
Tin tức
Hiệu suất của Máy chủ Dell PowerEdge R750xa cho MLPerf™ Inference v2.0
Trừu tượng
Dell Technologies gần đây đã gửi kết quả cho bộ điểm chuẩn MLPerf Inference v2.0. Kết quả cung cấp thông tin về hiệu suất của máy chủ Dell. Blog này xem xét kỹ hơn về máy chủ Dell PowerEdge R750xa và hiệu suất của nó đối với MLPerf Inference v1.1 và v2.0 .
Chúng tôi so sánh kết quả v1.1 với kết quả v2.0. Chúng tôi cho thấy sự khác biệt về hiệu suất giữa các phiên bản ngăn xếp phần mềm. Chúng tôi cũng sử dụng máy chủ PowerEdge R750xa để chứng minh rằng kết quả v1.1 từ tất cả các hệ thống có thể được tham chiếu để lập kế hoạch khối lượng công việc ML trên các hệ thống không có sẵn cho MLPerf Inference v2.0.
Máy chủ PowerEdge R750xa
Được xây dựng với các thành phần hiện đại, máy chủ PowerEdge R750xa lý tưởng cho khối lượng công việc trí tuệ nhân tạo (AI), học máy (ML) và học sâu (DL). Máy chủ PowerEdge R750xa là phiên bản được tối ưu hóa cho GPU của máy chủ PowerEdge R750. Nó hỗ trợ các máy gia tốc là 4 x 300 W DW hoặc 6 x 75 W SW. Các GPU được đặt ở phía trước máy chủ PowerEdge R750xa cho phép quản lý luồng không khí tốt hơn. Nó có tới tám khe cắm PCIe Gen4 khả dụng và hỗ trợ tối đa tám ổ SSD NVMe.
Các số liệu sau đây cho thấy máy chủ PowerEdge R750xa ( nguồn ):

Hình 1: Mặt trước của máy chủ PowerEdge R750xa

Hình 2: Mặt sau của máy chủ PowerEdge R750xa

Hình 3: Mặt trên của máy chủ PowerEdge R750xa
So sánh cấu hình
Bảng sau đây mô tả các cấu hình ngăn xếp phần mềm từ hai vòng đệ trình cho bộ phận trung tâm dữ liệu đã đóng:
Bảng 1: Ngăn xếp phần mềm MLPerf Inference v1.1 và v2.0
| thành phần NVIDIA | ngăn xếp phần mềm v1 .1 | ngăn xếp phần mềm v2 .0 |
| TenorRT | 8.0.2 | 8.4.0 |
| CUDA | 11.3 | 11.6 |
| cuDNN | 8.2.1 | 8.3.2 |
| trình điều khiển GPU | 470.42.01 | 510.39.01 |
| ĐẠI LÝ | 0.30.0 | 0.31.0 |
| triton | 21.07 | 22.01 |
Mặc dù phần mềm đã được cập nhật qua hai vòng gửi, nhưng hiệu suất vẫn nhất quán, nếu không muốn nói là tốt hơn, đối với lần gửi v2.0. Đối với MLPerf Inference v2.0, kết quả hiệu suất của Triton có thể được ngoại suy từ MLPerf Inference v1.1 ngoại trừ điểm chuẩn 3D U-Net, do thay đổi bộ dữ liệu v2.0.
