
Tin tức
Kết quả hiệu suất MLPerf Inference v2.1 đầu tiên trên máy chủ PowerEdge dựa trên CPU AMD EPYC™
Dell Technologies, AMD và Deci AI gần đây đã gửi kết quả tới MLPerf Inference v2.1 ở phần mở. Blog này giới thiệu quá trình gửi ba chiều thành công đầu tiên của chúng tôi và mô tả cách sử dụng tốt nhất phần mềm và phần cứng của mỗi bên để đạt được hiệu suất tối ưu cho mô hình MLPerf BERT-Large.
Giới thiệu
MLCommons™ là một tập đoàn gồm các công ty có sứ mệnh thúc đẩy đổi mới công nghệ máy học để mang lại lợi ích cho mọi người. Tổ chức tập trung vào việc đo điểm chuẩn để cho phép hiển thị các phép đo hiệu suất hợp lý và làm cho các bộ dữ liệu mở và có sẵn vì các mô hình trong điểm chuẩn chỉ tốt khi có dữ liệu. Nó cũng chia sẻ các phương pháp hay nhất để bắt đầu tiêu chuẩn hóa việc chia sẻ và giao tiếp giữa các bên liên quan đến học máy.
Việc gửi MLPerf Inference v2.1 nằm trong lộ trình đo điểm chuẩn cho MLCommons. Các đệ trình được gửi tới bộ phận khép kín đảm bảo sự so sánh công bằng giữa nền tảng phần cứng và khung phần mềm. Các bài nộp phải sử dụng cùng một mô hình và trình tối ưu hóa như cách triển khai tham chiếu. Ngoài ra, không được phép đào tạo lại trong bộ phận đóng cửa. Mặt khác, bộ phận mở thúc đẩy các mô hình và trình tối ưu hóa nhanh hơn vì nó cho phép triển khai điểm chuẩn sử dụng một mô hình khác cho cùng một nhiệm vụ. Bất kỳ phương pháp học máy nào cũng được phép nếu nó đáp ứng được chất lượng mục tiêu. Kết quả được gửi tới bộ phận mở giới thiệu các công nghệ thú vị đang được phát triển.
Blog này nêu bật một bản gửi ngoại tuyến được thực hiện trong danh mục BERT 99.9 phân chia mở cho tác vụ xử lý ngôn ngữ tự nhiên (NLP). Mục tiêu của việc gửi là tối đa hóa thông lượng trong khi vẫn giữ độ chính xác trong phạm vi sai số 0,1% so với độ chính xác cơ bản, là 90,874 F1 (Bộ dữ liệu trả lời câu hỏi Stanford (SQuAD)).
Máy chủ Dell PowerEdge R7525 được trang bị bộ xử lý AMD EPYC™
Vì kết quả đo điểm chuẩn MLPerf là sự thể hiện hiệu suất chung của cả phần mềm và phần cứng cơ bản, nên mô hình BERT-Large được tối ưu hóa của Deci AI, được gọi là DeciBERT-Large, đã được chạy bằng ONNXRT trên máy chủ rack Dell PowerEdge R7525 có hai lõi 64 Bộ xử lý AMD EPYC 7773X.
Máy chủ rack PowerEdge R7525 là máy chủ rack 2U hai socket có khả năng mở rộng và khả năng thích ứng cao, mang lại hiệu suất mạnh mẽ và cấu hình linh hoạt. Đây là giải pháp lý tưởng cho các khối lượng công việc cũng như ứng dụng truyền thống và mới nổi bao gồm bộ nhớ flash được xác định bằng phần mềm (SDS), cơ sở hạ tầng máy tính ảo (VDI) và khối lượng công việc phân tích dữ liệu (DA). Như bài đăng MLPerf của blog này cho thấy, máy chủ rack PowerEdge R7525 cũng rất phù hợp với khối lượng công việc AI như suy luận học sâu.
Máy chủ PowerEdge R7525 là một lựa chọn máy chủ tuyệt vời vì nhiều lý do. Một số thông số kỹ thuật cấp cao nhằm đáp ứng nhu cầu về hiệu suất bao gồm tối đa 24 ổ NVMe được kết nối trực tiếp hỗ trợ tất cả các Nút sẵn sàng AF8 vSAN flash. Bộ nhớ 4 TB và hai bộ xử lý AMD EPYC mang lại hiệu suất tối ưu. Ngoài ra, máy chủ PowerEdge R7525 còn có cấu hình IOPS, lưu trữ và bộ nhớ tối đa được hỗ trợ bởi tối đa tám khe cắm PCIe Gen4. Hơn nữa, bộ tăng tốc dòng AMD Instinct™ MI100 và MI200 cũng như các GPU có chiều rộng gấp đôi khác có thể cung cấp thêm mức tăng tốc.
