
Tin tức
Hiệu suất ứng dụng HPC trên Máy chủ Dell PowerEdge R750xa với Bộ tăng tốc AMD Instinct TM MI210
Tổng quan
Máy chủ Dell PowerEdge R750xa, được trang bị bộ xử lý Intel Xeon có thể mở rộng thế hệ thứ 3, là máy chủ rack 2U hỗ trợ CPU kép, với tối đa 32 DDR4 DIMM ở tốc độ 3200 MT/s ở tám kênh trên mỗi CPU. Máy chủ PowerEdge R750xa được thiết kế để hỗ trợ tối đa bốn thẻ tăng tốc PCI Gen 4 và tối đa tám ổ SSD SAS/SATA hoặc NVMe.

Hình 1: Mặt trước của máy chủ PowerEdge R750xa
Bộ tăng tốc PCIe AMD Instinct™ MI210 là GPU mới nhất của AMD được thiết kế cho nhiều ứng dụng HPC và AI. Nó cung cấp các tính năng và công nghệ chính sau:
- Được xây dựng với kiến trúc AMD CDNA thế hệ thứ 2 với các lõi ma trận mới mang đến những cải tiến về hoạt động của FP64 và cho phép thực hiện nhiều khả năng có độ chính xác hỗn hợp
- Băng thông bộ nhớ HBM2e tốc độ cao 64 GB hỗ trợ khối lượng công việc đòi hỏi nhiều dữ liệu
- Công nghệ AMD Infinity Fabric™ thế hệ thứ 3 mang lại khả năng mở rộng và kết nối nền tảng tiên tiến cho phép các tổ hợp GPU P2P kép được kết nối đầy đủ thông qua các liên kết AMD Infinity Fabric™
- Kết hợp với nền tảng phần mềm mở AMD ROCm™ 5 cho phép các nhà nghiên cứu khai thác sức mạnh của bộ tăng tốc AMD Instinct™ với các trình biên dịch, thư viện và hỗ trợ thời gian chạy được tối ưu hóa
Blog này cung cấp các đặc tính hiệu suất của một máy chủ PowerEdge R750xa duy nhất với bộ tăng tốc AMD Instinct MI210. Nó so sánh số hiệu suất của các điểm chuẩn vi mô (GEMM của FP64 và FP32 và kiểm tra băng thông), HPL và LAMMPS cho cả bộ tăng tốc AMD Instinct MI210 và bộ tăng tốc AMD Instinct MI100 thế hệ trước.
Bảng sau đây cung cấp chi tiết cấu hình cho hệ thống PowerEdge R750xa đang được thử nghiệm (SUT):
Bảng 1: Cấu hình phần cứng và phần mềm SUT
| Thành phần | Sự miêu tả |
| Bộ xử lý | Intel Xeon Gold 6338 kép |
| Ký ức | 512 GB – 16 x 32 GiB@3200 MHz |
| Đĩa cục bộ | SSD 3,84 TB SATA-6GB |
| Hệ điều hành | Rocky Linux phát hành 8.4 (Green Obsidian) |
| mô hình GPU | 4 x AMD MI210 (PCIe-64G) hoặc 3 x AMD MI100 (PCIe-32G) |
| Phiên bản trình điều khiển GPU | 5.13.20.5.1 |
| Phiên bản ROCm | 5.1.3 |
| Cài đặt bộ xử lý > Bộ xử lý logic | Tàn tật |
| Hồ sơ hệ thống | Hiệu suất |
| rocm-blas-băng ghế | 5.1.3 |
| Băng ghế dự bị chuyển nhượng | 5.1.3 |
| HPL | Biên soạn với ROCm v5.1.3 |