Bảng sau đây mô tả các cấu hình Hệ thống đang thử nghiệm (SUT) từ MLPerf Inference v1.1 và v2.0 của các lần gửi suy luận trung tâm dữ liệu:
Bảng 2: Cấu hình hệ thống MLPerf Inference v1.1 và v2.0 của máy chủ PowerEdge R750xa
| Thành phần | cấu hình hệ thống v1 .1 | cấu hình hệ thống v2 .0 |
| Nền tảng | R750xa 4x A100-PCIE-80GB, TenorRT | TenorRT R750xa 4xA100 |
| ID hệ thống MLPerf | R750xa_A100-PCIE-80GBx4_TRT | R750xa_A100_PCIE_80GBx4_TRT |
| Hệ điều hành | CentOS 8.2 | |
| CPU | CPU Intel Xeon Vàng 6338 @ 2.00 GHz | |
| Kỉ niệm | 1TB | |
| GPU | NVIDIA A100-PCIE-80GB | |
| Yếu tố hình thức GPU | PCIe | |
| số lượng GPU | 4 | |
| ngăn xếp phần mềm | TenorRT 8.0.2 CUDA 11.3 cuDNN 8.2.1 Trình điều khiển 470.42.01 DALI 0.31.0 |
TenorRT 8.4.0
CUDA 11.6 cuDNN 8.3.2 Trình điều khiển 510.39.01 DALI 0.31.0 |
Trong vòng gửi v1.1, Dell Technologies đã gửi bốn cấu hình khác nhau trên máy chủ PowerEdge R750xa. Mặc dù số lượng GPU là bốn vẫn được duy trì, Dell Technologies đã gửi các phiên bản 40 GB và 80 GB của GPU NVIDIA A100. Ngoài ra, Dell Technologies đã gửi số hiệu GPU đa phiên bản (MIG) bằng cách sử dụng 28 phiên bản của một phiên bản điện toán có cấu hình bộ nhớ 10gb trên GPU A100 80 GB. Hơn nữa, Dell Technologies đã gửi số hiệu suất (MaxQ là hiệu suất và hiệu suất) cho phiên bản 40 GB của GPU A100 và được gửi cùng với máy chủ Triton trên phiên bản 80 GB của GPU A100. Bạn có thể tìm thấy thảo luận về bản đệ trình v1.1 của Dell Technologies trong blog này .
So sánh hiệu suất của máy chủ PowerEdge R70xa cho MLPerf Inference v2.0 và v1.1
ResNet 50