Bộ xử lý AMD EPYC với Công nghệ AMD 3D V-Cache™ được ra mắt vào tháng 3 năm 2022. Dòng bộ xử lý AMD EPYC cấp máy chủ cải tiến mới này được thiết kế để tăng tốc khối lượng công việc tính toán kỹ thuật, bao gồm động lực học chất lỏng tính toán (CFD), tự động hóa thiết kế điện tử (EDA) và phân tích phần tử hữu hạn (FEA).
Với lần gửi MLPerf chung này, lần đầu tiên dành cho bộ xử lý AMD EPYC với Công nghệ AMD 3D V-Cache, AMD chứng minh khả năng ứng dụng của bộ xử lý AMD EPYC mới và bộ đệm L3 bổ sung của họ cho khối lượng công việc suy luận deep learning.
Deci AI DeciBERT-So sánh và số liệu mô hình lớn
Deci AI đã sử dụng Công cụ AutoNAC™ (Xây dựng kiến trúc thần kinh tự động) độc quyền của họ để tạo ra mô hình BERT-Large được tối ưu hóa, được gọi là DeciBERT-Large, được điều chỉnh riêng cho máy chủ PowerEdge R7525 cơ bản và hai bộ xử lý AMD EPYC 7773X 64 nhân. Thuật toán Deci AI giảm kích thước mô hình BERT-Large tham chiếu gần ba lần, từ 340 triệu tham số trong mô hình BERT-Large tiêu chuẩn xuống còn 115 triệu tham số, đồng thời đạt được hiệu suất và độ chính xác hấp dẫn.
Từ góc độ dung lượng bộ nhớ, việc giảm số lượng tham số cũng góp phần tiết kiệm không gian đáng kể tương tự với mô hình DeciBERT-Large. Kích thước mô hình ONNX DeciBERT-Large là 378 MB ở FP32 và 95 MB ở INT8 so với 1,4 GB khi triển khai mô hình BERT-Large tham chiếu từ MLCommons.
Bằng cách ghép nối mô hình DeciBERT-Large được tối ưu hóa, nhỏ hơn với dung lượng bộ đệm L3 mở rộng của bộ xử lý AMD EPYC với 3D V-Cache, nhiều mô hình có thể được lưu trữ trong bộ đệm cùng một lúc. Phương pháp tận dụng bộ nhớ đệm L3 bổ sung này cho phép truy cập bộ nhớ gần như tính toán và có độ trễ thấp hơn so với DRAM.
Các bảng sau nêu bật các điểm dữ liệu được Deci AI thu thập trên máy chủ PowerEdge R7525 với hai bộ xử lý AMD EPYC 7773X. Việc áp dụng thuật toán Deci AI AutoNAC để tạo mô hình DeciBERT-Large cho thấy hiệu suất FP32 được cải thiện 6,33 lần và hiệu suất INT8 tăng 6,64 lần, đồng thời đạt được điểm INT8 F1 là 91,08, cao hơn điểm F1 là 90,07 về việc triển khai BERT-Large tham chiếu trong INT8.
Bảng 1: So sánh BERT-Large – FP32
| Bật độ chính xác của F1
SQuAD (FP32) |
Số lượng tham số | Kích thước mô hình | Thông lượng (QPS)
Thời gian chạy ONNX FP32 |
|
| BERT-Lớn | 90,87 | 340 triệu | 1,4 GB | 12 |
| DeciBERT-Lớn | 91.08 | 115 triệu | 378 MB hoặc 0,378 GB | 76 |
| Mức tăng Deci | Độ chính xác F1 tốt hơn 0,21 | Cải thiện 66,2% | Giảm kích thước 73% | Cải thiện thông lượng gấp 6,33 lần |
