
Tin tức
Hiệu năng ứng dụng HPC trên Dell PowerEdge R6625 với AMD EPYC-GENOA
Bộ xử lý AMD EPYC 9354 khi được tích hợp vào máy chủ Dell R6625 sẽ mang đến một giải pháp đáng gờm cho các ứng dụng điện toán hiệu năng cao (HPC). Genoa, được xây dựng trên kiến trúc Zen 4, mang lại sức mạnh và hiệu quả xử lý vượt trội, khiến nó trở thành lựa chọn hấp dẫn cho khối lượng công việc HPC đòi hỏi khắt khe. Khi kết hợp với cơ sở hạ tầng mạnh mẽ và các tính năng mở rộng của PowerEdge R6625, CPU này sẽ nâng cao hiệu suất máy chủ, cho phép thực thi các ứng dụng HPC hiệu quả và đáng tin cậy. Những tính năng này làm cho nó trở thành một lựa chọn lý tưởng cho các nghiên cứu và nghiên cứu ứng dụng HPC.
Tại Dell Technologies, mục tiêu của chúng tôi là giúp đẩy nhanh thời gian tạo ra giá trị cho khách hàng. Dell muốn giúp khách hàng tận dụng các nghiên cứu mở rộng và hiệu suất chuẩn của chúng tôi để giúp lập kế hoạch cho môi trường của họ. Bằng cách sử dụng kiến thức chuyên môn của chúng tôi, khách hàng không cần phải mất thời gian thử nghiệm các cách kết hợp CPU, bộ nhớ và kết nối khác nhau hoặc chọn CPU có điểm phù hợp nhất về hiệu năng. Điều này cũng giúp tiết kiệm thời gian vì khách hàng không phải mất thời gian quyết định nên tinh chỉnh những tính năng BIOS nào để có hiệu suất và khả năng mở rộng tốt nhất. Dell muốn đẩy nhanh quá trình thiết lập, triển khai và điều chỉnh cụm HPC để cho phép khách hàng nhận được giá trị thực khi chạy ứng dụng của họ và giải quyết các vấn đề phức tạp như sản xuất sản phẩm tốt hơn cho khách hàng.
Cấu hình thử nghiệm
Việc đo điểm chuẩn cho các ứng dụng điện toán hiệu năng cao được thực hiện bằng cách sử dụng máy chủ Dell PowerEdge 16G được trang bị Bộ xử lý 32 nhân AMD EPYC 9354.
Bảng 1. Cấu hình hệ thống giường thử nghiệm được sử dụng cho nghiên cứu tiêu chuẩn này
| Nền tảng | Dell PowerEdge R6625 |
| Bộ xử lý | Bộ xử lý 32 nhân AMD EPYC 9354 |
| Lõi/ổ cắm | 32 (tổng cộng 64) |
| Tần số cơ sở | 3,25 GHz |
| Tần số Turbo tối đa | 3,75 GHz |
| TDP | 280 W |
| Bộ đệm L3 | 256 MB |
| Ký ức | 768GB | DDR5 4800 tấn/giây |
| Kết nối | NVIDIA Mellanox ConnectX-7 NDR 200 |
| Hệ điều hành | RHEL 8.6 |
| Nền tảng Linux | 4.18.0-372.32.1 |
| BIOS | 1.0.1 |
| OFED | 5.6.2.0.9 |
| Hồ sơ hệ thống | Tối ưu hóa hiệu suất |
| Trình biên dịch | AOCC 4.0.0 |
| MPI | OpenMPI 4.1.4 |
| Tăng tốc Turbo | TRÊN |
| Kết nối | Mellanox NDR 200 |
| Ứng dụng | Tên miền dọc | Bộ dữ liệu điểm chuẩn |
| OpenFOAM | Sản xuất – Động lực học chất lỏng tính toán (CFD) | Xe máy 50M 34M và lưới ô 20M |
| Nghiên cứu và dự báo thời tiết (WRF) | Thời tiết và Môi trường | Conus 2.5KM
|
| Bộ mô phỏng song song lớn nguyên tử/phân tử quy mô lớn (LAMMPS) | Động lực học phân tử | Rhodo, EAM, Stilliger Weber, tersoff, HECBIOSIM và Airebo |
| GROMACS | Khoa học đời sống – Động lực phân tử | Điểm chuẩn HECBioSim – Nguyên tử 3M , Nước và Prace LignoCellulose |
| CP2K | Khoa học đời sống | H2O-DFT-LS-NREP- 4,6 H2O-64-RI-MP 2 |
Khả năng mở rộng hiệu suất cho miền ứng dụng HPC
Dọc – Sản xuất | Ứng dụng – OPENFOAM
OpenFOAM là gói phần mềm tính toán động lực học chất lỏng (CFD) mã nguồn mở nổi tiếng vì tính linh hoạt trong việc mô phỏng dòng chất lỏng, nhiễu loạn và truyền nhiệt. Nó cung cấp một khuôn khổ vững chắc cho các kỹ sư và nhà khoa học để mô hình hóa các vấn đề động lực học chất lỏng phức tạp và tiến hành mô phỏng với các tính năng có thể tùy chỉnh. Trong nghiên cứu này, chúng tôi làm việc trên OpenFOAM phiên bản 9, được biên dịch bằng gcc 11.2.0 và OPENMPI 4.1.5. Để biên dịch và tối ưu hóa thành công trên bộ xử lý AMD EPYC, các cờ bổ sung như ‘ -O3 -znver4’ đã được thêm vào.
