
Tin tức
LAMMPS — với Ice Lake trên Máy chủ Dell EMC PowerEdge
Bộ xử lý có khả năng thay đổi Intel Xeon® thế hệ thứ 3 (mã kiến trúc có tên là Ice Lake ) là sản phẩm kế thừa Cascade Lake của Intel. Các tính năng mới bao gồm tối đa 40 lõi cho mỗi bộ xử lý, tám kênh bộ nhớ hỗ trợ tốc độ bộ nhớ 3200 MT/s và PCIe Gen4. HPC và Phòng thí nghiệm đổi mới AI tại Dell EMC có quyền truy cập vào một số hệ thống và blog này trình bày kết quả nghiên cứu điểm chuẩn ban đầu của chúng tôi.
Tổng quan về LAMMPS
Trình mô phỏng song song khối lượng lớn nguyên tử/phân tử quy mô lớn ( LAMMPS ) là một bộ sưu tập gói mã nguồn mở, song song tốt cho nghiên cứu động lực học phân tử (MD). LAMMPS có một bộ sưu tập đẹp về “kiểu nguyên tử”, trường lực và nhiều gói đóng góp. LAMMPS có thể chạy trên một bộ xử lý hoặc trên các siêu máy tính song song lớn nhất. Nó cũng có các gói cung cấp các phép tính lực được tăng tốc trên GPU. Nó có thể thực hiện các mô phỏng với hàng tỷ nguyên tử!
LAMMPS có thể chạy trên một bộ xử lý đơn lẻ hoặc song song bằng cách sử dụng một số hình thức truyền tin nhắn, chẳng hạn như Giao diện truyền tin nhắn (MPI). Mã nguồn mới nhất cho LAMMPS được viết bằng C++. Để biết thêm thông tin về LAMMPS, hãy xem liên kết sau: https://www.lammps.org/ .
Khách quan
Trong nghiên cứu này, chúng tôi đo lường hiệu suất của LAMMPS trên các mẫu bộ xử lý Ice Lake khác nhau như được liệt kê trong Bảng 1 so với các hệ thống Cascade Lake thế hệ trước. Các thử nghiệm về khả năng mở rộng của nút đơn cũng như đa nút đã được tiến hành.
Tổng hợp chi tiết
Phiên bản LAMMPS được sử dụng để phát hành thử nghiệm là lammps-ngày 2 tháng 7 năm 2021, sử dụng trình biên dịch Intel 2020 update 5 để tận dụng tối ưu hóa AVX2 và AVX512 cũng như thư viện Intel MKL FFT. Chúng tôi đã sử dụng gói INTEL mặc định , gói này đi kèm với gói LAMMPS cung cấp một số kiểu cặp nguyên tử được tối ưu hóa tốt trong LAMMPS cho hướng dẫn vectơ trên bộ xử lý Intel. Các bộ dữ liệu được sử dụng cho nghiên cứu của chúng tôi được mô tả trong Bảng 2, cùng với cấu hình chi tiết về kích thước nguyên tử và các bước chạy. Đơn vị hiệu suất là dấu thời gian trên giây và càng cao càng tốt.