Bảng 2: So sánh BERT-Large – INT8
| Độ chính xác của F1 trên SQuAD (INT8) | Số lượng tham số | Kích thước mô hình | Thông lượng (QPS)
Thời gian chạy ONNX INT8 |
|
| BERT-Lớn | 90,07 | 340 triệu | 1,4 GB
|
18 |
| DeciBERT-Lớn | 91.08 | 115 triệu | 95 MB hoặc 0,095 GB | 116 |
| Mức tăng Deci | Độ chính xác F1 tốt hơn 1,01 | Cải thiện 66,2% | Giảm kích thước 93,2% | Cải thiện thông lượng gấp 6,44 lần |
Hình dưới đây cho thấy việc triển khai các mô hình BERT-Large được biên dịch bằng ONNXRT của Deci AI là rất quan trọng trong việc mang lại hiệu suất cạnh tranh ở cả độ chính xác FP32 và INT8:
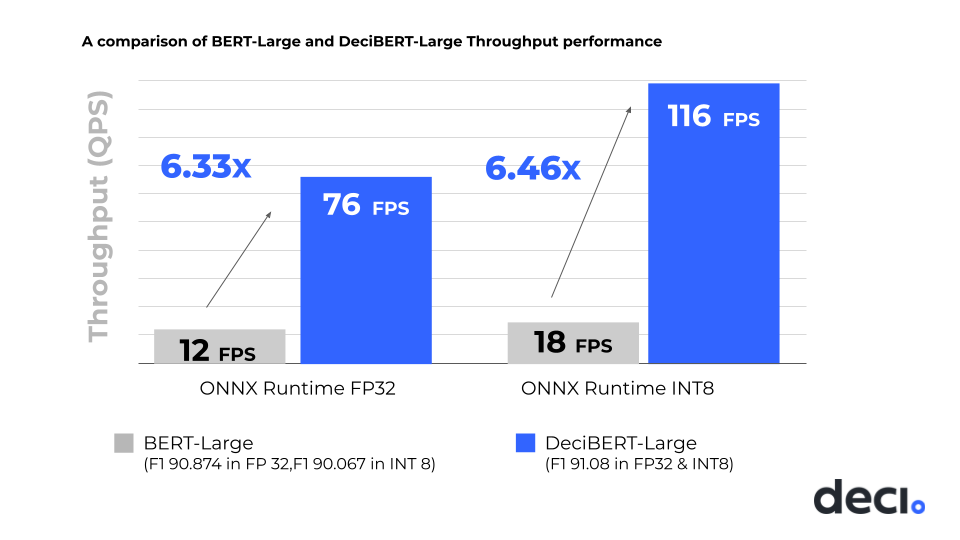
Hình 1: So sánh hiệu suất giữa việc triển khai mô hình BERT-Large tham chiếu và mô hình DeciBERT-Large được tối ưu hóa của Deci AI
FP32 thường được sử dụng để chạy các mô hình học sâu vì đây là kiểu dữ liệu nổi mặc định trong các ngôn ngữ lập trình. Nó bao gồm 32 bit số 1 và số 0, trong đó bit đầu tiên là bit dấu, biểu thị giá trị có dương hay không. Tám bit tiếp theo là số mũ của số và 23 bit cuối cùng là phân số hoặc phần định trị của số. FP32, hay dấu phẩy động 32, sử dụng 9 bit cho phạm vi và 23 bit cho độ chính xác. Phạm vi động của FP32 hoặc số lượng số có thể biểu thị bằng cách sử dụng kiểu dữ liệu này, đạt gần bốn tỷ giá trị.
INT8 đã trở thành kiểu dữ liệu phổ biến cho suy luận deep learning. Vì INT8 có ít bit hơn và dải động nhỏ hơn (256 giá trị so với bốn tỷ giá trị được biểu thị bằng FP32), nên yêu cầu tính toán của INT8 giảm đáng kể so với FP32. Thông thường, độ trễ thấp hơn và thông lượng cao hơn khi sử dụng mô hình INT8 so với mô hình FP32. Tuy nhiên, thông lượng tăng lên và độ trễ thấp hơn có xu hướng làm giảm độ chính xác.
Hầu hết các lần gửi MLPerf BERT-Large trong danh mục độ chính xác 99,9 phần trăm đều sử dụng lượng tử hóa 32 bit hoặc 16 bit vì lượng tử hóa 8 bit bị mất và thường làm giảm độ chính xác của mô hình xuống dưới ngưỡng 99,9 phần trăm. Ví dụ: trong khi áp dụng lượng tử hóa INT8 cho mô hình BERT-Large cơ sở là một tùy chọn giúp tăng tốc thông lượng từ 12 FPS lên 18 FPS, nó không còn đáp ứng các giới hạn về độ chính xác 99,9% MLPerf.
Công cụ và tối ưu hóa Deci AI AutoNac
Công cụ Deci AI AutoNAC đảm bảo rằng mô hình được thiết kế đáp ứng các yêu cầu về độ chính xác do MLPerf đặt ra và theo đuổi biến thể hiệu suất cao nhất của mô hình cụ thể trong phạm vi các ràng buộc đó, cho phép tận dụng lượng tử hóa INT8 để gửi.