Trường hợp hướng dẫn trong danh mục bộ giải SimpleFoam, motorBike, đã được sử dụng để đánh giá hiệu suất của gói OpenFOAM trên bộ xử lý AMD EPYC 9354. Ba loại lưới khác nhau đã được tạo như 20M, 34M và 50M ô bằng cách sử dụng các tiện ích blockMesh và snappyHexMesh của OpenFOAM. Mỗi lần chạy được tiến hành với toàn bộ lõi (64 lõi trên mỗi nút) và từ nút đơn đến 16 nút. Các thử nghiệm về khả năng mở rộng đã được thực hiện cho cả ba bộ lưới. Thời gian thực hiện bộ giải SimpleFoam ở trạng thái ổn định được ghi lại dưới dạng số hiệu suất. Hình dưới đây cho thấy hiệu suất ứng dụng cho tất cả các bộ dữ liệu.
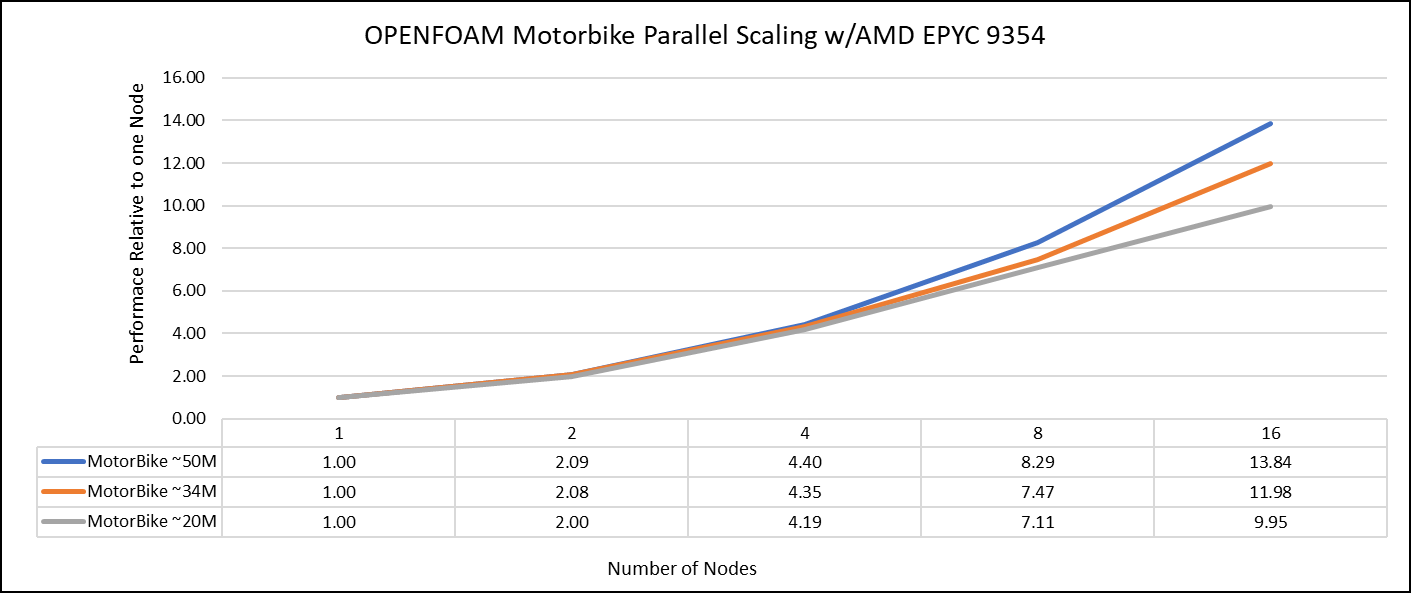
Hình 1: Hiệu suất mở rộng của bộ dữ liệu OpenFOAM Motorbike sử dụng Bộ xử lý AMD EPYC, tập trung vào hiệu suất so với một nút duy nhất.