ReNet50 là mạng thần kinh tích chập sâu 50 lớp được tạo thành từ 48 lớp tích chập cùng với một nhóm tối đa và lớp nhóm trung bình. Mô hình này được sử dụng cho các ứng dụng thị giác máy tính bao gồm phân loại hình ảnh, phát hiện đối tượng và phân loại đối tượng. Đối với điểm chuẩn ResNet 50, các con số hiệu suất từ lượt gửi v2.0 phù hợp và vượt trội hơn trong các tình huống máy chủ và ngoại tuyến tương ứng khi so sánh với lượt gửi v1.1. Như thể hiện trong hình dưới đây, kết quả gửi v2.0 nằm trong khoảng 0,02 phần trăm trong kịch bản máy chủ và vượt trội so với vòng trước 1 phần trăm trong kịch bản ngoại tuyến:
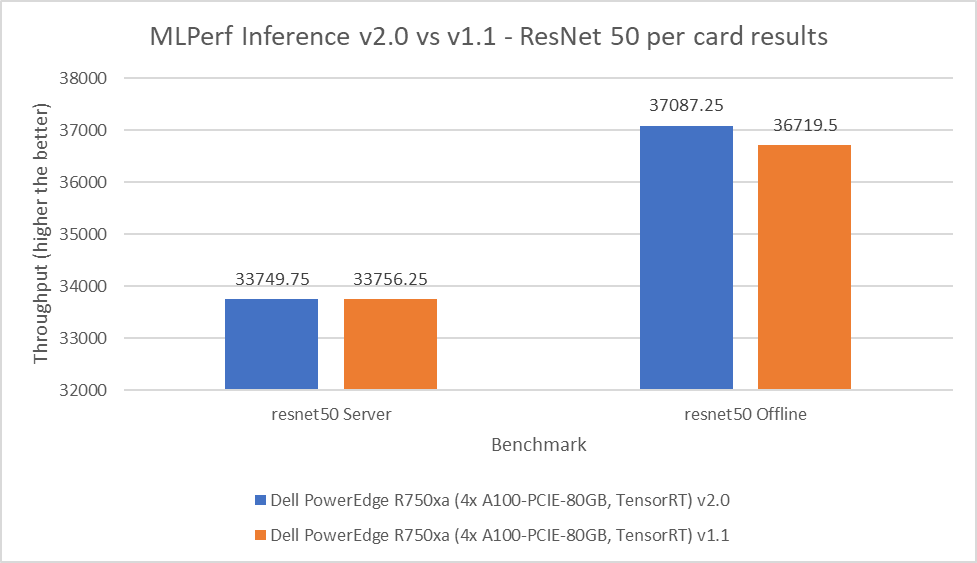
Hình 4: MLPerf Inference v2.0 so với v1.1 Kết quả ResNet 50 trên mỗi thẻ trên máy chủ PowerEdge R750xa
BERT
Biểu diễn bộ mã hóa hai chiều từ Transformers (BERT) là mô hình biểu diễn ngôn ngữ tiên tiến nhất dành cho các ứng dụng Xử lý ngôn ngữ tự nhiên. Điểm chuẩn này thực hiện nhiệm vụ trả lời câu hỏi SQuAD. Điểm chuẩn BERT bao gồm các chế độ mặc định và độ chính xác cao cho các tình huống ngoại tuyến và máy chủ. Trong vòng gửi v2.0, máy chủ PowerEdge R750xa đã khớp và vượt trội hơn một chút so với hiệu suất của nó so với vòng trước. Trong các tình huống ngoại tuyến và máy chủ BERT mặc định, hiệu suất được trích xuất lần lượt nằm trong khoảng 0,06 và 2,33 phần trăm. Trong các tình huống ngoại tuyến và máy chủ BERT có độ chính xác cao, hiệu suất trích xuất nằm trong khoảng 0,14 và 1,25 phần trăm tương ứng.
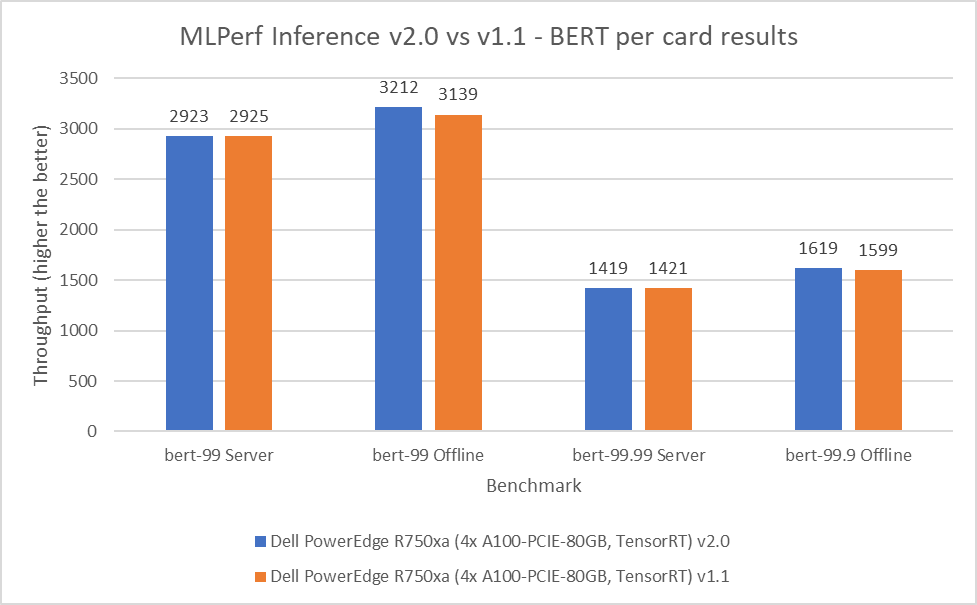
Hình 5: Kết quả MLPerf Inference v2.0 so với v1.1 BERT trên mỗi thẻ trên máy chủ PowerEdge R750xa
SSD-ResNet 34
Mẫu SSD-ResNet 34 thuộc danh mục thị giác máy tính. Điểm chuẩn này thực hiện phát hiện đối tượng. Đối với điểm chuẩn SSD-ResNet 34, kết quả được tạo ra trong vòng gửi v2.0 nằm trong khoảng 0,14 phần trăm cho kịch bản máy chủ và cho thấy sự cải thiện 1 phần trăm trong kịch bản ngoại tuyến.
