
Tin tức
Kích hoạt khối lượng công việc AI trong môi trường HPC
Triệu chứng
Nghị quyết
Trí tuệ nhân tạo (AI) hiện tại và ngăn xếp phần mềm khoa học dữ liệu phức tạp một cách đáng báo động. Có lẽ điều đáng báo động hơn nữa đối với người dùng mới là tốc độ phát triển của các ngăn xếp này – các bản cập nhật hàng tháng cho nhiều lớp ngăn xếp không phải là hiếm. Ngăn xếp phần mềm AI có thể có sự phụ thuộc lẫn nhau nội tại sâu sắc giữa nhiều thư viện, điều này trong nhiều trường hợp khiến chúng dễ vỡ hơn đáng kể so với ngăn xếp HPC truyền thống. Các nhà nghiên cứu và nhà khoa học dữ liệu đang giải quyết vấn đề phần mềm này bằng các hệ thống hiện đại dựa trên Docker và Kubernetes để tận dụng các vùng chứa dựng sẵn được tối ưu hóa. Hiện tại, không phải tất cả các nhà nghiên cứu đều có quyền truy cập vào các giải pháp dựa trên vùng chứa này và đang sử dụng các cụm HPC truyền thống.
Các tài nguyên HPC theo truyền thống là một loại hộp thời gian phần mềm: Sau khi một cụm HPC được đưa vào trực tuyến, có khả năng các bản cập nhật tiếp theo duy nhất được thực hiện trong suốt vòng đời của nó sẽ là các bản sửa lỗi bảo mật hệ điều hành. Điều này có nghĩa là người dùng AI rất có thể sẽ không tìm thấy phiên bản mới nhất của trình biên dịch và thư viện cần thiết để cập nhật phiên bản mới nhất của phần mềm cần thiết cho dự án của họ.
May mắn thay, hai dự án quản lý gói Python đã trở thành tiêu chuẩn thực tế để giải quyết vấn đề này. Python Package Index (PyPI) cung cấp pip dưới dạng trình quản lý gói ( https://pypi.org/project/pip/ ), trong khi Anaconda, Inc. ( https://www.anaconda.com/ ) cung cấp hai giải pháp dựa trên trình quản lý gói conda. Cả hai cách tiếp cận đều tìm cách đơn giản hóa quy trình mà người dùng bình thường (nghĩa là không phải root) có thể tự do quản lý môi trường Python cục bộ của riêng họ trong khi vẫn an toàn bên trong quyền truy cập do quản trị viên HPC của họ cung cấp.
Mục tiêu của bài viết này là cung cấp cho người dùng HPC hiện tại các hướng dẫn về cách nhanh chóng xây dựng một môi trường mạnh mẽ để đánh giá và phát triển các ngăn xếp học sâu AI hiện đại. Bắt đầu với cách sử dụng Anaconda và pip cùng nhau trong việc xây dựng một môi trường phần mềm không gian người dùng phức tạp. Sau đó, xem qua một ví dụ về việc sử dụng môi trường này để chạy ứng dụng đào tạo TensorFlow phân tán được tăng tốc GPU bằng cách sử dụng Horovod. Cuối cùng, chúng tôi trình bày kết quả chạy chuẩn ResNet-50 với môi trường Conda.
Anaconda, Inc. cung cấp hai giải pháp dựa trên conda: Anaconda và Miniconda. Anaconda áp dụng cách tiếp cận “bồn rửa nhà bếp” và cài đặt hơn 720 gói Python phổ biến, trong khi Miniconda chọn cách tiếp cận tối giản. Phần trình diễn bên dưới đã được viết rõ ràng cho Miniconda. Nhóm tại Anaconda, Inc. đã tạo sẵn một số lượng gói đáng kinh ngạc, vậy điều gì có thể bắt buộc phải sử dụng trình quản lý gói thứ hai?
