
Tin tức
Hiệu suất phát triển mô hình và AI
Đã có một sự gia tăng thông tin to lớn về trí tuệ nhân tạo (AI) và AI tạo sinh (GenAI) đã trở thành tâm điểm như một trường hợp sử dụng chính. Các công ty đang tìm cách tìm hiểu thêm về cách xây dựng kiến trúc để vận hành thành công cơ sở hạ tầng AI. Trong hầu hết các trường hợp, việc tạo ra giải pháp GenAI liên quan đến việc tinh chỉnh một mô hình nền tảng được đào tạo trước và triển khai nó như một dịch vụ suy luận. Dell gần đây đã xuất bản một hướng dẫn thiết kế – AI tạo sinh trong Doanh nghiệp – Suy luận , cung cấp phác thảo về toàn bộ quy trình.
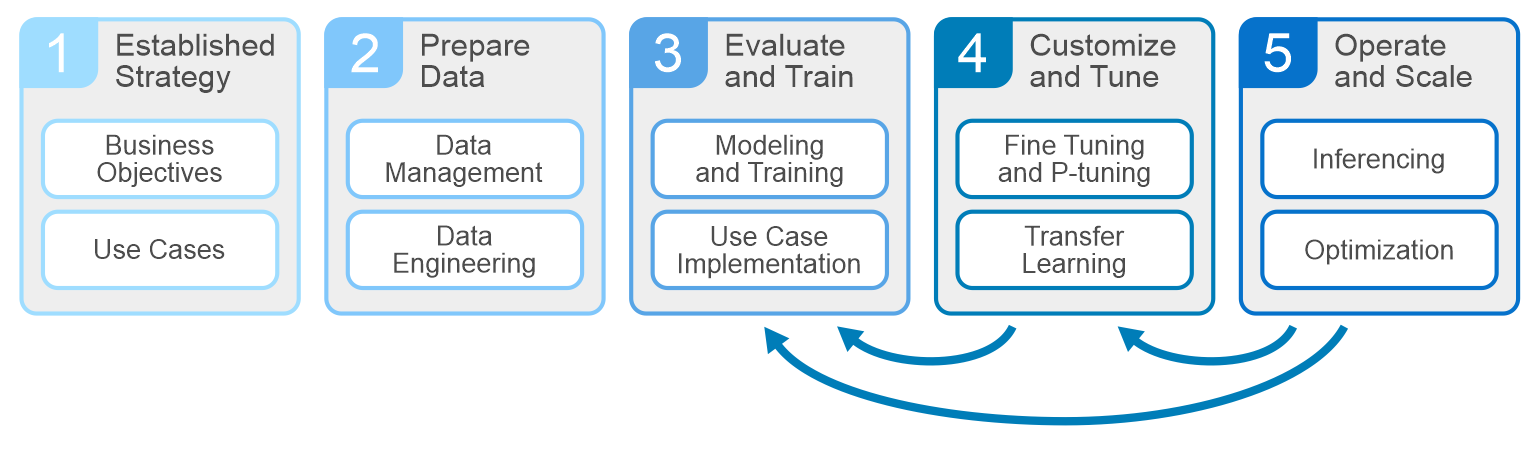
Tất cả các dự án AI nên bắt đầu bằng việc hiểu các mục tiêu kinh doanh và các chỉ số hiệu suất chính. Lập kế hoạch, chuẩn bị dữ liệu và đào tạo tạo nên các giai đoạn khác của chu kỳ. Cốt lõi của quá trình phát triển là các hệ thống thúc đẩy các giai đoạn này – máy chủ, GPU, lưu trữ và cơ sở hạ tầng mạng. Dell được trang bị tốt để cung cấp mọi thứ mà một doanh nghiệp cần để xây dựng, phát triển và duy trì các mô hình phân tích phục vụ nhu cầu kinh doanh.
GPU và bộ tăng tốc đã trở thành thông lệ phổ biến trong cơ sở hạ tầng AI. Chúng thu thập dữ liệu và đào tạo/tinh chỉnh các mô hình trong khả năng tính toán của GPU. Khi GPU phát triển, khả năng xử lý các mô hình lớn hơn và các chu kỳ phát triển song song của chúng cũng phát triển. Điều này khiến nhiều người trong chúng ta tự hỏi – làm thế nào để xây dựng một kiến trúc hỗ trợ phát triển mô hình mà doanh nghiệp của tôi cần? Việc hiểu một vài thông số sẽ hữu ích.
Việc xác định mục tiêu kinh doanh và trường hợp sử dụng sẽ giúp định hình các yêu cầu về kiến trúc của bạn.
- Kích thước và vị trí của tập dữ liệu đào tạo
- Kích thước mô hình theo số lượng tham số và loại mô hình đang được đào tạo/điều chỉnh
- Đào tạo song song và thời gian hoàn thành đào tạo/điều chỉnh.