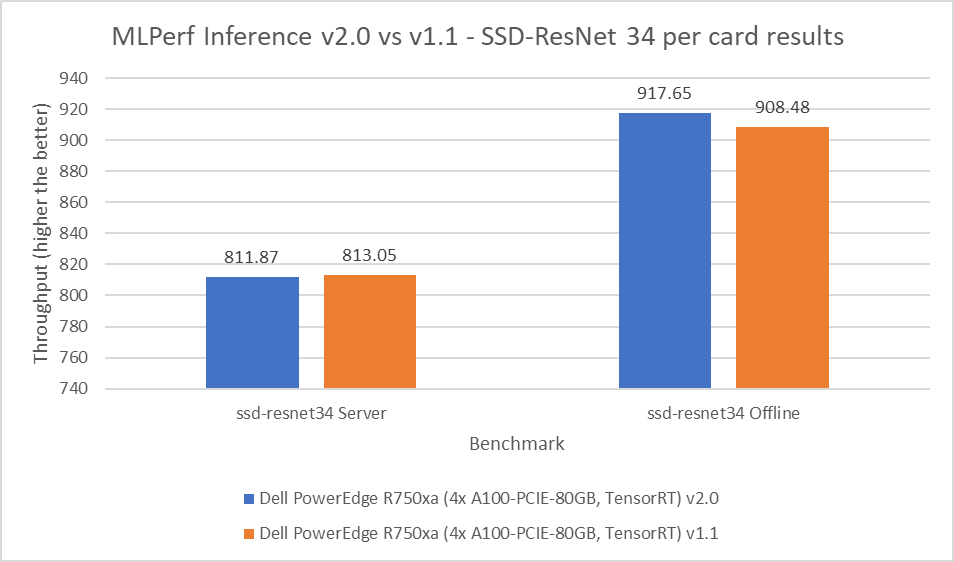
Hình 6: MLPerf Inference v2.0 so với v1.1 SSD-ResNet 34 kết quả trên mỗi thẻ trên máy chủ PowerEdge R750xa
DLRM
Mô hình đề xuất Deep Learning (DLRM) là một điểm chuẩn hiệu quả để hiểu các yêu cầu về khối lượng công việc để xây dựng hệ thống đề xuất. Mô hình này sử dụng các phương pháp tiếp cận dựa trên phân tích dự đoán và lọc cộng tác để xử lý lượng lớn dữ liệu. Điểm chuẩn DLRM bao gồm các chế độ mặc định và độ chính xác cao, cả hai đều chứa máy chủ và các kịch bản ngoại tuyến. Đối với kịch bản máy chủ ở cả chế độ mặc định và độ chính xác cao, kết quả gửi v2.0 nằm trong khoảng 0,003 phần trăm. Đối với kịch bản ngoại tuyến trên cả hai chế độ, máy chủ PowerEdge R750xa cho thấy mức tăng hiệu suất 2,62%.