| LAMMPS (KOKKOS) | Phiên bản: LAMMPS patch_4May2022 |
Bảng sau đây cung cấp thông số kỹ thuật của GPU AMD Instinct MI210 và MI100:
Bảng 2: Thông số GPU AMD Instinct MI100 và MI210 PCIe
| kiến trúc GPU | Bản năng AMD MI210 | Bản năng AMD MI100 |
| Đồng hồ động cơ đỉnh (MHz) | 1700 | 1502 |
| Bộ xử lý luồng | 6656 | 7680 |
| Đỉnh FP64 (TFlop) | 22,63 | 11,5 |
| DGEMM Tensor đỉnh FP64 (TFlops) | 45,25 | 11,5 |
| Đỉnh FP32 (TFlop) | 22,63 | 23.1 |
| SGEMM Tensor đỉnh FP32 (TFlops) | 45,25 | 46,1 |
| Kích thước bộ nhớ (GB) | 64 | 32 |
| Loại bộ nhớ | HBM2e | HBM2 |
| Băng thông bộ nhớ tối đa (GB/s) | 1638 | 1228 |
| Hỗ trợ ECC bộ nhớ | Đúng | Đúng |
| TDP (Watt) | 300 | 300 |
Điểm chuẩn vi mô GEMM
Phép nhân ma trận-ma trận chung (GEMM) là một tiêu chuẩn nhân ma trận dày đặc đa luồng được sử dụng để đo hiệu suất của một GPU. Độ phức tạp tính toán O(n 3 ) duy nhất so với yêu cầu bộ nhớ O(n 2 ) của GEMM khiến nó trở thành chuẩn mực lý tưởng để đo khả năng tăng tốc GPU với hiệu suất cao vì việc đạt được hiệu quả cao phụ thuộc vào việc giảm thiểu truy cập bộ nhớ dư thừa.
Đối với thử nghiệm này, chúng tôi đã tuân thủ tệp nhị phân rocblas-bench từ https://github.com/ROCmSoftwarePlatform/rocBLAS để thu thập các số hiệu suất DGEMM (độ chính xác kép) và SGEMM (độ chính xác đơn).
Những kết quả này chỉ phản ánh hiệu suất của phép nhân ma trận và kết quả được đo dưới dạng TFLOPS đỉnh mà máy gia tốc có thể cung cấp. Những con số này có thể được sử dụng để so sánh khả năng hiệu suất điện toán cao nhất của các máy gia tốc khác nhau. Tuy nhiên, chúng có thể không đại diện cho hiệu suất ứng dụng trong thế giới thực.
Hình 2 trình bày kết quả hiệu suất được đo cho DGEMM và SGEMM trên một GPU:
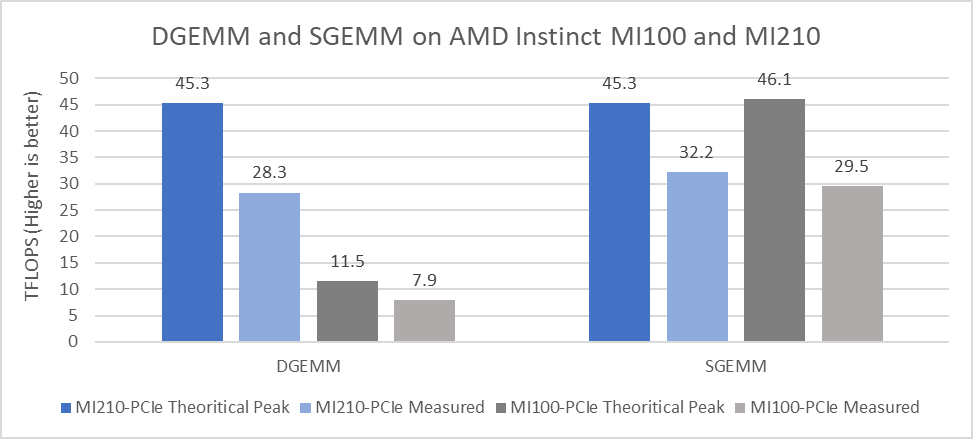
Hình 2: Số DGEMM và SGEMM thu được trên GPU AMD Instinct MI210 và MI100 với máy chủ PowerEdge R750xa
Từ kết quả chúng tôi nhận thấy:
- Kiến trúc CDNA 2 của AMD, bao gồm Lõi ma trận thế hệ thứ hai và bộ nhớ nhanh hơn, mang lại sự cải thiện đáng kể về giá trị DGEMM FP64 Tensor cao nhất về mặt lý thuyết (45,3 TFLOPS). Kết quả này tốt hơn 3,94 lần so với GPU AMD Instinct MI100 thế hệ trước đạt đỉnh 11,5 TFLOPS. Giá trị DGEMM đo được trên GPU AMD Instinct MI250 là 28,3 TFlops, tốt hơn 3,58 lần so với giá trị đo được là 7,9 TFlops trên GPU AMD Instinct MI100.