Các kết quả không được thứ nguyên với kết quả nút đơn. Khả năng mở rộng được mô tả trong Hình 1. Ứng dụng OpenFOAM hiển thị tỷ lệ tuyến tính từ một nút đến tám nút trên bộ xử lý 9354 cho tập dữ liệu cao hơn (50M). Đối với các tập dữ liệu nhỏ hơn khác có ô 20M và 34M, tỷ lệ tuyến tính được hiển thị tối đa bốn nút và tỷ lệ giảm một chút trên tám nút. Đối với tất cả các bộ dữ liệu (20M, 34M và 50M) trên 16 nút, khả năng mở rộng đã giảm.
Việc đạt được kết quả khả quan với các tập dữ liệu nhỏ hơn có thể được thực hiện bằng cách sử dụng ít bộ xử lý và nút hơn vì các tập dữ liệu nhỏ hơn không yêu cầu số lượng bộ xử lý cao hơn. Tuy nhiên, việc tăng số lượng nút và do đó, số lượng bộ xử lý, liên quan đến thời gian tính toán của bộ giải sẽ dẫn đến tăng khả năng giao tiếp giữa các bộ xử lý, sau đó kéo dài thời gian chạy tổng thể. Do đó, số lượng nút cao hơn sẽ có lợi hơn khi xử lý các tập dữ liệu lớn hơn trong mô phỏng OpenFOAM.
Dọc – Thời tiết và Môi trường | Ứng dụng – WRF
Mô hình Dự báo và Nghiên cứu Thời tiết (WRF) luôn đi đầu trong nghiên cứu khí tượng và khí quyển, với phiên bản mới nhất là minh chứng cho những tiến bộ trong điện toán hiệu năng cao (HPC). WRF cho phép các nhà khoa học và nhà khí tượng học mô phỏng và dự báo các kiểu thời tiết phức tạp với độ chính xác tuyệt vời. Trong nghiên cứu này, chúng tôi đã làm việc trên phiên bản WRF 4.5, được biên dịch bằng AOCC 4.0.0 với OPENMPI 4.1.4. Để biên dịch và tối ưu hóa thành công với trình biên dịch AMD EPYC, các cờ bổ sung như ‘ -O3 -znver4’ đã được thêm vào.
Bộ dữ liệu được sử dụng trong nghiên cứu của chúng tôi là CONUS v4.4. Điều này có nghĩa là lưới, thông số và dữ liệu đầu vào của mô hình được thiết lập để tập trung vào điều kiện thời tiết ở lục địa Hoa Kỳ. Cấu hình này đặc biệt hữu ích cho các nhà nghiên cứu, nhà khí tượng học và cơ quan chính phủ, những người cần dự báo và mô phỏng thời tiết có độ phân giải cao phù hợp với khu vực địa lý cụ thể này. Các chi tiết cấu hình, chẳng hạn như độ phân giải lưới, sơ đồ vật lý khí quyển và nguồn dữ liệu đầu vào, có thể khác nhau tùy thuộc vào phiên bản WRF cụ thể và mục tiêu của dự án mô hình hóa. Trong nghiên cứu này, chúng tôi chủ yếu tuân thủ cấu hình đầu vào mặc định, thực hiện các thay đổi hoặc điều chỉnh tối thiểu đối với mã nguồn hoặc tệp đầu vào. Mỗi lần chạy được thực hiện với toàn bộ lõi (64 lõi trên mỗi nút) và từ một nút đến 16 nút. Các thử nghiệm về khả năng mở rộng đã được tiến hành và chỉ số hiệu suất tính bằng “giây” đã được ghi lại.