Trong một thế giới hoàn hảo, một trình quản lý gói duy nhất sẽ hoàn toàn cho phép bạn xây dựng một môi trường khoa học dữ liệu Python AI lý tưởng chứa mọi phụ thuộc cần thiết để xây dựng, thử nghiệm và/hoặc triển khai thành công môi trường tăng tốc GPU để đào tạo TensorFlow phân tán. Tuy nhiên, như đã đề cập ở trên, ngăn xếp phần mềm khoa học dữ liệu AI rất lớn và năng động.
Trong thế giới hiện tại, một trình quản lý gói duy nhất dường như đảm bảo rằng ít nhất một gói được yêu cầu không có sẵn – hoặc vẫn chỉ có phiên bản trước đó. Lập luận về môi trường phát triển AI hỗn hợp conda/pip Python rất đơn giản: Nó giảm số giờ kỹ thuật AI được sử dụng chung để duy trì môi trường Python và giúp duy trì sự tập trung vào khối lượng công việc thực tế.
Trước khi bắt đầu:
Ví dụ này ghi lại một quy trình để xây dựng môi trường Python đa nút, đa GPU đang hoạt động, phù hợp để đào tạo nhiều mô hình AI có liên quan ở quy mô lớn trên cơ sở hạ tầng HPC. Trường hợp cụ thể này trình bày cách xây dựng môi trường TensorFlow được tăng tốc GPU với conda và cách thêm Horovod của Uber bằng NCCL mà không phá vỡ môi trường conda. NCCL ( N VIDIA C ollective C ommunications L ibrary) là một thư viện phần mềm của Nvidia cung cấp các nguyên mẫu giao tiếp tập thể đa GPU và nhiều nút. Horovod ( https://github.com/uber/horovod ) là một nền tảng đào tạo GPU phân tán quy mô lớn, cung cấp phương tiện để sử dụng nhiều nút điện toán thông qua Giao diện truyền tin nhắn (MPI) để đào tạo mạng thần kinh phân tán. Mặc dù điều này được viết và thử nghiệm cho TensorFlow, quá trình xây dựng môi trường Python cho các khung AI phổ biến khác cũng diễn ra theo cách tương tự.
Xin lưu ý rằng có những lưu ý khi sử dụng đồng thời conda và pip: https://www.anaconda.com/blog/developer-blog/using-pip-in-a-conda-environment/
Cụ thể, việc chạy conda sau pip có khả năng ghi đè hoặc phá vỡ các gói đã cài đặt pip. Ngược lại, pip cũng có thể phá vỡ môi trường conda đã cài đặt.
Khuyến nghị: ĐẦU TIÊN xây dựng môi trường conda, SAU ĐÓ cài đặt các gói pip. LUÔN.
Tùy thuộc vào các chi tiết cụ thể trong tình huống của bạn, bạn có thể muốn/được yêu cầu chỉnh sửa các tệp đăng nhập của mình theo một cách riêng, chẳng hạn như bằng cách:
- Thêm các mục vào PATH và LD_LIBRARY_PATH của bạn
- Tải các mô-đun môi trường hệ thống – ví dụ: tải CUDA phiên bản 10.0 có thể được thực hiện trên hệ thống của bạn bằng một lệnh như: tải mô-đun cuda10.0 .
Thư mục trên cùng của nhiều kho AI GitHub phổ biến chứa một tệp có tên tests.txt, tệp này chứa danh sách các gói Python bổ sung mà mã của nhà phát triển phụ thuộc vào. Xem xét đề xuất ở trên (conda sau đó là pip), bạn phải quyết định phương pháp phù hợp nhất để kết hợp các gói này vào môi trường HPC-AI của mình. Theo kinh nghiệm, đáng để thử một vài biến thể trên các hướng dẫn cơ bản này để hội tụ thành một môi trường mạnh mẽ cho từng repo AI cụ thể – một kích thước hiện không phù hợp với tất cả.
