
Tin tức
Hiệu suất suy luận mạng thần kinh sâu trên Intel FPGA sử dụng Intel OpenVINO
Suy luận là quá trình chạy một mạng lưới thần kinh đã được đào tạo để xử lý các đầu vào mới và đưa ra dự đoán. Việc đào tạo thường được thực hiện ngoại tuyến trong trung tâm dữ liệu hoặc cụm máy chủ. Suy luận có thể được thực hiện trong nhiều môi trường khác nhau tùy thuộc vào trường hợp sử dụng. Intel® FPGA cung cấp giải pháp thông lượng cao, tiêu thụ điện năng thấp để chạy suy luận. Trong blog này, chúng tôi xem xét việc sử dụng Thẻ tăng tốc lập trình Intel® (PAC) với Intel® Arria® 10GX FPGA để chạy suy luận trên mô hình Mạng thần kinh chuyển đổi (CNN) được đào tạo để xác định các bệnh lý ở lồng ngực.
Ưu điểm của việc sử dụng Intel® FPGA
Tăng tốc hệ thống: Intel® FPGA tăng tốc và hỗ trợ tính toán cũng như khả năng kết nối cần thiết để thu thập và xử lý lượng thông tin khổng lồ xung quanh chúng ta bằng cách kiểm soát đường dẫn dữ liệu. Ngoài việc sử dụng FPGA làm giảm tải điện toán, chúng còn có thể trực tiếp nhận dữ liệu và xử lý nội tuyến mà không cần thông qua hệ thống máy chủ. Điều này giải phóng bộ xử lý để quản lý các sự kiện hệ thống khác và cho phép hiệu năng hệ thống theo thời gian thực cao hơn.
Hiệu suất năng lượng: Intel® FPGA có băng thông bộ nhớ trên 8 TB/s. Vì vậy, các giải pháp có xu hướng giữ dữ liệu trên thiết bị gắn chặt với lần tính toán tiếp theo. Điều này giảm thiểu nhu cầu truy cập vào bộ nhớ ngoài và dẫn đến việc triển khai mạch hiệu quả hơn trong FPGA, nơi dữ liệu có thể được song song, dẫn đường và xử lý trên mỗi chu kỳ xung nhịp. Các mạch này có thể chạy ở tần số xung nhịp thấp hơn đáng kể so với các bộ xử lý đa năng truyền thống và mang lại các giải pháp rất mạnh mẽ và hiệu quả.
Kiểm chứng trong tương lai: Ngoài khả năng tăng tốc hệ thống và tiết kiệm năng lượng, Intel® FPGA còn hỗ trợ các hệ thống kiểm chứng trong tương lai. Với công nghệ năng động như máy học đang phát triển và thay đổi liên tục, Intel® FPGA mang đến sự linh hoạt không có ở các thiết bị cố định. Khi độ chính xác giảm từ mạng 32 bit xuống 8 bit và thậm chí cả mạng nhị phân/thứ ba, FPGA có khả năng linh hoạt để hỗ trợ những thay đổi đó ngay lập tức. Khi các kiến trúc và phương pháp thế hệ tiếp theo được phát triển, FPGA sẽ có mặt để triển khai chúng.
Mô hình và phần mềm
Mô hình này là Resnet-50 CNN được đào tạo trên bộ dữ liệu X-quang ngực của NIH . Bộ dữ liệu chứa hơn 100.000 ảnh chụp X-quang ngực, mỗi ảnh được dán nhãn một hoặc nhiều bệnh lý. Mô hình này được đào tạo trên bộ xử lý 512 Intel® Xeon® Scalable Gold 6148 trong 11,25 phút trên cụm Zenith tại DellEMC.
Mô hình được huấn luyện bằng Tensorflow 1.6. Chúng tôi sử dụng bộ công cụ Intel® OpenVINO™ R3 để triển khai mô hình trên FPGA. Bộ công cụ Intel® OpenVINO™ là tập hợp các công cụ phần mềm hỗ trợ triển khai các mô hình học sâu. Bài đăng trên blog OpenVINO này nêu chi tiết quy trình chuyển đổi mô hình Tensorflow sang định dạng có thể chạy trên FPGA.
Hiệu suất
Trong phần này, chúng ta xem xét số lượng điện năng tiêu thụ và thông lượng trên máy chủ Dell EMC PowerEdge R740 và R640.
Sử dụng Dell EMC PowerEdge R740 với 2x Intel® Xeon® Scalable Gold 6136 (300W) và 4x Intel® PAC
Các số liệu bên dưới thể hiện mức tiêu thụ điện năng và số lượng thông lượng để chạy mô hình trên Intel® PAC và kết hợp với Intel® Xeon® Scalable Gold 6136. Chúng tôi nhận thấy rằng việc bổ sung một Intel® PAC duy nhất chỉ tăng thêm 43W vào công suất hệ thống trong khi cung cấp khả năng suy luận hơn 100 tia X ngực mỗi giây. Sức mạnh bổ sung và hiệu suất suy luận sẽ tăng theo tuyến tính khi bổ sung thêm nhiều Intel® PAC hơn. Ở cấp độ hệ thống, chúng tôi thấy thông lượng cải thiện 2,3 lần và hiệu suất cải thiện 116% (hình ảnh trên giây trên Watt) khi sử dụng 4x Intel® PAC với 2x Intel® Xeon® Scalable Gold 6136.