- Đối với các hoạt động Tensor FP32 trong điểm chuẩn GEMM có độ chính xác đơn SGEMM, hiệu suất cao nhất về mặt lý thuyết của GPU AMD Instinct MI210 là 45,23 TFLOPS và giá trị hiệu suất đo được là 32,2 TFLOPS. Giá trị đo được của SGEMM đã được cải thiện khoảng chín phần trăm so với GPU AMD Instinct MI100.
Kiểm tra băng thông GPU-GPU
Thử nghiệm này nắm bắt các đặc tính hiệu suất của hoạt động sao chép bộ đệm và đọc/ghi kernel. Chúng tôi đã thu thập kết quả bằng cách sử dụng TransferBench, biên dịch tệp nhị phân bằng cách làm theo quy trình được cung cấp tại https://github.com/ROCmSoftwarePlatform/rccl/tree/develop/tools/TransferBench . Trên máy chủ PowerEdge R750xa, cả GPU AMD Instinct MI100 và MI210 đều có cùng thông lượng GPU-to-GPU, như minh họa trong hình sau:
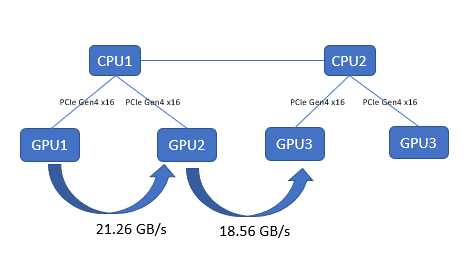
Hình 3 : Kiểm tra băng thông GPU-to-GPU bằng TransferBench trên máy chủ PowerEdge R750xa với GPU AMD Instinct MI210
Điểm chuẩn Linpack hiệu suất cao (HPL)
HPL đo lường khả năng tính toán dấu phẩy động của hệ thống bằng cách giải một hệ phương trình tuyến tính ngẫu nhiên bằng số học có độ chính xác kép (FP64). Trên lý thuyết, FLOPS cao nhất (Rpeak) là số lượng phép toán dấu phẩy động cao nhất mà máy tính có thể thực hiện mỗi giây.
Nó có thể được tính bằng công thức sau:
tốc độ xung nhịp của GPU × số lõi GPU × số hoạt động dấu phẩy động mà GPU thực hiện trong mỗi chu kỳ
Hiệu suất đo được gọi là Rmax. Tỷ lệ Rmax và Rpeak thể hiện hiệu suất HPL, tức là hiệu suất đo được gần với mức đỉnh lý thuyết đến mức nào. Một số yếu tố ảnh hưởng đến hiệu quả bao gồm tăng tốc độ xung nhịp lõi GPU và hiệu quả của thư viện phần mềm.
Các kết quả hiển thị trong hình dưới đây là giá trị Rmax, được đo số HPL trên GPU AMD Instinct MI210 và AMD MI100. Tệp nhị phân HPL được sử dụng để thu thập kết quả được biên dịch bằng ROCm 5.1.3.