Xây dựng GPU hỗ trợ đào tạo TensorFlow phân tán với Horovod và NCCL
- Điều kiện tiên quyết: Môi trường Python PHẢI được xây dựng trên một nút có phần cứng GPU chức năng.
- Trình điều khiển CUDA: Lớp phần mềm dành riêng cho GPU NVIDIA
- OpenMPI: MPI cho kết cấu mạng tốc độ cao như InfiniBand và Omni-Path.
- gcc: Cần thiết để xây dựng Horovod, phiên bản tối thiểu 7.2.0
- Cài đặt Miniconda. Xem https://docs.conda.io/projects/conda/en/latest/user-guide/install/index.html
- Tạo một môi trường Conda mới, chỉ định tên của nó và phiên bản Python ưa thích của bạn. Ví dụ: lệnh này tạo môi trường Python 3.6.8 mới có tên “mynewenv”:
conda tạo –name mynewenv python=3.6.8
- Kích hoạt môi trường conda mới tạo. Trong Linux, điều này được thực hiện bằng lệnh:
conda kích hoạt mynewenv
- Điều kiện trực tiếp để cài đặt phiên bản tăng tốc GPU 1.12.0 của TensorFlow. Theo mặc định, conda tính toán danh sách đầy đủ các thay đổi mà nó cần thực hiện để đáp ứng yêu cầu cài đặt gói, sau đó hiển thị danh sách với lời nhắc ay/n về việc có nên tiếp tục hay không. Cờ -y chỉ đơn giản là xác nhận lời nhắc này trước.
cài đặt conda -y tensorflow-gpu==1.12.0
- Tải xuống phiên bản NCCL không liên quan đến hệ điều hành (tarfile):
- NVIDIA hỗ trợ nhiều kịch bản cài đặt.
- Xem https://docs.nvidia.com/deeplearning/sdk/nccl-install-guide/index.html
- Trong ví dụ này, chúng tôi tải xuống trình cài đặt cục bộ không phụ thuộc vào hệ điều hành cho CUDA 10.0.
- Giải nén tarfile NCCL vào bất kỳ thư mục thuận tiện nào mà bạn có quyền truy cập đọc/ghi. Các tệp NCCL được trích xuất vào một thư mục con mới có cùng tên với trình cài đặt. Đối với ví dụ này, chúng tôi chỉ giải nén vào thư mục $HOME bằng lệnh:
tar xvf nccl_2.3.7-1+cuda10.0_x86_64.txz
- Trực tiếp pip để xây dựng và cài đặt Horovod bằng cách ban hành lệnh:
HOROVOD_NCCL_HOME=$HOME/nccl_2.3.7-1+cuda10.0_x86_64/ \
HOROVOD_GPU_ALLREDUCE=NCCL \
cài đặt pip –chỉ nâng cấp chiến lược nếu cần –no-cache-dir horovod==0.15.1
Xác minh hiệu suất
Để xác minh hiệu suất của môi trường Conda, chúng tôi đã chạy điểm chuẩn Resnet50 trên cụm HPC truyền thống. Cụm HPC truyền thống được định cấu hình với EDR Infiniband và sử dụng SLURM làm trình quản lý hàng đợi hàng loạt. Hệ thống này được tạo thành từ một tập hợp các máy chủ Dell PowerEdge C4140 với GPU Nvidia V100-SXM2 32GB. Điểm chuẩn ResNet50 được chạy bằng GPU 1, 2, 4 và 8. Các thử nghiệm đã được chạy với dữ liệu tổng hợp và thực tế.