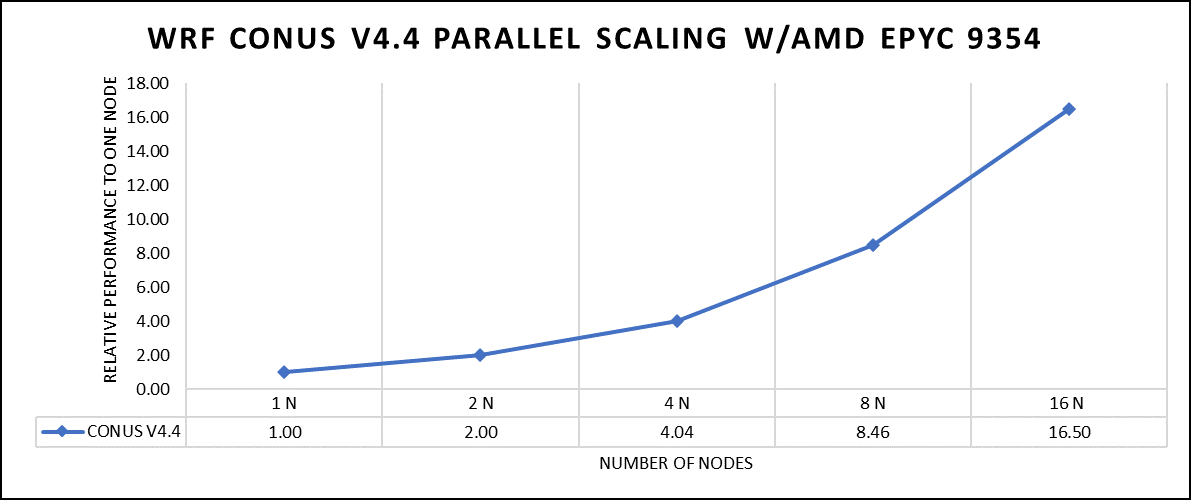
Hình 2: Hiệu suất mở rộng của tập dữ liệu WRF CONUS sử dụng bộ xử lý AMD EPYC 9354, tập trung vào hiệu suất so với một nút duy nhất.
Các tệp nhị phân được biên dịch AOCC của WRF hiển thị tỷ lệ tuyến tính từ một nút duy nhất đến mười sáu nút trên bộ xử lý 9354 cho CONUS v4.4 mới. Để có hiệu suất tốt nhất với WRF, cần xem xét cẩn thận tác động của kích thước khối ảnh, quy trình và luồng trên mỗi quy trình. Do ứng dụng bị hạn chế bởi bộ nhớ và băng thông DRAM nên chúng tôi đã chọn DRAM DDR5 4800 MT/s mới nhất để đánh giá thử nghiệm của mình. Điều quan trọng nữa là phải xem xét cài đặt BIOS, đặc biệt là cấu hình SubNUMA, vì những cài đặt này có thể ảnh hưởng đáng kể đến hiệu suất của các ứng dụng sử dụng bộ nhớ, có khả năng dẫn đến cải thiện từ một đến năm phần trăm. Để biết các đề xuất điều chỉnh BIOS chi tiết hơn, vui lòng xem bài đăng blog trước đây của chúng tôi về tối ưu hóa cài đặt BIOS để có hiệu suất tối ưu.
Dọc – Động lực học phân tử | Ứng dụng – LAMMPS
Bộ mô phỏng song song nguyên tử/phân tử quy mô lớn (LAMMPS) là một công cụ mạnh mẽ dành cho HPC. Nó được thiết kế đặc biệt để khai thác khả năng tính toán to lớn của cụm HPC và siêu máy tính. LAMMPS cho phép các nhà nghiên cứu và nhà khoa học tiến hành mô phỏng động lực phân tử quy mô lớn với hiệu quả và khả năng mở rộng vượt trội. Trong nghiên cứu này, chúng tôi đã làm việc trên LAMMPS, phiên bản ngày 15 tháng 6 năm 2023, được biên soạn bằng AOCC 4.0.0 và OPENMPI 4.1.4. Để biên dịch và tối ưu hóa thành công với trình biên dịch AMD EPYC, các cờ bổ sung như ‘ -O3 -znver4’ đã được thêm vào.
Chúng tôi đã chọn gói không mặc định, gói này cung cấp các kiểu cặp nguyên tử được tối ưu hóa. Chúng tôi cũng đã thử chạy một số điểm chuẩn không được hỗ trợ với gói mặc định để kiểm tra hiệu suất và tỷ lệ. Chỉ số hiệu suất của chúng tôi cho điểm chuẩn này là nano giây mỗi ngày, trong đó nano giây mỗi ngày cao hơn được coi là kết quả tốt hơn .
Có hai yếu tố được xem xét khi tổng hợp dữ liệu để so sánh, đó là số lượng nút và số lượng lõi. Hình 3 cho thấy kết quả cải thiện hiệu suất quan sát được trên bộ xử lý 9354 với 64 lõi.
