Ubuntu 22.04 | ||
| CPU | Intel Xeon Bạch Kim 8470 | AMD EPYC 7763 | Intel Xeon Bạch Kim 8470 |
| Ký ức | 2 TB | 4 TB | |
| GPU | NVIDIA H100-SXM-80GB | NVIDIA A100-SXM-80GB CTS | NVIDIA A100-SXM-80GB CTS |
| Yếu tố hình thức GPU | SXM | ||
| Cấu hình bộ nhớ GPU | HBM3 | HBM2e | |
| số lượng GPU | số 8 | 4 | số 8 |
| ngăn xếp phần mềm | TenorRT 8.6.0
CUDA 12.0 cuDNN 8.8.0 Trình điều khiển 525.85.12 ĐẠI LÝ 1.17.0 |
||
Bảng 1: Phần mềm gửi đi được thực hiện trên GPU NVIDIA H100 và NVIDIA A100 SXM trong MLPerf Inference v3.0
Máy chủ giá PowerEdge XE9680
Với máy chủ PowerEdge XE9680, khách hàng có thể đảm nhận khối lượng công việc đòi hỏi trí tuệ nhân tạo, học máy và học sâu, bao gồm cả AI tổng hợp. Máy chủ ứng dụng hiệu suất cao này cho phép phát triển, đào tạo và triển khai nhanh chóng các mô hình học máy lớn. Máy chủ PowerEdge XE9680 được thiết kế cho trí tuệ nhân tạo, học máy, học sâu và các khối lượng công việc đòi hỏi khắt khe khác. Máy chủ PowerEdge XE9680 được trang bị nhiều tính năng dành cho mọi khối lượng công việc trí tuệ nhân tạo, máy học và học sâu vì nó hỗ trợ 8 GPU NVIDIA HGX H100 80GB 700W SXM5 hoặc 8 GPU NVIDIA HGX A100 80GB 500W SXM4, được kết nối hoàn toàn với công nghệ NVIDIA NVLink. Để biết thêm chi tiết, hãy xem bảng thông số kỹ thuật cho máy chủ PowerEdge XE9680.