Công cụ Deci AI AutoNAC bắt đầu bằng cách tạo ra một không gian tìm kiếm động có tính đến các tham số như độ chính xác cơ bản, mục tiêu hiệu suất suy luận, phần cứng cơ bản, trình biên dịch và lượng tử hóa, cùng nhiều thông số khác. Một thuật toán tìm kiếm đa ràng buộc nhanh và chính xác được khởi tạo và tạo ra một kiến trúc mô hình mới mang lại hiệu suất cao nhất với các ràng buộc đã xác định.
Từ góc độ thời gian tính toán, quá trình tìm kiếm AutoNAC dài hơn khoảng ba lần so với đào tạo tiêu chuẩn, tùy thuộc vào nhiệm vụ. Ví dụ: đào tạo mô hình DeciBert để thực hiện tác vụ SQuAD NLP cần khoảng 60 giờ GPU. Việc tìm kiếm mô hình DeciBERT này cần khoảng 180 giờ GPU và quá trình tính toán liên quan được thực hiện song song. Do đó, việc tính toán AutoNAC có giá cả phải chăng về mặt thương mại đối với hầu hết mọi tổ chức.
Tóm lại, Deci AI đã tạo ra một mô hình sử dụng AutoNAC được thiết kế đặc biệt để mang lại hiệu suất tối ưu trong giới hạn MLPerf khi chạy trên máy chủ Dell có bộ xử lý AMD EPYC với 3D V-Cache.
Hình dưới đây thể hiện quá trình tối ưu hóa AutoNAC:
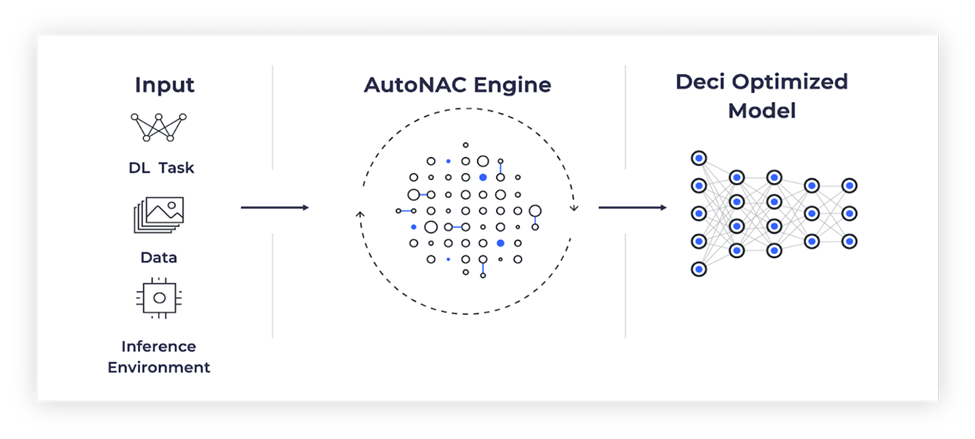
Hình 2: Quy trình AutoNac của Deci AI
Phần kết luận
Công cụ Deci AI AutoNAC tạo ra các mô hình suy luận deep learning được tối ưu hóa, đáp ứng các yêu cầu về độ chính xác và dữ liệu của khách hàng, đồng thời tối đa hóa hiệu suất. Hiệu suất tăng lên, kết hợp với việc giảm đáng kể số lượng tham số và kích thước bộ nhớ, giúp các mô hình được tối ưu hóa Deci AI có hiệu quả cao cho nhiều ứng dụng. Mô hình DeciBERT-Large là phiên bản tối ưu hóa của mô hình BERT-Large hiện đại cho các ứng dụng NLP. Áp dụng điều đó vào các tình huống thực tế, trung tâm cuộc gọi là ví dụ về những khách hàng có thể tận dụng hiểu biết sâu sắc trong các lĩnh vực phân tích cảm xúc, phiên âm và dịch trực tiếp cũng như trả lời câu hỏi. Mô hình DeciBERT-Large, do Deci AI phát triển cho MLPerf v2.1, có thể dễ dàng điều chỉnh cho phù hợp với tập dữ liệu và ứng dụng của chính trung tâm cuộc gọi, đồng thời được triển khai trong sản xuất ngay hôm nay để cải thiện hiệu suất, rút ngắn thời gian thu thập thông tin chi tiết và cho phép triển khai các ứng dụng nhỏ hơn. các mô hình được tối ưu hóa với yêu cầu tính toán giảm, điều này trở nên đặc biệt có lợi trong môi trường hạn chế về năng lượng hoặc chi phí.
Bài viết mới cập nhật
Công bố các bản nâng cấp không gây gián đoạn dựa trên Drain (NDU)
Trong quy trình làm việc NDU, các nút được khởi động ...
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...