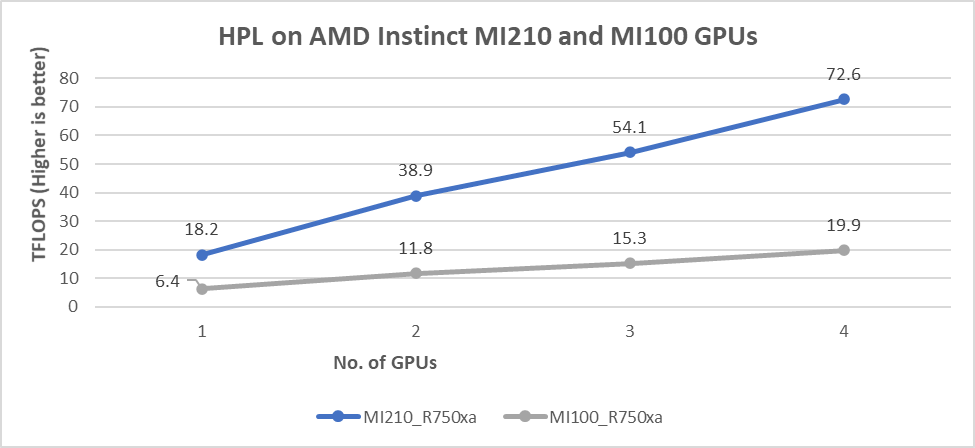
Hình 4: Hiệu suất HPL trên GPU AMD Instinct MI210 và MI100 được trang bị máy chủ R750xa
Hình dưới đây cho thấy mức tiêu thụ điện năng trong một lần kiểm tra HPL:

Hình 5: Mức sử dụng năng lượng của hệ thống trong một lần kiểm tra HPL trên bốn GPU
Quan sát của chúng tôi bao gồm:
- Chúng tôi đã nhận thấy sự cải thiện đáng kể về hiệu suất HPL với GPU AMD Instinct MI210 so với GPU AMD Instinct MI100. Hiệu năng trong một phép thử duy nhất của GPU AMD Instinct MI210 là 18,2 TFLOPS, cao hơn 2,8 lần so với con số 6,4 TFLOPS của AMD Instinct MI100. Cải tiến này là kết quả của kiến trúc AMD CDNA2 trên GPU AMD Instinct MI210, đã được tối ưu hóa cho khối lượng công việc vectơ và ma trận FP64.
- Như được hiển thị trong Hình 4, GPU AMD Instinct MI210 cung cấp khả năng mở rộng gần như tuyến tính trong các giá trị HPL khi chạy nhiều GPU một nút. GPU AMD Instinct MI210 cho thấy khả năng mở rộng tốt hơn so với GPU AMD Instinct MI100 thế hệ trước.
- Cả GPU AMD Instinct MI100 và MI210 đều có cùng mức TDP là 300 W, trong đó GPU AMD Instinct MI210 mang lại hiệu năng tốt hơn 3,6 lần. Giá trị hiệu suất trên mỗi watt từ máy chủ PowerEdge R750xa cao hơn 3,6 lần.
Điểm chuẩn LAMMPS
LAMMPS là mã mô phỏng động lực phân tử, là một ứng dụng giới hạn băng thông GPU. Chúng tôi đã sử dụng triển khai thư viện tăng tốc KOKKOS của LAMMPS để đo hiệu suất của GPU AMD Instinct MI210.