Trả lời những câu hỏi này giúp xác định cần bao nhiêu GPU để đào tạo/tinh chỉnh mô hình. Hãy xem xét hai yếu tố chính trong việc định cỡ GPU. Đầu tiên là lượng bộ nhớ GPU cần thiết để lưu trữ các tham số mô hình và trạng thái tối ưu hóa. Thứ hai là số phép toán dấu phẩy động (FLOP) cần thiết để thực thi mô hình. Cả hai thường mở rộng theo kích thước mô hình. Các mô hình lớn thường vượt quá tài nguyên của một GPU duy nhất và yêu cầu phân bổ một mô hình duy nhất trên nhiều GPU.
Việc ước tính số lượng GPU cần thiết để đào tạo/tinh chỉnh mô hình giúp xác định công nghệ máy chủ cần lựa chọn. Khi định cỡ máy chủ, điều quan trọng là phải cân bằng mật độ GPU và kết nối phù hợp, mức tiêu thụ điện năng, công nghệ bus PCI, dung lượng cổng ngoài, bộ nhớ và CPU. Máy chủ Dell PowerEdge bao gồm nhiều tùy chọn cho loại GPU và mật độ. Máy chủ PowerEdge XE có thể lưu trữ tối đa 8 GPU NVIDIA H100 trong một máy chủ GenAI trên PowerEdge XE9680 , cũng như các công nghệ mới nhất, bao gồm NVLink, NVIDIA GPUDirect, PCIe 5.0 và đĩa NVMe. Máy chủ PowerEdge chính thống có từ hai đến bốn cấu hình GPU, cung cấp nhiều loại GPU từ các nhà sản xuất khác nhau. Máy chủ PowerEdge cung cấp hiệu suất vượt trội cho tất cả các giai đoạn phát triển mô hình. Truy cập Dell.com để biết thêm thông tin về Máy chủ PowerEdge .
Bây giờ chúng ta đã hiểu cần bao nhiêu GPU và máy chủ để lưu trữ chúng, đã đến lúc giải quyết vấn đề lưu trữ. Ít nhất, bộ lưu trữ phải có dung lượng để lưu trữ bộ dữ liệu đào tạo, các điểm kiểm tra trong quá trình đào tạo mô hình và bất kỳ dữ liệu nào khác liên quan đến giai đoạn cắt tỉa/chuẩn bị. Bộ lưu trữ cũng cần phân phối dữ liệu ở tốc độ mà GPU yêu cầu. Tốc độ phân phối được nhân với tính song song của mô hình hoặc số lượng mô hình được đào tạo song song và sau đó là số lượng GPU yêu cầu dữ liệu đồng thời (đồng thời). Lý tưởng nhất là mọi GPU đều chạy ở mức 90% trở lên để tối đa hóa khoản đầu tư của chúng ta và một hệ thống lưu trữ hỗ trợ tính đồng thời cao sẽ phù hợp với các loại khối lượng công việc này.
Các công cụ như FIO hoặc GDSIO (được sử dụng để hiểu tốc độ và nguồn cấp dữ liệu của hệ thống lưu trữ) rất tuyệt vời để đạt được số lượng anh hùng hoặc mức tối đa lý thuyết cho các lần đọc/ghi, nhưng chúng không đại diện cho các yêu cầu về hiệu suất cho các chu kỳ phát triển AI. Chuẩn bị dữ liệu và giai đoạn hiển thị trên bộ lưu trữ dưới dạng R/W ngẫu nhiên, trong khi trong giai đoạn đào tạo/tinh chỉnh, GPU đồng thời truyền phát các lần đọc từ hệ thống lưu trữ. Các điểm kiểm tra trong suốt quá trình đào tạo được xử lý dưới dạng ghi trở lại bộ lưu trữ. Những điểm khác nhau này trong suốt vòng đời AI yêu cầu bộ lưu trữ có thể xử lý thành công các khối lượng công việc này ở quy mô được xác định bởi các tính toán mô hình và các chu kỳ phát triển song song của chúng tôi.
Các nhà khoa học dữ liệu tại Dell nỗ lực rất nhiều trong việc tìm hiểu cách phát triển mô hình khác nhau ảnh hưởng đến yêu cầu về máy chủ và lưu trữ như thế nào. Ví dụ, các mô hình ngôn ngữ như BERT và GPT có ít tác động đến hiệu suất lưu trữ và tài nguyên, trong khi các mô hình giải trình tự hình ảnh và DLRM có hiệu suất lưu trữ và nhu cầu tài nguyên đáng kể hoặc cho thấy trường hợp xấu nhất. Đối với điều này, các nhóm lưu trữ của Dell tập trung thử nghiệm và đánh giá chuẩn trên các quy trình làm việc AI Deep Learning dựa trên các mô hình hình ảnh phổ biến như ResNet với GPU thực để hiểu các yêu cầu về hiệu suất cần thiết để cung cấp dữ liệu cho GPU trong quá trình đào tạo mô hình. Hình ảnh sau đây cho thấy một kiến trúc được thiết kế với máy chủ Dell PowerEdge và mạng với bộ lưu trữ mở rộng PowerScale.