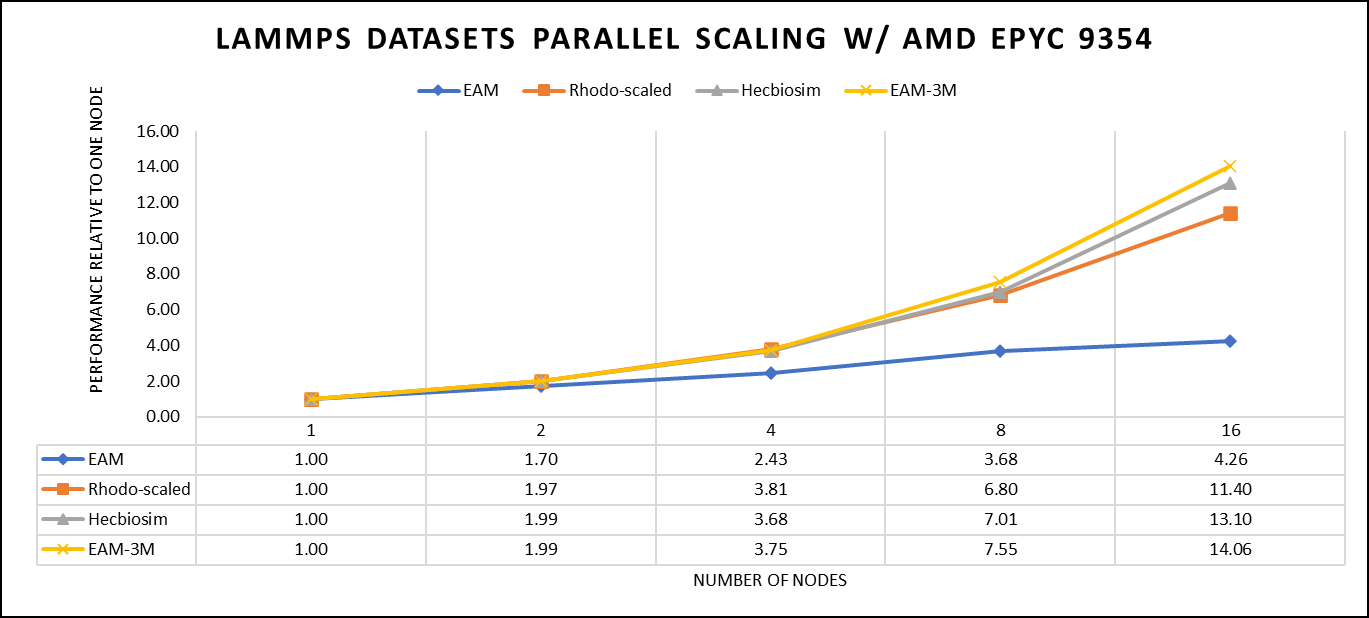
Hình 3: Hiệu suất mở rộng của bộ dữ liệu LAMMPS sử dụng bộ xử lý AMD EPYC 9354, tập trung vào hiệu suất so với một nút duy nhất.
Hình 3 cho thấy tỷ lệ của các bộ dữ liệu LAMMPS khác nhau. Chúng tôi nhận thấy sự cải thiện đáng kể về tỷ lệ khi chúng tôi tăng kích thước nguyên tử và kích thước bước. Chúng tôi đã thử nghiệm hai bộ dữ liệu EAM và Hecbiosim với hơn 3 triệu nguyên tử và nhận thấy khả năng mở rộng tốt hơn so với các bộ dữ liệu khác.
Dọc – Động lực học phân tử | Ứng dụng – GROMACS
GROMACS, phần mềm động lực phân tử hiệu suất cao, là một công cụ quan trọng cho môi trường HPC. Được thiết kế riêng cho các cụm HPC và siêu máy tính, GROMACS chuyên mô phỏng các chuyển động và tương tác phức tạp của các nguyên tử và phân tử. Các nhà nghiên cứu trong các lĩnh vực khác nhau, bao gồm hóa sinh và lý sinh, dựa vào tính hiệu quả và khả năng mở rộng của nó để khám phá các quá trình phân tử phức tạp. GROMACS được sử dụng nhờ khả năng khai thác sức mạnh tính toán to lớn của HPC, cho phép các nhà khoa học tiến hành các mô phỏng phức tạp nhằm tiết lộ những hiểu biết quan trọng về hành vi ở cấp độ nguyên tử, từ phân tử sinh học đến phản ứng hóa học và vật liệu. Trong nghiên cứu này, chúng tôi đã nghiên cứu phiên bản GROMACS 2023.1 được biên dịch bằng AOCC 4.0.0 và OPENMPI 4.1.4. Để biên dịch và tối ưu hóa thành công với trình biên dịch AMD EPYC, các cờ bổ sung như ‘ -O3 -znver4’ đã được thêm vào.
