
Trong hướng dẫn về Giải pháp sẵn sàng cho Dell EMC dành cho AI – Học sâu với kiến trúc NVIDIA , giải pháp sẵn sàng bao gồm các công nghệ được lựa chọn cẩn thận đã được mô tả chi tiết, bao gồm cả chi tiết về lựa chọn thiết kế của từng thành phần. Hướng dẫn kiến trúc đã giới thiệu hai loại máy chủ GPU Dell EMC PowerEdge C4140: PCIe và SXM2. Trong blog này, một cấu hình khác của SXM2 được giới thiệu và chúng tôi sẽ định lượng so sánh hiệu suất cho cả hai cấu hình SXM2.
Tổng quan
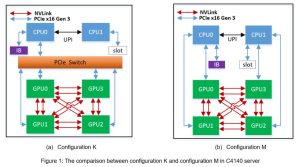
Dell EMC PowerEdge C4140 là máy chủ rack 1U, 2 ổ cắm. Hệ thống này có bộ xử lý Intel Skylake, tối đa 24 DIMM và 4 GPU có chiều rộng gấp đôi. Có hai loại cấu hình SXM2 cho máy chủ C4140: cấu hình K và cấu hình M. Việc so sánh cả hai cấu hình được thể hiện trong Hình 1. Trong cấu hình K, hai CPU được kết nối với bốn GPU chỉ bằng một liên kết PCIe. Tuy nhiên, trong cấu hình M, mỗi CPU được kết nối với một GPU bằng liên kết PCIe. Do đó, có bốn liên kết PCIe kết nối hai CPU với bốn GPU. Blog này sẽ trình bày sự khác biệt về hiệu suất đào tạo deep learning giữa hai cấu hình này. Các framework deep learning mà chúng tôi đã đánh giá chuẩn bao gồm TensorFlow và Horovod. Horovod là một khung phân tán cho TensorFlow. Chúng tôi đã sử dụng Horovod vì nó có triển khai khả năng mở rộng tốt hơn (sử dụng mô hình MPI) so với triển khai phân tán trong chính TensorFlow, điều này đã được giải thích trong bài viết ” Làm quen với Horovod: Khung học tập sâu phân tán mã nguồn mở của Uber cho TensorFlow “.
Bảng 1 cho thấy cấu hình phần cứng và chi tiết phần mềm mà chúng tôi đã thử nghiệm. Việc đánh giá được thực hiện trên tối đa 8 GPU trên hai nút. Tập dữ liệu hình ảnh ILSVRC 2012 nổi tiếng đã được sử dụng, bao gồm 1.281.167 hình ảnh đào tạo và 50.000 hình ảnh xác thực. Tập dữ liệu này được lưu trữ trong bộ lưu trữ Isilon F800. Các mô hình mạng thần kinh đã được đánh giá chuẩn bao gồm Resnet50 và VGG16. Quá trình đo điểm chuẩn được thực hiện ở cả chế độ FP32 (dấu phẩy động 32 bit) và FP16 (độ chính xác hỗn hợp của cả hai dấu phẩy động 32 bit và dấu phẩy động 16 bit). Ở chế độ FP32, kích thước lô đang sử dụng 64 trên mỗi GPU đối với mẫu VGG16 và 128 trên mỗi GPU đối với mẫu Resnet50. Ở chế độ FP16, kích thước lô tương ứng được nhân đôi. Số liệu hiệu suất là tốc độ đào tạo tính bằng hình ảnh/giây.

Đánh giá hiệu suất
Hình 2 và Hình 3 hiển thị so sánh hiệu suất cho cả hai cấu hình C4140 SXM2 với các mẫu Resnet50 và VGG16. Để đơn giản hóa ký hiệu, chúng tôi ký hiệu cấu hình K và cấu hình M của máy chủ C4140 lần lượt là C4140-K và C4140-M. Các kết luận sau đây có thể được đưa ra dựa trên những kết quả này:
- Không có sự khác biệt về hiệu suất khi sử dụng 1 GPU hoặc 2 GPU trong một nút, mặc dù khi sử dụng 2 GPU, C4140-M sử dụng 2 liên kết PCIe trong khi C4140-K chỉ sử dụng 1 liên kết PCIe. Điều này cho thấy rằng đối với cả hai kiểu máy, một liên kết PCIe đủ nhanh để cung cấp cho hai GPU.