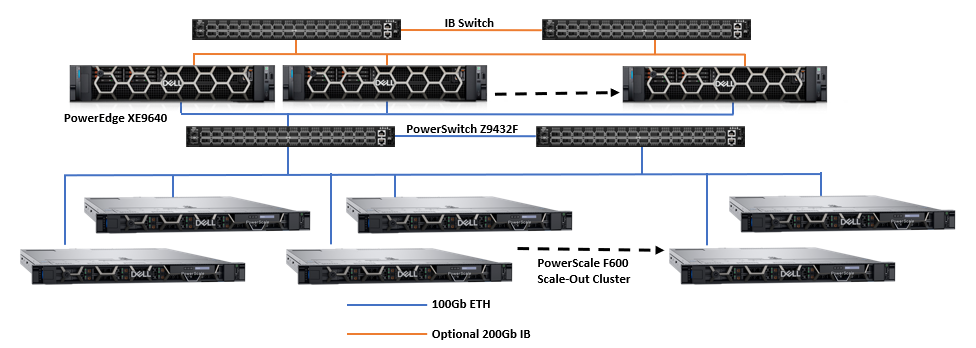
Lưu trữ tệp mở rộng Dell PowerScale đặc biệt phù hợp với các khối lượng công việc này. Mỗi nút trong cụm PowerScale cung cấp hiệu suất tương đương khi cụm và khối lượng công việc mở rộng. Các hình ảnh sau đây cho thấy hiệu suất PowerScale mở rộng tuyến tính như thế nào khi GPU tăng lên, trong khi hiệu suất của từng GPU riêng lẻ vẫn không đổi. Kiến trúc mở rộng của lưu trữ tệp PowerScale dễ dàng hỗ trợ các quy trình công việc AI từ nhỏ đến lớn.
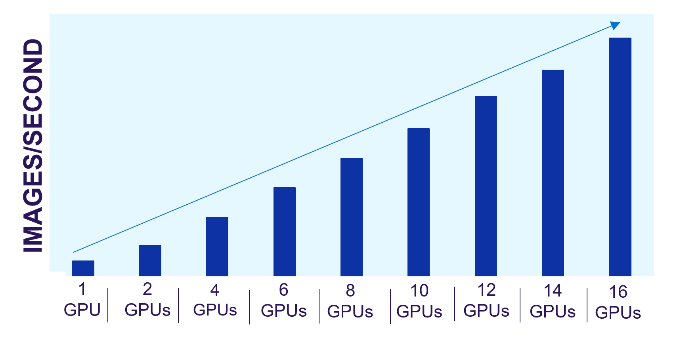
Hình 1. Hiệu suất tuyến tính của PowerScale
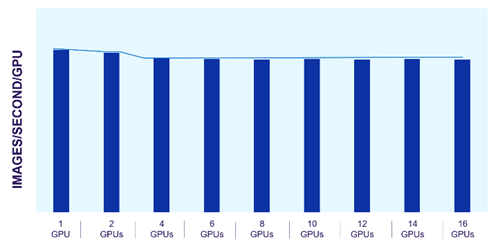
Hình 2. Hiệu suất GPU nhất quán với quy mô
Khả năng dự đoán của PowerScale cho phép chúng tôi ước tính tài nguyên lưu trữ cần thiết để đào tạo mô hình và tinh chỉnh. Chúng tôi có thể dễ dàng mở rộng các kiến trúc này dựa trên loại và kích thước mô hình cùng với số lượng và loại GPU cần thiết.
Việc thiết kế kiến trúc cho khối lượng công việc AI nhỏ và lớn là một thách thức và cần phải lập kế hoạch. Việc hiểu nhu cầu về hiệu suất và cách các thành phần trong kiến trúc sẽ hoạt động khi nhu cầu khối lượng công việc AI tăng lên là rất quan trọng.
Tác giả : Darren Miller
Bài viết mới cập nhật
Chính sách bảo mật tài khoản OneFS
Một trong những cải tiến bảo mật cốt lõi khác được ...
Chính sách bảo mật mật khẩu OneFS
Trong số hàng loạt cải tiến bảo mật được giới thiệu ...
Hỗ trợ Rekey của OneFS Key Manager
Trình quản lý khóa OneFS là dịch vụ phụ trợ điều ...
Hiệu suất phát triển mô hình và AI
Đã có một sự gia tăng thông tin to lớn về ...