Cấu hình phần cứng và phần mềm
Bảng 1: Chi tiết giường thử nghiệm phần cứng và phần mềm
|
Thành phần |
Máy chủ Dell EMC PowerEdge R750 | Máy chủ Dell EMC PowerEdge R750 | Máy chủ Dell EMC PowerEdge C6520 | Máy chủ Dell EMC PowerEdge C6520 | Máy chủ Dell EMC PowerEdge C6420 | Máy chủ Dell EMC PowerEdge C6420 |
| mô hình CPU | xeon 8380 | xeon 8358 | Xeon 8352Y | xeon6330 | xeon 8280 | Xeon 6248R |
| Lõi/ổ cắm | 40 | 32 | 32 | 28 | 28 | 24 |
| tần số cơ sở | 2,30 GHz | 2,60 GHz | 2,20 GHz | 2,00 GHz | 2,70 GHz | 3,00 GHz |
| TDP | 270W | 250W | 205 W | 205 W | 205 W | 205 W |
| Hệ điều hành | Red Hat Enterprise Linux 8.3 4.18.0-240.22.1.el8_3.x86_64 | |||||
| Ký ức |
16 GB x 16 (2Rx8) 3200 tấn/giây
|
16 GB x 12 (2Rx8)
2933 tấn/giây |
||||
| BIOS/CPLD | 1.1.2/1.0.1 | |||||
| kết nối | NVIDIA Mellanox HDR
|
NVIDIA Mellanox HDR100 | ||||
| Trình biên dịch | Studio song song Intel 2020 (bản cập nhật 4) | |||||
| ĐÈN | ngày 2 tháng 7 năm 2021 | |||||
Bộ dữ liệu được sử dụng để phân tích hiệu suất
Bảng 2: Mô tả các bộ dữ liệu được sử dụng để phân tích hiệu suất
| Bộ dữ liệu | Sự miêu tả | Các đơn vị | phong cách nguyên tử | Kích thước nguyên tử | Cỡ bước chân |
| lennard jones | Chất lỏng nguyên tử (LJ Benchmark) | lj | nguyên tử | 512000 | 7900 |
| hoa đỗ quyên | Protein (Điểm chuẩn Rhodopsin) | thực tế | đầy | 512000 | 520 |
| Tinh thể lỏng | Tinh thể lỏng với tiềm năng Gay-Berne | lj | hình elip | 524288 | 840 |
| Eam | Điểm chuẩn đồng với Phương pháp nguyên tử nhúng | kim loại | nguyên tử | 512000 | 3100 |
| Stilliger Weber | Điểm chuẩn silicon với Stillinger-Weber | kim loại | nguyên tử | 512000 | 6200 |
| teroff | Điểm chuẩn silicon với Tersoff | kim loại | nguyên tử | 512000 | 2420 |
| Nước | Định chuẩn nước hạt thô sử dụng Stillinger-Weber | thực tế | nguyên tử | 512000 | 2600 |
| polyetylen | Điểm chuẩn polyetylen với AIREBO | kim loại | nguyên tử | 522240 | 550 |
Hình 1: Chế độ xem hình ảnh của bộ dữ liệu từ OVITO (phần mềm phân tích và trực quan hóa dữ liệu khoa học cho mô hình mô phỏng dựa trên phân tử và hạt khác). Hình ảnh được liệt kê theo thứ tự 1a-1h, hình con 1a- 1h đại diện cho một phần nhỏ miền mô phỏng cho Chất lỏng nguyên tử (Lennard Jones), rhodo(protein), tinh thể lỏng(lc), đồng(eam), stilliger webner(sw), Bộ dữ liệu Terasoff, nước, polyetylen tương ứng.
Bảng 1 và Hình 1 cho thấy chế độ xem hình ảnh của bộ dữ liệu được sử dụng để phân tích đơn và đa nút. Để trực quan hóa tất cả các bộ dữ liệu đã được thực hiện bằng OVITO, phần mềm phân tích và trực quan hóa dữ liệu khoa học cho mô hình mô phỏng dựa trên phân tử và hạt khác. Đối với nghiên cứu hiệu suất một nút, tất cả các bộ dữ liệu hiển thị trong Bảng 2 đã được sử dụng và đối với nghiên cứu đa nút, Atomic Fluid được xem xét để đo điểm chuẩn.