Chúng tôi đã tuyển chọn nhiều bộ dữ liệu để đánh giá điểm chuẩn của mình. Đầu tiên, chúng tôi đưa vào “nước GMX_50 1536” và “nước GMX_50 3072”, thể hiện các mô phỏng liên quan đến phân tử nước. Những mô phỏng này có vai trò then chốt để hiểu rõ hơn về quá trình hòa tan, khuếch tán và hoạt động của nước trong các điều kiện khác nhau. Tiếp theo, chúng tôi kết hợp các bộ dữ liệu “HECBIOSIM 14K” và “HECBIOSIM 30K”, được chọn đặc biệt vì khả năng điều tra các hệ thống phức tạp và cấu trúc phân tử sinh học lớn hơn. Cuối cùng, chúng tôi đã đưa vào bộ dữ liệu “PRACE Lignocellulose”, phù hợp với mục tiêu đo điểm chuẩn của chúng tôi, đặc biệt là trong bối cảnh nghiên cứu về lignocellulose. Các bộ dữ liệu này cùng nhau cung cấp một loạt các kịch bản đa dạng cho các đánh giá điểm chuẩn của chúng tôi.
Đánh giá hiệu suất của chúng tôi dựa trên phép đo nano giây mỗi ngày (ns/ngày) cho mỗi tập dữ liệu, cung cấp những hiểu biết sâu sắc có giá trị về hiệu quả tính toán. Ngoài ra, chúng tôi còn chú ý đến việc tối ưu hóa các tham số điều chỉnh mdrun (tức là ntomp, dlb tunepme nsteps, v.v.) trong mỗi lần chạy thử để đảm bảo kết quả chính xác và đáng tin cậy. Chúng tôi đã kiểm tra khả năng mở rộng bằng cách tiến hành các thử nghiệm trải dài từ một nút duy nhất đến tổng số 16 nút.
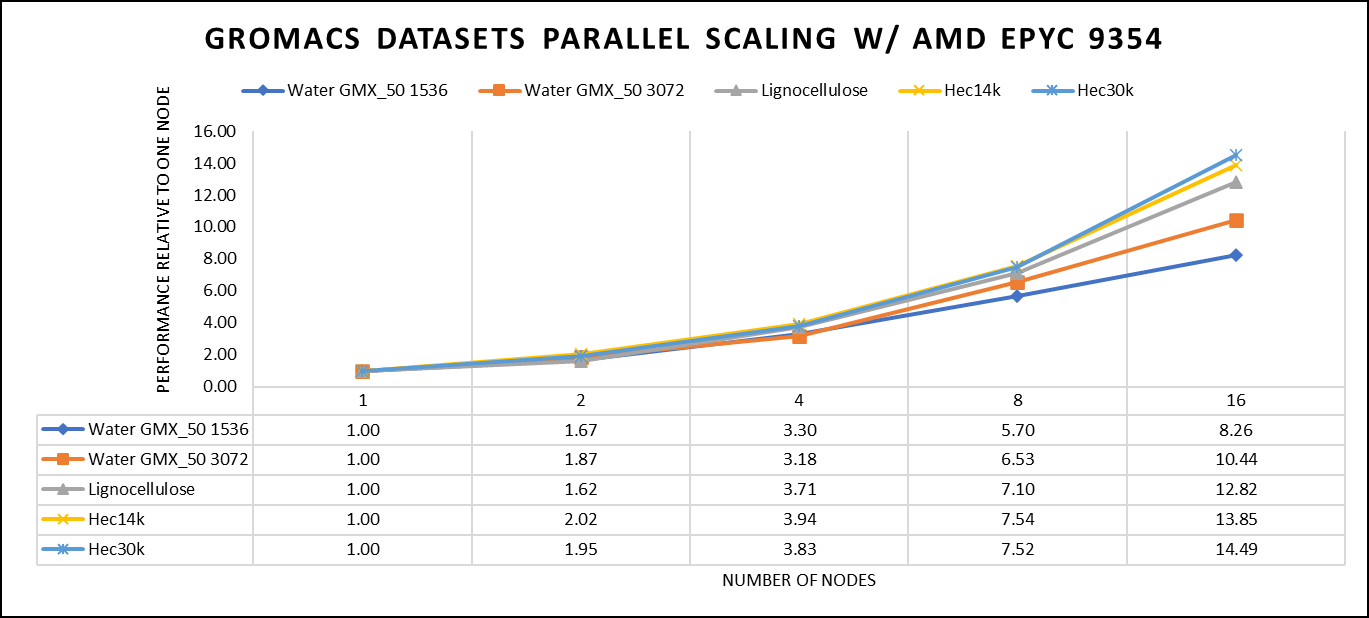
Hình 4: Hiệu suất mở rộng của bộ dữ liệu GROMACS sử dụng bộ xử lý AMD EPYC 9354, tập trung vào hiệu suất so với một nút duy nhất.