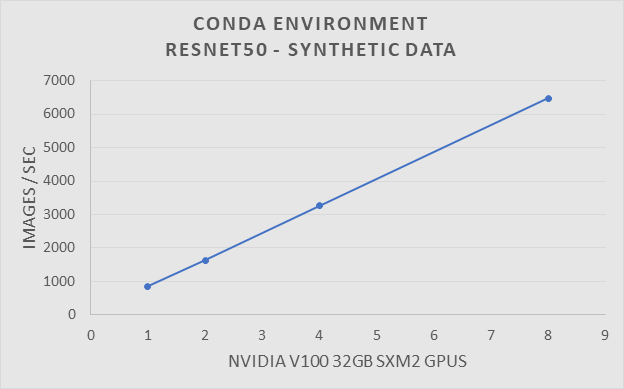
Điểm chuẩn ResNet-50 sử dụng dữ liệu tổng hợp với Môi trường Conda trên hệ thống HPC truyền thống
| Nền tảng | PowerEdge C4140 |
| CPU | 2 x Intel® Xeon® Gold 6148 @2.4GHz |
| Kỉ niệm | 384GB DDR4 @ 2666MHz |
| Kho | Nước bóng |
| GPU | V100-SXM2 32GB |
| Hệ điều hành | RHEL 7.4x86_64 |
| Nền tảng Linux | 3.10.0-693.x86_64 |
| Mạng | Mellanox EDR InfiniBand |
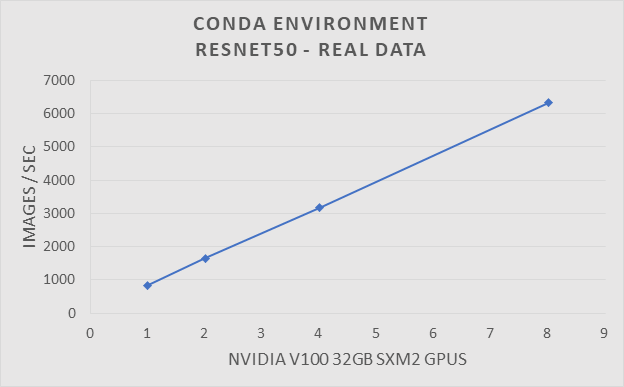
Điểm chuẩn ResNet-50 sử dụng dữ liệu tổng hợp với Môi trường Conda trên hệ thống HPC truyền thống.
| khung | TenorFlow 1.12.0 |
| Horovod | 0.15.1 |
| Bộ KH&ĐT | OpenMPI 4.0.1 |
| CUDA | 10,0 |
| NCCL | 2.3.7 |
| CUDNN | 7.6.0 |
| con trăn | 3.6.8 |
| Hệ điều hành | RHEEL 7.4 |
| GCC | 7.2.0 |
Tóm lược:
Các ngăn xếp phần mềm được sử dụng cho Deep Learning rất phức tạp, nhưng các nhà nghiên cứu và quản trị viên hệ thống không cần phải lo lắng về cách xây dựng chúng. Anaconda cung cấp một phương pháp để nhanh chóng thiết lập môi trường phần mềm phức tạp cần thiết để thực hiện đào tạo phân tán trên cụm HPC truyền thống. Những kết quả này chứng minh rằng các nhà nghiên cứu có thể dễ dàng đạt được hiệu suất mong đợi mà không cần biết cách xây dựng ngăn xếp riêng lẻ. Giờ đây, các cụm HPC truyền thống có thể chạy song song các khối lượng công việc học sâu hiện đại để giảm thời gian tìm ra giải pháp.
Bài viết mới cập nhật
Dell PowerScale và Marvel hợp tác để tạo ra quy trình làm việc truyền thông tối ưu
Hiện đang ở thế hệ thứ 9, giải pháp lưu trữ Dell ...
Bảo mật PowerScale OneFS SyncIQ
Trong thế giới sao chép dữ liệu, việc đảm bảo tính ...
Danh sách kiểm tra cơ sở bảo mật PowerScale
Là một biện pháp bảo mật tốt nhất, chúng tôi khuyến ...
Bảo vệ dữ liệu của bạn trong tương lai: Airgap Bộ dữ liệu về tính liên tục của doanh nghiệp của bạn
Trong thời đại kỹ thuật số ngày nay, mối đe dọa ...