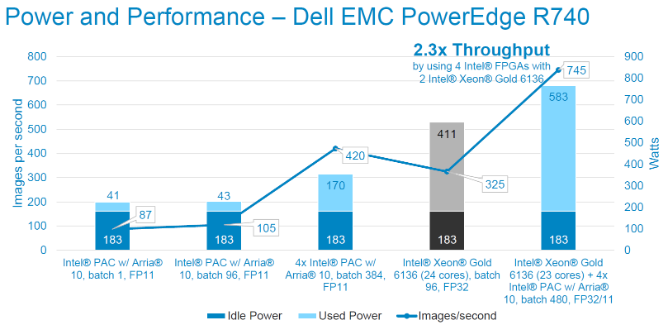 Kiểm tra hiệu năng suy luận bằng cấu trúc liên kết ResNet-50. Độ chính xác FP11 Kích thước hình ảnh là 224x224x3. Công suất đo qua racadm
Kiểm tra hiệu năng suy luận bằng cấu trúc liên kết ResNet-50. Độ chính xác FP11 Kích thước hình ảnh là 224x224x3. Công suất đo qua racadm
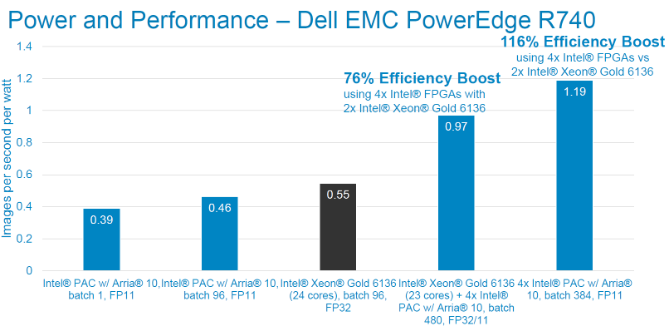 Kiểm tra hiệu suất trên mỗi watt bằng cấu trúc liên kết ResNet-50. Độ chính xác FP11 Kích thước hình ảnh là 224x224x3. Công suất đo qua racadm
Kiểm tra hiệu suất trên mỗi watt bằng cấu trúc liên kết ResNet-50. Độ chính xác FP11 Kích thước hình ảnh là 224x224x3. Công suất đo qua racadm
Sử dụng Dell EMC PowerEdge R640 với 2x Intel® Xeon® Scalable Gold 5118 (210W) và 2x Intel® PAC
Chúng tôi cũng sử dụng máy chủ có công suất nhàn rỗi thấp hơn. Chúng tôi thấy hiệu suất hệ thống được cải thiện 2,6 lần trong trường hợp này. Như trước đây, mỗi Intel® PAC tăng thêm hiệu năng cho hệ thống một cách tuyến tính, tăng thêm hơn 100 lần suy luận mỗi giây với mức tiêu thụ 43W (2,44 hình ảnh/giây/W).
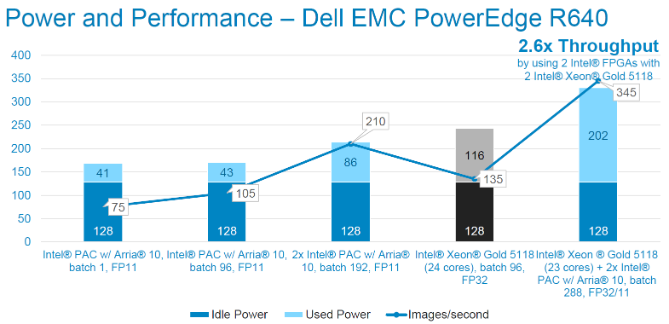 Kiểm tra hiệu năng suy luận bằng cấu trúc liên kết ResNet-50. Độ chính xác FP11 Kích thước hình ảnh là 224x224x3. Công suất đo qua racadm
Kiểm tra hiệu năng suy luận bằng cấu trúc liên kết ResNet-50. Độ chính xác FP11 Kích thước hình ảnh là 224x224x3. Công suất đo qua racadm
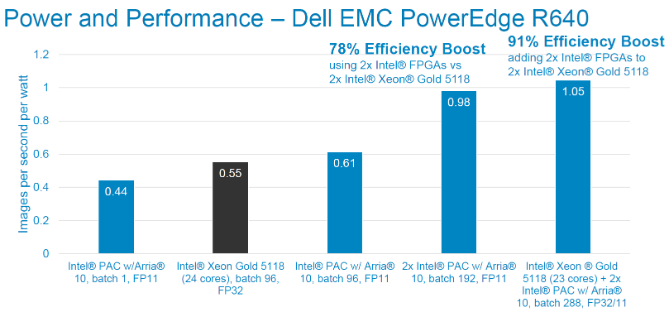 Kiểm tra hiệu suất trên mỗi watt bằng cấu trúc liên kết ResNet-50. Độ chính xác FP11 Kích thước hình ảnh là 224x224x3. Công suất đo qua racadm
Kiểm tra hiệu suất trên mỗi watt bằng cấu trúc liên kết ResNet-50. Độ chính xác FP11 Kích thước hình ảnh là 224x224x3. Công suất đo qua racadm
Phần kết luận
Intel® FPGA kết hợp với Intel® OpenVINO™ cung cấp giải pháp hoàn chỉnh để triển khai các mô hình học sâu trong sản xuất. FPGA cung cấp công suất thấp và tính linh hoạt khiến chúng rất phù hợp làm thiết bị tăng tốc cho khối lượng công việc deep learning.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...