Để dễ so sánh giữa các bộ dữ liệu khác nhau, hiệu suất tương đối đã được đưa vào một biểu đồ. Tuy nhiên, điều đáng lưu ý là mỗi tập dữ liệu hoạt động riêng lẻ khi xem xét hiệu suất, vì mỗi tập dữ liệu sử dụng các tệp đầu vào cấu trúc liên kết phân tử (tpr) và các tệp cấu hình khác nhau.
Chúng tôi có thể đạt được khả năng mở rộng hiệu suất mong đợi cho GROMACS lên tới tám nút cho các bộ dữ liệu lớn hơn. Tất cả các lõi trong mỗi máy chủ đều được sử dụng khi chạy các điểm chuẩn này. Hiệu suất tăng gần như tuyến tính trên tất cả các loại tập dữ liệu, tuy nhiên, số lượng nút lớn hơn sẽ giảm do kích thước tập dữ liệu nhỏ hơn và số lần lặp mô phỏng.
Dọc – Động lực học phân tử | Ứng dụng – CP2K
CP2K là gói phần mềm tính toán linh hoạt bao gồm nhiều mô phỏng hóa học lượng tử và vật lý trạng thái rắn, bao gồm cả động lực phân tử. Nó không bị giới hạn nghiêm ngặt ở động lực phân tử mà thay vào đó là một công cụ toàn diện cho các nhiệm vụ khoa học vật liệu và hóa học tính toán khác nhau. Mặc dù CP2K được sử dụng rộng rãi cho các mô phỏng động lực phân tử nhưng nó cũng có thể thực hiện các nhiệm vụ như tính toán cấu trúc điện tử, động lực phân tử ban đầu, mô phỏng cơ học lượng tử/cơ học phân tử lai (QM/MM), v.v. Trong nghiên cứu này, chúng tôi đã làm việc trên phiên bản CP2K 2023.1 được biên dịch bằng AOCC 4.0.0 với OPENMPI 4.1.4. Để biên dịch và tối ưu hóa thành công với trình biên dịch AMD EPYC, các cờ bổ sung như ‘ -O3 -znver4’ đã được thêm vào.
Trong nghiên cứu tập trung vào điện toán hiệu năng cao (HPC), chúng tôi đã sử dụng các bộ dữ liệu cụ thể được tối ưu hóa cho hiệu quả tính toán. Tập dữ liệu đầu tiên, “H2O-DFT-LS-NREP-4.6,” được định cấu hình để mô phỏng và tính toán HPC, nhấn mạnh vào mô hình hóa nước (H2O) bằng Lý thuyết chức năng mật độ (DFT). Cài đặt thông số “NREP-4,6” bổ sung đã được tinh chỉnh để đảm bảo hiệu suất HPC hiệu quả. Tập dữ liệu thứ hai, “H2O-64-RI-MP2,” được tạo riêng cho các ứng dụng HPC và xoay quanh việc kiểm tra một hệ thống bao gồm 64 phân tử nước (H2O). Bằng cách sử dụng phương pháp Độ phân giải nhận dạng (RI) kết hợp với lý thuyết nhiễu loạn Møller–Plesset bậc hai (MP2), bộ dữ liệu này đã chứng minh khả năng tính toán đáng kể của HPC để thực hiện các phép tính cấu trúc điện tử tiên tiến trong môi trường có số lượng phân tử cao. Chúng tôi đã kiểm tra khả năng mở rộng bằng cách tiến hành các thử nghiệm trải dài từ một nút duy nhất đến tổng số 16 nút.