Phân tích hiệu suất trên một nút
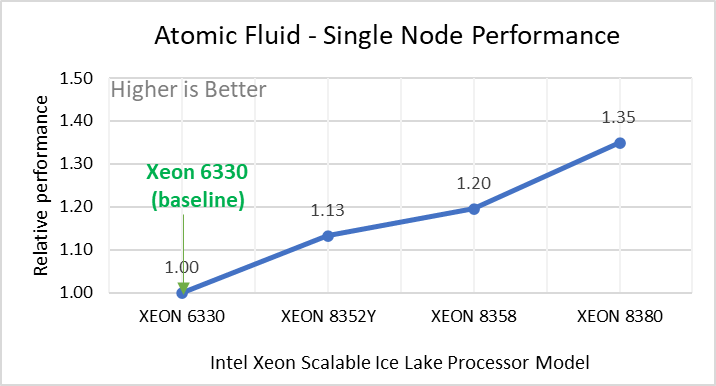
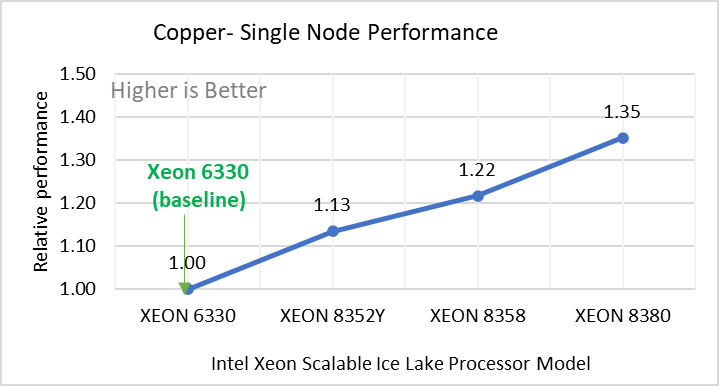
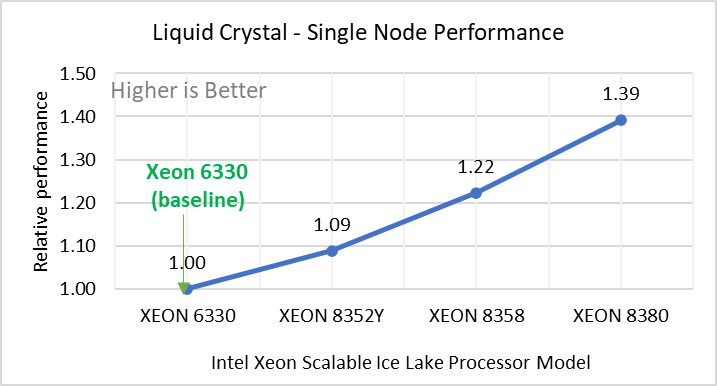
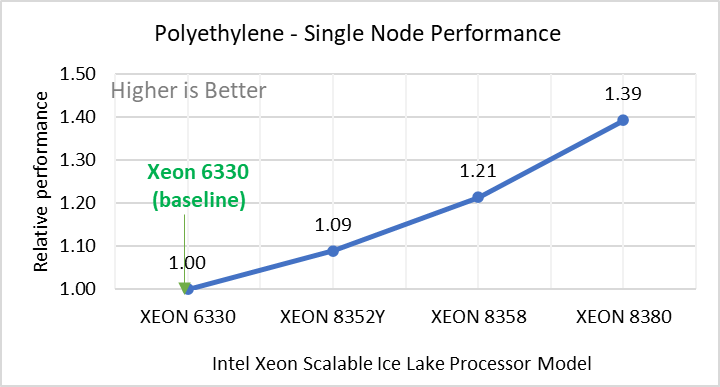
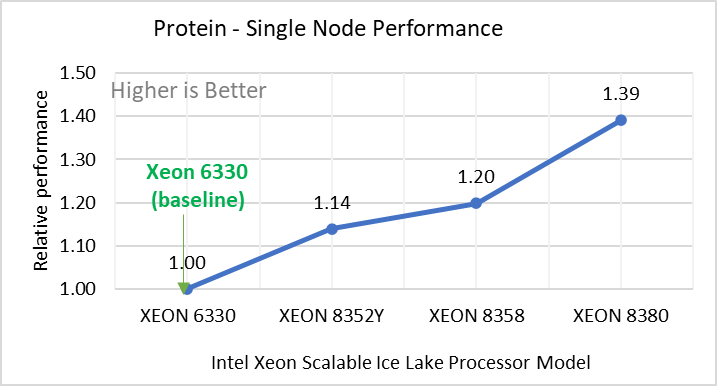
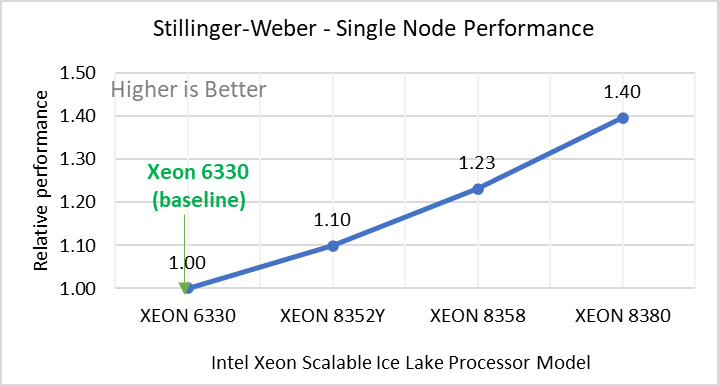
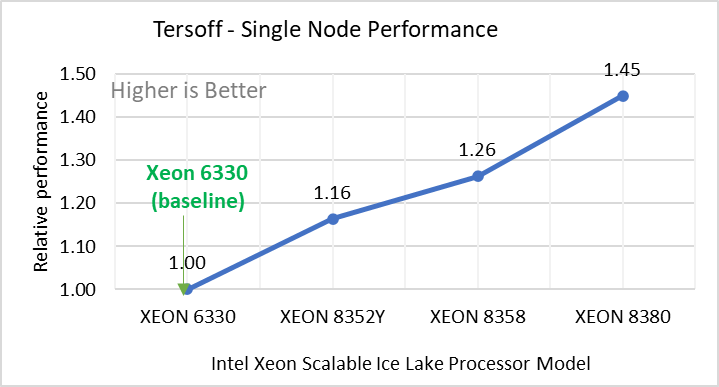
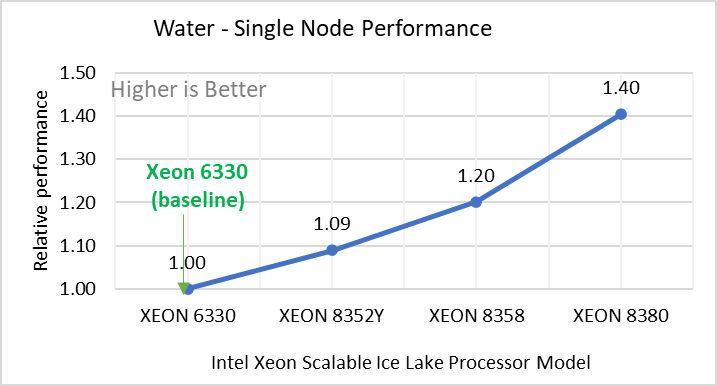
Hình 2: Hiệu suất nút đơn của LAMMPS trên các bộ dữ liệu với mẫu bộ xử lý Intel Ice Lake. Mỗi biểu đồ trong Hình 2 là một hình con riêng lẻ, được gắn nhãn (ah) theo thứ tự được hiển thị. Mỗi cấu hình con (2a- 2h) thể hiện so sánh hiệu suất nút đơn giữa các bộ xử lý Xeon với Xeon 6330 làm đường cơ sở cho Atomic Fluid (Lennard Jones), rhodo(protein), tinh thể lỏng (lc), đồng(eam), stilliger webner(sw) , Terasoff, nước, bộ dữ liệu polyetylen tương ứng.
Hình 2 cho thấy hiệu suất nút đơn cho tám bộ dữ liệu (hình phụ 2a-h) được liệt kê trong Bảng 2 với bốn mẫu bộ xử lý Ice Lake có sẵn để đánh giá LAMMPS.
Để dễ so sánh giữa các kiểu bộ xử lý, hiệu suất tương đối của các bộ dữ liệu đã được đưa vào một biểu đồ khác. Tuy nhiên, điều đáng chú ý là mỗi bộ dữ liệu hoạt động riêng lẻ khi hiệu suất được xem xét, vì mỗi bộ sử dụng các tiềm năng phân tử khác nhau và có số lượng nguyên tử khác nhau. Hình 2 cho thấy rằng việc tăng số lượng lõi trong mô hình bộ xử lý sẽ làm tăng hiệu suất, trên tập dữ liệu được sử dụng. Tiếp theo, bằng cách so sánh các con số tương đối với bộ xử lý cơ sở Xeon 6330(28C) với Xeon 8380(40C), chúng tôi đã đo được mức tăng hiệu suất từ 30 đến 45 phần trăm với các bộ dữ liệu này. Một phần của những lần tăng này là do tần số của kiểu bộ xử lý.