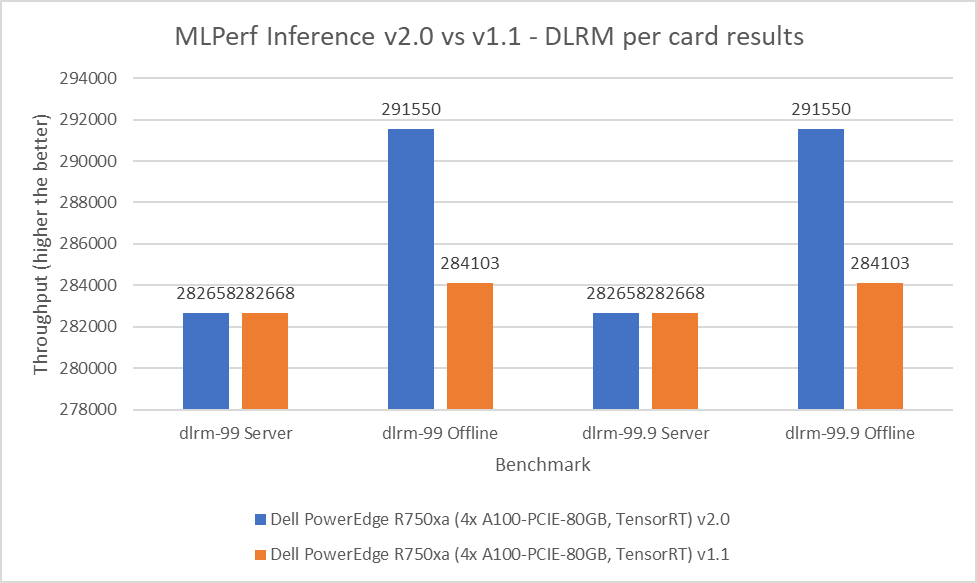
Hình 7: MLPerf Inference v2.0 so với v1.1 DLRM trên mỗi kết quả thẻ trên máy chủ PowerEdge R750xa
RNNT
Mô hình Bộ chuyển đổi mạng thần kinh tái phát (RNNT) thuộc danh mục nhận dạng giọng nói. Điểm chuẩn này chấp nhận các mẫu âm thanh thô và tạo ra bản phiên âm ký tự tương ứng. Đối với điểm chuẩn RNNT, máy chủ PowerEdge R750xa duy trì hành vi hiệu suất tương tự trong phạm vi 0,04 phần trăm ở chế độ máy chủ và cho thấy mức tăng hiệu suất 1,46 phần trăm ở chế độ ngoại tuyến.
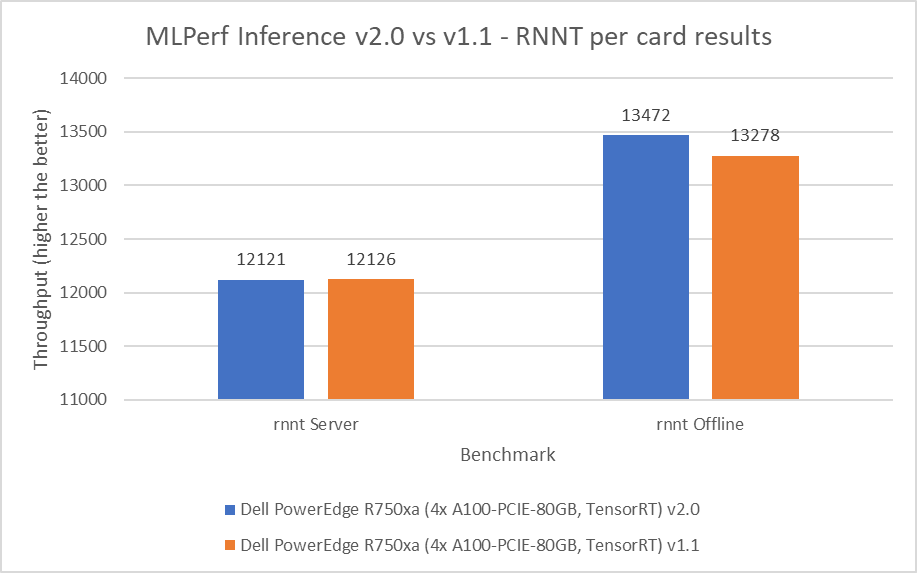
Hình 8: MLPerf Inference v2.0 so với v1.1 RNNT trên mỗi kết quả thẻ trên máy chủ PowerEdge R750xa
U-Net 3D
Các số hiệu suất 3D U-Net đã thay đổi về tỷ lệ và không thể so sánh được trong biểu đồ thanh do thay đổi đối với tập dữ liệu. Bộ dữ liệu mới cho mô hình này là bộ Phân đoạn khối u thận Kitts 2019 . Tuy nhiên, máy chủ PowerEdge R750xa đã mang lại kết quả Số Một trong số các hệ thống có hệ số dạng PCIe đã được gửi. Mô hình này thuộc danh mục thị giác máy tính, nhưng nó đặc biệt liên quan đến dữ liệu hình ảnh y tế.
tóm tắt kết quả
Hình 1 đến Hình 8 cho thấy hiệu suất nhất quán của máy chủ PowerEdge R750xa qua cả hai vòng gửi.