Hình dưới đây so sánh hiệu suất LAMMPS của GPU AMD Instinct MI210 và MI100 với bốn bộ dữ liệu khác nhau:
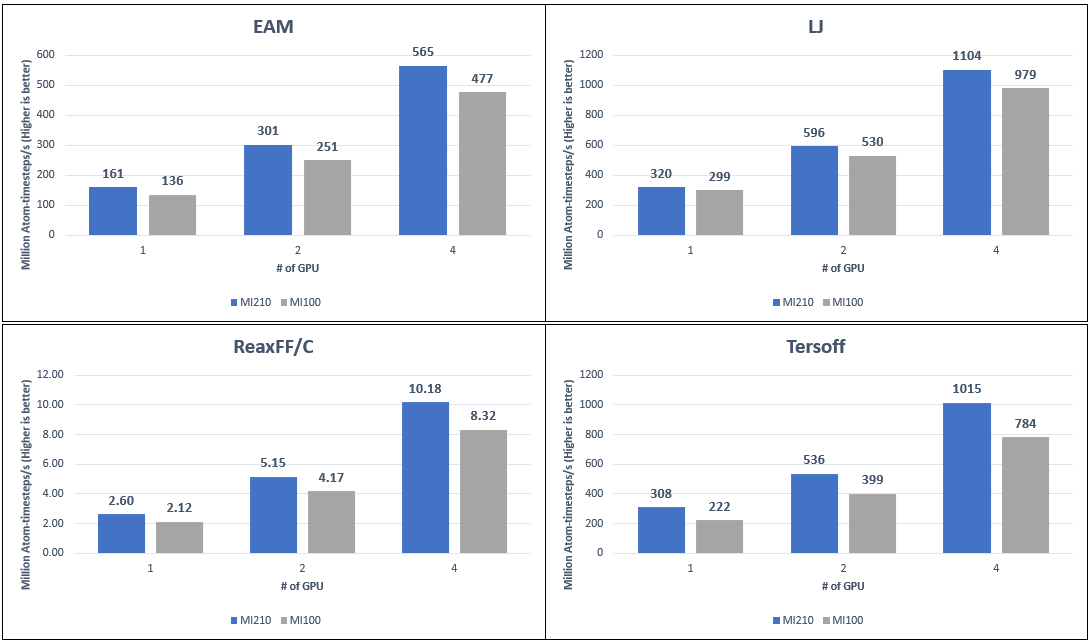
Hình 6: Số hiệu suất LAMMPS trên GPU AMD Instinct MI210 và MI100 trên máy chủ PowerEdge R750xa với các bộ dữ liệu khác nhau
Quan sát của chúng tôi bao gồm:
- Chúng tôi đo lường mức cải thiện hiệu suất trung bình là 21% trên GPU AMD Instinct MI210 so với GPU AMD Instinct MI100 với máy chủ PowerEdge R750xa. Vì GPU MI100 và MI210 có kích thước bộ nhớ GPU tích hợp khác nhau nên kích thước sự cố của từng tập dữ liệu LAMMPS đã được điều chỉnh để thể hiện hiệu suất tốt nhất từ mỗi GPU.
- Các bộ dữ liệu như Tersoff, ReaxFF/C và EAM trên GPU AMD Instinct MI210 cho thấy mức cải thiện lần lượt là 30%, 22% và 18%. Kết quả này chủ yếu là do GPU AMD Instinct MI210 đi kèm bộ nhớ HBM2e (64 GB) nhanh hơn và lớn hơn so với GPU AMD Instinct MI100 đi kèm bộ nhớ HBM2 (32 GB). Đối với các bộ dữ liệu LJ, sự cải thiện ít hơn nhưng vẫn được quan sát thấy ở mức 12%. Kết quả này là do các phép tính có độ chính xác đơn được sử dụng và hiệu suất cao nhất của FP32 cho GPU AMD Instinct MI210 và MI100 ở cùng mức.
Phần kết luận
GPU AMD Instinct MI210 cho thấy sự cải thiện hiệu suất ấn tượng trong khối lượng công việc FP64. Những khối lượng công việc này được hưởng lợi vì AMD đã tăng gấp đôi chiều rộng ALU của họ lên toàn bộ 64 bit cho phép các hoạt động FP64 hiện chạy ở tốc độ tối đa trong kiến trúc CDNA 2 mới. Các ứng dụng và khối lượng công việc có thể tận dụng hoạt động của FP64 dự kiến sẽ tận dụng tối đa khía cạnh của GPU AMD Instinct MI210. Băng thông bộ nhớ HBM2e nhanh hơn của GPU AMD Instinct MI210 mang lại lợi thế cho các ứng dụng giới hạn bộ nhớ GPU.
Máy chủ PowerEdge R750xa với GPU AMD Instinct MI210 là một công cụ điện toán mạnh mẽ, rất phù hợp cho người dùng HPC cần các giải pháp điện toán tăng tốc.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...