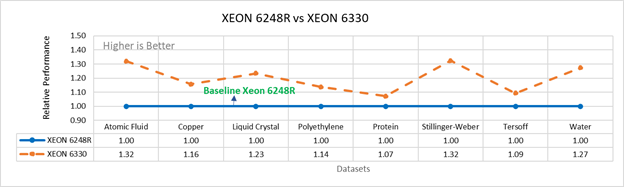
Hình 3a: Hiệu suất của LAMMPS trên Cascade Lake (Xeon 6248R) so với Ice Lake (Xeon 6330)
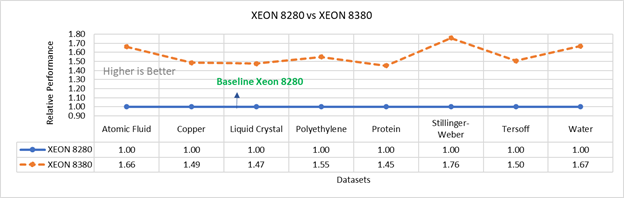
Hình 3b: Hiệu suất của LAMMPS trên Cascade Lake (Xeon 8280) so với Ice Lake (Xeon 8380)
Hình 3 so sánh hiệu suất của Cascade Lake 6248R tầm trung (24 lõi) với Ice Lake 6330 (28 lõi) và Cascade Lake 8280 (28 lõi) cấp cao nhất với Ice Lake 8380 (40 lõi) Từ hình 3a , Ice Lake 6330 nhanh hơn tới 30 phần trăm so với 6248R. Xeon 6330 có nhiều lõi hơn 16% và băng thông bộ nhớ nhanh hơn 9%. Hình 3b cho thấy Ice Lake 8380 nhanh hơn tới 75% so với Xeon 8280 trong các thử nghiệm nút đơn, điều này phù hợp với 42% lõi bổ sung và băng thông bộ nhớ nhanh hơn 9%. Những kết quả này là do tốc độ bộ xử lý cao hơn trong đó mỗi lõi có thể truy cập nhiều dữ liệu hơn.
Phân tích hiệu suất trên nhiều nút
Để phân tích kiểm tra khả năng mở rộng với quy mô mạnh và yếu, chúng tôi đã sử dụng bộ dữ liệu Atom Fluid (LJ) từ gói Intel. Thời gian chạy công việc là 7900 bước với 512000 nguyên tử trong hệ thống mô phỏng.
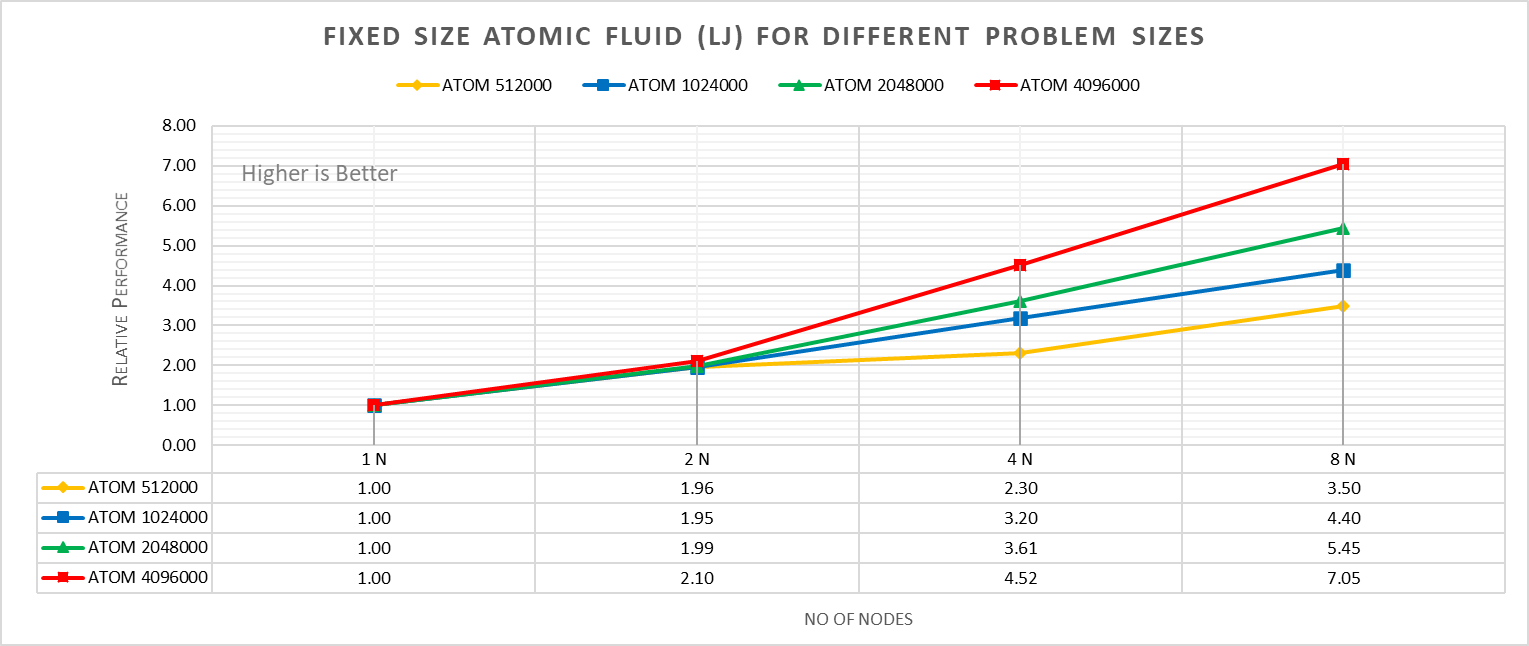
Hình 4a: Kích thước cố định Chất lỏng nguyên tử (LJ) cho các kích thước vấn đề khác nhau (mở rộng quy mô mạnh) với Xeon 8380