Hình dưới đây cho thấy rằng trong các tình huống ngoại tuyến đối với điểm chuẩn, có một sự cải thiện hiệu suất nhỏ nhưng đáng chú ý:
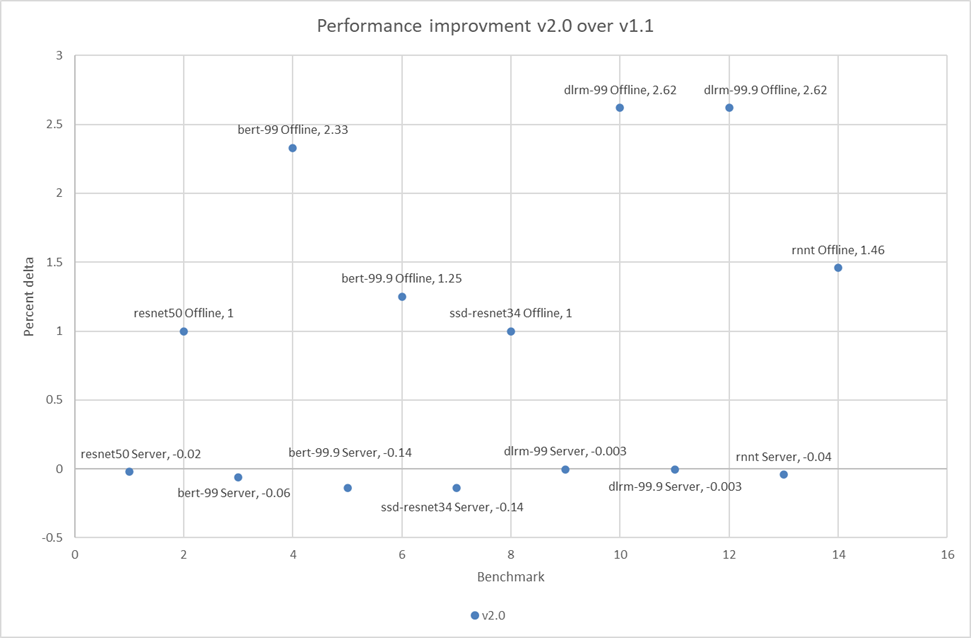
Hình 9: Phần trăm cải thiện hiệu suất của máy chủ PowerEdge R750xa trên MLPerf Inference v2.0 và v1.1
Tỷ lệ phần trăm nhỏ delta trong các kịch bản máy chủ có thể là kết quả của tiếng ồn và phù hợp với vòng gửi trước đó.
Kết luận
Blog này xác nhận hiệu suất nhất quán của máy chủ Dell PowerEdge R750xa qua các lần gửi MLPerf Inference v1.1 và MLPerf Inference v2.0. Bởi vì một hệ thống giống hệt từ vòng v1.1 được thực hiện ở mức nhất quán cho MLPerf Inference v2.0, chúng tôi thấy rằng việc nâng cấp ngăn xếp phần mềm có tác động tối thiểu đến hiệu suất. Do đó, kết quả tối ưu từ vòng gửi v1.1 có thể được sử dụng để đưa ra các quyết định sáng suốt về hiệu suất máy chủ đối với khối lượng công việc ML cụ thể. Do Dell Technologies đã gửi một bộ cấu hình đa dạng trong vòng gửi v1.1 nên khách hàng có thể tận dụng nhiều kết quả.
Bài viết mới cập nhật
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...
Cơ sở hạ tầng CNTT: Mua hay đăng ký?
Nghiên cứu theo số liệu của IDC về giải pháp đăng ...