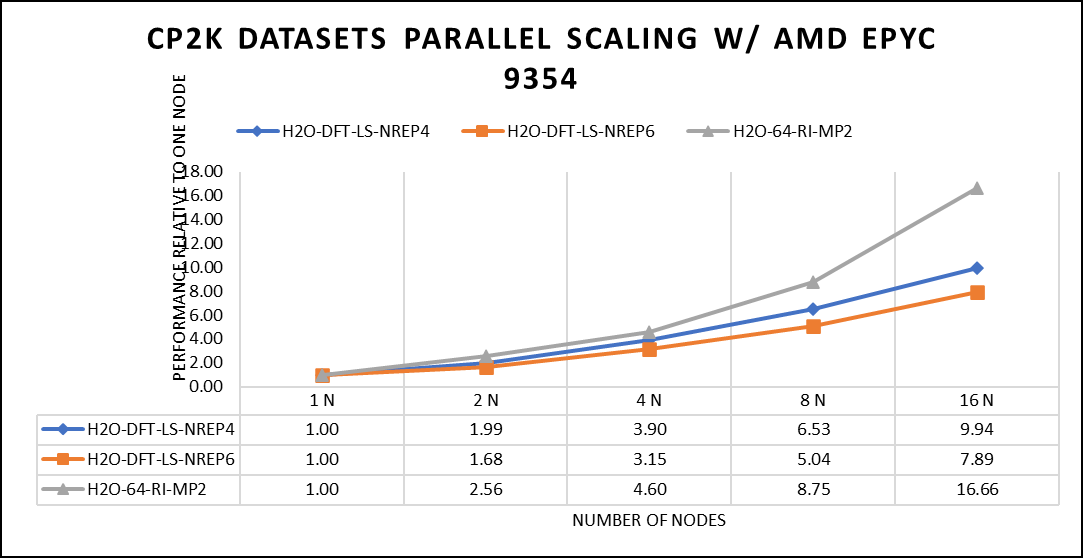
Hình 5: Hiệu suất mở rộng của bộ dữ liệu CP2K sử dụng bộ xử lý AMD EPYC 9354, tập trung vào hiệu suất so với một nút duy nhất.
Các bộ dữ liệu biểu thị phép tính năng lượng một điểm sử dụng Lý thuyết hàm mật độ tỷ lệ tuyến tính (DFT). Hệ thống này bao gồm 6144 nguyên tử được giới hạn trong hộp mô phỏng 39 Å^3, nghĩa là có tổng cộng 2048 phân tử nước. Để điều chỉnh khối lượng công việc tính toán, bạn có thể sửa đổi tham số NREP trong tệp đầu vào.
Nỗ lực đo điểm chuẩn của chúng tôi bao gồm các cấu hình liên quan đến tối đa 16 nút tính toán. Hiệu suất tối ưu đạt được khi sử dụng NREP4 và NREP6 ở chế độ Kết hợp, kết hợp MPI (Giao diện truyền tin nhắn) và OpenMP (Đa xử lý mở). Cấu hình này thể hiện hiệu suất mở rộng tốt nhất, đặc biệt trên 4 đến 8 nút. Tuy nhiên, cần lưu ý rằng việc mở rộng quy mô vượt quá 8 nút không thể hiện sự cải thiện hiệu suất tuyến tính hoàn toàn. Hình 5 ở trên mô tả kết quả khi sử dụng Pure MPI, sử dụng 64 lõi với một luồng đơn trên mỗi lõi.
Phần kết luận
Khi xem xét các CPU có số lượng lõi tương đương, các bộ xử lý AMD EPYC đời trước có thể mang lại mức hiệu năng giống như các bộ xử lý Genoa của chúng. Tuy nhiên, để đạt được hiệu suất tương đương này có thể cần phải tăng gấp đôi số lượng nút. Để nâng cao hơn nữa hiệu suất sử dụng bộ xử lý AMD EPYC, chúng tôi khuyên bạn nên tối ưu hóa cài đặt BIOS như đã nêu trong bài đăng trên blog trước đây của chúng tôi và đặc biệt là tắt tính năng Siêu phân luồng cho các điểm chuẩn được thảo luận trong bài viết này. khối lượng công việc khác nhau, chúng tôi khuyên bạn nên tiến hành thử nghiệm toàn diện và nếu có lợi, hãy bật Siêu phân luồng. Ngoài ra, đối với nghiên cứu hiệu suất này, chúng tôi đánh giá cao việc sử dụng kết nối Mellanox NDR 200 để có kết quả tối ưu.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...