Với quy mô mạnh mẽ, chúng tôi đề cập đến quy mô vấn đề cố định và tăng quy trình song song (định luật Amdahl). Trong khi ở quy mô yếu, chúng tôi đã thay đổi kích thước nguyên tử từ 512000 nguyên tử thành 4096000 nguyên tử trong môi trường mô phỏng với sự gia tăng các quá trình song song (định luật Gustafson-Barsis). Giường thử nghiệm bao gồm các máy chủ DellEMC Poweredge R750, mỗi máy chủ có bộ xử lý Ice Lake Xeon 8380 kép, một kết nối NVIDIA Networking HDR chạy ở tốc độ 200 Gbps.Hình 4a biểu thị hiệu suất tương đối của kích thước cố định cho bốn kích thước vấn đề khác nhau, tức là 512000,1024000,2048000 và 4096000 nguyên tử, trên số lượng nút khác nhau.
Hiệu suất tương đối được chuẩn hóa bằng hiệu suất nút đơn. Do đó, hiệu suất nút đơn cho mỗi đường cong là 1,00 (đơn vị). Hiệu suất tương đối cho kích thước cố định Chất lỏng nguyên tử được tính theo phương trình sau:
Hiệu suất tương đối = thời gian lặp của nút ‘N’ / thời gian lặp cho một nút
Thời gian vòng lặp là tổng thời gian đồng hồ treo tường để chạy mô phỏng. Có thể quan sát thấy rằng hiệu suất tương đối tăng lên khi kích thước vấn đề tăng lên. Điều này là do đối với các sự cố nhỏ hơn, hệ thống dành nhiều thời gian hơn cho liên lạc giữa các nút. Thời gian dành cho giao tiếp tại 8 nút lần lượt là 61,91%, 59,74%,48,42%,45,04% cho kích thước nguyên tử 512000,1024000,2048000,4096000.