- Có sự khác biệt về hiệu suất bắt đầu từ 4 GPU và C4140-M tốt hơn C4140-K trong hầu hết các trường hợp vì nó có thêm ba liên kết PCIe. Sự cải thiện hiệu suất chi tiết được thể hiện trong Bảng 2. Khi sử dụng 4 GPU trong một nút, nó không có sự khác biệt về hiệu suất đối với mô hình VGG16 nhưng có sự khác biệt đối với mô hình Resent50. Điều này có nghĩa là một liên kết PCIe đủ nhanh để cung cấp bốn GPU cho VGG16, nhưng không phải cho Resnet50. Đối với mẫu Resnet50, C4140-M nhanh hơn 5,4% trong FP32 và 7,4% trong FP16 nhanh hơn so với C4140-K. Để tìm ra lý do cải thiện hiệu suất, việc định hình được thực hiện trên C4140-K với 4 GPU (một nút). Chúng tôi đã đo được ~8% thời gian trong FP32 và ~9% thời gian trong FP16 được dành cho việc truyền dữ liệu từ CPU sang GPU. C4140-M có thể cải thiện thời gian này gấp 4 lần vì nó có các liên kết PCIe gấp 4 lần so với C4140-K.
- Khi sử dụng hai nút (8 GPU), cải thiện hiệu suất của C4140-M so với C4140-K cao hơn nhiều so với 4 GPU trong một nút. Điều này là do không chỉ thời gian truyền dữ liệu từ CPU sang GPU được cải thiện, hiệu suất của giao tiếp tập thể All Giảm với thư viện NCCL cũng được cải thiện đáng kể.
- Do C4140-M có hiệu suất đa nút được cải thiện so với C4140-K nên nó có thể đạt được hiệu quả mở rộng quy mô cao hơn. Đối với kiểu máy Resnet50, hiệu suất thay đổi quy mô của C4140-M so với C4140-K là 96,6%:90,0% đối với FP32 và 96,7%:87,1 đối với FP16. Đối với mẫu VGG16, hiệu suất thay đổi quy mô của C4140-M so với C4140-K là 76,9%:70,4% đối với FP32 và 77,8%:70,5% đối với FP16. Nhìn chung, đối với cả hai kiểu máy ở cả chế độ FP32 và FP16, C4140-M có hiệu suất mở rộng cao hơn ~7% so với C4140-K khi sử dụng hai nút.


Kết luận và công việc tương lai
Trong blog này, chúng tôi đã so sánh hiệu suất học sâu trên cả cấu hình K và cấu hình M của máy chủ Dell EMC PowerEdge C4140. Cả hai mô hình Resnet50 và VGG16 đều được đo điểm chuẩn. Đối với một nút và mô hình Resnet50, C4140-M tốt hơn 5% so với C4140-K và cải thiện hiệu suất lên tới 10% được đo cho hai nút. Đối với mẫu VGG16, C4140-M hoạt động tương tự như C4140-K tại một nút, nhưng cải thiện tới 10% đã được ghi nhận tại hai nút. Từ góc độ hiệu quả mở rộng quy mô, đối với cả hai kiểu máy, C4140-M cao hơn ~7% so với C4140-K với 8 GPU (hai nút). C4140-M có lợi thế về hiệu suất vì nó có số liên kết PCIe gấp 4 lần so với C4140-K, dẫn đến thời gian truyền dữ liệu từ CPU sang GPU ít hơn và Tất cả Giảm thời gian giao tiếp tập thể giữa các GPU trên các nút. Trong công việc sắp tới,
Bài viết mới cập nhật
Dell Storage Engines: Tăng tốc suy luận AI với PowerScale và ObjectScale
Giải pháp chuyển tải bộ nhớ đệm KV của Dell cho ...
Bảo vệ Nhà máy AI
Áp dụng phương pháp tiếp cận kiến trúc để bảo mật ...
Tiến lên mạnh mẽ với Dell PowerMax: Vượt mặt Hitachi VSP 5000
Dell PowerMax mang lại khả năng phục hồi, hiệu suất và ...
Đẩy nhanh đổi mới AI: Sức mạnh của quyền truy cập mở
Từ các mô hình tiên tiến đến các ứng dụng cấp ...