Hình 2: Mặt trước của Máy chủ Rack PowerEdge XE9680

Hình 3: Mặt trước của Máy chủ Rack PowerEdge XE9680

Hình 4: Mặt sau của Máy chủ Rack PowerEdge XE9680

Hình 5: Mặt sau của Máy chủ Rack PowerEdge XE9680

Hình 6: Mặt trên của Máy chủ Rack PowerEdge XE9680
So sánh GPU NVIDIA H100 SXM với GPU NVIDIA A100 SXM
Nhìn vào kết quả tốt nhất của toàn bộ hệ thống cho vòng gửi này (v3.0) và vòng gửi trước đó (v2.1), mức tăng hiệu suất mà máy chủ PowerEdge XE9680 đạt được với tám GPU NVIDIA H100 là rất nổi bật. Để so sánh, máy chủ GPU NVIDIA H100 hoạt động tốt hơn người tiền nhiệm của nó, máy chủ GPU NVIDIA A100, với chênh lệch lớn trong tất cả khối lượng công việc được thử nghiệm, như minh họa trong hình sau. Lưu ý rằng kết quả tốt nhất trong vòng gửi trước được tạo ra bởi máy chủ PowerEdge XE8545 với bốn GPU NVIDIA A100.
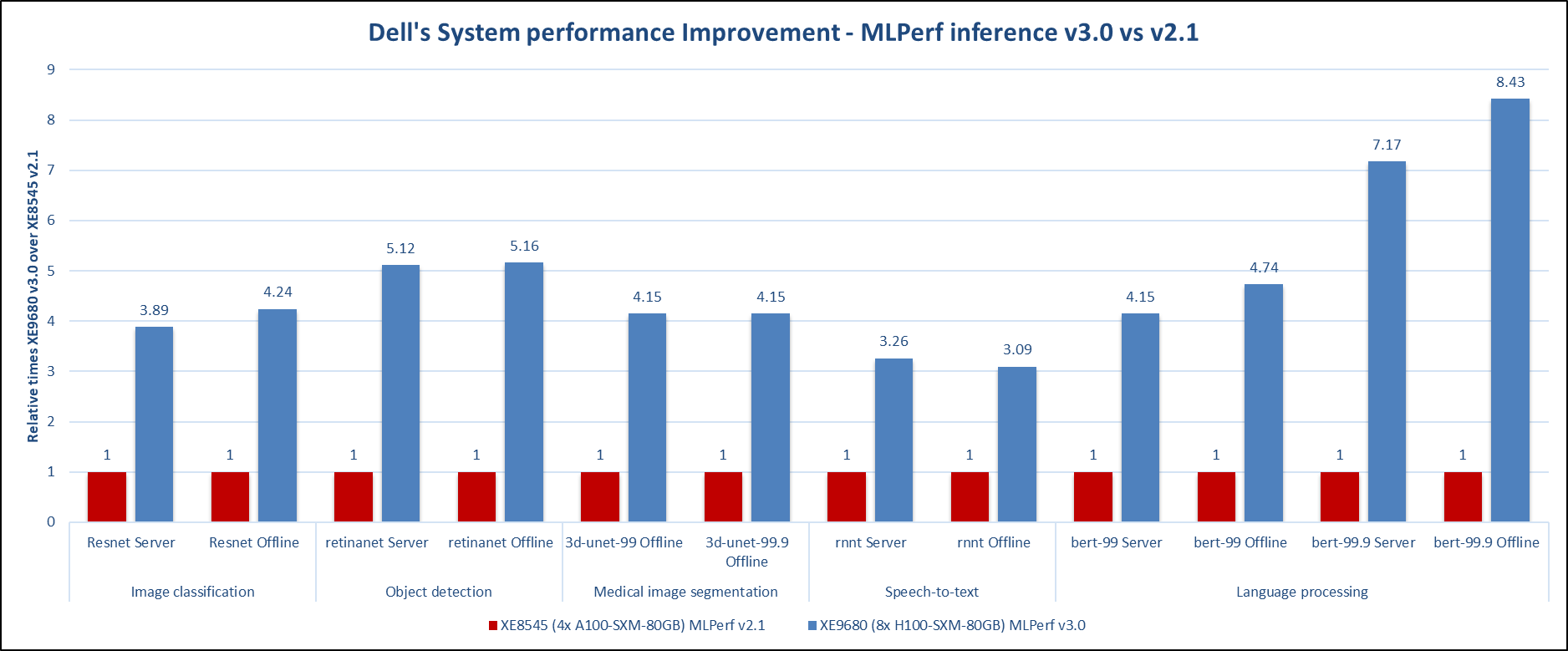
*ID MLPerf 2.1-004 và ID MLPerf 3.0.-0013
Hình 7: Cải thiện hiệu suất hệ thống của Dell – MLPerf Inference v3.0 so với MLPerf Inference v2.1
Trong miền Thị giác Máy tính để phân loại hình ảnh và phát hiện đối tượng, lượt gửi cho vòng này cho thấy sự cải thiện hiệu suất gấp bốn và năm lần tương ứng trong hai vòng gửi. Đối với nhiệm vụ phân đoạn hình ảnh y tế, điểm chuẩn 3D-Unet, máy chủ PowerEdge XE9680 với GPU NVIDIA H100 đã tạo ra hiệu suất tăng gấp bốn lần. Đối với điểm chuẩn RNNT, nằm trong miền chuyển giọng nói thành văn bản, bản gửi PowerEdge XE9680 cho v3.0 cho thấy sự cải thiện hiệu suất gấp ba lần khi so sánh với bản gửi PowerEdge XE8545 cho v2.1. Trong tiêu chuẩn xử lý ngôn ngữ tự nhiên, BERT, chúng tôi đã quan sát thấy mức tăng ấn tượng ở cả chế độ mặc định và chế độ có độ chính xác cao. Đối với chế độ mặc định, có thể thấy hiệu suất tăng gấp bốn lần và có thể yêu cầu tăng hiệu suất gấp tám lần đối với chế độ có độ chính xác cao. Với sự gia tăng mức độ phổ biến gần đây của Mô hình ngôn ngữ lớn (LLM), những kết quả này tạo nên một bài nộp thú vị.
Phần kết luận
GPU NVIDIA H100 là nhân tố thay đổi cuộc chơi với hiệu suất tăng đáng kể khi so sánh với GPU NVIDIA A100. Máy chủ PowerEdge XE9680 hoạt động cực kỳ tốt trong vòng này trong tất cả các tác vụ học máy, từ phân loại hình ảnh, phát hiện đối tượng, phân đoạn hình ảnh y tế, lời nói đến văn bản và xử lý ngôn ngữ. Ngoài NVIDIA, Dell Technologies là người gửi MLPerf duy nhất cho kết quả GPU NVIDIA H100 SXM. Với các bài nộp chất lượng cao do Dell Technologies thực hiện cho vòng này với máy chủ PowerEdge XE9680, tương lai của không gian học sâu rất thú vị, đặc biệt là khi chúng tôi nhận thấy tác động mà máy chủ này với GPU NVIDIA H100 có thể gây ra đối với khối lượng công việc AI tổng quát.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...