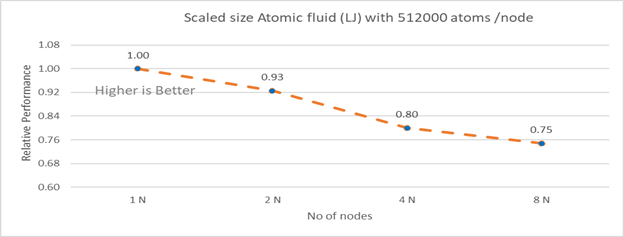
Hình 4b: Kích thước theo tỷ lệ Chất lỏng nguyên tử (LJ) với 512000 nguyên tử trên mỗi nút (tỷ lệ yếu) với Xeon 8380
Hình 4b biểu thị hiệu suất kích thước được chia tỷ lệ cho các lần chạy với 512000 nguyên tử trên mỗi nút. Do đó, một lần chạy 2 nút có kích thước được chia tỷ lệ dành cho 1024000 nguyên tử; 8 lần chạy nút là dành cho 4096000 nguyên tử. Hiệu suất tương đối cho kích thước được chia tỷ lệ Chất lỏng nguyên tử được tính theo phương trình sau:
Hiệu suất tương đối = thời gian lặp cho ‘n’ nút/ (thời gian lặp cho một nút * số nút)
Hiệu quả mở rộng quy mô yếu giảm khi không có nút nào trong phạm vi được điều tra tăng lên. Điều này là do thực tế đối với số lượng nút lớn hơn thì thời gian dành cho giao tiếp MPI sẽ lớn hơn. Thời gian dành cho giao tiếp với nguyên tử kích thước được chia tỷ lệ cho 1N, 2N, 4N và 8 N lần lượt là 27,17%, 32,42%, 40,87%, 45,04%.
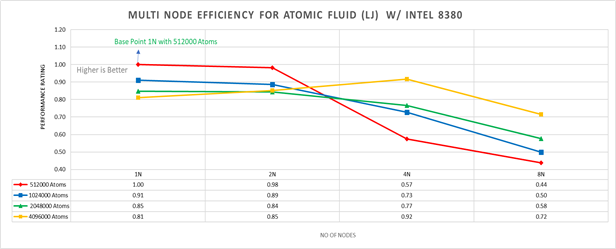
Hình 5 : Hiệu quả đa nút cho Atomic Fluid (LJ) w/I 8380
Hình 5 biểu thị hiệu suất đa nút cho Atomic Fluid với Xeon 8380. Hiệu suất tương đối được chuẩn hóa bằng nút đơn với hiệu suất 512000 nguyên tử. Do đó, hiệu suất nút đơn cho 512000 nguyên tử là 1,00 (đơn vị). Điểm này được lấy làm cơ sở để so sánh khác.
Đánh giá hiệu suất = (thời gian lặp * số nguyên tử)/ (thời gian lặp cho 512000 nguyên tử trên 1 nút * số nút * 512000)
Chúng tôi đã quan sát thấy rằng đối với các hệ thống nhỏ hơn, chẳng hạn như những hệ thống có ít nguyên tử hơn, hiệu quả của việc mở rộng quy mô mạnh sẽ giảm khi hệ thống dành nhiều thời gian hơn cho giao tiếp MPI; trong khi ở các hệ thống lớn hơn có nhiều nguyên tử, hiệu quả của việc mở rộng quy mô mạnh tăng lên khi thời gian dành cho tính toán lực theo cặp trở nên chiếm ưu thế. Đối với tỷ lệ yếu, vì không có nút nào làm tăng hiệu quả của tỷ lệ yếu sẽ giảm.
Phần kết luận
Các máy chủ Dell EMC Power Edge dựa trên bộ xử lý Ice Lake, với các nâng cấp tính năng phần cứng so với Cascade Lake, cho thấy mức tăng hiệu suất lên tới 50 đến 70 phần trăm cho tất cả các bộ dữ liệu được sử dụng để đo điểm chuẩn LAMMPS
Bài viết mới cập nhật
Tăng tốc khối lượng công việc của Hệ thống tệp mạng (NFS) của bạn với RDMA
Giao thức NFS hiện nay được sử dụng rộng rãi trong ...
Mẹo nhanh về dữ liệu phi cấu trúc – OneFS Protection Overhead
Gần đây đã có một số câu hỏi từ lĩnh vực ...
Giới thiệu Dell PowerScale OneFS dành cho Quản trị viên NetApp
Để các doanh nghiệp khai thác được lợi thế của công ...
Cơ sở hạ tầng CNTT: Mua hay đăng ký?
Nghiên cứu theo số liệu của IDC về giải pháp đăng ...